
One of the key capabilities provided by OpenShift Container Platform is Source to Image (S2I) - the framework that enables us as developers to write images that take application source code and runtime frameworks as an input, and produce a new image that runs the assembled application as the output.
As part of Red Hat’s Professional Services organisation, I work with many clients who are using the xPaaS Maven S2I builders to produce their application images - and one of the questions I get asked frequently is “how does S2I handle Maven multi-module projects?’
In this post, I will look at how to use multi-module builds with Red Hat JBoss Enterprise Application Platform (EAP), and Red Hat JBoss Fuse Integration Services (FIS), and how you can create a single project that enables builds for both frameworks using a simple and scalable approach.
Why Use Multi-Module Builds?
Consider the scenario - you might have an existing project that you’re looking to migrate into OpenShift, or maybe a greenfield development. You know up front that the project is going to have some common dependencies between its components. Data models are a classic example of this. In either case, you might use Maven’s multi-module capability to:
- Collect all the available components that make up an application into modules in a single source control repository.
- Allow each module to have its own build, test, and deployment lifecycle.
- Allow each module to have a well-defined place in a build order, with its dependencies understood and catered for as part of that build.
By default, OpenShift’s Maven-enabled S2I builders will expect a single module at build time, enforcing a one-to-one mapping between source repository and output image. However, these builder images do provide standard approaches to customising the build process in such a way that allows you to create each of these modules as discreet containers, retaining a familiar project structure for the developers working on the project whilst still recognising the benefits gained from deploying each executable module as its own container.
Customising S2I with a Multi-Module Build
Example Project - Country Generator App
For the purposes of the exercise, we will be looking at a small example project which, whilst contrived, does demonstrate how you might enable multi-module builds using S2I and OpenShift. It is made up of three individual modules:
- FIS - a RESTful web service defined using Camel’s REST DSL. This service wraps a Camel route that retrieves a random Country name from a file and returns it as a JSON payload to the client. Based on the Fuse Integration Service image for Java.
- Web - A very simple web project that presents a servlet which in turn uses a client class to call the web service and display the random Country name received in a web page. Based on the Enterprise Application Platform 7.0 image.
- Common - Common dependencies shared between the *Web* and *FIS* modules. Image agnostic.
You will note that as the imaginatively named Common module contains common resources for both the FIS and Web modules, it needs to be built to satisfy the dependencies of each dependent module.
Build Configuration
The key thing to remember when working with these multi-module builds in OpenShift, is that each module should be treated as a discrete component, regardless of the provenance of the source code you’re building from. Therefore, like every standard S2I build, you will have a BuildConfig object for each component you’re building, which will look a little like this:
objects:
- apiVersion: v1
kind: BuildConfig
metadata:
...
spec:
output:
...
sourceStrategy:
env:
- name: MAVEN_ARGS_APPEND
value: -pl fis --also-make
- name: ARTIFACT_DIR
value: fis/target/
- name: MODULE_DIR
value: fis
from:
kind: ImageStreamTag
name: fis-java-openshift:latest
namespace: openshift
type: Source
triggers:
...
status: {}
Note that sections of this configuration have been omitted for brevity.
The important part of this BuildConfig, and the section that separates it from a standard build, are the environment variables. Like many images, the runtime behaviour of the S2I builder can be influenced by environment variables - in this case MAVEN_ARGS_APPEND and ARTIFACT_DIR:
- MAVEN_ARGS_APPEND - Extra arguments passed to mvn, e.g. -pl groupId:module-artifactId -am
- ARTIFACT_DIR - The Maven build directory relative to the project root, e.g. module/target/
For MAVEN_ARGS_APPEND, the arguments that enable individual modules to be built should be added here:
-pl <module name>- Tells Maven which module to build.--also-make(or-am) - Tells Maven to build the dependencies for the module referenced in the-plargument.
