L'ère moderne de l'entraînement de l'IA, en particulier pour les grands modèles, est confrontée à des exigences simultanées en matière de puissance de calcul et de confidentialité stricte des données. L'apprentissage automatique (AA) traditionnel nécessite de centraliser les données d'entraînement, ce qui engendre des difficultés et des efforts considérables en matière de confidentialité, de sécurité, d'efficacité et de volume des données.
Ce défi s'accentue à l'échelle de l'infrastructure mondiale hétérogène dans les environnements multicloud, cloud hybride et edge computing, obligeant les entreprises à entraîner des modèles à l'aide des ensembles de données distribués existants tout en protégeant la confidentialité des données.
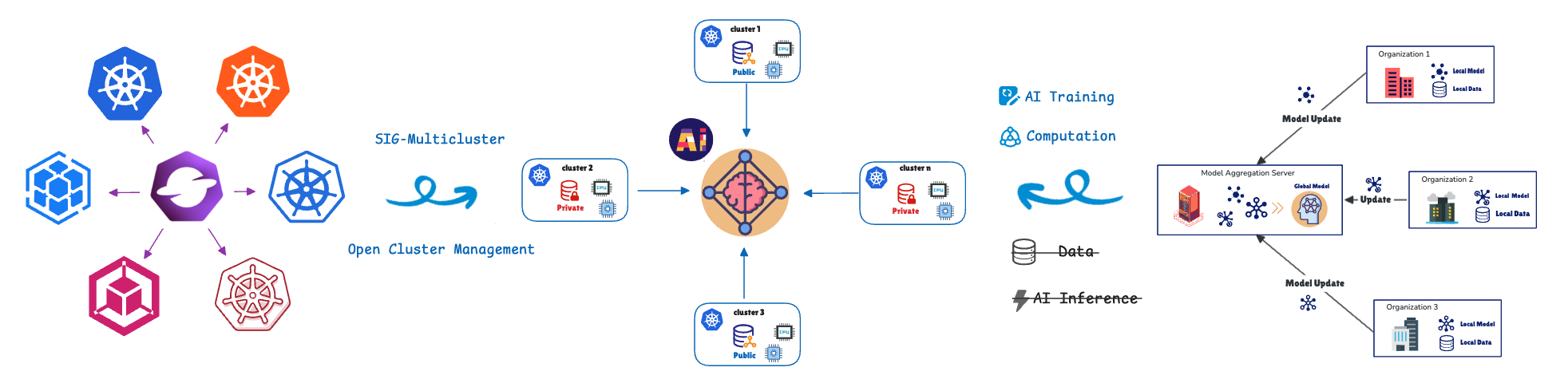
L'apprentissage fédéré (FL pour Federated Learning) relève ce défi en déplaçant l'entraînement du modèle vers les données. Les clusters ou appareils distants (collaborateurs/clients) entraînent les modèles localement à l'aide de leurs données privées et partagent uniquement les mises à jour du modèle (et non les données brutes) avec un serveur central (agrégateur). Cette approche contribue à protéger la confidentialité des données de bout en bout. Cette approche est essentielle pour les scénarios sensibles à la confidentialité ou à forte charge de données que l'on retrouve dans les secteurs de la santé, de la vente au détail, de l'automatisation industrielle et des véhicules définis par logiciel (SDV) dotés de systèmes avancés d'aide à la conduite (ADAS) et de fonctionnalités de conduite autonome (AD), telles que l'avertissement de sortie de voie, le régulateur de vitesse adaptatif et la surveillance de la fatigue du conducteur.
Pour gérer et orchestrer ces unités de calcul distribuées, nous utilisons la définition de ressource personnalisée (CRD) d'apprentissage fédéré d'Open Cluster Management (OCM).
OCM : la base des opérations distribuées
OCM est une plateforme d’orchestration multicluster Kubernetes et un projet Open Source CNCF Sandbox.
OCM utilise une architecture en étoile et un modèle basé sur l'extraction.
- Cluster Hub : il sert de plan de contrôle central responsable de l'orchestration.
- Clusters gérés (spoke) : il s'agit de clusters distants où les charges de travail sont déployées.
Les clusters gérés extraient l'état souhaité du hub et lui renvoient leur statut. OCM fournit des API telles que ManifestWork et Placement pour planifier les charges de travail. Nous aborderons plus de détails sur l'API d'apprentissage fédéré ci-dessous.
Nous allons maintenant examiner pourquoi et comment la conception de la gestion de clusters distribués d'OCM s'aligne étroitement sur les exigences du déploiement et de la gestion des contributeurs FL.
Intégration native : OCM en tant qu'orchestrateur FL
1. Alignement architectural
L'association d'OCM et de FL est efficace en raison de leur congruence structurelle fondamentale. OCM prend en charge nativement FL, car les deux systèmes partagent une conception fondamentale identique : l'architecture en étoile et un protocole basé sur l'extraction.

