This is part of a series of blog posts and podcasts that discuss Red Hat’s work on and thinking about cloud computing. See also:
Cloud computing is in no small part about architecture. It’s about workload scheduling and movement, interfacing to a variety of resource types and providers, bringing in and managing images, providing application programming interfaces (APIs) at various levels, and enabling appropriate visibility into resource use and service levels. How these components connect and relate to each other–and the degree to which they can work in concert with or substitute components that third parties have developed–is (or should be) very much a discussion about architectures, rather than piece parts or monolithic stacks.
A few underlying principles have guided Red Hat as it has developed its cloud computing strategy.
The first should be especially unsurprising given Red Hat’s history. All the projects feeding into Red Hat’s cloud products are open source and, just as important, are actively engaged with communities of developers and users around the industry. For example, the Deltacloud API is now under the governance and licensing of an Incubator project within the Apache Foundation. Open source provides the innovation, economic and business models that run through all Red Hat products.
The second is closely related and that is interoperability. Red Hat is committed to delivering a cloud computing solution that is both comprehensive and based on an infrastructure with advanced multi-tenant security and high levels of scalability. At the same time, however, Red Hat is equally committed to doing this in an open source and interoperable way that lets users pick and choose among components from Red Hat, those from third parties, pieces bought new and pieces already in place.
This theme of evolutionary change isn’t limited to the question of which products will be bought from whom and when. Existing applications can be brought over to cloud environments or evolve incrementally–which is a good thing because applications are one of the longest-lived parts of any IT infrastructure. Red Hat’s approach to cloud computing is to support choice of operating and development environment. Red Hat Enterprise Linux and JBoss Enterprise Middleware make the cloud usable for new and existing enterprise-class applications, while LAMP, Ruby and Spring enable fast, lightweight application development. There’s no need to rewrite applications to take advantage of a cloud computing infrastructure.
With that background, let’s now take a look at some of the specific elements that make up Red Hat’s cloud architecture. Many of these elements have been or will be covered in greater detail in other blog postings and podcasts; this is intended as a high-level overview. (Note that this is an architectural discussion and shouldn’t be taken as a disclosure of roadmaps or future product structure.)
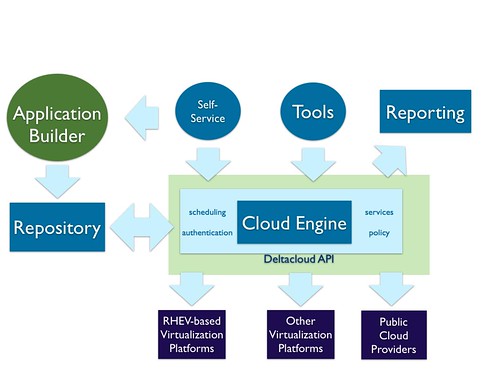
Cloud Engine and Deltacloud API. The Cloud Engine creates scalable private clouds, using a choice of virtualization platforms, that can be federated to public cloud providers under a unified management framework. The Cloud Engine handles tasks such as managing users, groups and permissions; resource management; and image placement/scheduling. This scheduling is handled by embedded Red Hat Enterprise MRG Grid code, a highly scalable job scheduler based on the open source Condor project. Both inbound and outbound communications with the engine are through the Deltacloud API, an open set of interfaces that were described in detail in an earlier post.
“Application Builder.” This function is about getting content into the cloud, whether by constructing a new image or by importing an existing one, and then managing the library of the resulting images. It’s explicitly designed to support multiple target clouds and to provide configuration management of settings such as public IP addresses, firewall rules, network settings and so forth. This aims to provide application portability across clouds and let developers write once and deploy anywhere, eliminating the potential for getting locked-in to a proprietary cloud platform.
Portal and tools. These provide self-service and administrative access for image deployment and configuration, setting policies such as quotas, provisioning users with appropriate access permissions, and providing access to real-time and historical data. In addition to a web-based graphical user interface, there are command line tools to support automated scripting.
Reporting. The Cloud Engine logs granular data about things like resource utilization, service levels, and quota/policy enforcement. This data can be used for purposes such as charging back for computing resource use or planning for capacity upgrades.
Cloud services. These can be called on by applications or tools running in a cloud environment to perform some task. In this way, they simplify development and operations by significantly reducing the need to re-implement commonly needed functions. For example, two types of storage services could be options, one with a REST web interface for large objects and the other an operational store that is more filesystem-like. Services enable private clouds and they also enable the portability of data and application features across different public cloud providers.
Red Hat’s approach to cloud architecture embodies openness and modularity. This preserves customer choice in that it offers them the ability to mix and match new cloud technologies from Red Hat with existing investments, public cloud providers and products from other vendors. It’s an effective approach to leverage open source innovation because it allows and encourages small chunks of function to be added incrementally through open interfaces. In this way, it’s a lot like Linux.
For more on cloud computing from Red Hat, visit here.
À propos de l'auteur

Plus de résultats similaires
AIOps and Ansible Automation Platform: Where AI intelligence meets trusted execution
Why automated OS upgrades still need a human in the loop
Technically Speaking | Taming AI agents with observability
You Can’t Automate Collaboration | Code Comments
Parcourir par canal

Automatisation
Les dernières nouveautés en matière d'automatisation informatique pour les technologies, les équipes et les environnements

Intelligence artificielle
Actualité sur les plateformes qui permettent aux clients d'exécuter des charges de travail d'IA sur tout type d'environnement

Cloud hybride ouvert
Découvrez comment créer un avenir flexible grâce au cloud hybride

Sécurité
Les dernières actualités sur la façon dont nous réduisons les risques dans tous les environnements et technologies

Edge computing
Actualité sur les plateformes qui simplifient les opérations en périphérie

Infrastructure
Les dernières nouveautés sur la plateforme Linux d'entreprise leader au monde

Applications
À l’intérieur de nos solutions aux défis d’application les plus difficiles
Virtualisation
L'avenir de la virtualisation d'entreprise pour vos charges de travail sur site ou sur le cloud