One point of interest here is that we are using MAVEN_ARGS_APPEND to alter the build behaviour in an additive manner - so the default Maven build command will be executed, with our arguments appended. If you need more control over the build behaviour at this level, you can use the MAVEN_ARGS environment variable instead, as this will effectively overwrite the default build command. For example:
clean package -DskipTests=true -pl <module name> --also-make
There is no right or wrong way to do this - it’s simply a question of how much you need to influence the build.
For ARTIFACT_DIR, we simply need to inform the S2I builder image where it should pick up the build artifacts once the build is complete. Unless you have explicitly configured your Maven build differently, this will have a value of <module name>/target/.
Recognition of these environment variables and the behaviour they drive is consistent across the Red Hat xPaaS images, enabling developers to have a standardised approach for configuring the behaviour of their builds.
NOTE: We’ll look at MODULE_DIR later - this is a specific environment variable to drive bespoke behaviour that will be covered later in this post.
At this point, if you were to go ahead and instantiate an xPaaS-oriented BuildConfig containing these environment variables, you would have a multi-module aware S2I build process. But we can take this further.
S2I Scripts
The approach described above, whereby we influence the behaviour of a build using environment variables, is entirely adequate for most use cases related to multi-module builds and S2I. However, for the corner cases where you need more fine-grained control over what the build actually does, we can turn to the S2I scripting mechanism.
By default, a multi-module build pulls down the entire source code repository, and will look in the root of that directory structure for a number of elements which might influence the build. One of these elements is the .s2i directory, which will contain some optional scripts to drive the build and runtime behaviour of the images.
The problem we have here is that out of the box, S2I will only honour the scripts in this root folder. However, given that we are generating images from modules within the project structure, we might want to have S2I scripts to influence how the module is packaged into its image, and how that image is executed.
In this scenario, we are interested in the assemble and run scripts.
Assemble
The assemble script uses the MODULE_DIR environment variable mentioned earlier to introspect the modules of the build, and see if any of the modules have specific .s2i directory structures and associated scripts - again, the scripts we’re looking for are assemble and run - but this time at the module level, rather than the root (parent) of the project.
#!/bin/bash
set -eo pipefail
S2I_SCRIPT_DIR="/usr/local/s2i"
S2I_SOURCE_DIR="/tmp/src"
function check_run {
if [ -f $S2I_SOURCE_DIR/$MODULE_DIR/.s2i/bin/run ]; then
echo "Custom run script found. Using this instead of the default."
mkdir -p /deployments/scripts/$MODULE_DIR/
cp $S2I_SOURCE_DIR/$MODULE_DIR/.s2i/bin/run /deployments/scripts/$MODULE_DIR/
else
echo "Using default run script"
fi
}
function check_assemble {
if [ -f $S2I_SOURCE_DIR/$MODULE_DIR/.s2i/bin/assemble ]; then
echo "Custom assemble script found. Using this instead of the default."
$S2I_SOURCE_DIR/$MODULE_DIR/.s2i/bin/assemble
else
default_assemble
fi
}
function default_assemble {
echo "Using default assemble script"
$S2I_SCRIPT_DIR/assemble
}
echo "Checking for module-specific S2I scripts..."
if [ x"$MODULE_DIR" != "x" ]; then
check_run
check_assemble
else
default_assemble
fi
Why are we checking for the existence of both assemble and run here in the assemble script? The assemble script is used to build out the runtime container image. So we use it to make sure that if there is a custom run script defined, this is the script that will be executed as the entry point into the container at runtime.
If MODULE_DIR isn’t defined in the BuildConfig, or no customised script exists in the location suggested by MODULE_DIR then the defaults will be used.
Run
During the build, the assemble script will check for the existence of a module-specific run script. If it exists, it will be copied to a predetermined location and executed at runtime. However, this execution does not happen automatically, and as a consequence we need to bootstrap this process with what is effectively a placeholder run script at the root level of our project.
