
Introduction
Tuning is a very interesting topic in the field of Software Engineering. Everybody can agree that it’s important but I have rarely seen people actually doing it. This can be especially true when people have spare computational resources to spend, or if they are following these mantras: “the load won’t reach at this point” or “let the cloud scale it.”
The goal of this post is to share some insights regarding tuning an Apache Camel application deployed into Spring Boot. This is not an ultimate guide for tuning and performance tests in Spring Boot applications, but more of an experience sharing during a tuning process.
When talking about tuning and performance tests, one thing that needs to be clear is the requirements, or what do you want to achieve by tuning an application. For example, one could say that with the computational resources they have, they aim for a 10% increase of requests the application can handle.
We created a fictional scenario to make things easier and to define a requirement where we can apply the proposed tuning configurations. Also, for you to be able to replicate the topics discussed in this post, there is a demonstration lab available at Github. This lab has what you should need to create the environment and run the load tests while exploring the configuration changes addressed in the following sections.
The Scenario
Things get clearer when we demonstrate by example, so let’s use a fictional scenario to do so.
A customer is asking to improve the number of transactions per second (TPS) that their REST Apache Camel application deployed into Spring Boot can handle. The requirements are very strict:
- Can’t increase memory, CPU or disks
- The architecture must remain intact
- Can’t change application source code
The following figure illustrates the scenario architecture:
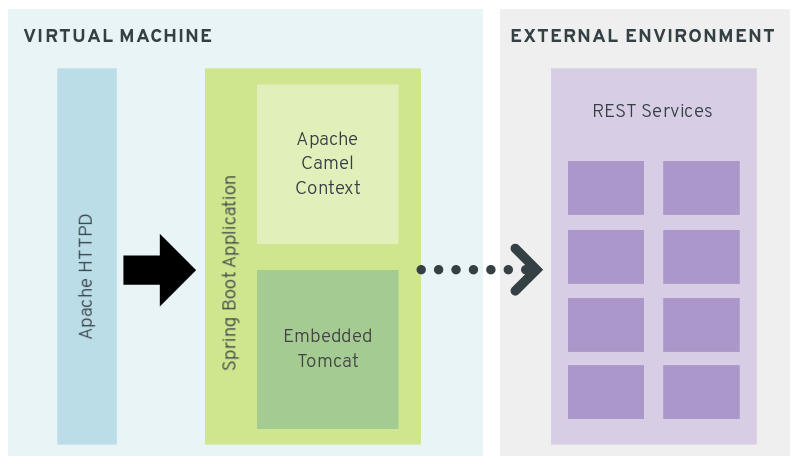
In this use case, the Apache HTTPD Web Server acts as a proxy server, load balancer and also offers TLS support for application servers. The Web Server is proxying requests to a REST application based on Apache Camel and Spring Boot with an embedded Tomcat. This architecture is always used by the customer when implementing REST services that are being integrated with external web services and third party applications.
In this scenario, requests are treated by the proxy server through an encrypted connection and then passed to the underlying Spring Boot application. The application connects to an external service, transforms or composes the received data and then returns a response to the client.
Every component of this architecture is compressed inside a virtual machine with 512MB of RAM and 2 vCPUs. The resources are sparse to emulate a possible real world scenario, where a potential customer is asking for performance improvements in this environment, without having to invest in hardware resources nor modifying the architecture or the application source code.
With such narrow requirements, where would you start? Let’s begin our tuning plan using a very old war strategy: dīvide et imperā (divide and conquer).
Let’s navigate by each component in the architecture and explore what was done in this scenario to tune the environment. Each configuration change proposed is documented in a demonstration lab that could be replicated in other environments. In the next sections, we’re going to discuss each decision based on this example scenario.
Apache HTTPD Web Server
The Apache HTTPD Web Server plays an important role in the architecture by implementing connection encryption and proxying requests to underlying JVM processes.
When installed in a Linux machine, the HTTPD web server comes with default values that could fit most use case scenarios, but when the workload starts to increase, you might face performance problems like proxy timeout errors, low throughout, and high machine resources usage.
Here we’ll work with Apache 2.4, since it’s the current version and includes several bug and security fixes. The links, docs, and codes here will be related to Apache HTTPD 2.4.