Composant OCM | Composant FL | Fonction |
Plan de contrôle du hub OCM | Agrégateur/Serveur | Orchestre l'état et regroupe les mises à jour des modèles. |
Cluster géré | Collaborateur/Client | Extrait l'état souhaité/le modèle global, entraîne localement et envoie les mises à jour. |
2. Placement flexible pour la sélection de clients multi-acteurs
L'avantage opérationnel principal d'OCM est sa capacité à automatiser la sélection des clients dans les configurations FL en tirant parti de ses capacités de planification inter-clusters flexibles. Cette fonctionnalité utilise l'API Placement d'OCM pour mettre en œuvre des politiques multicritères sophistiquées, assurant simultanément efficacité et conformité en matière de confidentialité.
L'API Placement permet une sélection intégrée des clients basée sur les facteurs suivants :
- Localité des données (critère de confidentialité) : les charges de travail FL sont planifiées uniquement sur les clusters gérés qui déclarent disposer des données privées nécessaires.
- Optimisation des ressources (critère d'efficacité) : la stratégie de planification d'OCM offre des politiques flexibles qui permettent l'évaluation combinée de plusieurs facteurs. Elle sélectionne les clusters non seulement en fonction de la présence des données, mais aussi des attributs annoncés comme la disponibilité du processeur ou de la mémoire.
3. Sécurisation de la communication entre collaborateur et agrégateur via l'enregistrement d'un module complémentaire OCM
Le module complémentaire FL Collaborator est déployé sur les clusters gérés et exploite le mécanisme d'enregistrement des modules complémentaires d'OCM pour établir une communication protégée et chiffrée avec l'agrégateur sur le hub. Lors de l'enregistrement, chaque module complémentaire Collaborator obtient automatiquement des certificats du hub OCM. Ces certificats authentifient et chiffrent toutes les mises à jour de modèles échangées pendant FL, garantissant ainsi la confidentialité, l'intégrité et la protection des données sur plusieurs clusters.
Ce processus affecte efficacement les tâches d'entraînement de l'IA uniquement aux clusters disposant de ressources adéquates, offrant ainsi une sélection intégrée des clients basée à la fois sur la localité des données et la capacité des ressources.
Le cycle de vie de l'entraînement FL : planification basée sur OCM
Un Federated Learning Controller dédié a été développé pour gérer le cycle de vie de l'entraînement de FL sur plusieurs clusters. Le contrôleur utilise des CRD pour définir les workflows et prend en charge les environnements d'exécution FL courants tels que Flower et OpenFL, et il est extensible.


