Dans un article précédent, nous avons abordé la fonctionnalité qui transforme les grands modèles de langage (LLM) d’un outil polyvalent en un instrument de recherche grâce à une personnalisation spécifique à un domaine. Le réglage fin permet aux équipes de recherche d'encoder l'expertise métier, la recherche institutionnelle et les schémas de raisonnement dans des systèmes qui contribuent à accélérer les découvertes plutôt qu'à simplement les assister.
Toutefois, les modèles personnalisés ne constituent qu'une moitié de l'équation. Pour que ces modèles deviennent utiles à l'échelle institutionnelle, les équipes ont besoin d'une plateforme capable d'assurer l'entraînement, la distribution, le contrôle des accès et l'intégration de ces modèles dans l'environnement informatique de recherche global. Cette plateforme doit faire le lien entre les univers actuels des équipes de recherche : les clusters de calcul haute performance (HPC) traditionnels exécutant le gestionnaire de charge de travail Slurm et l'écosystème d'IA cloud-native en pleine expansion basé sur Kubernetes.
Dans cet article, nous étudions la structure de cette plateforme, à savoir l'architecture qui permet aux établissements de recherche de faire converger les charges de travail HPC et cloud-native, d'opérationnaliser les modèles personnalisés en tant que services partagés et de fournir des capacités d'IA générative à l'ensemble des organisations sans sacrifier la gouvernance, la reproductibilité ou le contrôle des coûts.
L'architecture de la plateforme : L'articulation des éléments
Le cas de la personnalisation étant établi, examinons comment l'ensemble de la plateforme s'articule. L'architecture est généralisée et s'applique aux universités de recherche, aux centres de recherche et développement financés par le gouvernement fédéral, aux centres hospitaliers universitaires, aux entreprises du secteur de l'énergie ou aux groupes de recherche en services financiers. Les composants restent identiques, mais la configuration diffère pour chaque domaine.
La base repose sur Red Hat OpenShift, une distribution Kubernetes qui fournit l'orchestration des conteneurs, la gouvernance des espaces de noms, le contrôle d'accès basé sur les rôles (RBAC), l'intégration du stockage persistant et les outils opérationnels dont le personnel d'ingénierie de plateforme a besoin pour exploiter une infrastructure d'IA partagée à l'échelle institutionnelle.
En plus d'OpenShift, Red Hat OpenShift AI fournit des capacités spécifiques à l'IA, notamment la mise à disposition de modèles, la personnalisation de modèles, l'orchestration de pipelines, les environnements de notebooks pour les data scientists et l'observabilité des charges de travail d'IA. OpenShift AI transforme la plateforme Kubernetes de base en un environnement où les personnes en charge de la recherche peuvent entraîner, régler, évaluer, déployer et surveiller des modèles via une interface gérée en libre-service, sans que chaque équipe doive gérer sa propre infrastructure d'apprentissage automatique (ML).
Le moteur d'inférence est vLLM, mis à disposition via la couche de distribution de modèles de OpenShift AI. Le traitement par lots continu et les mécanismes d'attention économes en mémoire de vLLM en font le choix approprié pour les environnements d'inférence partagés où plusieurs équipes de recherche utilisent simultanément des points de terminaison de modèles. Dans un environnement aux ressources limitées, ce qui est le cas de la plupart des établissements de recherche, la différence entre une inférence efficace et une inférence inefficace représente une part significative du budget GPU.
La couche matérielle Red Hat AI Factory with NVIDIA constitue le point de rencontre direct de la collaboration entre Red Hat et NVIDIA. Red Hat AI Factory with NVIDIA associe le matériel GPU de NVIDIA et le framework NVIDIA Inference Microservices (NIM) aux capacités d'orchestration et de gouvernance d’OpenShift AI. Les conteneurs NIM regroupent des configurations de modèles optimisées et validées prêtes pour le matériel NVIDIAL Leur exécution sur OpenShift signifie qu’ils héritent de la gouvernance des espaces de noms, du RBAC et de la pile d'observabilité de la plateforme.
