A medida que la inteligencia artificial se convierte en un motor de la competitividad nacional, el concepto de inteligencia artificial soberana (la capacidad de operar sistemas de inteligencia artificial sin influencia externa) es cada vez más relevante, pero el camino hacia la adopción está lleno de desafíos. Una encuesta reciente a más de 900 líderes de TI e ingenieros de inteligencia artificial sobre la adopción de la inteligencia artificial pone de manifiesto una importante "brecha de valor" que demuestra que, a pesar del gran entusiasmo (72 %), solo el 7 % de las empresas de Europa, Oriente Medio y África (EMEA) obtienen resultados.
La encuesta destaca que la privacidad de los datos y los silos de infraestructura paralizan las iniciativas de desarrollo de la inteligencia artificial. Como resultado, la inteligencia artificial soberana pasó rápidamente de ser un "desafío de la nube" teórico a una necesidad práctica. Al reducir los riesgos específicos identificados en la encuesta de Red Hat, la inteligencia artificial soberana permite que las empresas reguladas pasen con confianza de la fase piloto a la producción sin comprometer:
- El cumplimiento normativo: El cumplimiento de normas estrictas, como el Reglamento General de Protección de Datos (RGPD), la Ley de inteligencia artificial de la Unión Europea y las leyes de residencia de datos que exigen que los datos de los ciudadanos permanezcan dentro de ciertos límites.
- La resistencia operativa: La capacidad de continuar con las operaciones durante la inestabilidad geopolítica o la desconexión de internet global.
- La autonomía estratégica: Las empresas evitan depender de un solo proveedor y mantienen el control total sobre la propiedad intelectual, como los modelos y los pesos, que se genera a partir de los datos confidenciales.
Red Hat OpenShift AI proporciona una base para esta soberanía, ya que permite que las empresas diseñen una fábrica de inteligencia artificial aislada y, al mismo tiempo, mantengan el control absoluto sobre la seguridad, los datos, los modelos y los resultados
En este artículo, analizamos ejemplos específicos de los desafíos de inteligencia artificial soberana que enfrentan nuestros clientes, resumimos los temas principales que deben abordarse y proponemos una solución para estos problemas
Historia de uno de nuestros usuarios: El dilema de la "independencia de la inteligencia artificial"
Protagonista: Dra. Aris (un perfil compuesto basado en los desafíos reales de los clientes) es la directora de datos del Ministerio de Salud de una nación europea mediana.
El desafío: El Ministerio posee una mina de oro de datos: décadas de registros anónimos de pacientes, secuencias genómicas e historial epidemiológico local. El objetivo de la Dra. Aris es diseñar un "LLM nacional de salud" para ayudar a los médicos a diagnosticar enfermedades raras específicas de su población.
Lo más importante es que el Ministerio enfrenta un problema de "inteligencia artificial en las sombras". Los investigadores, frustrados, suben en secreto fragmentos anónimos a los LLM públicos para llevar a cabo su trabajo, lo cual corre el riesgo de que se filtren datos. Necesitan una plataforma interna totalmente segura y aprobada que sea tan fácil de usar como la nube pública.
El problema:
- La nube trampa: Los principales proveedores de inteligencia artificial que ofrecen Modelos como servicio (MaaS) requieren que los datos confidenciales se carguen en las nubes públicas de Estados Unidos. Esto puede infringir el Reglamento General de Protección de Datos (RGPD), las leyes de residencia de datos y los protocolos de seguridad nacional.
- La pesadilla del proyecto DIY: La Dra. Aris intenta diseñar la plataforma desde cero. Su equipo se ve paralizado rápidamente por el caos operativo que implica arbitrar el acceso al clúster de 500 GPU, lo que genera una disputa constante por los recursos, en la que los experimentos más importantes tienen que esperar indefinidamente mientras el hardware reservado permanece inactivo.
La solución: El Ministerio diseña una plataforma de inteligencia artificial soberana sobre OpenShift AI y también utiliza Kubeflow y Feast.
