
Sua nuvem privada parece um buffet livre sem controle? Você sabe que ela gera valor, mas, quando a conta chega, é quase impossível saber quem está consumindo o quê.
Nos ambientes dinâmicos de nuvem atuais, é cada vez mais importante atribuir corretamente os custos aos usuários internos, principalmente para empresas que operam a própria infraestrutura de nuvem. É necessário estabelecer a responsabilização para distribuir os custos de maneira justa entre os departamentos ou incentivar as equipes a ajustar o tamanho de suas cargas de trabalho. Obter visibilidade é o primeiro passo.
Com o Feature Release 5 (FR5) do Red Hat OpenStack Services on OpenShift 18, entregamos uma peça fundamental para resolver esse quebra-cabeça: a capacidade de realizar a tarifação com base no uso medido dos seus tenants.
Apresentamos o CloudKitty, o serviço de tarifação nativo do OpenStack, em disponibilidade geral no FR5. Esse serviço preenche a lacuna entre suas métricas técnicas brutas e as operações financeiras.
Por que o CloudKitty é importante?
O CloudKitty fornece uma camada de tradução que transforma dados de uso do servidor em informações para embasar os orçamentos departamentais. Pense no CloudKitty como o leitor do medidor: ele fica entre as métricas coletadas e a sua solução de faturamento ou FinOps. Ele coleta dados técnicos brutos, como as horas de funcionamento de uma máquina virtual (VM) ou o volume de armazenamento consumido, e aplica suas regras de tarifação específicas para gerar um relatório. Isso ajuda a alcançar dois objetivos principais:
- Recuperação transparente de custos: agora você pode visualizar um detalhamento claro e discriminado do uso de recursos por tenant. Isso permite recuperar as despesas operacionais com precisão, sem surpreender os clientes internos com cobranças pouco transparentes.
- Confiança e otimização: quando os tenants veem como o próprio consumo (detalhado por projeto, flavor e métrica) afeta seus custos, eles podem tomar decisões embasadas, como arquivar dados inativos ou otimizar o uso de suas VMs.
Observe que o CloudKitty atua apenas como um mecanismo de visibilidade e tarifação. Ele não impõe orçamentos ativamente nem bloqueia a criação de recursos (como instâncias Nova) caso um tenant exceda um determinado limite de custo.
Como o CloudKitty funciona?
Embora não seja uma solução de faturamento completa, o CloudKitty estabelece o elo crucial entre o uso e o custo. O fluxo de trabalho, em termos simples, é o seguinte:
Defina regras de tarifação → Colete métricas → Gere relatórios de tarifação
Defina as regras
Apresentamos um tenant de exemplo da nossa lista fictícia: o Ministério dos Dados. Historicamente, o Ministério cria VMs de grande porte para suas cargas de trabalho de análise, mantendo-as em execução muito tempo após a conclusão dos cálculos.
Para obter uma recuperação transparente de custos, precisamos rastrear sua pegada de computação. Faremos isso monitorando a métrica ceilometer_cpu. Essa métrica específica permite oferecer uptime baseado em flavor, o que significa que, para cada período em que uma instância de VM estiver em execução, o CloudKitty poderá calcular uma taxa diferente com base no tamanho dela.
Etapa 1: crie o serviço
Primeiro, precisamos criar um container de nível superior para nossa métrica. O nome do serviço deve corresponder exatamente ao nome da métrica ou ao alt_name definido em metrics.yaml. (Abordaremos esse arquivo com mais detalhes posteriormente.)
openstack rating hashmap service create ceilometer_cpu
+----------+--------------------------------------+
| Nome | ID do serviço |
+----------+--------------------------------------+
| ceilometer_cpu | <uuid> |
+----------+--------------------------------------+Salve esse ID de serviço (UUID) — você precisará dele para os próximos comandos!
Ao criar um serviço chamado ceilometer_cpu, garantimos que cada ponto de dados de CPU recebido do coletor seja direcionado diretamente para essa nova regra de classificação.
