Actuellement, de plus en plus d'entreprises font le choix de rapatrier leur infrastructure de grands modèles de langage (LLM) dans leurs locaux. Le recours à l'autohébergement avec des modèles Open Source sur leur propre matériel leur permet de contrôler de nombreux aspects du déploiement de l'intelligence artificielle (IA), notamment la latence, la conformité et la confidentialité des données. La mise à l'échelle des LLM de l'expérimentation à la production entraîne toutefois des coûts élevés et une haute complexité.
Soutenu par de nombreux contributeurs, parmi lesquels Red Hat, IBM et Google, le nouveau framework Open Source llm-d est conçu pour relever ces défis. Il cible le cœur du problème : l'inférence d'IA, c'est-à-dire le processus dans le cadre duquel un modèle génère des résultats pour divers usages : instructions génératives, agents, génération augmentée de récupération (RAG), etc.
Grâce à des décisions d'ordonnancement intelligent (désagrégation) et à des modèles de routage propres à l'IA, llm-d permet une distribution dynamique et intelligente des charges de travail pour les LLM. Pourquoi est-ce si important ? Voyons comment fonctionne ce framework et la manière dont il réduit les coûts associés à l'IA tout en améliorant les performances.
Défis liés à la mise à l'échelle de l'inférence des LLM
Il existe des modèles établis pour la mise à l'échelle des services web traditionnels sur des plateformes comme Kubernetes. Généralement, les requêtes HTTP standards sont rapides, stateless et uniformes. La mise à l'échelle de l'inférence des LLM est toutefois bien différente,
notamment parce que les caractéristiques des requêtes présentent un haut niveau de variation. Par exemple, à partir d'une longue instruction d'entrée contenant du contexte issu d'une base de données vectorielle, un modèle de RAG peut générer une réponse courte d'une phrase. À l'inverse, une tâche de raisonnement peut commencer par une courte instruction et produire une longue réponse en plusieurs étapes. Cette variation crée des déséquilibres de charge qui peuvent dégrader les performances et augmenter la latence en aval. L'inférence des LLM dépend également du cache clé-valeur, la mémoire à court terme d'un LLM, qui stocke les résultats intermédiaires. Le système d'équilibrage de charge traditionnel ignore l'état de ce cache, ce qui entraîne un routage inefficace des requêtes et une sous-utilisation des ressources de calcul.

Avec Kubernetes, l'approche actuelle consiste à déployer des LLM sous forme de conteneurs monolithiques, c'est-à-dire de grandes boîtes noires sans visibilité ni contrôle. En plus d'ignorer la structure des instructions génératives, le nombre de jetons textuels, la latence de réponse visée (objectifs de niveau de service ou SLO), la disponibilité du cache et de nombreux autres facteurs, cette pratique complique la mise à l'échelle.
En bref, nos systèmes d'inférence actuels sont inefficaces et utilisent plus de ressources de calcul que nécessaire.
Amélioration de l'efficacité et de la rentabilité de l'inférence avec llm-d
La technologie du vLLM prend déjà en charge de nombreux modèles sur différents types de matériel. Le framework llm-d va encore plus loin. En s'appuyant sur les infrastructures informatiques d'entreprise existantes, il offre des capacités d'inférence avancées et distribuées qui aident à économiser des ressources et à améliorer les performances. Il permet notamment de diviser par trois le délai d'obtention du premier jeton textuel et de doubler le débit malgré les contraintes de latence (SLO). Si le framework llm-d propose de nombreuses innovations, deux d'entre elles améliorent particulièrement l'inférence :
- Désagrégation : la désagrégation du processus permet d'utiliser plus efficacement les accélérateurs matériels lors de l'inférence. Cette pratique consiste à séparer le traitement des instructions génératives (phase de préremplissage) et la génération des jetons textuels (phase de décodage) dans des charges de travail individuelles, appelées pods. Grâce à cette séparation, chaque phase est mise à l'échelle et optimisée de manière indépendante, en fonction de leurs exigences différentes en matière de calcul.
- Couche d'ordonnancement intelligent : en complétant l'API Gateway de Kubernetes, cette couche permet de nuancer les décisions de routage pour les requêtes entrantes. Elle exploite des données en temps réel, telles que l'utilisation du cache clé-valeur et la charge des pods, pour diriger les requêtes vers l'instance la plus adaptée. Ce mécanisme permet d'optimiser les performances du cache et d'équilibrer les charges de travail dans le cluster.