- El cambio: En lugar de depender de las API propietarias de la nube, el equipo de Aris diseña una "fábrica de modelos" en su propia infraestructura protegida y aislada. OpenShift AI, que incluye elementos de Kubeflow, extrae el hardware del clúster de la GPU, lo que permite que el equipo entrene modelos de gran tamaño sin enviar un solo byte al otro lado de la frontera. Feast ayuda a centralizar la gestión de las funciones en el entrenamiento y la inferencia para que las características que se incorporan a los modelos se definan de manera uniforme, lo que permite el control y la trazabilidad.
- Resultado: Un analista de datos simplemente envía una solicitud de entrenamiento, y el sistema activa automáticamente un clúster distribuido, recupera las características de Feast, entrena el modelo y lo elimina, todo dentro del centro de datos nacional aislado. La Dra. Aris logra la "autonomía de la inteligencia artificial" utilizando una plataforma de inteligencia artificial escalable y desconectada en los términos propios de su país.
Los tres pilares de la inteligencia artificial soberana
Para pasar de una "colonia digital" (una nación o comunidad que depende tanto de la infraestructura tecnológica extranjera que pierde el control sobre su propia economía digital, datos y desarrollo futuro) a la "soberanía digital", una nación debe controlar tres capas del stack de tecnología de inteligencia artificial.
Soberanía técnica (la base)
Principio: La soberanía exige una cadena de custodia transparente y resistencia contra el uso de armas en la cadena de suministro. Al adoptar una capa de plataforma que no depende del hardware, los países pueden optimizar el progreso de la inteligencia artificial a través de una estrategia de varios proveedores, por lo que su autonomía estratégica se conserva independientemente de los cambios en la cadena de suministro global. La plataforma soberana debe separar el software del hardware y combinar la propiedad estricta de la infraestructura con la flexibilidad para adaptarse a la disponibilidad del mercado. Al adherirse a los estándares open source, las funciones de inteligencia artificial de una empresa se pueden inspeccionar, auditar y mantener independientemente de la hoja de ruta de un solo proveedor o del monopolio de hardware, lo cual conserva la autoridad absoluta sobre la continuidad del servicio.
Validación: La encuesta de Red Hat AI confirma que el 92 % de los líderes de TI considera que la tecnología de open source empresarial es fundamental para su estrategia de inteligencia artificial. Ofrece la uniformidad y la transparencia necesarias para controlar la cadena de suministro de la inteligencia artificial.
Soberanía de los datos (el recurso)
Principio: La gravedad de los datos es absoluta. Los datos confidenciales deben residir en medios de almacenamiento ubicados físicamente dentro del perímetro soberano y sujetos únicamente a las leyes locales. El desafío consiste en proporcionar a los analistas de datos la facilidad de selección y recuperación de datos que se encuentra en la nube, mientras se restringe físicamente el movimiento de datos a una red interna segura.
Soberanía operativa (el control)
Principio: El "plano de control" debe ser local. Los flujos de trabajo esenciales no pueden depender de una consola de software como servicio (SaaS) alojada en otro continente para gestionar los recursos informáticos o el acceso de los usuarios. Una plataforma soberana requiere un plano de control autónomo que administre la gestión de identidades y accesos (IAM) y la organización de los recursos por completo dentro del perímetro local.
Solución técnica
Nuestra solución se basa en una arquitectura en capas en la que Red Hat AI funciona como la plataforma soberana unificadora que organiza las funciones de entrenamiento de Kubeflow y la gestión de datos de Feast.
Esta solución se basa en los estándares open source, en especial Red Hat OpenShift, que proporciona una base de Kubernetes, y el proyecto Kubeflow. Gracias al uso de los elementos incluidos, como Model Registry, KServe, Pipeline and Training y Feast para la distribución de funciones, las empresas pueden mantener la propiedad total de su stack tecnológica. Esta transparencia permite que las empresas analicen el código en busca de puntos vulnerables y contribuyan directamente al plan del proyecto. En este caso, nos centraremos en la forma en que Kubeflow Train y Feast respaldan estos requisitos de soberanía.
El plan abierto para la soberanía de la inteligencia artificial: Red Hat AI
Para lograr una verdadera soberanía, la plataforma subyacente debe ser tan confiable como los datos que procesa. Red Hat AI ofrece una base reforzada y de nivel empresarial que aborda las necesidades específicas de las fábricas de inteligencia artificial autónomas y protegidas.