Etapa 2: crie um grupo (opcional)
Não queremos que as cobranças de computação do Ministério se misturem com as contas de armazenamento ou de rede. Os grupos nos ajudam a organizar mapeamentos relacionados e a isolar os cálculos uns dos outros.
openstack rating hashmap group create cpu_ratingAo agrupar esses mapeamentos, separamos diferentes cenários de cobrança. Se múltiplos mapeamentos no mesmo grupo forem correspondentes, o CloudKitty aplicará apenas o mais caro.
Etapa 3: crie um mapeamento
Os mapeamentos são as regras de custo. Primeiro, vamos estabelecer uma linha de base para o Ministério dos Dados cobrando um valor fixo por item. Ao substituir <service_id> e <group_id> pelos UUIDs retornados nas etapas anteriores, você pode vincular essa nova regra diretamente ao seu serviço ceilometer_cpu e ao grupo cpu_rating.
openstack rating hashmap mapping create 0.02 \
-s <service_id> \
-g <group_id> \
-t flatNesse cenário, 0,02 significa 0,02 unidades por período de coleta (por padrão, a cada hora). Cada instância de CPU tem uma cobrança fixa de 0,02 unidades, independentemente do seu uso.
Etapa 4: precificação baseada em campos (a arma secreta)
O Ministério dos Dados executa servidores web minúsculos ao lado de nós de banco de dados robustos e de alto consumo de recursos. Cobrar uma taxa fixa por tudo não seria justo. Queremos cobrar preços diferentes para cada um dos flavors de VM específicos que eles usam.
Primeiro, criamos um campo referente à chave de metadados:
openstack rating hashmap field create <service_id> flavor_idEm seguida, criamos um mapeamento específico para o valor desse flavor:
openstack rating hashmap mapping create 0.05 \
--field-id <field_id> \
--value <flavor_uuid> \
-t flatRepetiremos a criação desse mapeamento para todos os flavors disponíveis em nosso ambiente. Para cada flavor, uma nova regra define a taxa que o serviço de classificação deve calcular quando esse tamanho específico de VM estiver em execução.
O resultado: como tudo funciona em conjunto
No final do mês, quando o Ministério dos Dados solicita a visualização do seu uso, veja como o CloudKitty processa as regras que criamos acima:
ceilometer_cpu (métrica)
└─> Serviço: ceilometer_cpu
└─> Campo: flavor_id (opcional)
└─> Mapeamento: m1.tiny = 0,01, m1.large = 0,05
└─> Mapeamento (direto): 0,02 fixoSe você pode medir, pode precificar
Usamos o consumo de CPU do Ministério dos Dados (ceilometer_cpu) como principal exemplo, mas a computação é apenas uma parte do quebra-cabeça. O verdadeiro poder do CloudKitty no Red Hat OpenStack Services on OpenShift é a sua integração com o Prometheus.
Lembre-se de que você pode usar qualquer métrica já coletada para a precificação. Isso significa que você pode criar facilmente regras de precificação para o restante dos recursos do seu locatário, seguindo exatamente as mesmas etapas descritas acima. Por exemplo, você pode criar mapeamentos de custos para:
- Armazenamento em bloco: acompanhe a capacidade de GB-mês usando
ceilometer_disk_device_capacity - Rede: cobre por endereços públicos alocados usando
ceilometer_ip_floating - Largura de banda de saída: classifique o tráfego de saída total de VMs usando
ceilometer_network_outgoing_bytes
Após o CloudKitty buscar esse escopo de dados do Prometheus, o processador aplica suas regras de classificação personalizadas e envia as métricas finalizadas e classificadas diretamente para um backend de armazenamento. Ele serve como a ponte automatizada definitiva entre a telemetria técnica bruta e os relatórios de FinOps.
Gere relatórios de classificação: a hora da verdade
Após criar suas regras e coletar as métricas do Prometheus, a etapa final é extrair os dados classificados.