Switching the MPM
The first thing that was done was choosing the right Multi-Processing Module (MPM) for our use case scenario. By default, the MPM configured in HTTPD is prefork, which fits for use cases that need compatibility with libraries that are non-thread safe, like some old PHP libraries.
In this case, we are going to change to the worker MPM that is much more performatic and suitable for our scenario, since we don’t need HTTPD to load any non-thread safe library nor serve dynamic scripts. The worker MPM implements a multi-process multi-threaded server, and according to the worker documentation, by using threads to serve requests, it is able to serve a large number of requests with fewer system resources than a process-based server.
It’s worth noting that the worker MPM might be better than prefork in other scenarios as well, as long as you don’t need compatibility with non-thread safe libraries.
Another approach that could be used was the event MPM, but because of a bug in the HTTPD version we were working with at the time of this article, we decided to stick with worker.
Setting the connection parameters
Once the worker MPM is configured, the next thing that to do is define a consistent number for the MaxRequestWorkers parameter. In general, we use 300 times the number of CPU cores for worker MPM, but of course a lot of fine-tuning and experimentation have to be done. Don’t blindly set this parameter without properly testing.
If we just followed the general advice of 300 * CPU cores, the max number of connections that the HTTPD server would serve in our architecture is 600 (we have 2 vCPUs for each machine). But is this number realistic?
In our scenario, the HTTPD server and the Tomcat server are in the same machine, so they are competing for resources. The HTTPD server should serve more requests than the Tomcat because it’s acting simply as a proxy server, while the Tomcat server is the one who is performing all the heavy work by processing our integration services.
Having said that, the proxy server should act like a gatekeeper to help avoid processing more requests than the underlying application server can handle. To came up with an ideal number, a lot of experimentation with load tests have to be done at the application server to figure out how many concurrent requests it can handle. After that, set a number below this one to the HTTPD. This is the final configuration I came up with:
<IfModule mpm_worker_module>
ThreadLimit 30
ServerLimit 10
StartServers 3
MinSpareThreads 5
MaxSpareThreads 20
MaxRequestWorkers 300
ThreadsPerChild 30
MaxRequestsPerChild 0
Timeout 30
ProxyTimeout 30
</IfModule>
Taking into account the machine resources that we had, in our scenario the maximum number of requests that Tomcat handled without errors, while leaving some room for the other processes in the machine, was 400. So we set the max connections to 300 in the proxy server, which proved to be a fine configuration for this scenario. This way, the workload on Tomcat won’t reach the maximum, preserving its healthy state in most situations. Also, 300 simultaneous connections was enough to address the customer’s requirements.
Other important parameters to pay attention to are Timeout and ProxyTimeout. Those numbers should be set equally to the underlying Tomcat server, so if the application times out, the error propagates to the client. Otherwise, you could have connections opened at the proxy server, spending valuable machine resources.
Changing Proxy Pass connector to AJP
The last tuning configuration that was set in this scenario is the AJP connection to the Tomcat server. A basic proxy pass configuration is to bypass requests to the underlying server using the HTTP protocol. Instead, we used the AJP protocol, which is a binary protocol representation of the HTTP protocol that also skips HTTP header re-processing by the underlying server. This way we save a little bit of processing power. The final configuration looked like:
<Location /svc>
ProxyPass ajp://localhost:8009
</Location>
Final thoughts
These are the tuned configuration done so far at the HTTP server side:
- Switched the MPM from prefork to worker
- Adjusted the max connections that the proxy server can handle to preserve machine resources and also protect the application server from a workload that it can’t handle
- Set a proper timeout configuration aligned with the Tomcat server
- Changed the proxy pass protocol from HTTP to AJP
Of course, there are a lot of other things that could be done. There are other guides on the internet describing how to tune an Apache HTTPD server, but for this scenario and use case, we found that these configurations were enough to accomplish our customer requirements.
Embedded Tomcat
The role of the Tomcat Server in this architecture is to serve as a servlet container to the Apache Camel REST component. This implementation is managed by the Spring Boot Web as an embedded server. There are other servlet implementations to work with Spring Boot and Apache Camel like Undertow and Jetty that might perform better, but the requirements of the customer were not to change any piece of their architecture.
Having said that, what can be done at the configuration level to have the Apache Tomcat Server perform better?
