En un artículo anterior, nos centramos en la función que convierte a los modelos de lenguaje de gran tamaño (LLM) de herramientas de uso general en instrumentos de investigación mediante la personalización específica de un área. Los equipos de investigación utilizan los modelos perfeccionados para codificar la experiencia en el área, la investigación institucional y los patrones de razonamiento en sistemas que agilizan el descubrimiento, en lugar de simplemente asistirlo.
Sin embargo, los modelos personalizados son solo la mitad de la ecuación. Para que esos modelos sean útiles a escala institucional, necesitan una plataforma que te permita entrenarlos, ponerlos en servicio, controlar su acceso e integrarlos en el entorno informático de investigación más amplio. Esa plataforma debe conectar los mundos en los que ya vives: los clústeres tradicionales de informática de alto rendimiento (HPC) que ejecutan el gestor de cargas de trabajo Slurm y el ecosistema de inteligencia artificial nativo de la nube, que se expande rápidamente y se basa en Kubernetes.
En este artículo, analizamos cómo se combina esa plataforma: la arquitectura que permite que las instituciones de investigación unifiquen la HPC y las cargas de trabajo nativas de la nube, pongan en marcha modelos personalizados como servicios compartidos y ofrezcan funciones de inteligencia artificial generativa en organizaciones enteras sin sacrificar el control, la capacidad de reproducción ni el control de costos.
La arquitectura de la plataforma: Cómo encajan las piezas
Una vez establecido el caso de la personalización, veamos cómo se combina la plataforma completa. La arquitectura es generalizada y se aplica ya sea que la diseñes en una universidad de investigación, un centro de investigación y desarrollo financiado con fondos federales, un hospital universitario, una empresa de energía o un grupo de investigación de servicios financieros. Los componentes son los mismos, pero la configuración de cada dominio es diferente.
La base es Red Hat OpenShift, una distribución de Kubernetes que ofrece la orquestación de contenedores, el control del espacio de nombres, el control de acceso basado en funciones (RBAC), la integración del almacenamiento persistente y las herramientas operativas que los ingenieros de plataformas necesitan para ejecutar una infraestructura de inteligencia artificial compartida a escala institucional.
Sobre OpenShift, Red Hat OpenShift AI ofrece funciones específicas de inteligencia artificial, como la puesta en servicio y personalización de modelos, la orquestación de canales, los entornos de notebook para los científicos de datos y la observabilidad para las cargas de trabajo de inteligencia artificial. OpenShift AI transforma la plataforma base de Kubernetes en un entorno en el que puedes entrenar, perfeccionar, evaluar, implementar y supervisar los modelos a través de una interfaz de autoservicio controlada, sin que cada equipo necesite gestionar su propia infraestructura de machine learning (aprendizaje automático).
El motor de inferencia es vLLM, que se ofrece a través de la capa de servicio de modelos de OpenShift AI. El procesamiento por lotes continuo y los mecanismos de atención con uso eficiente de la memoria de vLLM lo convierten en la opción ideal para los entornos de inferencia compartida en los que varios equipos de investigación utilizan los endpoints de los modelos simultáneamente. En un entorno con recursos limitados —como la mayoría de las instituciones de investigación— la diferencia entre una inferencia eficiente y una ineficiente representa una parte importante del presupuesto de la GPU.
La capa de hardware de Red Hat AI Factory with NVIDIA es donde la colaboración entre Red Hat y NVIDIA cobra relevancia directa. Red Hat AI Factory with NVIDIA combina el hardware de GPU de NVIDIA y el marco de NVIDIA Inference Microservices (NIM) con las funciones de orquestación y control de OpenShift AI. Los contenedores NIM empaquetan configuraciones de modelos validadas y optimizadas que están listas para ponerse en servicio en el hardware de NVIDIA. Además, como se ejecutan en OpenShift, heredan el control del espacio de nombres, el RBAC y el stack de observabilidad de la plataforma.