É importante ressaltar que o CloudKitty não é um sistema de faturamento. Ele não tenta gerar uma fatura bonita em PDF. Em vez disso, ele foi projetado para servir como um mecanismo de dados robusto que fornece dados JSON limpos e analisáveis por meio de sua API REST ou do cliente OpenStack. Isso facilita a integração direta dos dados classificados ao middleware de FinOps, showback ou faturamento existente da sua empresa.
A visão do tenant: o Ministério verifica a conta
O CloudKitty tem controle de acesso integrado com reconhecimento de tenant. Quando o Ministério de Dados deseja visualizar o uso atual, ele só pode acessar o consumo do próprio projeto. A API bloqueia ou ignora automaticamente qualquer tentativa de visualizar os dados de outros tenants.
Para obter o resumo mensal, o Ministério pode usar o cliente OpenStack:
# Obtenha o resumo de um mês específico
openstack rating summary get --begin 2026-02-01 --end 2026-03-01A visão do administrador: a visão panorâmica
Embora o Ministério de Dados esteja restrito ao uso próprio, os administradores de nuvem precisam de uma visão holística de todo o ambiente para gerenciar a capacidade e facilitar o chargeback global.
Com um token de administrador, os operadores têm visibilidade total. Eles podem complementar o comando para isolar um tenant específico usando --tenant-id <project_uuid>.
openstack rating summary get \
--begin 2026-02-01 \
--end 2026-03-01 \
--tenant-id <project_uuid>Como alternativa, se a equipe de FinOps precisar da visão completa para exportar para seu sistema de faturamento, o administrador poderá extrair os dados tarifados de toda a nuvem de uma só vez usando a flag --all-tenants.
Conecte-se diretamente à sua solução de FinOps
Se o seu middleware de FinOps estiver extraindo esses dados programaticamente, ele poderá usar a API REST para solicitar um detalhamento agrupado pelos tipos de serviço específicos configurados anteriormente (como ceilometer_cpu):
curl -X GET \
-H "X-Auth-Token: $TENANT_TOKEN" \
"http://localhost:8888/v1/report/summary?begin=2026-02-01T00:00:00&end=2026-03-01T00:00:00&groupby=res_type"A saída JSON resultante apresenta claramente o tipo de recurso, o período e o total de unidades calculadas
{
"summary": [
{
"tenant_id": "MoD-project-uuid",
"res_type": "ceilometer_cpu",
"begin": "2026-02-01T00:00:00",
"end": "2026-03-01T00:00:00",
"rate": 125.50
}
]
}Ao direcionar esses dados JSON estruturados e agregados diretamente ao software financeiro da sua empresa, você completa o ciclo entre o consumo bruto de infraestrutura e a responsabilidade pelos custos.
Por baixo do capô
Agora que vimos o CloudKitty em ação pela perspectiva do operador, vamos olhar por baixo do capô para analisar o mecanismo interno. Compreender a arquitetura ajudará você a analisar a escalabilidade, solucionar problemas e entender as razões de certas decisões de design.