Adjusting the connection parameters
First of all, like we said in the Apache HTTPD section, the Tomcat server was tested alone to figure out how many requests it could handle in the most common use cases.
For this task you could use the Pareto distribution to have a sample amount of requests to test the application. For example, using an API which reads, creates, and deletes customers, the read and create operation could be the most common use case. You can create a small set of sample requests and start putting some workload on your server. JMeter is a reasonable tool to do that, and we used this tool in our lab.
Having come up with the max concurrent requests that the application could handle during a certain period of time without breaking, we adjusted the server parameters like this:
| Parameter | Value | Description |
| Connection Timeout (ms) | 30000 | This value is aligned with the Apache HTTPD proxy server timeout and has shown to be a reasonable number for our scenario. |
| Compression | False | We are serving only small JSON payloads, and in our tests the compression didn’t make any noticeable difference. Besides, this can be set only at the proxy server level. |
| Max Connections | 400 | A little more than the max connections at the proxy server side, so we had room to handle extra connections that could come between requests. |
| Max Threads | 300 | This number seems reasonable for our resources and number of connections to handle. Each thread can handle more than one connection. |
| Min Spare Threads | 300 | There’s no warm up for this server, which means that during high load there is no need to create more threads reaching the max to handle all the requests. But during idle or low workloads, these threads are up, although doing nothing. In our scenario, there wasn’t too much idle time that would justify decreasing this number. |
| Accept Count | 100 | The number of connections waiting to be handled. If we reach the max connection number, the server starts to stack requests in this queue before denying a reply to the client. |
Of course, a lot of experimentation and load tests had been done. These numbers are for reference only and are the ones set in our lab. These numbers can be completely different depending on your requirements. Just keep in mind the responsibility of evaluating each parameter and determining what you can do to improve the performance of your server by fine-tuning each one. Take a look at the documentation to understand the parameters that can be configured in the Tomcat connectors.
Using Tomcat Native Connectors
The next adjustment made on the Tomcat server was to use the native connectors to handle the connections coming up from the proxy server. Quoting from the official documentation:
“The Apache Tomcat Native Library is an optional component for use with Apache Tomcat that allows Tomcat to use certain native resources for performance, compatibility, etc.”
The decision to use the native libraries was guided by the performance improvements this can offer versus the standard Java libraries like BIO or NIO, leveraging from the OS capabilities to handle I/O operations.
For this to work we had to install the APR library on our server, employ the native connectors, and create a custom embedded Tomcat server constructor on the Spring Boot side. The custom constructor was also used to set the configuration listed in the table above, because not all the Tomcat configurations can be set using the default application properties from the Spring Boot Tomcat embedded server.
@Bean
public EmbeddedServletContainerFactory servletContainer() {
TomcatEmbeddedServletContainerFactory tomcat = new TomcatEmbeddedServletContainerFactory();
tomcat.addConnectorCustomizers(this.customizer(tomcat));
if (ajpPort != null) {
Connector ajpConnector = new Connector(PROTOCOL);
if (enableApr) {
tomcat.addContextLifecycleListeners(new AprLifecycleListener());
ajpConnector = new Connector("org.apache.coyote.ajp.AjpAprProtocol");
}
ajpConnector.setPort(ajpPort);
tomcat.addAdditionalTomcatConnectors(ajpConnector);
}
return tomcat;
}
Final thoughts
The customizations made on the Tomcat side to tune our environment were:
- Set the max connections and timeout values to align with the Apache HTTPD web server and prevent excessive load on the Tomcat server.
- Installed APR and used the native AJP connector for I/O performance improvements.
- Customized the default Spring Boot embedded Tomcat constructor to set the properties not externalized by the Spring Boot properties component.
- Tweaked the connection and thread parameters to establish numbers that performed well during our load tests.
Besides the requirement from our customer to not change the source code, this custom embedded Tomcat can be placed in the actual embedded server dependency of a project. Alternately, we can go further and create a patch, since the Spring Boot project limits our ability to change the default connector.
There isn’t much to do at the Tomcat side besides experimentation. The main focus should be with the application that is using its servlet capabilities. A common scenario is a bad performatic application taking too long to return a reply, resulting in a bad experience for the client. But we can leverage several Tomcat parameters and connector implementations to improve the way that the server handles connections.