Para las instituciones de investigación que adquieren infraestructura de GPU de NVIDIA, la arquitectura de referencia de Red Hat AI Factory with NVIDIA ofrece un camino validado y compatible desde el hardware hasta la ejecución de los servicios de inferencia, lo que ayuda a evitar meses de trabajo de integración. El catálogo de NIM de NVIDIA incluye modelos base de las principales familias de modelos, mientras que el canal de personalización de OpenShift AI amplía esas bases con el perfeccionamiento específico del dominio. La combinación es un camino práctico desde "tenemos GPU" hasta "tenemos un modelo clínico perfeccionado al servicio de nuestros investigadores".
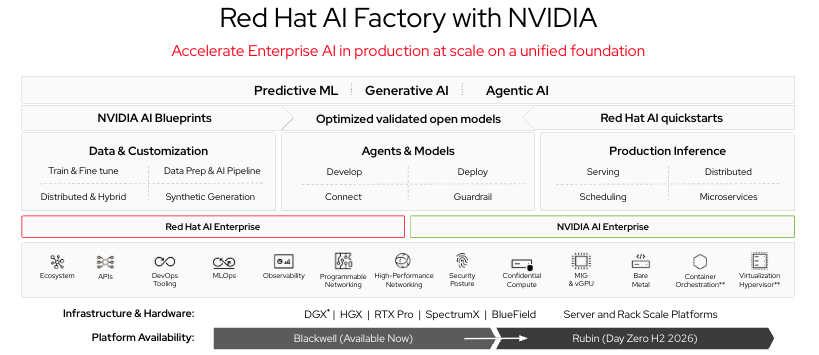
Figura 1: Red Hat AI Factory with NVIDIA
Conexión entre HPC y tecnología nativa de la nube: El operador Slinky
Slurm potencia muchas de las supercomputadoras más importantes del mundo y es la interfaz estándar para el envío de trabajos de computación de alto rendimiento (HPC) en las instituciones de investigación. Los puntos fuertes de Slurm son reales, e incluyen reservas de GPU exclusivas, rendimiento predecible, colas de prioridad maduras e integración profunda con sistemas de archivos paralelos y cargas de trabajo de estilo de interfaz de paso de mensajes (MPI). La mayoría de los usuarios de HPC de las instituciones de investigación conocen Slurm, y sus flujos de trabajo generalmente están escritos para Slurm.
El desafío siempre ha sido la brecha entre el mundo de Slurm y el de Kubernetes: dos planificadores, dos sistemas de contabilidad de recursos, dos formas de solicitar una GPU y dos equipos operativos. Los artefactos de datos se trasladan de un entorno a otro de forma manual, y la capacidad de la GPU suele permanecer inactiva en el clúster de HPC durante los períodos de poco uso, mientras el entorno de Kubernetes pone los trabajos en cola.
El operador Slinky soluciona esta brecha. Como se analiza en este artículo sobre la ejecución de las cargas de trabajo de Slurm en OpenShift, Slinky es un operador de Kubernetes que implementa y gestiona los componentes de Slurm, como `slurmctld` y `slurmd`, como cargas de trabajo en contenedores dentro de OpenShift. Esto automatiza la implementación, el escalado y la gestión del ciclo de vida del clúster de Slurm para que pueda coexistir con las cargas de trabajo nativas de Kubernetes en el mismo hardware.
Lo que esto significa en la práctica para los ingenieros de plataformas de investigación:
- Planificación de recursos unificada: Los trabajos por lotes de Slurm y las cargas de trabajo de inteligencia artificial nativas de Kubernetes comparten el mismo grupo de GPU. La capacidad inactiva entre los trabajos de simulación de gran tamaño se puede asignar a las cargas de trabajo de inferencia o ajuste fino sin intervención manual ni reasignación de hardware.
- Flujos de trabajo de investigación preservados: Los investigadores de HPC que envían trabajos a través de `sbatch` no tienen que cambiar su flujo de trabajo. La interfaz de Slurm que conocen todavía está allí, pero ahora también se ejecuta dentro de OpenShift con toda la observabilidad, la gestión del ciclo de vida y el control que ofrece Kubernetes.
- Entornos reproducibles: Los trabajos de Slurm se ejecutan como contenedores, lo que significa que la imagen del contenedor define el entorno y no lo que esté instalado en el nodo de computación. Esto mejora considerablemente la reproducibilidad y simplifica la colaboración entre las instituciones que desean compartir flujos de trabajo.