Visão geral da arquitetura
O CloudKitty funciona como dois processos independentes, cada um com uma responsabilidade distinta:
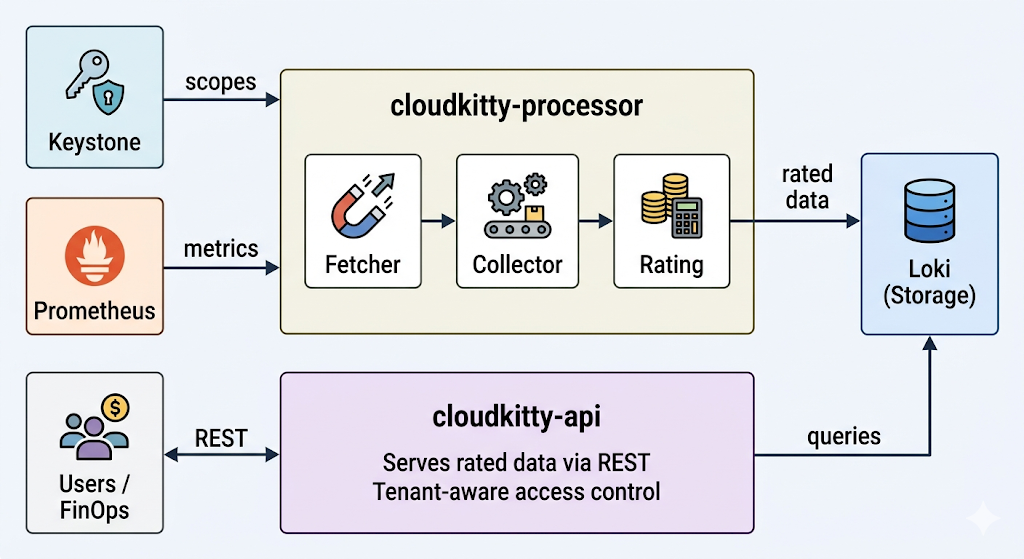
Figura 1. A arquitetura do CloudKitty. O cloudkitty-processor busca escopos no Keystone e métricas no Prometheus, tarifa os dados e os armazena no Loki. A cloudkitty-api fornece os dados tarifados do Loki para usuários e ferramentas de FinOps via REST.
cloudkitty-processor é o mecanismo de tarifação. A cada período de coleta (uma hora, por padrão), ele executa um pipeline de quatro estágios:
- Busca: solicita ao Keystone a lista de projetos do OpenStack (escopos) que exigem tarifação.
- Coleta: para cada escopo, consulta no Prometheus os valores brutos de métrica definidos em
metrics.yaml. - Tarifação: aplica as regras de hashmap (serviços, campos e mapeamentos configurados anteriormente) para converter o consumo bruto em dados tarifados.
- Armazenamento: envia os dataframes tarifados resultantes para o Loki para fins de persistência.
cloudkitty-api é o front-end REST. Processa todas as consultas recebidas de tenants, administradores e ferramentas externas de FinOps. Quando o usuário solicita um resumo de tarifação, consulta o Loki e retorna os resultados. Este processo é stateless e pode ser dimensionado horizontalmente para processar mais requisições simultâneas.
Como os dois processos são desacoplados, é possível dimensioná-los de forma independente: adicione mais réplicas de API para processar a carga de consultas ou ajuste o paralelismo do processador para tarifar mais escopos simultaneamente.
Por que Loki?
Usar o Grafana Loki como o back-end de armazenamento de dados tarifados pode parecer uma escolha não convencional, já que o Loki é conhecido principalmente como um sistema de agregação de logs. No entanto, ele é uma excelente opção:
- Nativo de séries temporais: os dados tarifados são inerentemente temporais: custo por escopo por período de coleta. O Loki foi desenvolvido especificamente para consultas eficientes de intervalo de tempo em fluxos estruturados.
- Já na stack: as implantações do OpenStack Services on OpenShift já incluem um LokiStack para gerenciamento de logs. O CloudKitty reutiliza a mesma infraestrutura gerenciada pelo operador, eliminando a necessidade de implantar ou manter um banco de dados adicional.
- Baseado em armazenamento de objetos: o Loki persiste os dados em armazenamento de objetos compatível com S3, mantendo o impacto operacional reduzido, sem a necessidade de gerenciar PVCs ou clusters de banco de dados adicionais.
- Metadados estruturados: no futuro, o CloudKitty armazenará metadados indexados (tenant, tipo de métrica, flavor) diretamente em cada entrada de log. Isso permitirá realizar consultas filtradas rápidas sem fazer o parsing completo do JSON, melhorando significativamente o desempenho das consultas em escala.
