In a previous blog post we took a look at the Red Hat Container Development Kit (CDK) and how it can be used to build and deploy applications within a development environment that closely mimics a production OpenShift cluster. In this post, we’ll take an in-depth look at what a production OpenShift cluster looks like -- the individual components, their functions, and how they relate to each other. We’ll also check out how OpenShift supports scaling up and scaling out applications in a production environment.
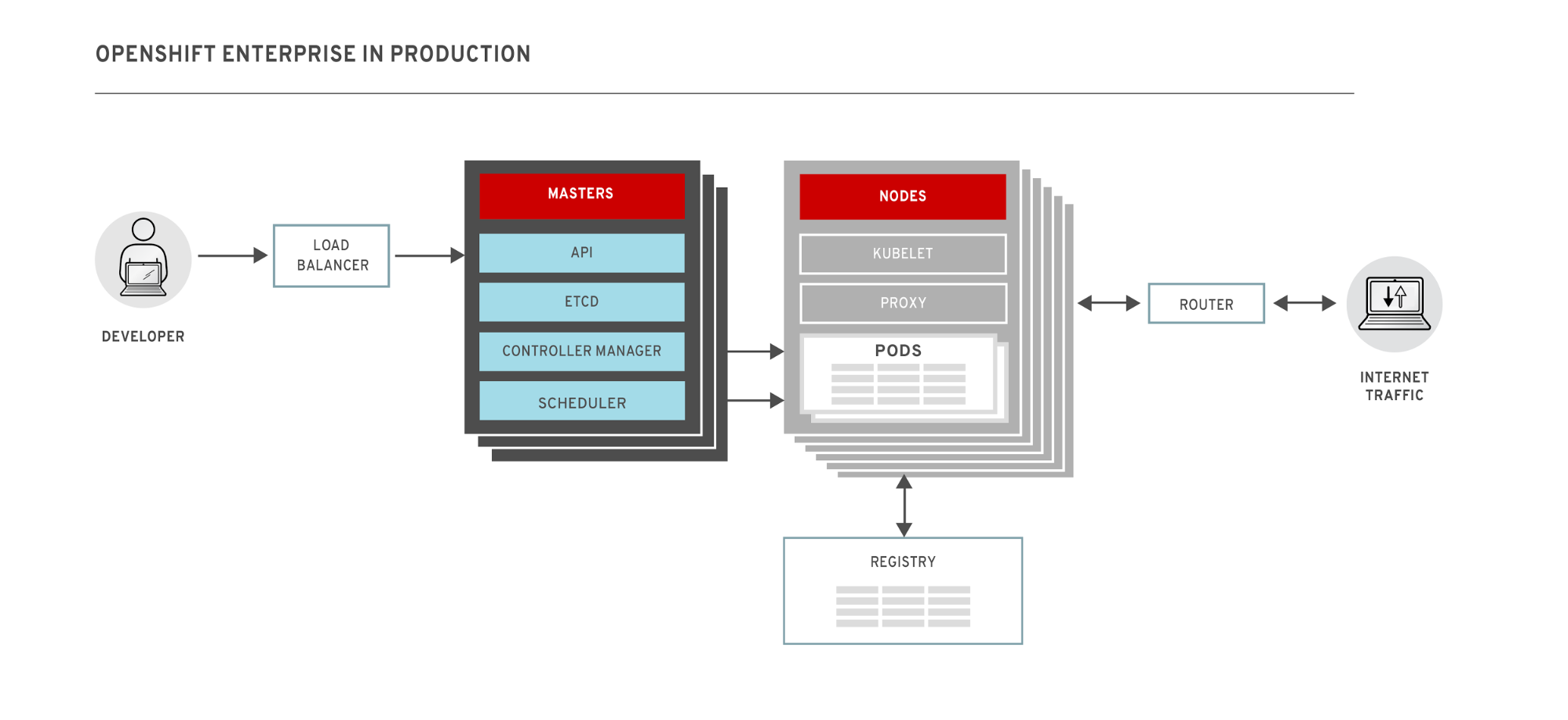
The immediate and most obvious difference between a development OpenShift environment and a production environment is that a production cluster is made up of multiple masters, with redundancy built-in to ensure high availability (HA). In the diagram above, we show an example with three masters and five nodes. OpenShift schedules applications at the level of pods -- groups of applications which can consist of multiple containers. Applications running on pods are exposed by services -- static endpoints which route requests to the appropriate pods. This allows pods to be ephemeral -- they can come and go or move from node to node without affecting the end user’s experience in anyway.