- Superficie operativa única: Los ingenieros de plataformas mantienen un clúster, un stack de observabilidad y un modelo de control de acceso basado en roles (RBAC). Slinky no requiere ni crea una segunda infraestructura; incorpora la planificación de HPC en la plataforma que ya utilizas.
La adquisición de SchedMD, el principal desarrollador de Slurm, por parte de NVIDIA indica hacia dónde se dirige esta convergencia en el sector. Los límites entre la planificación de HPC, la orquestación de Kubernetes y la infraestructura de inteligencia artificial se están borrando deliberadamente. Slinky es la contribución de Red Hat a esa convergencia y ya está disponible para ejecutarse en producción.
Para una universidad de investigación que opera tanto un clúster de HPC para la ciencia computacional como un entorno de OpenShift para la investigación de la inteligencia artificial, Slinky ayuda a que estas dos inversiones funcionen como una sola.
Modelos como servicio (MaaS): El modelo de plataforma de inteligencia artificial compartida para instituciones de investigación
La convergencia de las plataformas resuelve el problema de la infraestructura, pero hay otro problema que es igualmente importante y se analiza menos: la mayoría de los equipos de investigación no incluyen ingenieros de infraestructura. Un equipo de informática clínica que diseña un chatbot para la equidad en la salud no quiere gestionar espacios de nombres de Kubernetes. Un laboratorio de genómica que necesita un modelo ajustado para la anotación de variantes no desea configurar implementaciones de vLLM. Un departamento de ciencias sociales computacionales que desea ejecutar análisis de documentos basados en modelos de lenguaje de gran tamaño (LLM) no desea escribir charts de Helm.
El modelo operativo que resuelve este problema es Models-as-a-Service (MaaS).
¿Qué es MaaS?
MaaS es un enfoque en el que los ingenieros de plataformas implementan, gestionan y operan modelos de inteligencia artificial como servicios compartidos, y los exponen a los usuarios a través de API. En el contexto de una institución de investigación, esto significa que el equipo de la plataforma informática de investigación opera el clúster de GPU, gestiona el ciclo de vida del modelo, se encarga de las versiones y las actualizaciones, y mantiene la infraestructura de servicio. Mientras tanto, los equipos de investigación consumen los endpoints del modelo como un servicio, de la misma manera que consumen una asignación de recursos informáticos o un montaje de almacenamiento.
Las implicaciones para la productividad de la investigación son significativas. Compara cómo es el flujo de trabajo actual frente a cómo es bajo un modelo de MaaS.
Hoy, sin MaaS
Un equipo de investigación necesita un modelo con ajuste fino para su proyecto. Pasan semanas configurando un entorno de GPU, instalando dependencias, configurando un marco de servicio y depurando problemas de infraestructura. Tu investigación real comienza cuando la infraestructura finalmente funciona, lo cual puede ocurrir meses después del inicio del proyecto. Al terminar, el modelo reside en la estación de trabajo de una persona o en una asignación de clúster temporal que se recupera.
Con MaaS en Red Hat OpenShift AI
El equipo de investigación aporta su conjunto de datos y los requisitos de su dominio al equipo de la plataforma. Trabajas con ingenieros de plataformas para configurar y ejecutar una tarea de ajuste fino a través de Training Hub en Red Hat OpenShift AI. El modelo resultante se ofrece como un endpoint de API controlado y con versiones en el clúster compartido. Otros equipos de investigación con necesidades similares pueden acceder al mismo endpoint. Cuando necesitas actualizar el modelo con datos nuevos, vuelves a ejecutar el pipeline de entrenamiento y promueves la nueva versión mediante el mismo proceso controlado.
El equipo de la plataforma se encarga de la infraestructura mientras el equipo de investigación se ocupa de la ciencia. Esta división del trabajo ayuda a escalar las capacidades de la inteligencia artificial en toda la institución.