Red Hat AI proporciona independencia total de la infraestructura. Admite la implementación en servidores dedicados aislados, nubes privadas o partners de nube soberana de confianza. Esto permite que una empresa elija sus propios proveedores de hardware (por ejemplo, NVIDIA, Intel, AMD) y conserve la autoridad absoluta sobre la continuidad del servicio.
- Cadena de suministro de software de confianza: La soberanía comienza con la fuente. Red Hat AI ofrece un catálogo de herramientas de inteligencia artificial certificadas, analizadas en función de los puntos vulnerables y firmadas digitalmente para que el software que se ejecuta dentro de tu perímetro aislado no contenga puntos vulnerables conocidos, un requisito fundamental para la seguridad nacional.
- Plano de control de MLOps unificado: La plataforma consolida el stack tecnológico de inteligencia artificial fragmentada en una sola interfaz. Permite gestionar las dependencias complejas entre el sistema operativo (Red Hat Enterprise Linux), el hardware (GPU) y la capa de la aplicación (Kubeflow/Feast), de modo que los analistas de datos puedan centrarse en la creación de modelos en lugar de en la infraestructura.
- Abstracción de hardware escalable: Ya sea que se ejecute en racks de servidores dedicados (bare metal) o en una nube privada virtualizada, Red Hat AI extrae los recursos físicos. Utiliza operadores para ajustar y exponer automáticamente hardware especializado, como las GPU en una supercomputadora nacional, lo que permite una arquitectura multitenant sólida sin exponer la complejidad al usuario.
Una vez establecida esta base segura, confiamos en Red Hat OpenShift AI. OpenShift AI es una plataforma de inteligencia artificial distribuida que forma parte de la cartera de Red Hat AI y permite que las empresas diseñen, ajusten, implementen y gestionen modelos y aplicaciones de inteligencia artificial. Actúa como el sistema nervioso central que organiza tres funciones esenciales e integradas: un motor de entrenamiento de alto rendimiento, una capa de gestión de datos precisa y un marco optimizado de distribución de modelos.
Informática integrada: Entrenador de Kubeflow
Para una fábrica de inteligencia artificial soberana, depender de la infraestructura de nube pública no suele ser una opción debido a los estrictos requisitos de control y residencia de datos. Para mantener la soberanía real, debes poseer y operar el hardware. Sin embargo, esta independencia conlleva la responsabilidad de gestionarla de manera efectiva, lo que incluye la programación de tareas distribuidas complejas, la gestión de las fallas de los nodos y el uso eficiente de los recursos de supercomputación de gran valor.
Kubeflow Trainer (un elemento de OpenShift AI) soluciona esta paradoja operativa. Aporta facilidad de uso en la nube a tu infraestructura privada, ya que funciona como el motor de alto rendimiento que optimiza el entrenamiento distribuido en Kubernetes. Reemplaza los flujos de trabajo fragmentados con la API de TrainJob unificada, lo que permite que los analistas de datos ajusten los marcos como PyTorch y TensorFlow sin tener que volver a escribir código de infraestructura complejo.
- Simplificación: Al abstraer la infraestructura soberana subyacente, proporciona una interfaz única y uniforme para las tareas de entrenamiento distribuido masivo.
- Fiabilidad: Se basa en la API JobSet de Kubernetes y se asegura de que todo el grupo se gestione correctamente (programación de todo o nada) si falla un nodo en un clúster de entrenamiento distribuido. Esto ayuda a reducir el desperdicio de recursos, ya que las tareas de entrenamiento a gran escala se ejecutan por completo o se reinician sin problemas.
- Integración: Se integra directamente con Kueue (parte del stack de programación de OpenShift AI) para gestionar las colas y las cuotas de tareas, y asigna de forma dinámica los recursos de GPU del grupo de nodos subyacente de OpenShift para que los recursos informáticos nacionales se utilicen de la manera más eficiente.
Datos soberanos: Feast Feature Store
Si bien la verdadera soberanía de los datos requiere una estrategia de datos integral, se necesita un componente especializado para cerrar la brecha entre los datos sin procesar y el uso del modelo. Como complemento del motor informático, Feast funciona como la "memoria" de la solución. Feast se ejecuta sobre OpenShift y separa el modelo de la infraestructura de datos sin procesar para mejorar el cumplimiento normativo y la capacidad de reproducción.