Pour les établissements de recherche qui font l'acquisition d'une infrastructure GPU NVIDIA, l'architecture de référence Red Hat AI Factory with NVIDIA propose un parcours validé et pris en charge, du matériel jusqu'aux services d'inférence opérationnels, ce qui permet d'éviter des mois de travail d'intégration. Le catalogue NIM de NVIDIA comprend des modèles de base pour les principales familles de modèles, et le pipeline de personnalisation de OpenShift AI étend ces bases avec un réglage fin spécifique au domaine. Cette combinaison constitue un parcours concret pour passer de la simple possession de GPU à la mise à disposition d'un modèle clinique affiné pour les équipes de recherche.
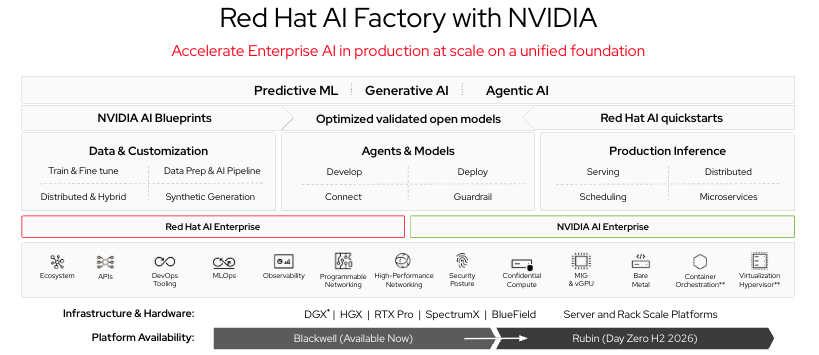
Figure 1 : Red Hat AI Factory with NVIDIA
Convergence du HPC et du cloud-native : L'opérateur Slinky
Slurm alimente de nombreux superordinateurs parmi les plus puissants au monde et constitue l'interface standard pour la soumission de tâches HPC dans les établissements de recherche. Les atouts de Slurm sont réels : réservations de GPU exclusives, performances prévisibles, gestion mature des files d'attente, intégration approfondie aux systèmes de fichiers parallèles et aux charges de travail de type MPI (Message Passing Interface). La majorité des personnes utilisant le HPC au sein des établissements de recherche connaissent Slurm, et leurs pipelines sont généralement écrits pour ce système.
Le défi réside depuis toujours dans l'écart entre l'univers Slurm et l'univers Kubernetes : deux ordonnanceurs, deux systèmes de comptabilité des ressources, deux manières de demander un GPU et deux équipes d'exploitation. Le transfert des artéfacts de données entre les environnements s'effectue manuellement, et la capacité GPU reste souvent inutilisée dans le cluster HPC lors des périodes de faible activité, pendant que l'environnement Kubernetes met les tâches en file d'attente.
L'opérateur Slinky permet de combler cet écart. Comme indiqué dans cet article sur l'exécution des charges de travail Slurm sur OpenShift, Slinky constitue un opérateur Kubernetes qui déploie et gère les composants Slurm (notamment slurmctld et slurmd) en tant que charges de travail conteneurisées dans OpenShift. Il automatise le déploiement, la mise à l'échelle et la gestion du cycle de vie du cluster Slurm, afin qu'il puisse coexister avec les charges de travail natives pour Kubernetes sur le même matériel.
Voici la signification concrète de ce projet pour les équipes d'ingénierie de plateforme de recherche :
- Ordonnancement unifié des ressources : Les tâches par lots Slurm et les charges de travail d'IA natives pour Kubernetes partagent le même pool de GPU. L'allocation de la capacité inactive entre des tâches de simulation volumineuses vers des charges de travail d'inférence ou de réglage fin s'effectue sans intervention manuelle ni réaffectation du matériel.
- Workflows de recherche préservés : Les équipes de recherche en HPC qui envoient des tâches via sbatch n'ont pas à modifier leur workflow. L'interface Slurm habituelle reste disponible, mais elle fonctionne désormais également dans OpenShift avec toutes les fonctionnalités d'observabilité, de gestion du cycle de vie et de gouvernance fournies par Kubernetes.
- Environnements reproductibles : Les tâches Slurm s'exécutent en tant que conteneurs, ce qui signifie que l'image de conteneur définit l'environnement, et non les éléments installés sur le nœud de calcul. Cette approche améliore considérablement la reproductibilité et simplifie la collaboration entre les établissements qui souhaitent partager des pipelines.