Apache Camel and Spring Boot
We finally arrive at the application layer after tweaking several knobs on the proxy and servlet server.
Tuning the GC algorithm
The Spring Boot component ties the embedded Tomcat server and the Apache Camel routes and components together. All of these components run on the same Java Virtual Machine (JVM) process, so we decided to start by tuning the JVM Garbage Collector (GC) algorithm.
Garbage Collector tuning deserves an entire article dedicated to it. As with the Apache HTTPD server tuning, there’s other articles on the internet talking about this subject. If you’re interested in a deep dive into it, give it a try using Oracle’s JVM Tuning documentation. This documentation doesn’t cover any particular use cases, but it provides good explanations of the structure of each algorithm.
If not set, the JVM tries to tune the GC by itself in a process called ergonomics. This could work in environments with a small load, but in our scenario, we decided to take control of our GC algorithm and experiment with it. In the end, the G1 was the chosen one. The decision was based on the following criteria:
- It’s the algorithm that performed better at our tests, taking into account our scenario, resources and architecture.
- It’s optimized to maximize the throughput with small pauses during the application life cycle, favoring REST applications that have high-throughput requirements.
If you have little or no knowledge about GC tuning, a starting point could be Red Hat’s JVM configuration Lab (subscription required). The Lab gives you some options to configure your GC that can lead you into fine-tuning once an algorithm is chosen.
Some aspects of the GC that you should take care of:
- Too many “full GCs” during application load. To perform a full GC, the GC starts an event called “stop the world” that is a pause in every running thread to free up memory. During those pauses, nothing is processed at the JVM, which might increase the application response time.
- Long pauses. Even if the GC are not performing too many “stop the world” events, it’s important to take a look into the pause times. Depending on your requirements, pauses of 1 second or more could impact your application. There are configurations to try to control such behavior.
A good tool to analyse the GC is Garbagecat or the gceasy website. The last one can give you a high level GC analysis based on your logs and could be a good starting point to understand the behavior of your GC.
Besides the GC algorithm chosen, there are two configurations that you should always set in any JVM configuration:
- GC logs output: to examine your GC behavior during the application load, you must enable the GC logs. You should not worry since you shouldn’t lose any performance and the logs will come in handy during troubleshooting.
- Heap dump on out of memory error: this is a must if you’re running into memory problems. The heap dump is a valuable artifact for memory leak troubleshooting or memory usage analysis. Just add the following option to your JVM configuration: -XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=<path>. To analyze the heap generated by the JVM, you could use the Eclipse Memory Analyzer Tool (MAT).
Switching to a async log appender
In this particular scenario we observed that the application had heavy audit log requirements. In our scenario, the application logged every input and output message for auditing and monitoring purposes. In a high load environment this could lead to a high disk usage during the current execution thread.
The default implementation of popular logs frameworks in Java is the synchronous log, that is, every time the application needs to log something in the disk, the current execution thread is responsible for writing the log content to the disk.
To avoid interfering in the current execution thread while writing to the disk, we switched the log appender to an asynchronous one. The log implementation is Logback, which has an interesting async feature that can minimize the risk of losing logs. We ended up with the following configuration:
<appender name="ASYNC-app" class="ch.qos.logback.classic.AsyncAppender"> <appender-ref ref="app" /> <discardingThreshold>0</discardingThreshold> <queueSize>500</queueSize> </appender>
Setting the option “discardingThreshold” to zero, the appender won’t discard any log events even if the queue is full, but the blocking queue will stop until everything is written. Some experimentation is needed to adjust queue size with the expected load. Ideally, this queue does not reach its limit.
Final thoughts
Finally, in the end we came up with the following conclusions:
- JVM tuning and experimentation: we decided to go with with G1 algorithm due to its throughput maximization nature.
- GC logs were turned on to capture data to be analyzed later, giving us valuable information used to configure the GC algorithm.
- Turned the log appenders to async due to the high audit log usage by the Apache Camel routes.
The Spring Boot Apache Camel Java application was the last part of our scenario’s architecture to be reviewed.
The Replication Lab
Each tuning aspect discussed up to this point in our example scenario can be explored using a demonstration lab available at our repository in Github.