This placeholder script does not need to be complicated, and if you have no intention of customising the runtime behaviour, it doesn’t need to exist at all - but if it does exist, it will either be calling your module-specific run script, or the default run script embedded in the image. Therefore the placeholder script only has to have, as a minimum, the following content:
#!/bin/bash
set -eo pipefail
# Master run script.
# Due to the decision tree in the Dockerfile, if we just copy the module script in, it's not recognised at runtime.
# If we have this here, then use it to bootstrap the module run script, everything works.
S2I_SCRIPT_DIR="/usr/local/s2i"
if [ -f /deployments/scripts/$MODULE_DIR/run ]; then
echo "Using module specific run script"
exec /deployments/scripts/$MODULE_DIR/run
else
echo "Using default run script"
exec $S2I_SCRIPT_DIR/run
fi
At the module level, we then have our own run script for the FIS module:
#!/bin/bash
set -eo pipefail
if [ x"$DATA_DIRECTORY" != "x" ]; then
mkdir -p $DATA_DIRECTORY
cp /tmp/src/fis/src/main/resources/data/* $DATA_DIRECTORY
else
echo
echo "Oops. Did you forget to set the DATA_DIRECTORY environment variable?"
echo
export DATA_DIRECTORY="/tmp/data"
mkdir -p $DATA_DIRECTORY
echo "Pugh, Pugh, Barney McGrew, Cuthbert, Dibble, Grub" > $DATA_DIRECTORY/data.csv
fi
exec /usr/local/s2i/run
This script checks for the existence of an environment variable, copies some data from our source repository and puts it in the location defined by that variable where it can be read by the Camel route defined in the FIS module. If the environment variable isn’t defined in the DeploymentConfig object, then the script artificially adds it to the environment, and generates some mock data to be read from that location.
NOTE: In reality, this kind of data would be kept outside the container (good practice when working with containers dictates that they should be stateless and immutable unless an explicit use case demands otherwise), and the application might be designed to fail fast if its configuration properties were not present - but this example serves its purposes by simply demonstrating that the script is called, and an output is generated.
Putting it all Together
In this section, we will put all the pieces together and see how they interact.
Template
The first step, if you haven’t already done so, is to create a project in which to build and deploy your application. We will call our project countries, but you can call yours whatever you like.
oc new-project countries
In order to simplify the process of deploying this project, an example OpenShift template has been provided, which should enable you to see the configuration options which enable multi-module builds more easily. You can import this template into OpenShift by executing the following command in your OpenShift client tools:
oc create -f https://raw.githubusercontent.com/benemon/multi-module-s2i-project/b1.0/openshift/multi-module-example.yaml
This should add the template to your project. If the process completes successfully, you’ll receive a message similar to the following:
template "multi-module-example" created
Now, in order to get to the good bit, we need to instantiate the template. This will create a number of Kubernetes objects within your project, but we’re mostly interested in the BuildConfig. Execute the following command with the client tools:
oc new-app --template=multi-module-example
You’ll see output similar to the following:
--> Deploying template multi-module-example
* With parameters:
* SOURCE_REPOSITORY=https://github.com/benemon/multi-module-s2i-project
* SOURCE_REF=b.10
* DATA_DIRECTORY=/deployments/data
--> Creating resources with label app=multi-module-example ... buildconfig "country-service" created buildconfig "country-web" created deploymentconfig "country-service" created deploymentconfig "country-web" created imagestream "country-service" created imagestream "country-web" created service "country-service" created service "country-web" created route "country-service" created route "country-web" created --> Success Build scheduled, use 'oc logs -f bc/country-service' to track its progress. Build scheduled, use 'oc logs -f bc/country-web' to track its progress. Run 'oc status' to view your app.
You can see that the SOURCE_REPOSITORY, SOURCE_REF and DATA_DIRECTORY environment variables are automatically populated - if you were to instantiate this template via the web console, you would see the same values here with pre-populated fields:
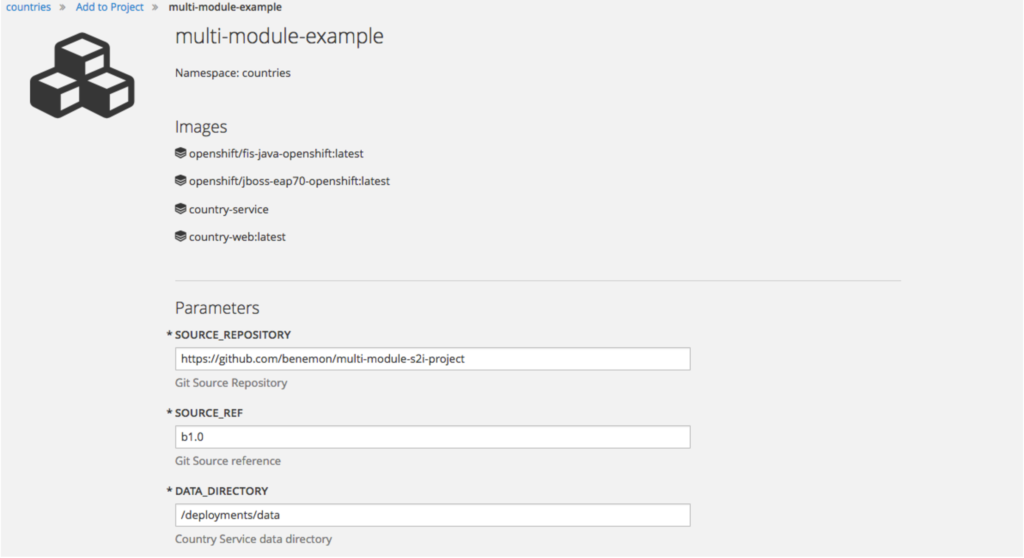
Builds
If we now log in to the web console (if you haven’t already) and look at the Builds tab in the web console, we can see that the two builds have been created - one for country-service (our FIS module), and one for country-web (our EAP module):