- Surface d'exploitation unique : Les équipes d'ingénierie de plateforme gèrent un cluster, une pile d'observabilité et un modèle RBAC. Slinky ne nécessite ni ne crée de seconde infrastructure ; il intègre l'ordonnancement HPC à la plateforme déjà utilisée.
L'acquisition de SchedMD par NVIDIA, le principal développeur de Slurm, indique la direction de cette convergence au niveau du secteur. Les frontières entre l’ordonnancement HPC, l’orchestration Kubernetes et l’infrastructure d’IA s’effacent délibérément. Slinky représente la contribution de Red Hat à cette convergence, désormais disponible pour une exécution en production.
Pour une université de recherche exploitant à la fois un cluster HPC pour les sciences informatiques et un environnement OpenShift pour la recherche sur l'IA, Slinky permet de faire converger ces deux investissements.
MaaS (Models-as-a-Service) : Le modèle de plateforme d'IA partagée pour les établissements de recherche
La convergence des plateformes résout le problème d'infrastructure, mais un autre défi tout aussi important subsiste : la plupart des équipes de recherche ne disposent pas d’ingénieurs infrastructure. Une équipe d'informatique clinique qui crée un agent conversationnel pour l'équité en matière de santé ne souhaite pas gérer les espaces de noms Kubernetes. Un laboratoire de génomique nécessitant un modèle affiné pour l'annotation de variantes ne souhaite pas configurer de déploiements vLLM. Un département de sciences sociales informatiques souhaitant effectuer des analyses de documents basées sur des LLM ne souhaite pas rédiger de charts Helm.
Le modèle d'exploitation qui résout ce problème est le MaaS (Models-as-a-Service).
Le MaaS, qu'est-ce que c'est ?
Le MaaS désigne une approche selon laquelle les équipes d'ingénierie de plateforme déploient, gèrent et exploitent des modèles d'IA en tant que services partagés, en les exposant aux personnes utilisatrices via des API. Dans le contexte d'un établissement de recherche, l'équipe chargée de la plateforme de recherche exploite le cluster GPU, gère le cycle de vie du modèle, assure la gestion des versions et des mises à jour, et maintient l'infrastructure de distribution. Les équipes de recherche utilisent les points de terminaison des modèles en tant que service, de la même manière qu'une allocation de calcul ou un montage de stockage.
Les répercussions sur la productivité de la recherche s'avèrent significatives. Comparez les caractéristiques actuelles du workflow avec celles offertes par le modèle MaaS.
Aujourd'hui, sans le MaaS
Une équipe de recherche nécessite un modèle affiné pour son projet. Le personnel passe plusieurs semaines à configurer un environnement GPU, à installer des dépendances, à configurer un framework de distribution et à résoudre des problèmes d'infrastructure. La recherche commence lorsque l'infrastructure fonctionne enfin, parfois plusieurs mois après le démarrage du projet. Une fois l'opération effectuée, le modèle réside sur le poste de travail d'un seul individu ou dans une allocation de cluster temporaire récupérée ultérieurement.
Avec le MaaS sur OpenShift AI
L'équipe de recherche transmet son ensemble de données et les exigences de son domaine à l'équipe de plateforme. Les équipes collaborent avec le personnel d'ingénierie de plateforme pour configurer et exécuter une tâche d'affinage via l’interface Training Hub sur OpenShift AI. Le modèle obtenu est mis à disposition sous forme de point de terminaison d'API régi et versionné sur le cluster partagé. D'autres équipes de recherche ayant des besoins similaires peuvent accéder au même point de terminaison. Lorsque le modèle nécessite une mise à jour avec de nouvelles données, le pipeline d'entraînement est réexécuté et la nouvelle version est promue via le même processus régi.
L'équipe de plateforme prend en charge l'infrastructure tandis que l'équipe de recherche gère les activités scientifiques. Cette division du travail favorise la mise à l'échelle des capacités d'IA au sein d'une institution.

