-
Products & documentation Red Hat AI
A platform of products and services for the development and deployment of AI across the hybrid cloud.
Red Hat AI Enterprise
Build, develop, and deploy AI-powered applications across the hybrid cloud.
Red Hat AI Inference
Optimize model performance with an integrated stack for fast, consistent, and cost-effective inference at scale.
Red Hat Enterprise Linux AI
Develop, test, and run generative AI models to power enterprise applications.
Red Hat OpenShift AI
Build and deploy AI-enabled applications and models at scale across hybrid environments.
-
Learn Basics
-
AI partners
Why you should care about AI inference
Simply put, there’s no AI without inference.
Inference is at the core of generative AI. But when big models have to execute even bigger strategies, things can get complicated.
That’s why we’re breaking down the challenges and opportunities that come with AI inference—from model optimization with vLLM to the latest open source, distributed frameworks like llm-d.
Why is inference so important?
Inference is the final step in a long and complex machine learning process, when a model delivers the desired output.
Most importantly, it’s a necessary function for AI to be successful.
That’s why the hardware and software that support your inference capabilities can make or break your AI strategy.

What’s holding you back from scaling?
Inference gets a lot of pressure from models that keep growing bigger. As models get more complex, inference becomes slower.
For inference to be successful, AI models need to do a lot of math in a short period of time. So, factors like model size, high user volume, and latency can all limit performance.
When models require more data and more memory, hardware and accelerators struggle to keep up.
66%
AI computing resources expected to be consumed by inference in 2026, up from 33% in 2023 and 50% in 2025.1
So, how do you make inference better?
When you optimize inference, AI models can run faster and smarter.
Optimization methods include processing GPUs more efficiently, speculative decoding, sparsity, compressing models with quantization techniques, and distributed inference.
Tools like LLM Compressor use the latest model compression research to make LLMs smaller, more energy efficient, and faster. This reduces hardware requirements and improves efficiency—without sacrificing accuracy.
Optimizations like these help AI inference stay cost effective, so it can scale with your teams as you go.
>99%
Accuracy preserved during optimizations with LLM Compressor.2

2x
More computational throughput using compressed models, without sacrificing accuracy.3
50%
Cost savings without sacrificing performance when optimizing models with LLM Compressor.4

How does vLLM optimize inference?
Optimizing models is only half the battle. You also need a high-performing inference engine. That’s where vLLM can help.
Traditional LLM memory management systems don’t organize memory in the most efficient way, which makes LLMs move slowly. vLLM uses PagedAttention, a memory management technique that identifies repetitive key values to reduce extra work for the LLM.
This allows vLLM to make better use of GPU memory and speed up generative AI inference. It maximizes throughput (tokens processed per second) to serve many users at once.
Using accelerators more efficiently means models can do more math in less time, so teams can serve more users and agents faster.
50%
Parameters reduced when using sparsity structure.5

2.1x
Inference latency decreased with speculative decoding techniques.6
24x
Higher throughput performance with vLLM compared to competitors.7
Why is vLLM so popular?
vLLM has helped address the core issues around efficient GPU utilization, unlocking lower cost per token, stable latency at scale, and doing it with an open, portable deployment approach.
That’s why the vLLM community is active and vibrant. Contributions come from passionate groups like Hugging Face, UC Berkeley, NVIDIA, Red Hat, and many more. The community consistently challenges and improves the software in the open source project.
With Day 0 support for all major models and accelerators, its accessibility is attractive to both industries and academia.
10K+
vLLM GitHub commits*—an increase of over 200%—in 2025.
The vLLM community today
500K+
GPUs deployed 24/78
200+
Different accelerator types9
500+
Supported model architectures9
2.2K+
Where does distributed inference fit in?
Distributed inference allows AI models to divide the labor of inference across a group of interconnected devices.
When a model can fulfill different requests—all at the same time—it significantly reduces the necessary hardware and increases inference efficiency.
Distributed inference uses techniques like tensor parallelism, intelligent inference scheduling, and disaggregation. When layered with vLLM, inference becomes a very efficient, multitasking machine.
This helps inference stay observable, scalable, and consistent.
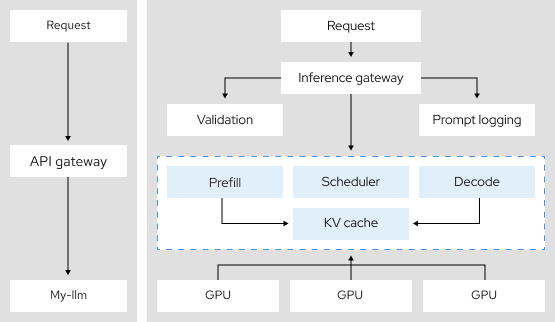
3.9x
More token throughput using tensor parallelism, a distributed inference architecture.10
Is there an open source community for that?
Yes, it’s called llm-d.
llm-d is an open source framework that gives developers a blueprint for building distributed inference at scale.
Its modular architecture supports the complex resource demands of sophisticated LLMs and replaces manual, fragmented processes with integrated well-lit paths, speeding up the time from pilot to production.
llm-d brings inference to Kubernetes, providing a standardized tool-kit that helps apply distributed inference to your unique enterprise use cases.
2x
Baseline of Queries Per Second (QPS) sustained by llm-d.11
More AI resources
Red Hat AI Inference
Move your LLMs from code to production faster.
Built on vLLM, our enterprise-grade inference engine enables faster inference without sacrificing performance.
Scale across the hybrid cloud with your preferred and optimized gen AI model, on any AI accelerator, in any cloud environment.

Cited sources
[1] “Why AI’s Next Phase Will Likely Demand More Computing Power—Not Less .”The Wall Street Journal, 22 Jan. 2026.
[2] Kurtić, Eldar, et al. “We ran over half a million evaluations on quantized LLMs—here's what we found.” Red Hat Developer Blog, 17 Oct. 2024.
[3] Condado, Carlos. “A strategic approach to AI inference performance.” Red Hat Blog, 15 Sept. 2025.
[4] Zelenović, Saša. “Unleash the full potential of LLMs: Optimize for performance with vLLM.”Red Hat Blog, 27 Feb. 2025.
[5] Kurtić, Eldar, et al. “2:4 Sparse Llama: Smaller models for efficient GPU inference.” Red Hat Developer Blog, 28 Feb, 2025.
[6] Marques, Alexandre, et al. “Fly Eagle(3) fly: Faster inference with vLLM & speculative decoding.”Red Hat Developer Blog, 1 July 2025.
[7] Kwon, Woosuk, et al. “vLLM: Easy, Fast, and Cheap LLM Serving with PagedAttention.” vLLM Blog, 20 June 2023.
[8] Goin, Michael. “[vLLM Office Hours #38] vLLM 2025 Retrospective & 2026 Roadmap - December 18, 2025.” YouTube, Dec. 8, 2025.
[9] Kwon, Woosuk. “Today, vLLM supports 500+ model architectures, runs on 200+ accelerator types, and powers inference at global scale.” X, Jan. 26, 2026.
[10] Goin, Michael. “Distributed inference with vLLM.” Red Hat Developer, 6 Feb. 2025.
[11] Shaw, Robert. “llm-d: Kubernetes-native distributed inferencing.” Red Hat Developers, 20 May, 2025.