This lab replicates tools and machines used during our experience of tuning this architecture. The lab was created to support this article and to serve as a sandbox for anyone who wants to experiment with this scenario and compare each aspect of tuning. The figure below illustrates the components provided by this lab:
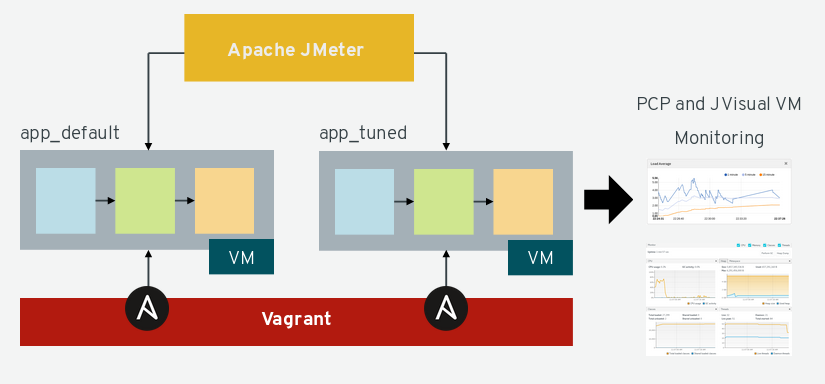
The lab is composed of a Vagrant file, ansible playbooks and a demo Spring Boot Apache Camel application. With Vagrant you can set up a virtual environment in an operating system. Ansible also plays an important role since we used it to:
- Install the required software: the HTTPD Server, Java, Python 3 and PCP (Performance Co-Pilot).
- Deploy the application and the mock external service: the Spring Boot application is installed as a systemd service with its configuration set in the startup scripts. Ansible also runs a script to provide a Python 3 web service for mocking external calls from the Apache Camel routes.
- Open the required ports for PCP and JMX monitoring.
- Apply the tuned configurations on every component of the architecture: HTTPD and Spring Boot configuration, APR and Tomcat native connectors.
For more detailed information about how Ansible was used in this lab, take a look at the playbooks.
To be able to run this lab in your environment, you must first install the required tools, which are basically Maven, Vagrant and Ansible. After that, just run the script start.sh and you should be ready to go. For a detailed explanation of how to use this demo, refer to the instructions in the Github repository.
Load Tests
The demo lab also includes a JMeter load test project ready to be used. This load test was configured to run simultaneously in both machines (default and tuned) to be able to compare the benchmarks and their behavior at the same time.
The test spares 150 threads and has a ramp-up period curve of two and a half minutes. This means that every second one user is added to the test until a total of 150 is reached. Once this threshold is reached, the test continues indefinitely.
In our tests, after approximately ten minutes the machine that hadn’t been tuned stopped answering our requests and started to return proxy errors. After investigation, we discovered that the JVM just stopped responding, or the process exhausted its resources and stopped itself. The tuned machine kept responding to approximately almost all of the requests until we stopped the test.
The table below illustrates the test results of one of our test runs, performed during 20 minutes:

The tuned machine kept a regular pacing of responses while the untouched one started to time out our requests:
Non HTTP response code: org.apache.http.conn.ConnectTimeoutException/Non HTTP response message: Connect to app.local:80 timed out
Looking at the transactions per second (TPS) chart, we can visually confirm the difference between them:
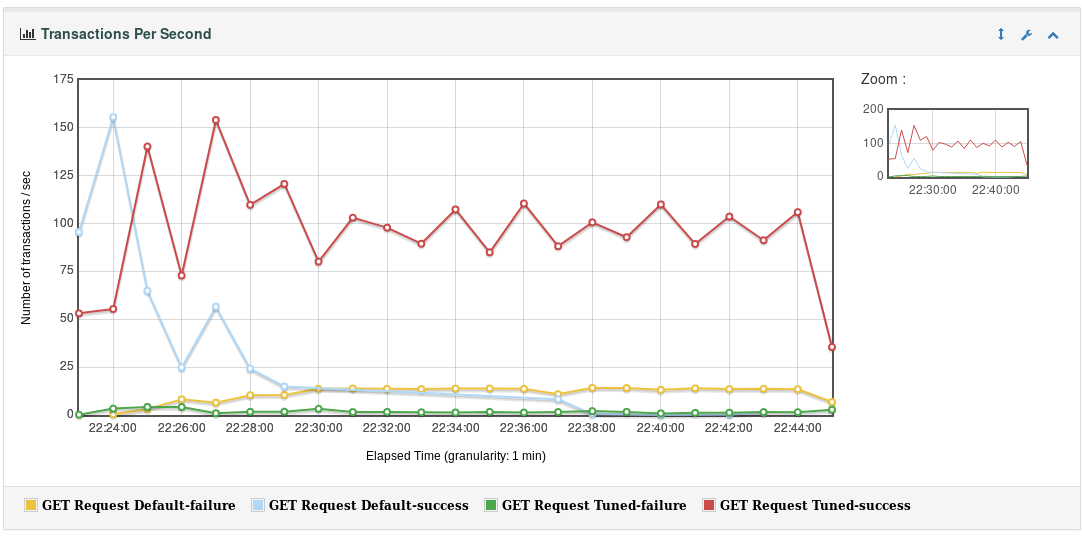
At first, both machines kept almost the same TPS, but over time the tuned one was more reliable.