Feast gestiona la corrección "en un momento determinado", de modo que el modelo se entrena exactamente con los datos disponibles en un momento histórico específico, lo que evita la filtración de datos y permite la auditoría completa.
- Tienda sin conexión (p. ej., MinIO): Se conecta de forma segura al almacén de objetos aislados y compatibles con S3 para gestionar datos históricos de alto rendimiento para el entrenamiento.
- Tienda en línea (p. ej., Redis): Gestiona las funciones de baja latencia para la inferencia, de modo que las decisiones inmediatas se toman dentro del perímetro soberano.
- Registro de funciones: Proporciona una única fuente de información para las definiciones de las funciones, de modo que todos los analistas de datos de la plataforma calculan de manera idéntica los indicadores importantes (p. ej., "Edad del paciente"), lo cual mantiene la integridad de la inteligencia soberana.
Completar el ciclo de vida: Distribución de modelos soberanos
La verdadera soberanía va más allá del entrenamiento y debe abarcar todo el ciclo de vida de MLOps. Una vez que Kubeflow entrena el modelo, se debe implementar para procesar los datos activos sin salir del perímetro seguro.
OpenShift AI cierra este ciclo con funciones integradas de distribución de modelos. Al aprovechar herramientas como KServe, vLLM y la compatibilidad con llm-d para la inferencia distribuida dentro de la plataforma, las empresas pueden implementar sus artefactos de modelos de inmediato en el mismo clúster soberano y aislado donde se entrenaron. Esto significa:
- La inferencia permanece interna: Con vLLM y llm-d, las consultas de los usuarios (por ejemplo, la solicitud de diagnóstico de un médico) y los flujos de datos en vivo se procesan de manera local, nunca a través de una API pública. Estas tecnologías optimizan el uso de la memoria de la GPU a través de PagedAttention y permiten que los modelos base masivos se fragmenten en varias GPU más pequeñas. Esta función optimizada permite que las empresas alojen la inteligencia artificial generativa (gen AI) de alto rendimiento en su propia infraestructura actual desde el punto de vista financiero y técnico, lo cual evita la necesidad de alquilar API de nube costosas y no soberanas.
- Soberanía unificada: Desde la aceleración del hardware hasta la supervisión de los modelos, todo el flujo (recopilación [Feast] → entrenamiento [Kubeflow] → prestación de servicios [OpenShift AI]) se ejecuta en una infraestructura soberana, bajo tu control.
Esta función conecta directamente la etapa de desarrollo con las etapas de integración y supervisión, lo que significa que una entidad regulada puede ejecutar una fábrica de inteligencia artificial integral y de primer nivel completamente interna.
Arquitectura
En el siguiente diagrama se muestra la función de OpenShift AI como capa de plataforma soberana, que concentra la organización, la seguridad y la gestión del hardware que se necesitan para ejecutar Kubeflow y Feast en un entorno aislado.
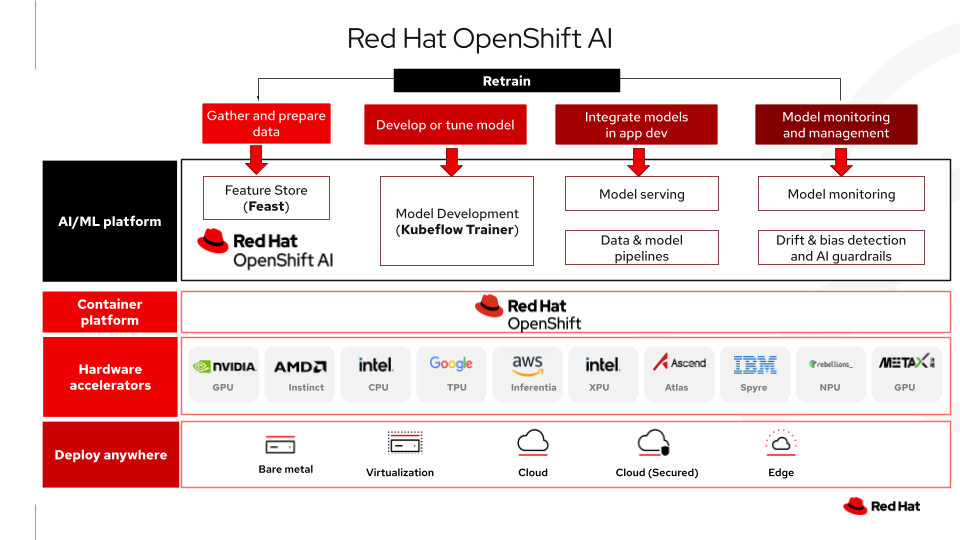
Conclusión
Para lograr una inteligencia artificial soberana, no solo se requiere hardware local, sino también una arquitectura de software que respete la importancia de los datos y la complejidad de los flujos de trabajo de inteligencia artificial modernos.