Figure 2 : Convergence du HPC, du cloud-native et du Models-as-a-Service pour la recherche scientifique
Pour les équipes d'ingénierie de plateforme, le MaaS sur OpenShift AI (« Research-as-a-Service ») fournit les leviers d'exploitation nécessaires : des quotas de ressources au niveau de l'espace de noms empêchant un projet de recherche de monopoliser la capacité du GPU, la gestion des versions du modèle via un registre, un RBAC contrôlant les accès au déploiement ou à la consommation, ainsi qu'une observabilité de toutes les charges de travail via un tableau de bord unifié.
Pour les établissements de recherche disposant de plusieurs groupes (p. ex. une faculté de médecine, un département de biologie computationnelle, une faculté d'informatique et un institut de science des données) s'exécutant sur la même plateforme, le MaaS permet à l'équipe de plateforme d'anticiper la demande sans augmenter les effectifs de manière linéaire avec le nombre de projets.
Gravité des données : Intégration de l'IA au cœur de la recherche
La recherche se heurte à un problème de gravité des données. Les ensembles de données les plus précieux (dossiers cliniques, séquences génomiques, résultats de simulation) s'avèrent déjà volumineux, distribués et souvent immuables en raison de contraintes de coût, de latence ou de gouvernance. Le transfert de pétaoctets de données vers un point de terminaison cloud s'avère inefficace et constitue souvent une tâche impossible.
La plateforme présentée ici apporte l'IA aux données, et non l'inverse. En exécutant l'entraînement, l'affinage et l'inférence des modèles là où les données résident déjà (sur site, en laboratoire, dans des environnements de recherche sécurisés, etc.), vous évitez les déplacements de données inutiles tout en préservant les performances et la conformité.
En fin de compte, cela constitue une exigence architecturale plutôt qu'une simple optimisation. Plus le modèle se rapproche des données, plus la boucle d'itération s'accélère, plus les coûts diminuent et plus l'opérationnalisation de l'IA au sein des flux de travail de recherche à grande échelle devient pratique.
Cas d'application de cette architecture : Recherche multi-sectorielle
Cette plateforme ne se limite pas à la recherche universitaire. Cette architecture s'adapte à toute institution où l'expertise métier prime, où la gouvernance des données restreint le déploiement cloud-native et où les charges de travail de recherche couvrent tout le spectre, du HPC au cloud-native.
- Universités de recherche et centres de recherche et de développement financés par le gouvernement fédéral (FFRDC) : Les universités et les centres de recherche et de développement financés par le gouvernement fédéral, tels que les laboratoires nationaux, possèdent généralement l'infrastructure ciblée par cette architecture : des clusters HPC pour la recherche intensive en simulation, une demande croissante d'IA cloud-native de la part des groupes de science des données et des équipes d'ingénierie de plateforme s'efforçant de servir des dizaines de groupes de recherche aux besoins de calcul variés.
- Établissements médicaux et hôpitaux universitaires : L'IA clinique constitue l'un des domaines d'investissement en recherche à la croissance la plus soutenue et l'un des plus exigeants en matière de précision des modèles, de gouvernance des données et de sécurité. Les modèles cloud généralistes s'avèrent souvent inenvisageables en raison des obligations liées à la confidentialité des données des patients. Ces organisations requièrent des modèles affinés s'exécutant sur site, dotés de journaux d'audit et de contrôles d'accès, et mis à disposition via une plateforme institutionnelle régie.
- Recherche en matière de défense et de renseignement : Les centres FFRDC et les prestataires de la défense opérant dans des environnements classifiés ou contrôlés partagent les mêmes besoins en gouvernance des données que la recherche clinique, auxquels s'ajoutent des exigences de classification interdisant l'usage d'API cloud. Ces activités exigent une mise à disposition de modèles sur site, un fonctionnement en mode déconnecté et des modèles affinés intégrant des connaissances métier classifiées.
- Services financiers et recherche quantitative : Les groupes de recherche dans les services financiers (par exemple, recherche quantitative, modélisation des risques, analyse réglementaire) traitent des données propriétaires et opèrent sous des contraintes réglementaires limitant l'envoi de données vers des API externes. Ces entités nécessitent des modèles affinés entraînés sur la recherche interne, mis à disposition sur site via MaaS et accessibles par des API régies s'intégrant aux flux de travail de recherche existants.