Given that we know we have a customised set of S2I scripts for the country-service module, we can check the output of the build process to make sure our custom scripts are being detected:
Cloning "https://github.com/benemon/multi-module-s2i-project" ...
...
Checking for module-specific S2I scripts...
Custom run script found. Using this instead of the default.
Using default assemble script
==================================================================
Starting S2I Java Build .....
Maven build detected
Using custom maven settings from /tmp/src/configuration/settings.xml
...
Copying Maven artifacts from /tmp/src/fis/target/hawt-app to /deployments ...
Push successful
Parts omitted for brevity.
The lines to pay attention to here are the lines that state:
Custom run script found. Using this instead of the default.
Using default assemble script
This signifies that, as per the instructions in the assemble script we created, the build has identified that we have an S2I run script in the module we’re building (FIS) and that needs to be used instead of the default script shipped with the image.
Running the Example
The template we used to create our application components in the OpenShift project will create a DeploymentConfig for each of the images we are building from our multi-module project. One will spin up the Web module, and the other will spin up the FIS module.
Once the S2I process has successfully built the modules as images, the deployment process will happen automatically. The status of the deployment can be checked by navigating to the Pods view.
NOTE: When deploying this example into the CDK, or any other similarly resource-constrained OpenShift environment, you can sometimes experience image push failures from the integrated Docker Registry when running simultaneous build processes (even if you can see that the actual Maven build completed successfully). Simply repeat the failed builds sequentially, and they should go through.
You should eventually see output similar to the following:

From this screen, we can see that country-service and country-web have their own runtime Pods and builder Pods. The builder Pods will be marked as Completed, and the runtime Pods should be Running.
Checking the log output for the country-service Pod should give you some initial output similar to the following:
Using module-specific S2I script
Executing /deployments/bin/run ... Launching application in folder: /deployments ...
What you see here is the output from the run script informing us that we are using our own version of the script.
Furthermore, each module has its own Kubernetes Route and Service. The FIS module is hosted on its own route with a context of /country - e.g. http://country-service-countries.rhel-cdk.10.1.2.2.xip.io/country - and the Web module is hosted on its own route with a context of /web - e.g. http://country-web-countries.rhel-cdk.10.1.2.2.xip.io/web.
Using these Routes, you can see the JSON output generated by the FIS module...
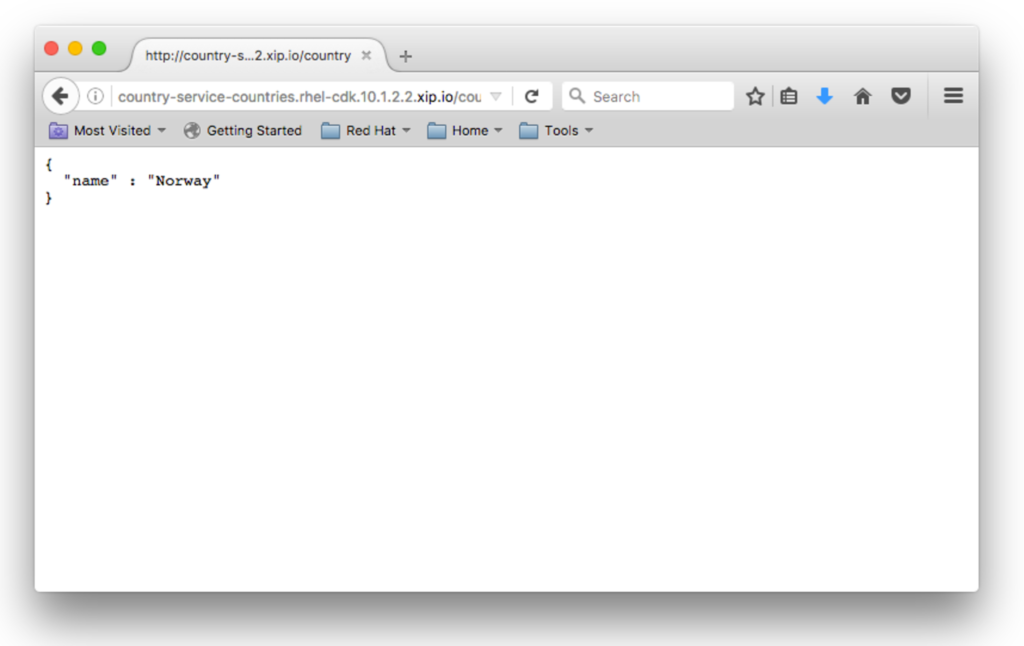
...versus the slightly prettier output generated by the Web module after it has made a web service call to the FIS module:
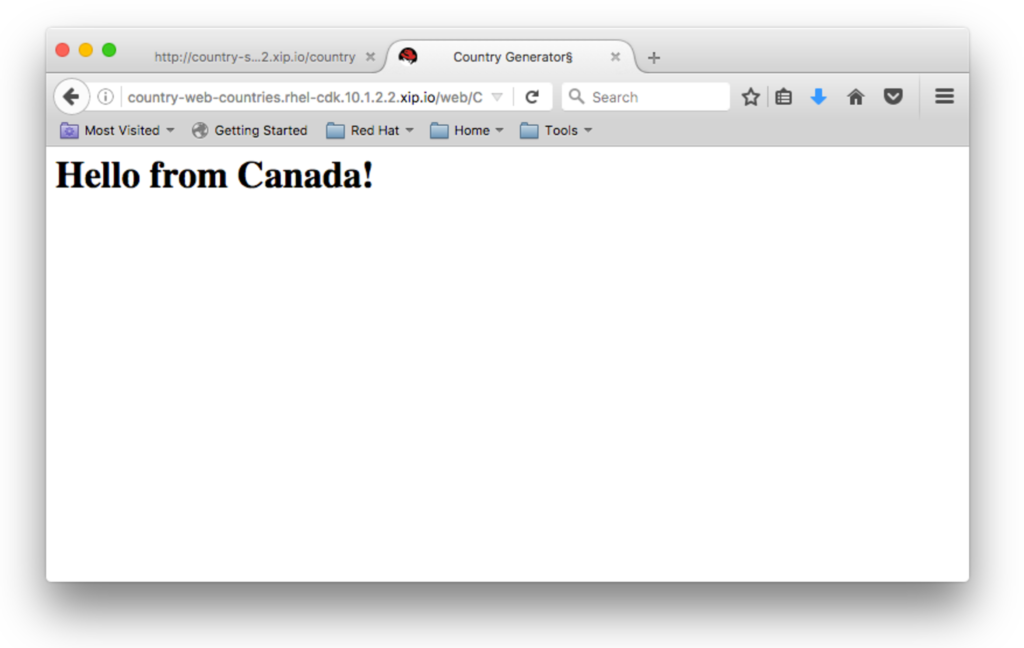
If you feel so inclined, you can examine the logs of both the Web module and the FIS module to see a record of traffic between the two containers.
Your Routes will be different to those in this example as they are generated based on the environment and project name you’re running in, although the context paths will be the same. Furthermore the output of the FIS service is entirely randomised, so it is highly unlikely that you’ll see the same output from the FIS module and the Web module in two consecutive requests.
Conclusion
There is no need to move away from Maven’s multi-module approach to building and deploying application when working with OpenShift, if that is a process you’re familiar with. It can become a powerful tool for helping break apart existing applications into more consumable microservices as it goes some way to enabling each component to have its own lifecycle, regardless of how the source code repository is managed. Sometimes it may require a little bit of customisation to give you the behaviour you need, and hopefully you’ll get some insight into how that customisation is achieved through this post.
Have a look at the examples, try it out yourself, and see how this approach might work for you!
Resources
NOTE: The stable version of this project is tagged as version b1.0. While the master branch may be stable, I cannot guarantee that it will continue to match the steps and narrative this post provides.
- Example Source Code - https://github.com/benemon/multi-module-s2i-project/tree/b1.0/
- S2I Script Overview - https://docs.openshift.com/container-platform/latest/creating_images/s2i.html#s2i-scripts
- Red Hat xPaaS Overview - https://access.redhat.com/documentation/en/red-hat-xpaas/
À propos de l'auteur
Plus de résultats similaires
Le paradoxe agentique et l'intérêt de l'IA hybride
Cessez de gérer le passé et commencez à bâtir l'avenir de l'informatique
Ready to Commit | Command Line Heroes
The Fractious Front End | Compiler: Stack/Unstuck
Parcourir par canal

Automatisation
Les dernières nouveautés en matière d'automatisation informatique pour les technologies, les équipes et les environnements

Intelligence artificielle
Actualité sur les plateformes qui permettent aux clients d'exécuter des charges de travail d'IA sur tout type d'environnement

Cloud hybride ouvert
Découvrez comment créer un avenir flexible grâce au cloud hybride

Sécurité
Les dernières actualités sur la façon dont nous réduisons les risques dans tous les environnements et technologies

Edge computing
Actualité sur les plateformes qui simplifient les opérations en périphérie

Infrastructure
Les dernières nouveautés sur la plateforme Linux d'entreprise leader au monde

Applications
À l’intérieur de nos solutions aux défis d’application les plus difficiles
Virtualisation
L'avenir de la virtualisation d'entreprise pour vos charges de travail sur site ou sur le cloud