The master nodes are responsible for managing the cluster and are made up of the following components:
- The scheduler, which is responsible for placing pods onto nodes.
- The controller manager, which is responsible for managing nodes and pods. At the node level, it is responsible for managing, monitoring, and adding resources. At the pod level, it will ensure that the correct number of pods are running for a given service and will start or stop pods as necessary.
- The API component provides the backend to the oc and kubectl commands that developers use to configure OpenShift. In particular, it is responsible for interpreting requests to start new services and delegating the work to the other components. In multi-master configurations, the API is behind a load-balancer which routes commands from developers to one of the masters.
- An etcd instance. Etcd is a distributed key-value store that is used to hold important configuration and state information for OpenShift. Etcd will fully replicate data across all masters for redundancy.
In a multi-master configuration, only one master acts as the active controller and scheduler. In the case of a failure or outage, an elegant leasing process results in the selection of the active master.
The worker nodes are responsible for running pods. Containers within a pod are always co-located (a pod cannot straddle two nodes) and will typically be tightly-coupled and/or require access to the same resources (e.g. files). Single container pods are common. All pods share a flat network space that is provided through software defined networking (SDN). Each pod will be assigned a unique IP address from the space and will be able to connect other pods, including those running on other nodes. OpenShift uses Open vSwitch for its SDN and includes support for multi-tenancy by assigning pods to projects which cannot communicate with pods from different projects.
Nodes also run the following components:
- The kubelet, which is the local agent on a node that is responsible for monitoring the node itself, as well as the pods on it. It will respond to requests from the master to start or stop pods as required.
- The proxy, which is responsible for routing incoming requests to service endpoints to the appropriate pod running on the host.
Master nodes can also be used to run pods, however it is generally considered best practice to avoid doing so, to ensure high-availability.
Finally there are two essential infrastructure components which will run on one of the nodes:
- The router, which is responsible for making services externally accessible. It will route requests from outside the OpenShift network to the appropriate service endpoint inside.
- The registry, which is a local Docker registry responsible for storing images for the cluster. A local registry is essential for OpenShift in order to provide s2i workflows. By default the registry will only be accessible by running pods, but can be exposed externally through the router.
Scaling
The major reason to run a multi-node, high-availability cluster like this is scaling. As an application grows in popularity and usage, it requires more resources to keep up with growing demand. Scaling can be be done both vertically and horizontally. The traditional approach is to go vertical, and provision bigger, faster servers on which to run our applications and databases. In OpenShift, this would simply mean augmenting the servers (or virtual machines) on which we run our OpenShift nodes.
A more flexible approach to scaling -- one that aligns better with our containerized, microservices architecture -- is to scale horizontally. This involves adding more servers (virtual machines or bare metal) to our existing environment and spreading the load across them. This approach lets us scale theoretically without limit, without touching the existing infrastructure. However, horizontal scaling requires more intelligence at the platform level in order to orchestrate work between multiple resources in parallel.