- Recherche énergétique et industrielle : Les organisations des secteurs pétrolier, gazier, des services publics et de la recherche industrielle exécutent des charges de travail de simulation intensives parallèlement à des pipelines de ML en expansion pour la recherche sur les matériaux, la maintenance prédictive et l'analyse géophysique. Slinky s'avère particulièrement pertinent dans ce secteur, car les flux de travail de simulation basés sur Slurm constituent la norme et l'analyse pilotée par le ML est de plus en plus requise en aval de ces simulations.
Dans tous ces contextes, le modèle architectural reste constant : faire converger l'ordonnancement HPC et cloud-native, personnaliser les modèles selon les spécificités du domaine, les mettre à disposition efficacement via une plateforme MaaS partagée et régir l'accès au niveau institutionnel.
Synthèse : Capacités offertes par la plateforme
À titre d'exemple, voici les possibilités offertes par l'architecture complète pour un établissement de recherche l'ayant déployée :
Un chercheur en génomique informatique soumet une tâche de variant calling à grande échelle via Slurm, selon la méthode utilisée pour les tâches HPC depuis des années. L'opérateur Slinky planifie cette tâche en tant que charge de travail conteneurisée sur OpenShift, sur les mêmes nœuds GPU qui desservent également des points de terminaison d'inférence affinés. Une fois la tâche terminée, les résultats sont stockés dans un magasin d'objets partagé accessible aux environnements HPC et Kubernetes.
Une chercheur en NLP clinique dans une faculté de médecine nécessite un modèle affiné sur des notes cliniques anonymisées pour une tâche de reconnaissance d'entités nommées. Les équipes collaborent avec le personnel chargé de la plateforme pour exécuter une tâche de réglage fin LoRA (Low-Rank Adaptation) via le hub d'entraînement Training Hub sur OpenShift AI, à l'aide d'un modèle de base du catalogue NVIDIA NIM. Le modèle résultant est versionné et mis à disposition en tant que point de terminaison MaaS. Deux autres équipes de recherche chargées de tâches de traitement du langage naturel (NLP) adjacentes commencent immédiatement à utiliser le même point de terminaison, ce qui répartit les coûts de réglage fin au sein de l'établissement.
Un groupe de recherche en cybersécurité au sein d'un FFRDC doit analyser des rapports sur les cybermenaces à grande échelle à l'aide d'un LLM. Comme les données présentent des contraintes de confidentialité interdisant l'utilisation d'API cloud, le modèle s'exécute entièrement sur site sur le cluster OpenShift. L'équipe a affiné le modèle sur son ensemble de données classifiées en utilisant la génération de données synthétiques InstructLab pour enrichir son petit ensemble de données étiquetées. Le point de terminaison est accessible uniquement aux namespaces dotés des liaisons RBAC appropriées.
Le personnel d'ingénierie de plateforme gérant l'ensemble de ces charges de travail sur le même cluster consulte un tableau de bord d'observabilité unique affichant l'utilisation des GPU pour les charges de travail Slurm et Kubernetes, la latence de service des modèles par point de terminaison, la profondeur de la file d'attente des tâches d'entraînement et l'utilisation des quotas de ressources par namespace. Le planificateur unifié résout les conflits de ressources entre les charges de travail, évitant ainsi toute intervention manuelle.
Chacune de ces capacités est disponible dès aujourd'hui dans Red Hat AI et OpenShift AI, intégrées au matériel NVIDIA via l'architecture de référence Red Hat AI Factory with NVIDIA, et étendues aux flux de travail HPC via l'opérateur Slinky.
Conclusion
Les personnes menant la prochaine génération de découvertes utiliseront les LLM comme outil principal et comme élément central de leur flux de travail de recherche, plutôt que comme un simple complément aux méthodes existantes.
Le personnel de recherche attend de la plateforme des capacités utilisables sans avoir à devenir des ingénieurs en infrastructure. Ces personnes nécessitent des modèles affinés maîtrisant leur domaine, une inférence rapide et fiable, des flux de travail HPC sans changement de contexte vers un autre cluster, ainsi qu'un accès partagé via un service gouverné.
Ensemble, Red Hat OpenShift, Red Hat AI, NVIDIA et l'opérateur Slinky fournissent cette plateforme.
Ressource
Se lancer avec l'IA en entreprise : guide pour les débutants
À propos des auteurs