Observing each machine’s resource usage, things get more interesting. The charts below were taken from running this same test using PCP:
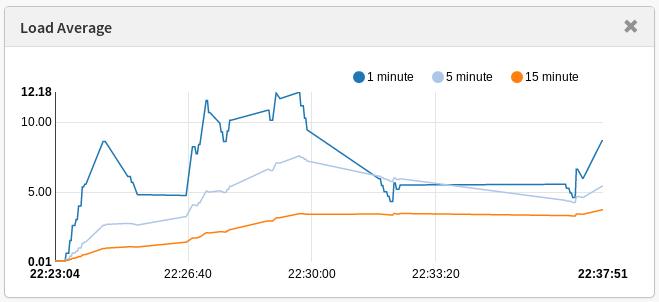

The load average on the default machine, executing the same processes, with the same workload as the tuned machine, had twice the system load when compared to the tuned one.
You can try this performance test for yourself by using the Github repository as a reference to set up your own environment. You should be able to expect similar results to the results discussed in this post. Try running other kinds of tests like bursting a ton of requests in a short period of time, or even increasing the load above 150 users.
Conclusion
In this post we discussed some aspects of tuning an Apache Camel REST application deployed into Spring Boot serving HTTP requests behind a proxy server, and how to exercise what was discussed by replicating the fictional scenario using a demonstration lab.
It’s worth noting that even if a component or software comes out of the box ready to use, such as the HTTPD server using the MPM prefork or the JVM ergonomics, your application can be extensively improved by running performance tests and configuring the environment accordingly.
The tuning topics addressed in this post aren’t rocket science nor should they be too difficult to implement. Today, if you neglect tuning, the platform could hide bottlenecks from you by scaling your application once it reaches a certain limit, or by restarting the container if the application stops responding.
Even if your cloud platforms are engineered to maintain application reliability at high levels, it should be worth the time required to properly tune your application. Tuning allows you to leverage the platform and your computational resources even more, while still improving your overall application quality metrics.
À propos de l'auteur
Plus de résultats similaires
Au-delà de l'horizon : naviguer entre les technologies d'aujourd'hui et l'IA de demain
Introducing Quarkus on Red Hat OpenShift
Communicating the Value of Connecting Systems | Code Comments
Parcourir par canal

Automatisation
Les dernières nouveautés en matière d'automatisation informatique pour les technologies, les équipes et les environnements

Intelligence artificielle
Actualité sur les plateformes qui permettent aux clients d'exécuter des charges de travail d'IA sur tout type d'environnement

Cloud hybride ouvert
Découvrez comment créer un avenir flexible grâce au cloud hybride

Sécurité
Les dernières actualités sur la façon dont nous réduisons les risques dans tous les environnements et technologies

Edge computing
Actualité sur les plateformes qui simplifient les opérations en périphérie

Infrastructure
Les dernières nouveautés sur la plateforme Linux d'entreprise leader au monde

Applications
À l’intérieur de nos solutions aux défis d’application les plus difficiles
Virtualisation
L'avenir de la virtualisation d'entreprise pour vos charges de travail sur site ou sur le cloud