Figura 2: Convergencia de HPC, cloud-native y Models-as-a-Service para la investigación científica
Para los ingenieros de plataformas, MaaS en Red Hat OpenShift AI (o "investigación como servicio", si prefieres) proporciona los controles operativos que necesitan: cuotas de recursos a nivel de espacio de nombres que evitan que un solo proyecto de investigación monopolice la capacidad de GPU, control de versiones de modelos mediante un registro, control de acceso basado en funciones (RBAC) que determina quién puede implementar y quién solo puede consumir, y observabilidad en todas las cargas de trabajo de servicio a través de un cuadro de mando unificado.
Para las instituciones de investigación con varios grupos (por ejemplo, una facultad de medicina, un departamento de biología computacional, una facultad de informática y un instituto de ciencia de datos que se ejecutan en la misma plataforma), MaaS permite que el equipo de la plataforma se adelante a la demanda sin aumentar el número de empleados de forma lineal con el número de proyectos.
Gravedad de los datos: Llevar la inteligencia artificial a donde reside la investigación
La investigación tiene un problema de gravedad de los datos. Los conjuntos de datos más valiosos (registros clínicos, secuencias genómicas, resultados de simulaciones) ya son grandes, están distribuidos y, a menudo, resultan inamovibles debido a costos, latencia o restricciones de gobernanza. Mover petabytes de datos a un endpoint de la nube es ineficiente y, a menudo, imposible.
La plataforma que analizamos aquí lleva la inteligencia artificial a los datos, y no al revés. Al ejecutar el entrenamiento, el ajuste fino y la inferencia de los modelos donde ya se encuentran los datos (en las instalaciones, en el laboratorio, en entornos de investigación seguros, etc.), puedes evitar el traslado innecesario de los datos y, al mismo tiempo, conservar el rendimiento y el cumplimiento normativo.
En última instancia, esto no es solo una optimización, es realmente un requisito arquitectónico. Cuanto más cerca esté el modelo de los datos, más rápido será el ciclo de iteración, menor será el costo y más práctico será poner en marcha la inteligencia artificial en los flujos de trabajo de investigación a gran escala.
Dónde se aplica esta arquitectura: Investigación en todos los sectores
Por supuesto, esta plataforma no es específica para la investigación académica. La arquitectura es aplicable a cualquier institución donde la experiencia en el área sea importante, el control de los datos limite la implementación en la nube y las cargas de trabajo de investigación abarquen todo el espectro, desde la HPC hasta la nube.
- Universidades de investigación y centros de investigación y desarrollo financiados con fondos federales (FFRDC): Las universidades y los centros de investigación y desarrollo financiados con fondos federales, como los laboratorios nacionales, suelen tener la infraestructura que aborda esta arquitectura: clústeres de HPC para la investigación con gran cantidad de simulaciones, la creciente demanda de inteligencia artificial nativa de la nube de los grupos de ciencia de datos y los equipos de ingeniería de plataformas que intentan prestar servicios a docenas de grupos de investigación con diferentes requisitos informáticos.
- Instituciones médicas y hospitales universitarios: La inteligencia artificial clínica es una de las áreas de inversión en investigación de más rápido crecimiento y una de las más exigentes en cuanto a la precisión del modelo, el control de los datos y los requisitos de seguridad. Los modelos de nube de uso general no suelen utilizarse debido a las obligaciones de privacidad de los datos de los pacientes. Estas organizaciones necesitan modelos con ajuste fino que se ejecuten en las instalaciones, con registros de auditoría y controles de acceso, a través de una plataforma institucional gobernada.
- Investigación en materia de defensa e inteligencia: Los FFRDC y los contratistas de defensa que operan en entornos clasificados o controlados comparten las mismas necesidades de control de datos que la investigación clínica, lo cual se ve agravado por los requisitos de clasificación que prohíben el uso de las API de la nube. Estos requieren la distribución de modelos en las instalaciones, el funcionamiento desconectado y modelos con ajuste fino que transporten información clasificada del área de manera interna.
- Servicios financieros e investigación cuantitativa: Los grupos de investigación en el sector de los servicios financieros (p. ej., la investigación cuantitativa, la creación de modelos de riesgo y el análisis normativo) trabajan con datos propietarios y se rigen por las restricciones normativas que limitan lo que se puede enviar a las API externas. Para ello, se necesitan modelos con ajuste fino, entrenados en investigaciones internas, disponibles en las instalaciones a través de MaaS y accesibles a través de API controladas que se integren a los flujos de trabajo de investigación actuales.