Al utilizar tecnologías como Kubeflow Trainer y Feast en OpenShift AI, las empresas pueden diseñar una fábrica de inteligencia artificial autónoma que sea:
- Reforzado por diseño: Los datos fluyen directamente dentro del perímetro protegido desde el almacenamiento hasta la informática, y se rigen por el control de acceso basado en funciones (RBAC) empresarial de Red Hat y el cumplimiento opcional de los Estándares Federales de Procesamiento de la Información (FIPS).
- Ajustable: Utiliza el potencial del entrenamiento distribuido en Kubernetes con la gestión automatizada del hardware que ofrecen OpenShift AI y Kubeflow Trainer.
- Reproducible: El uso de almacenes de características para respaldar el linaje de datos auditables.
Esta solución permite que los países y las empresas aprovechen el poder de la inteligencia artificial sin comprometer su independencia, lo que convierte el desafío de la soberanía en una ventaja competitiva.
¿Estás listo para diseñar tu propia fábrica de inteligencia artificial soberana?
- Aspectos técnicos: ¿Quieres ver el código que se encuentra detrás de la arquitectura? En el blog de Red Hat Developer encontrarás un tutorial técnico detallado: Mejorar la recuperación de RAG con Feast y Kubeflow Trainer.
- Descubre la plataforma: Si deseas obtener una descripción general, visita Red Hat OpenShift AI y descubre cómo nuestra plataforma empresarial permite que las empresas diseñen, implementen y gestionen las aplicaciones de inteligencia artificial protegidas y soberanas según sea necesario.
Recurso
La empresa adaptable: Motivos por los que la preparación para la inteligencia artificial implica prepararse para los cambios drásticos
Sobre el autor

Umberto Manganiello is a Staff Engineer at Red Hat since 2025. Prior to this, he spent over 15 years as a Principal Architect and Engineer in the Financial and Telecommunications sectors. He specializes in designing high-availability systems that operate at massive scale, leveraging deep expertise in Kubernetes, Kafka, and Cloud modernization. Currently, he applies this architectural discipline to the challenges of MLOps, with a focus on GenAI, OpenShift AI, and Kubeflow, blending cloud-native resilience with AI model training workflows.
Más como éste
Deja de administrar el pasado y comienza a forjar el futuro de TI
El próximo punto de inflexión de la IA: Transformando a los agentes en super usuarios empresariales
Technically Speaking | Build a production-ready AI toolbox
Technically Speaking | Platform engineering for AI agents
Navegar por canal

Automatización
Las últimas novedades en la automatización de la TI para los equipos, la tecnología y los entornos

Inteligencia artificial
Descubra las actualizaciones en las plataformas que permiten a los clientes ejecutar cargas de trabajo de inteligecia artificial en cualquier lugar

Nube híbrida abierta
Vea como construimos un futuro flexible con la nube híbrida

Seguridad
Vea las últimas novedades sobre cómo reducimos los riesgos en entornos y tecnologías

Edge computing
Conozca las actualizaciones en las plataformas que simplifican las operaciones en el edge

Infraestructura
Vea las últimas novedades sobre la plataforma Linux empresarial líder en el mundo

Aplicaciones
Conozca nuestras soluciones para abordar los desafíos más complejos de las aplicaciones
Virtualización
El futuro de la virtualización empresarial para tus cargas de trabajo locales o en la nube