I build real-world GenAI solutions for organizations that can’t afford to get it wrong.
My career spans national security, enterprise software, and next-generation AI platforms, with more than a decade focused on solving complex problems at the intersection of data, intelligence, and technology. I began in the intelligence community, serving eight years with the NSA and across the IC in intrusion defense, intelligence analysis, and mission-critical cyber operations. That experience in high-stakes security, pattern recognition, and adversarial thinking continues to shape how I approach GenAI strategy and deployment today.
Since then, I’ve led product and platform initiatives in digital ecosystems, advised startups, and worked across the data science landscape helping organizations move from experimentation to production. Much of my work focuses on making generative AI models more knowledgeable and reliable by grounding them in domain-specific data, mission context, and real operational constraints across national security, research, and healthcare.
Today, as an AI Solutions Advisor at Red Hat and IBM, I partner with government agencies, research institutions, and enterprises across North America to design scalable GenAI systems that work in the real world. The goal is never novelty — it’s better decisions, faster execution, and durable advantage.

O'Neill Joseph is a Sr AI Solutions Architect in Red Hat focused on specialized AI deployments, has over 20 experience in IT Infrastructure, from telecommunications to cloud native infrastructure with a Degree in Cybersecurity and IT Networking from University of Maryland.

Working with customers to build IT solutions for over 25 years, Wes has experience integrating various technologies and approaches to produce outcomes and achieve mission objectives. Serving highly regulated industries such as healthcare and defense, Wes understands how to approach IT challenges with a secure, compliant end state in mind.
At Red Hat, Wes focuses on helping customers build cloud-native platforms where they can run AI/ML workloads, integrate heterogeneous data and facilitate outcomes anywhere in the world.
Prior to joining Red Hat, Wes was the CTO at a small technology company in DC helping build solutions for a variety of government customers.
Wes has managed global engineering teams, built services to help customers scale their missions, and designed software solutions to meet the needs of growing organizations.
Plus de résultats similaires
Cessez de gérer le passé et commencez à bâtir l'avenir de l'informatique
Prochain point d'inflexion de l'IA : transformation des agents en super-utilisateurs pour l'entreprise
Technically Speaking | Build a production-ready AI toolbox
Technically Speaking | Platform engineering for AI agents
Parcourir par canal

Automatisation
Les dernières nouveautés en matière d'automatisation informatique pour les technologies, les équipes et les environnements

Intelligence artificielle
Actualité sur les plateformes qui permettent aux clients d'exécuter des charges de travail d'IA sur tout type d'environnement

Cloud hybride ouvert
Découvrez comment créer un avenir flexible grâce au cloud hybride

Sécurité
Les dernières actualités sur la façon dont nous réduisons les risques dans tous les environnements et technologies

Edge computing
Actualité sur les plateformes qui simplifient les opérations en périphérie

Infrastructure
Les dernières nouveautés sur la plateforme Linux d'entreprise leader au monde

Applications
À l’intérieur de nos solutions aux défis d’application les plus difficiles
Virtualisation
L'avenir de la virtualisation d'entreprise pour vos charges de travail sur site ou sur le cloud