En parallèle de fonctions telles que la mise en cache des paires clé-valeur de l'ensemble des requêtes pour éviter un nouveau calcul, llm-d divise l'inférence des LLM en services modulaires et intelligents pour offrir des performances évolutives (en s'appuyant largement sur le vLLM). Voici des exemples pratiques d'utilisation de ces technologies avec llm-d.
Augmentation du débit avec une latence réduite grâce à la désagrégation
La différence fondamentale entre les phases de préremplissage et de décodage de l'inférence des LLM est à l'origine d'un manque d'uniformité dans l'allocation des ressources. La phase de préremplissage, qui traite l'instruction d'entrée, est généralement liée au calcul et demande une puissance de traitement élevée pour créer les entrées initiales du cache clé-valeur. La phase de décodage, pendant laquelle les jetons textuels sont générés un par un, est souvent liée à la bande passante mémoire, car elle implique principalement la lecture et l'écriture dans le cache clé-valeur avec relativement moins de calcul.
Grâce au processus de désagrégation que met en œuvre llm-d, des pods Kubernetes distincts peuvent distribuer ces deux profils de calcul. Il est ainsi possible de provisionner des pods de préremplissage avec des ressources optimisées pour les tâches qui requièrent beaucoup de calculs, et de décoder des pods avec des configurations adaptées pour garantir l'efficacité de la bande passante mémoire.
Fonctionnement de la passerelle d'inférence sensible aux LLM
L'amélioration des performances qu'offre llm-d repose sur son routeur d'ordonnancement intelligent, qui orchestre où et comment les requêtes d'inférence sont traitées. Lorsqu'une requête d'inférence arrive à la passerelle llm-d (basée sur kgateway), elle n'est pas simplement transmise au pod disponible suivant. L'outil EPP (Endpoint Picker), qui fait partie des principaux composants de l'ordonnanceur llm-d, évalue également plusieurs facteurs en temps réel pour déterminer la destination optimale :
- Prise en compte du cache clé-valeur : l'ordonnanceur conserve un index de l'état du cache clé-valeur sur toutes les répliques du vLLM en cours d'exécution. Si une nouvelle requête partage un préfixe avec une session déjà mise en mémoire sur un pod spécifique, l'ordonnanceur accorde la priorité à ce pod. Ce processus améliore considérablement les résultats du cache, ce qui permet d'éviter les calculs redondants de préremplissage ainsi que de réduire directement la latence.
- Prise en compte de la charge : au-delà du simple décompte des requêtes, l'ordonnanceur évalue la charge réelle de chaque pod du vLLM. Il tient compte de la mémoire utilisée par le processeur graphique et des files d'attente de traitement afin d'éviter les goulets d'étranglement.
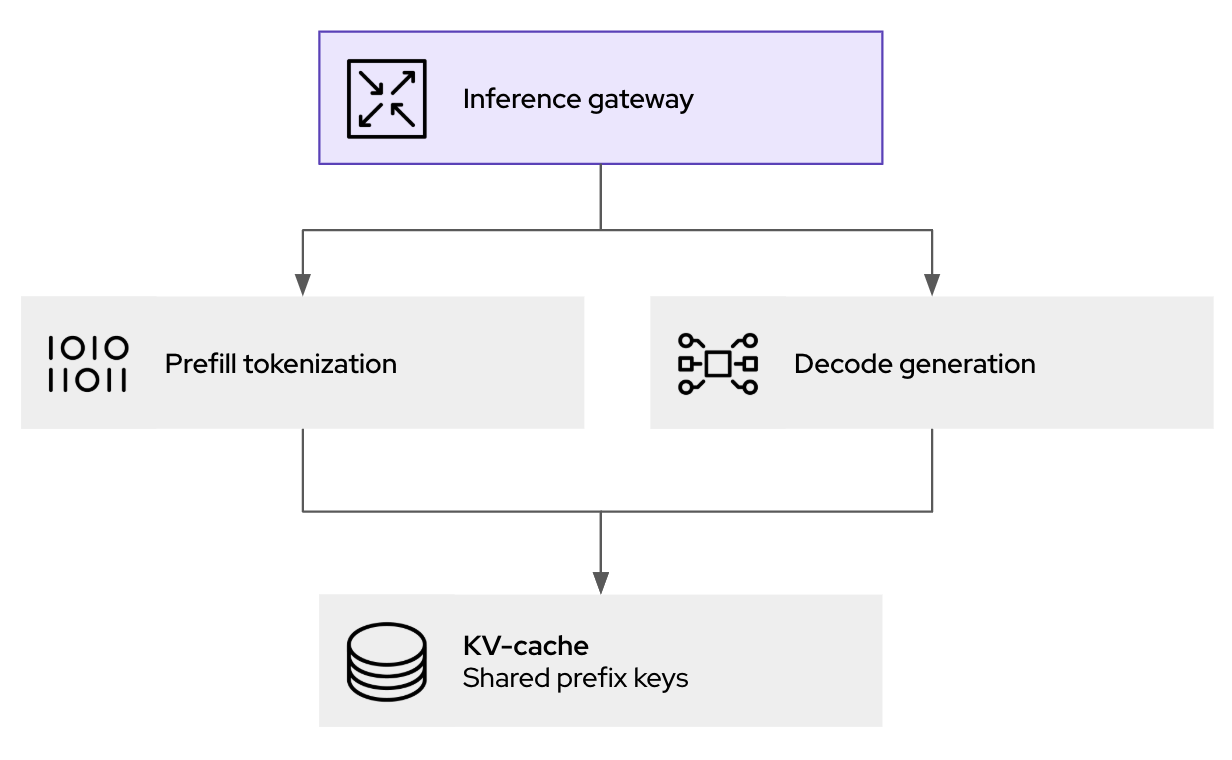
Cette approche native pour Kubernetes fournit les couches de politiques, de sécurité et d'observabilité dont les opérations d'inférence d'IA générative ont besoin. Elle permet non seulement de gérer le trafic, mais aussi de consigner les instructions génératives et de les vérifier (pour la gouvernance et la conformité), ainsi que de mettre en place des mesures de sécurité avant de passer à l'inférence.
Premiers pas avec llm-d
Le projet llm-d est en plein essor. Si le vLLM est idéal pour les configurations à un seul serveur, le framework llm-d sera plus adapté aux équipes qui gèrent un cluster, pour des opérations d'inférence d'IA performantes et rentables. Pour commencer à l'utiliser, accédez au référentiel llm-d sur GitHub et rejoignez la conversation sur Slack. Vous pourrez poser toutes vos questions et vous impliquer.
L'avenir de l'IA repose sur des principes d'ouverture et de collaboration. Au travers de communautés comme le vLLM et de projets comme llm-d, Red Hat s'efforce de rendre l'IA plus puissante, accessible et abordable pour les équipes de développement du monde entier.
Ressource
Se lancer avec l'IA en entreprise : guide pour les débutants
À propos des auteurs

