-
Produits et documentation Red Hat AI
Plateforme de produits et de services pour le développement et le déploiement de l'IA dans le cloud hybride.
Red Hat AI Enterprise
Créez, développez et déployez des applications basées sur l'IA dans le cloud hybride.
Red Hat AI Inference Server
Optimisation des performances des modèles avec le vLLM pour des inférences rapides et rentables à grande échelle.
Red Hat Enterprise Linux AI
Développez, testez et exécutez des modèles d'IA générative avec des capacités d'inférence optimisées.
Red Hat OpenShift AI
Assemblage et déploiement de modèles et d'applications basés sur l'IA à grande échelle dans des environnements hybrides.
-
Se former Notions de base
- Nouveautés de Red Hat AI
- Comprendre l'importance de l'inférence d'IA
- Le framework vLLM, qu'est-ce que c'est ?
- Les inférences d'IA, qu'est-ce que c'est ?
- IA prédictive et IA générative
- L'IA agentique, qu'est-ce que c'est ?
- RAG et réglage fin
- Voir tous les thèmes liés à l'IA
- Voir tous les articles de blog sur l'IA
Ressources techniques
-
Partenaires pour l'IA
Comprendre l'importance de l'inférence d'IA
Pour faire simple, l'IA ne pourrait pas fonctionner sans l'inférence.
L'inférence est au cœur de l'IA générative. Mais lorsque les entreprises utilisent de grands modèles pour appliquer des stratégies de plus en plus vastes, tout peut vite se compliquer.
C'est pourquoi nous expliquons ici les défis et les avantages associés à l'inférence d'IA, de l'optimisation des modèles avec vLLM jusqu'aux derniers frameworks Open Source distribués tels que llm-d.
L'importance de l'inférence
L'inférence est la phase finale d'un processus long et complexe d'apprentissage automatique, durant laquelle le modèle produit le résultat souhaité.
Surtout, c'est une opération essentielle au bon fonctionnement de l'IA.
C'est pourquoi la réussite des stratégies d'IA dépend du matériel et des logiciels sur lesquels reposent les fonctionnalités d'inférence.

Les obstacles à la mise à l'échelle
La croissance incessante des modèles affecte les performances de l'inférence. Plus les modèles se complexifient, plus le processus d'inférence ralentit.
L'inférence exige des modèles d'IA qu'ils effectuent une grande quantité de calculs en un court laps de temps. Par conséquent, des facteurs tels que la taille du modèle, le nombre d'utilisateurs et la latence peuvent limiter les performances.
Face à des modèles qui nécessitent davantage de données et de mémoire, le matériel et les accélérateurs peinent à suivre le rythme.
66 %
des ressources de calcul nécessaires à l'IA devraient être utilisées par l'inférence en 2026, contre 33 % en 2023 et 50 % en 20251
Les pistes d'amélioration de l'inférence
Lorsque l'inférence est optimisée, les modèles d'IA s'exécutent plus rapidement et efficacement.
Il existe plusieurs méthodes d'optimisation : amélioration de l'efficacité des GPU, décodage spéculatif, élagage, compression des modèles à l'aide de techniques de quantification et inférence distribuée.
Les outils tels que LLM Compressor tirent parti des dernières avancées en matière de compression des modèles pour optimiser la taille, la vitesse et l'utilisation des ressources des LLM. Ces avantages permettent de réduire les besoins matériels et d'améliorer l'efficacité, sans pour autant dégrader la précision.
Grâce à ces optimisations, l'inférence d'IA reste économique et peut être mise à l'échelle au rythme de l'évolution de l'entreprise.
Plus de 99 %
de précision préservée lors des optimisations réalisées avec LLM Compressor2

2 fois
plus de débit de calcul grâce à la compression des modèles, sans dégrader la précision3
50 %
de réduction des coûts pour un même niveau de performances grâce à l'optimisation des modèles avec LLM Compressor4

L'optimisation de l'inférence avec vLLM
L'optimisation des modèles ne représente qu'une partie de la solution : il faut également déployer un moteur d'inférence hautement efficace. C'est là qu'intervient le framework vLLM.
Les systèmes traditionnels de gestion de la mémoire des LLM manquent d'efficacité, ce qui ralentit les performances des LLM. Le framework vLLM utilise le mécanisme PagedAttention, une technique de gestion de la mémoire qui identifie les valeurs clés répétitives pour alléger le travail des LLM.
vLLM peut ainsi utiliser plus efficacement la mémoire GPU et accélérer l'inférence d'IA générative. Le débit (nombre de jetons textuels traités par seconde) peut aussi être optimisé, pour servir plusieurs utilisateurs à la fois.
L'utilisation plus efficace des accélérateurs permet aux modèles d'effectuer plus de calculs en moins de temps. Les équipes peuvent ainsi répondre aux besoins d'un plus grand nombre d'utilisateurs et d'agents.
50 %
de réduction des paramètres grâce à l'élagage5