A configuração de métricas
No centro da etapa de coleta está o metrics.yaml. Este arquivo informa ao CloudKitty quais métricas do Prometheus coletar e como tratá-las. Veja um trecho representativo da configuração fornecida:
metrics:
ceilometer_cpu:
unit: instance
alt_name: instance
groupby:
- resource
- user
- project
- flavor_name
- flavor_id
mutate: NUMBOOL
extra_args:
aggregation_method: max
ceilometer_image_size:
unit: MiB
factor: 1/1048576
groupby:
- resource
- project
metadata:
- container_format
- disk_format
extra_args:
aggregation_method: maxCada entrada controla como o CloudKitty coleta e interpreta uma métrica específica do Prometheus:
unit: a unidade de cobrança exibida nos relatórios de tarifação (por exemplo, instância, GiB, B, ip).alt_name: um nome alternativo para a métrica. Ao criar serviços de hashmap, você pode usar o nome da métrica do Prometheus (ceilometer_cpu) ou oalt_name(instância).groupby: os rótulos do Prometheus usados para desagregar a métrica. Para ceilometer_cpu, o agrupamento por flavor_name and flavor_id habilita as regras de tarifação baseadas em flavor que configuramos anteriormente.mutate: uma transformação aplicada ao valor bruto. O NUMBOOL converte qualquer valor diferente de zero em 1, o que é perfeito para a semântica "este recurso está ativo?" — não nos importamos com o contador de CPU bruto, apenas que a instância esteja em execução.factor: um fator de multiplicação para conversão de unidades. Por exemplo, oceilometer_image_sizeusa 1/1048576 para converter bytes brutos em MiB.metadata: rótulos adicionais do Prometheus que acompanham os dados tarifados para fins informativos (por exemplo,container_format,disk_formatpara imagens).extra_args: argumentos específicos de back-end. Oaggregation_method: maxinstrui o coletor do Prometheus a usar o valor máximo em cada período de coleta.
Como o coletor do CloudKitty se comunica diretamente com o Prometheus, a tarifação de qualquer métrica disponível é simples: adicione uma nova entrada ao metrics.yaml com os rótulos e a unidade adequados, e o CloudKitty começará a coletá-la e tarifá-la no próximo ciclo de processamento.
Inspecione os dados brutos
Embora o comando openstack rating summary get exiba os totais agregados, às vezes é preciso analisar os dados mais a fundo. Seja para verificar a aplicação correta das regras de tarifação, depurar uma métrica ausente ou entender o que o CloudKitty armazena, o comando openstack rating dataframes get permite inspecionar os pontos de dados tarifados individuais no Loki.
Pense nos resumos como o extrato mensal e nos dataframes como os itens individuais do recibo.
Para recuperar os dataframes tarifados brutos de uma janela de tempo específica:
openstack rating dataframes get --begin 2026-03-01T00:00:00Z --end 2026-03-01T01:00:00ZCada linha do resultado representa um único ponto de dados tarifado para um período de coleta:
| Begin | Término | Tipo de métrica | Unidade | Quantidade | Preço | Agrupar por | Metadados |
|---|---|---|---|---|---|---|---|
2026-03-01T00:00:00Z |
2026-03-01T01:00:00Z |
ceilometer_cpu |
instance |
1 |
0.05 |
flavor_id=<uuid>, flavor_name=m1.large, project=<project_uuid>, resource=<vm_uuid> |
|
2026-03-01T00:00:00Z |
2026-03-01T01:00:00Z |
ceilometer_cpu |
instance |
1 |
0.01 |
flavor_id=<uuid>, flavor_name=m1.tiny, project=<project_uuid>, resource=<vm_uuid> |
Vamos detalhar o que cada coluna mostra:
- Início/término: o período de coleta que este ponto de dados abrange. Por padrão, o CloudKitty coleta dados de hora em hora, por isso você verá janelas de uma hora.
- Tipo de métrica: o nome da métrica no
metrics.yaml(por exemplo,ceilometer_cpu,ceilometer_ip_floating). - Unidade: a unidade de cobrança, conforme definido no
metrics.yaml. - Quantidade: a quantidade bruta após qualquer mutação ou transformação de fator. Para
ceilometer_cpucomNUMBOOL, o valor será 1 se a instância estiver em execução. - Preço: o valor tarifado após a aplicação das suas regras de hashmap. Aqui você pode verificar se o mapeamento correto foi aplicado. Se você definir
m1.largecomo 0.05, esse valor deve aparecer aqui. - Agrupar por: valores de rótulo dos campos
groupbyemmetrics.yaml. É assim que o CloudKitty desagrega os dados, o que permite detalhar recursos, flavors ou projetos específicos. - Metadados: quaisquer rótulos adicionais transferidos pelo campo de metadados em
metrics.yaml.