Cedric Clyburn (@cedricclyburn), Senior Developer Advocate at Red Hat, is an enthusiastic software technologist with a background in Kubernetes, DevOps, and container tools. He has experience speaking and organizing conferences including DevNexus, WeAreDevelopers, The Linux Foundation, KCD NYC, and more. Cedric loves all things open-source, and works to make developer's lives easier! Based out of New York.

Christopher Nuland is a Principal Technical Marketing Manager for AI at Red Hat and has been with the company for over six years. Before Red Hat, he focused on machine learning and big data analytics for companies in the finance and agriculture sectors. Once coming to Red Hat, he specialized in cloud native migrations, metrics-driven transformations, and the deployment and management of modern AI platforms as a Senior Architect for Red Hat’s consulting services, working almost exclusively with Fortune 50 companies until recently moving into his current role. Christopher has spoken worldwide on AI at conferences like IBM Think, KubeCon EU/US, and Red Hat’s Summit events.
Plus de résultats similaires
Enable intelligent insights with Red Hat Satellite MCP Server
AI quickstart: Protecting inference with F5 Distributed Cloud and Red Hat AI
Technically Speaking | Build a production-ready AI toolbox
Technically Speaking | Platform engineering for AI agents
Parcourir par canal

Automatisation
Les dernières nouveautés en matière d'automatisation informatique pour les technologies, les équipes et les environnements

Intelligence artificielle
Actualité sur les plateformes qui permettent aux clients d'exécuter des charges de travail d'IA sur tout type d'environnement

Cloud hybride ouvert
Découvrez comment créer un avenir flexible grâce au cloud hybride

Sécurité
Les dernières actualités sur la façon dont nous réduisons les risques dans tous les environnements et technologies

Edge computing
Actualité sur les plateformes qui simplifient les opérations en périphérie

Infrastructure
Les dernières nouveautés sur la plateforme Linux d'entreprise leader au monde

Applications
À l’intérieur de nos solutions aux défis d’application les plus difficiles
Virtualisation
L'avenir de la virtualisation d'entreprise pour vos charges de travail sur site ou sur le cloud