Le workflow géré par OCM se déroule selon des étapes définies :
Étapes | Phase OCM/FL | Description |
0 | Prérequis | Le module complémentaire d'apprentissage fédéré est installé. L'application FL est disponible sous forme de conteneur déployable par Kubernetes. |
1 | CR FederatedLearning | Une ressource personnalisée est créée sur le hub, définissant le framework (par exemple, Flower), le nombre de cycles d'entraînement (chaque cycle étant un cycle complet où les clients s'entraînent localement et renvoient les mises à jour pour l'agrégation), le nombre requis de contributeurs d'entraînement disponibles et la configuration du stockage du modèle (par exemple, en spécifiant un chemin PersistentVolumeClaim (PVC)). |
2, 3, 4 | Attente et planification | L'état de la ressource est « En attente ». Le serveur (agrégateur) est initialisé sur le hub, et le contrôleur OCM utilise Placement pour planifier les clients (collaborateurs). |
5, 6 | En cours d'exécution | L'état passe à « En cours d'exécution ». Les clients extraient le modèle global, entraînent le modèle localement sur des données privées et synchronisent les mises à jour du modèle avec l'agrégateur de modèles. Le paramètre des cycles d'entraînement détermine la fréquence à laquelle cette phase se répète. |
7 | Terminé | L'état passe à « Terminé ». La validation peut être effectuée en déployant des notebooks Jupyter pour vérifier les performances du modèle par rapport à l'ensemble de données agrégées (par exemple, en confirmant qu'il prédit tous les chiffres MNIST (Modified National Institute of Standards and Technology)). |
Red Hat Advanced Cluster Management : contrôle d'entreprise et valeur opérationnelle pour les environnements FL
Les API et l'architecture de base fournies par OCM servent de fondation à Red Hat Advanced Cluster Management for Kubernetes. Red Hat Advanced Cluster Management assure la gestion du cycle de vie d'une plateforme FL homogène (Red Hat OpenShift) sur une infrastructure hétérogène. L'exécution du contrôleur FL sur Red Hat Advanced Cluster Management offre des avantages supplémentaires par rapport à ce qu'OCM offre seul. Red Hat Advanced Cluster Management offre une visibilité centralisée, une gouvernance basée sur des politiques et une gestion du cycle de vie sur l'ensemble des environnements multiclusters, améliorant considérablement la gestion des environnements distribués et FL.
1. Observabilité
Red Hat Advanced Cluster Management offre une observabilité unifiée sur l'ensemble des workflows FL distribués, permettant aux opérateurs de surveiller la progression de l'entraînement, l'état des clusters et la coordination inter-clusters à partir d'une interface unique et cohérente.
2. Connectivité et sécurité améliorées
La CRD FL prend en charge la communication protégée entre l'agrégateur et les clients via des canaux compatibles TLS. Elle offre également des options de mise en réseau flexibles au-delà de NodePort, notamment LoadBalancer, Route et d'autres types d'entrée, offrant une connectivité protégée et adaptable dans des environnements hétérogènes.
3. Intégration de bout en bout du cycle de vie ML avec Red Hat Advanced Cluster Management et Red Hat OpenShift AI
En tirant parti de Red Hat Advanced Cluster Management avec OpenShift AI, les entreprises peuvent créer un workflow FL complet, du prototypage de modèles à l'entraînement distribué, en passant par la validation et le déploiement en production, au sein d'une plateforme unifiée.
Conclusion
FL transforme l'IA en déplaçant l'entraînement des modèles directement vers les données, résolvant ainsi les frictions entre la mise à l'échelle du calcul, le transfert de données et les exigences strictes en matière de confidentialité. Nous avons souligné ici comment Red Hat Advanced Cluster Management fournit l'orchestration, la protection et l'observabilité nécessaires pour gérer des environnements Kubernetes distribués complexes.
Contactez Red Hat dès aujourd'hui pour découvrir comment vous pouvez donner à votre organisation les moyens d'utiliser l'apprentissage fédéré.
Ressource
L'entreprise adaptable : quand s'adapter à l'IA signifie s'adapter aux changements
À propos des auteurs

Andreas Spanner leads Red Hat’s Cloud Strategy & Digital Transformation efforts across Australia and New Zealand. Spanner has worked on a wide range of initiatives across different industries in Europe, North America and APAC including full-scale ERP migrations, HR, finance and accounting, manufacturing, supply chain logistics transformations and scalable core banking strategies to support regional business growth strategies. He has an engineering degree from the University of Ravensburg, Germany.

Meng Yan is a Senior Software Engineer at Red Hat, specializing in event-driven architectures for multi-cluster management at scale. His research interests focus on agentic AI systems and intelligent automation for software engineering, as well as AI/ML applications in distributed environments such as federated learning and multi-cluster inference.
Plus de résultats similaires
Cessez de gérer le passé et commencez à bâtir l'avenir de l'informatique
De l'inférence aux agents : mise à l'échelle de l'IA en entreprise avec Red Hat AI 3.4
Technically Speaking | Build a production-ready AI toolbox
Technically Speaking | Platform engineering for AI agents
Parcourir par canal

Automatisation
Les dernières nouveautés en matière d'automatisation informatique pour les technologies, les équipes et les environnements

Intelligence artificielle
Actualité sur les plateformes qui permettent aux clients d'exécuter des charges de travail d'IA sur tout type d'environnement

Cloud hybride ouvert
Découvrez comment créer un avenir flexible grâce au cloud hybride

Sécurité
Les dernières actualités sur la façon dont nous réduisons les risques dans tous les environnements et technologies

Edge computing
Actualité sur les plateformes qui simplifient les opérations en périphérie

Infrastructure
Les dernières nouveautés sur la plateforme Linux d'entreprise leader au monde

Applications
À l’intérieur de nos solutions aux défis d’application les plus difficiles
Virtualisation
L'avenir de la virtualisation d'entreprise pour vos charges de travail sur site ou sur le cloud