Isso oferece aos operadores uma ferramenta concreta para rastrear todo o caminho desde a métrica bruta até o preço final, tornando o comportamento do CloudKitty transparente e depurável em todas as etapas.
Tudo pronto para contabilizar os custos?
Quer o seu objetivo seja a recuperação rigorosa de custos de departamentos internos ou a visibilidade transparente do consumo de recursos, o CloudKitty fornece os dados estruturados e confiáveis necessários para isso. Ele preenche a lacuna entre a telemetria bruta do OpenStack e o middleware de FinOps empresarial.
Os dias de tratar a nuvem privada como um buffet livre acabaram. Temos a satisfação de trazer esse recurso nativo e altamente personalizável para o ecossistema do OpenStack Services on OpenShift na versão 5. Chegou a hora de parar com as suposições e começar a tarifar.
Comece agora mesmo
Explore a documentação oficial para configurar e gerenciar o CloudKitty no seu ambiente:
- Habilite a tarifação de nuvem em um ambiente do OpenStack Services on OpenShift
- Use o serviço de tarifação
Veja em ação
Confira a demonstração em vídeo para ver como um administrador pode configurar facilmente regras de tarifação baseadas em flavor e extrair o primeiro detalhamento mensal.
Este vídeo é um corte selecionado de duas sessões distintas de terminal. Se você deseja uma análise mais detalhada e interativa dos comandos brutos executados internamente, explore as gravações completas e sem cortes do Asciinema aqui:
- https://asciinema.org/a/ofDLdVKxHfMAsaNM: implante o CloudKitty e crie as regras de tarifação baseadas em flavor.
- https://asciinema.org/a/P11NR7CEqfiewF4R: verifique os dataframes de chargeback e extraia o resumo mensal.
Teste de produto
Red Hat OpenShift Container Platform | Teste de solução
Sobre os autores
Juan Larriba is a software engineer specializing in cloud infrastructure and OpenStack observability. He is a contributor to the OpenStack Kubernetes Operators ecosystem, where he works on the Telemetry Operator — a project that brings together metrics collection, alarming, and rating services like CloudKitty into cloud-native Kubernetes deployments. His work focuses on bridging traditional OpenStack telemetry components with modern container-native architectures, helping operators gain visibility and cost insight into their cloud workloads. Juan is passionate about open source collaboration and has contributed to projects spanning Ceilometer, Aodh, and CloudKitty, with a focus on making rating and chargeback capabilities more accessible in production OpenStack environments.
Mais como este
OpenShift: integração consistente para a empresa híbrida
Red Hat OpenShift 4.21: escalabilidade inteligente, migração mais rápida e eficiência impulsionada por IA
Avoiding Failure In Distributed Databases | Code Comments
Challenges In Solutions Engineering | Code Comments
Navegue por canal

Automação
Últimas novidades em automação de TI para empresas de tecnologia, equipes e ambientes

Inteligência artificial
Descubra as atualizações nas plataformas que proporcionam aos clientes executar suas cargas de trabalho de IA em qualquer ambiente

Nuvem híbrida aberta
Veja como construímos um futuro mais flexível com a nuvem híbrida

Segurança
Veja as últimas novidades sobre como reduzimos riscos em ambientes e tecnologias

Edge computing
Saiba quais são as atualizações nas plataformas que simplificam as operações na borda

Infraestrutura
Saiba o que há de mais recente na plataforma Linux empresarial líder mundial

Aplicações
Conheça nossas soluções desenvolvidas para ajudar você a superar os desafios mais complexos de aplicações
Virtualização
O futuro da virtualização empresarial para suas cargas de trabalho on-premise ou na nuvem