
In Architecting Containers Part 1 we explored the difference between user space and kernel space. In this post, we will continue by exploring why the user space matters to developers, administrators, and architects. From a functional perspective, we will explore the connection that both ISV applications and in-house application development have to the user space.
Virtual Machines vs. Containers
Since virtual machines are well understood, we will start with a comparison. A virtual machine is a convenient way of packaging up virtual hardware, a kernel, and a user space. A container, on the other hand, packages up only the user space; there is no kernel or virtual hardware.
 Virtual Machines
Virtual Machines
Currently, a lot of infrastructure is based on virtual machines. When people want to collaborate on a project, there are two main ways that they can share work. People can share a copy of the code that they are working on or they can share an entire virtual machine. While both methods are fairly common - each has its own respective advantages and disadvantages.
Developers typically only share code or binaries (instead of sharing an entire virtual machine). Sharing an entire virtual machine with other developers can be inconvenient because of a virtual machine's size and format. Sharing only the code is advantageous in terms of size - the disadvantage being that extra steps are required when deploying the software into a production environment. Developers often build on code that requires underlying modules (e.g. Ruby, PHP PECL, Python, Perl, etc). Some of these modules are provided as packages in the operating system, but often they are pulled from an external repository - some even need to be compiled from C/C++. Other developers, administrators, and architects are then left to figure out how to install these requirements. Tools like RPM, git, and RVM have been developed to make this easier... but the build and deployment steps can be complicated and often require some measure of expertise (outside the domain of the application being developed).
On the other side of things, architects and systems administrators often share an entire virtual machine. Doing so makes it easy to preserve the work they have done to customize core builds or gold images. A virtual machine is typically made up of two files - the first is a copy of the user space and kernel (we call this a virtual disk) - the second is a file containing metadata that defines the resources (CPU, RAM, video card, etc.) that are to be used when the virtual machine is started. This approach has the advantage of requiring only a few steps to deploy, but over time, it’s easy to lose track of what’s inside the virtual machine image. When ISVs deliver a virtual image, customers are often concerned with the methodology behind its creation, as well as how it should be maintained, configured and patched. Every vendor has (for example) a different way of logging in, changing passwords, configuring time services, and configuring the network. Worse - these configurations are almost always a manual processes.
So, it stands to reason that neither the "code only" nor "full virtual machine" method of sharing is perfect. Unsurprisingly, tools have been developed to try and bring these methodologies closer together. Tools such as Kickstart, Puppet, and Chef attempt to make server builds more like code (infrastructure as code) while tools like Vagrant have been developed to simplify the deployment of full virtual machines to developer laptops.
Should code or the full virtual machine be the currency for collaboration? Maybe there's another way? Read on!
Containers as Currency
When a container is first instantiated, the user space of the container host makes system calls into the kernel to create special data structures in the kernel (cgroups, svirt, namespaces). The container host can be a full installation of Red Hat Enterprise Linux 7 or a container optimized variant such as Red Hat Enterprise Linux Atomic Host. The system calls are the same either way.
Notice in the drawing below that when a container is created, the clone() system call is used to create a new process. Clone is similar to fork, but allows the new process to be set up within a kernel namespace. Kernel namespaces allow the new process to have its own hostname, IP address, filesystem mount points, process id, and more. A new name space can be created for each new container - allowing them to each look and feel similar to a virtual machine.