- Investigación en materia de energía e industria: Las empresas de investigación industrial, de servicios públicos y de petróleo y gas ejecutan cargas de trabajo de simulación que utilizan muchos recursos informáticos junto con canales de machine learning (ML) en crecimiento para la investigación de materiales, el mantenimiento predictivo y el análisis geofísico. Slinky es particularmente importante en este sector, ya que los flujos de trabajo de simulación basados en Slurm son estándar y el análisis basado en machine learning se requiere cada vez más después de esas simulaciones.
En todos estos contextos, el patrón de la arquitectura es uniforme: converge la HPC y la programación nativa de la nube, personaliza los modelos para la especificidad del dominio, los distribuye de manera eficiente a través de una plataforma MaaS compartida y controla el acceso a nivel institucional.
En resumen: Qué permite la plataforma
A modo de ejemplo, esto es lo que la arquitectura completa permite a una institución de investigación que la implementó:
Un investigador de genómica computacional envía un trabajo de solicitud de variantes a gran escala a través de Slurm, de la misma manera que ha enviado trabajos de HPC durante años. El operador de Slinky lo programa como una carga de trabajo en contenedores en OpenShift, en los mismos nodos de GPU que también prestan servicios a los endpoints de inferencia con ajuste fino. Cuando se completa la tarea, los resultados se almacenan en un almacén de objetos compartidos al que pueden acceder tanto los entornos de HPC como los de Kubernetes.
Un investigador de procesamiento de lenguaje natural (NLP) clínico de la facultad de medicina necesita un modelo con ajuste fino a partir de notas clínicas anónimas para una tarea de reconocimiento de entidades con nombre. Trabaja con el equipo de la plataforma para ejecutar un trabajo de ajuste fino de adaptación de bajo rango (LoRA) a través de Training Hub en OpenShift AI, utilizando un modelo base del catálogo de NVIDIA NIM. Se crea una versión del modelo resultante y se ofrece como un endpoint de MaaS. Otros 2 equipos de investigación con tareas de procesamiento de lenguaje natural (NLP) adyacentes comienzan a utilizar el mismo endpoint de inmediato, lo que reparte el costo del ajuste fino en toda la institución.
Un grupo de investigación sobre ciberseguridad en un Centro de Investigación y Desarrollo Financiado por el Gobierno Federal (FFRDC) necesita analizar informes de inteligencia sobre amenazas a gran escala con un LLM. Como sus datos tienen restricciones de confidencialidad que prohíben el uso de la API de nube, el modelo se ejecuta por completo en las instalaciones en su clúster de OpenShift. El modelo se ajustó en su conjunto de datos clasificados mediante la generación de datos sintéticos de InstructLab para aumentar su pequeño conjunto de datos etiquetados. Solo los espacios de nombres con los enlaces de RBAC adecuados pueden acceder al endpoint.
Un ingeniero de plataformas que gestiona todas estas cargas de trabajo en el mismo clúster ve un solo panel de observabilidad con el uso de la GPU en las cargas de trabajo de Slurm y Kubernetes, la latencia de la distribución del modelo por extremo, la profundidad de la cola de tareas de entrenamiento y el uso de la cuota de recursos por espacio de nombres. El programador unificado resuelve los conflictos de recursos entre las cargas de trabajo, no la intervención manual.
Cada una de estas capacidades está disponible hoy en Red Hat AI y OpenShift AI, se integra con el hardware de NVIDIA a través de Red Hat AI Factory con la arquitectura de referencia de NVIDIA y se extiende a los flujos de trabajo de HPC a través del operador Slinky.
Reflexiones finales
Los investigadores que impulsarán la próxima generación de descubrimientos utilizarán los LLM como herramienta principal y como parte central de su flujo de trabajo de investigación, no como un complemento de sus métodos actuales.
Lo que necesitan de la plataforma es una función que puedan utilizar sin tener que convertirse en ingenieros de infraestructura. Necesitan modelos con un ajuste fino que realmente conozcan su dominio, inferencias rápidas y confiables, flujos de trabajo de HPC que no requieran un cambio de contexto a un clúster diferente y acceso compartido a través de un servicio gobernado.
En conjunto, Red Hat OpenShift, Red Hat AI, NVIDIA y el operador Slinky pueden proporcionar esa plataforma.
Recurso
Introducción a la inteligencia artificial para las empresas: Guía para principiantes
Sobre los autores