2,1 fois
moins de latence d'inférence grâce aux techniques de décodage spéculatif6
24 fois
plus de débit grâce à vLLM par rapport à la concurrence7
Les avantages du framework vLLM
vLLM a apporté une réponse aux principaux problèmes liés à l'efficacité de l'utilisation des GPU, en réduisant le coût par jeton textuel et en assurant la stabilité de la latence à grande échelle grâce à une approche de déploiement ouverte et portable.
Ces avancées témoignent du dynamisme de la communauté vLLM, qui repose sur la contribution de groupes de passionnés comme Hugging Face, UC Berkeley, NVIDIA et Red Hat. La communauté teste et améliore sans cesse le framework dans le cadre du projet Open Source.
Parce qu'il prend en charge dès la conception tous les principaux modèles et accélérateurs, vLLM est très accessible et intéresse les entreprises comme les milieux universitaires.
Plus de 10 000
contributions* au GitHub vLLM en 2025, soit une augmentation de plus de 200 %
La communauté vLLM en quelques chiffres
Plus de 500 000
GPU déployés 24 h/24, 7 j/78
Plus de 200
types d'accélérateurs différents9
Plus de 500
architectures de modèles prises en charge9
Plus de 2 200
La place de l'inférence distribuée
L'inférence distribuée permet aux modèles d'IA de répartir les tâches liées à l'inférence entre plusieurs équipements interconnectés.
Lorsqu'un modèle est capable de répondre simultanément à plusieurs requêtes, les besoins matériels sont considérablement réduits et l'inférence est plus efficace.
L'inférence distribuée repose sur des techniques telles que le parallélisme des tenseurs, l'ordonnancement intelligent des tâches d'inférence et la désagrégation. Et avec vLLM, l'inférence devient une machine multitâche très efficace.
Tous ces avantages rendent l'inférence plus observable, évolutive et cohérente.
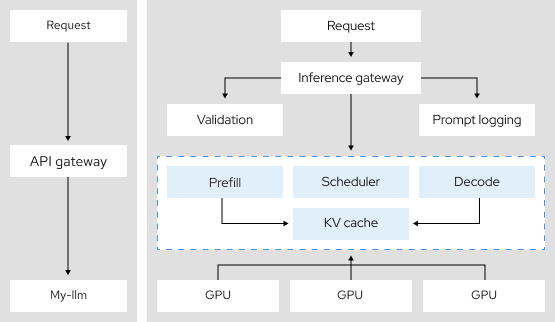
3,9 x
plus de débit de jetons textuels grâce au parallélisme des tenseurs, une architecture d'inférence distribuée10
Une communauté Open Source spécialisée dans l'inférence
Il existe une communauté qui se spécialise dans l'inférence, et qui se nomme llm-d.
llm-d est un framework Open Source qui propose aux équipes de développement un modèle pour mettre en place l'inférence distribuée à grande échelle.
Grâce à son architecture modulaire, ce framework gère les besoins complexes en ressources des LLM plus évolués. Il remplace les processus manuels et fragmentés par des schémas bien définis et intégrés qui permettent d'accélérer la mise en production.
llm-d intègre l'inférence à Kubernetes, offrant ainsi une boîte à outils standardisée aux entreprises qui souhaitent appliquer l'inférence distribuée à leur propre cas d'utilisation.
2 fois
plus de QPS (requêtes par seconde) traitées grâce au framework llm-d11
Autres ressources sur l'IA
Red Hat AI Inference Server
Accélérez la mise en production de vos LLM
Basé sur vLLM, notre moteur d'inférence pour les entreprises permet d'accélérer l'inférence sans dégrader les performances.
Avec Red Hat AI Inference Server, passez au cloud hybride et déployez le modèle d'IA générative optimisé de votre choix, avec tout accélérateur d'IA et dans tout type d'environnement cloud.

Sources citées
[1] « Why AI's Next Phase Will Likely Demand More Computing Power—Not Less », The Wall Street Journal, 22 janvier 2026.
[2] Kurtić, Eldar, et coll., « We ran over half a million evaluations on quantized LLMs—here's what we found », blog Red Hat Developer, 17 octobre 2024.
[3] Condado, Carlos, « Adopter une approche stratégique pour optimiser les performances de l'inférence d'IA », blog Red Hat, 15 septembre 2025.
[4] Zelenović, Saša, « Exploiter tout le potentiel des LLM : des performances optimisées avec le vLLM », blog Red Hat, 27 février 2025.
[5] Kurtić, Eldar, et coll. « 2:4 Sparse Llama: Smaller models for efficient GPU inference », blog Red Hat Developer, 28 février 2025.
[6] Marques, Alexandre, et coll., « Fly Eagle(3) fly: Faster inference with vLLM & speculative decoding, blog Red Hat Developer, 1er juillet 2025.
[7] Kwon, Woosuk, et coll., « vLLM: Easy, Fast, and Cheap LLM Serving with PagedAttention », blog vLLM, 20 juin 2023.
[8] Goin, Michael, « [vLLM Office Hours #38] vLLM 2025 Retrospective & 2026 Roadmap », YouTube, 18 décembre 2025.
[9] Kwon, Woosuk, « Today, vLLM supports 500+ model architectures, runs on 200+ accelerator types, and powers inference at global scale », X, 26 janvier 2026.
[10] Goin, Michael, « Distributed inference with vLLM », Red Hat Developer, 6 février 2025.
[11] Shaw, Robert, « llm-d: Kubernetes-native distributed inferencing », Red Hat Developer, 20 mai 2025.