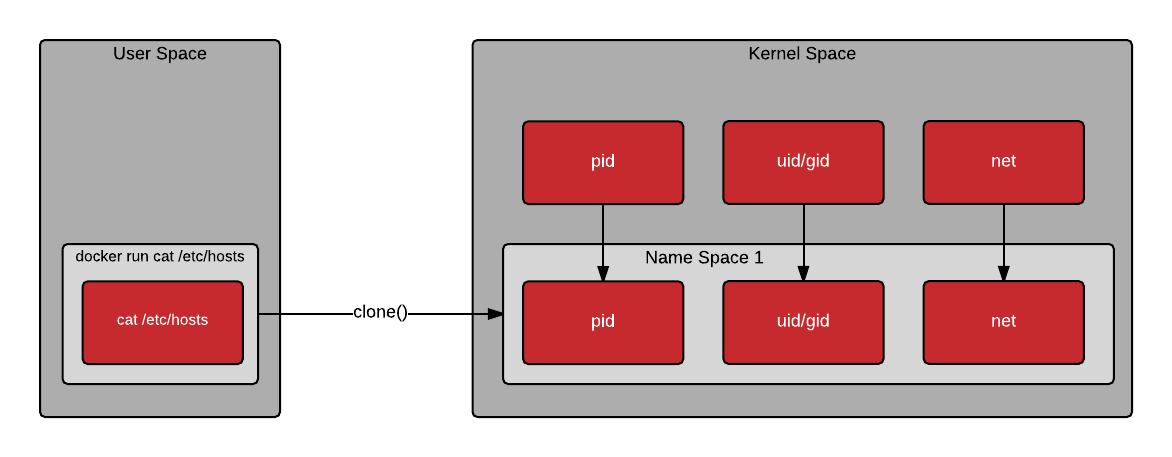 Once the container is instantiated, the process or processes execute within a pristine user space created from mounting the container image. The processes inside the container make system calls as they would normally. The kernel is responsible for limiting what the processes in the container can do. Notice from the drawing below, that the first command executes the open() system call directly from the host’s user space, the second command executes the open() system call through the mount namespace (containerized), and the third executes the getpid() through the PID namespace (containerized).
Once the container is instantiated, the process or processes execute within a pristine user space created from mounting the container image. The processes inside the container make system calls as they would normally. The kernel is responsible for limiting what the processes in the container can do. Notice from the drawing below, that the first command executes the open() system call directly from the host’s user space, the second command executes the open() system call through the mount namespace (containerized), and the third executes the getpid() through the PID namespace (containerized).
 When the container is stopped, the kernel name space count is decremented and typically removed. Once terminated, the user has the option of discarding the work done, or saving the container as a new image.
When the container is stopped, the kernel name space count is decremented and typically removed. Once terminated, the user has the option of discarding the work done, or saving the container as a new image.
As long as infrastructure parity (CPU, memory, network, kernel compatibility) is achieved between environments, the same container image can be started and run on a developer's laptop, servers in the datacenter, or on virtual machines in the cloud. Containers have the advantage of providing developers, architects, quality engineering, release engineers, and systems administrators with a currency for collaboration that has the entire user space packaged and shipped in a convenient and easy to use format.
Conclusion
The user space matters because it is the focus of most developers and architects. Whether developing Ruby on Rails applications, Java, or PHP PECL modules that require underlying C libraries - containers are a convenient way of packing up and shipping around an application and all of its user space dependencies.
The user space also matters because this is what provides all of the tooling to interact with container images, to build new images, and to instantiate new containers.
Whether developing and deploying traditional applications or a modern microservices architecture, focusing on the container image (user space) as the currency for collaboration grants everyone from developers and systems administrators to architects and release engineers more flexibility and the ability to be more efficient.
In Architecting Containers Part 3: How the User Space Affects Your Application, we will explore how the user space / kernel space relationship affects your application. If you have thoughts or questions – feel free to reach out using the comments section (below).
À propos de l'auteur
Plus de résultats similaires
Les menaces liées à l'IA évoluent. Vos défenses doivent en faire autant.
Au-delà de l'automatisation : pourquoi la montée des vulnérabilités de sécurité liées à l'IA exige une expertise technique humaine
Untangling Networks | Compiler
Technically Speaking | Defining sovereign AI with open source
Parcourir par canal

Automatisation
Les dernières nouveautés en matière d'automatisation informatique pour les technologies, les équipes et les environnements

Intelligence artificielle
Actualité sur les plateformes qui permettent aux clients d'exécuter des charges de travail d'IA sur tout type d'environnement

Cloud hybride ouvert
Découvrez comment créer un avenir flexible grâce au cloud hybride

Sécurité
Les dernières actualités sur la façon dont nous réduisons les risques dans tous les environnements et technologies

Edge computing
Actualité sur les plateformes qui simplifient les opérations en périphérie

Infrastructure
Les dernières nouveautés sur la plateforme Linux d'entreprise leader au monde

Applications
À l’intérieur de nos solutions aux défis d’application les plus difficiles
Virtualisation
L'avenir de la virtualisation d'entreprise pour vos charges de travail sur site ou sur le cloud