I build real-world GenAI solutions for organizations that can’t afford to get it wrong.
My career spans national security, enterprise software, and next-generation AI platforms, with more than a decade focused on solving complex problems at the intersection of data, intelligence, and technology. I began in the intelligence community, serving eight years with the NSA and across the IC in intrusion defense, intelligence analysis, and mission-critical cyber operations. That experience in high-stakes security, pattern recognition, and adversarial thinking continues to shape how I approach GenAI strategy and deployment today.
Since then, I’ve led product and platform initiatives in digital ecosystems, advised startups, and worked across the data science landscape helping organizations move from experimentation to production. Much of my work focuses on making generative AI models more knowledgeable and reliable by grounding them in domain-specific data, mission context, and real operational constraints across national security, research, and healthcare.
Today, as an AI Solutions Advisor at Red Hat and IBM, I partner with government agencies, research institutions, and enterprises across North America to design scalable GenAI systems that work in the real world. The goal is never novelty — it’s better decisions, faster execution, and durable advantage.

O'Neill Joseph is a Sr AI Solutions Architect in Red Hat focused on specialized AI deployments, has over 20 experience in IT Infrastructure, from telecommunications to cloud native infrastructure with a Degree in Cybersecurity and IT Networking from University of Maryland.

Working with customers to build IT solutions for over 25 years, Wes has experience integrating various technologies and approaches to produce outcomes and achieve mission objectives. Serving highly regulated industries such as healthcare and defense, Wes understands how to approach IT challenges with a secure, compliant end state in mind.
At Red Hat, Wes focuses on helping customers build cloud-native platforms where they can run AI/ML workloads, integrate heterogeneous data and facilitate outcomes anywhere in the world.
Prior to joining Red Hat, Wes was the CTO at a small technology company in DC helping build solutions for a variety of government customers.
Wes has managed global engineering teams, built services to help customers scale their missions, and designed software solutions to meet the needs of growing organizations.
Más como éste
La paradoja agéntica y los argumentos a favor de la IA híbrida
Deja de administrar el pasado y comienza a forjar el futuro de TI
Technically Speaking | Build a production-ready AI toolbox
Technically Speaking | Platform engineering for AI agents
Navegar por canal

Automatización
Las últimas novedades en la automatización de la TI para los equipos, la tecnología y los entornos

Inteligencia artificial
Descubra las actualizaciones en las plataformas que permiten a los clientes ejecutar cargas de trabajo de inteligecia artificial en cualquier lugar

Nube híbrida abierta
Vea como construimos un futuro flexible con la nube híbrida

Seguridad
Vea las últimas novedades sobre cómo reducimos los riesgos en entornos y tecnologías

Edge computing
Conozca las actualizaciones en las plataformas que simplifican las operaciones en el edge

Infraestructura
Vea las últimas novedades sobre la plataforma Linux empresarial líder en el mundo

Aplicaciones
Conozca nuestras soluciones para abordar los desafíos más complejos de las aplicaciones
Virtualización
El futuro de la virtualización empresarial para tus cargas de trabajo locales o en la nube