Horizontal scaling is ‘built-in’ to OpenShift through the services abstraction which exposes running applications. Scaling can be done manually, via the OpenShift web console or the CLI, by simply adding (or removing) additional pods. Via the web console, this is as easy as clicking the up (or down) arrows next to the pods graphic. For example, if we click on the up arrow in this deployment:
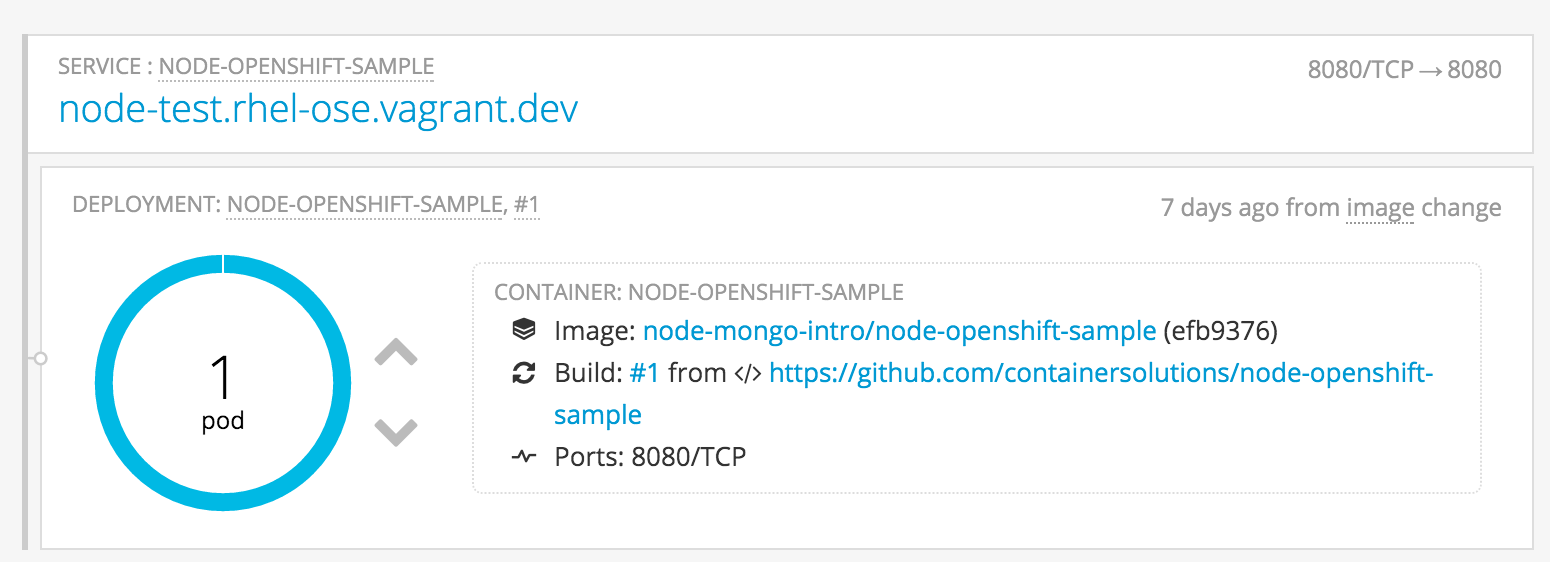
We will immediately see a second pod is provisioned, and should be running within a few seconds:

Another nice feature in the OpenShift web console is the ‘Topology View’. This gives us a high-level view of the entire project, showing each component and how they are related. An example can be seen in the following screenshot. At the base node, we have our deployment controllers represented by the gear icon. Linking directly off these are the replication controllers which we will look at in more detail in the next section. (Note that both replication controllers and deployment controllers are part of the controller manager component on the master.) Next, in blue, we see the pods which contain our running application. From there the service is shown in orange, and finally, if configured, the external route is shown in green. Selecting one of the components will show you its details, status and any additional pieces contained therein.
The screenshot shows how the topology changes as we use the CLI to scale up from one pod to five:
$ oc scale dc/node-openshift-sample --replicas=5
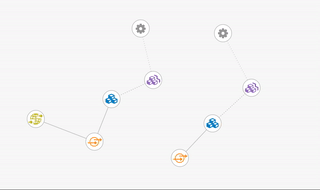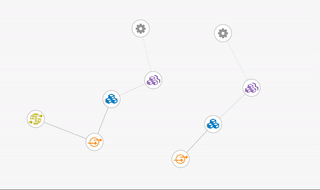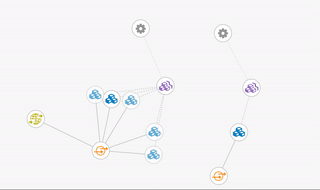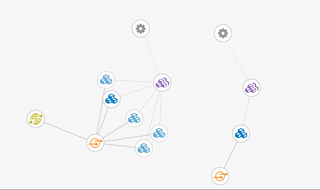
Here we can see the four additional pods being added to our existing service. This is great when we are expecting increased load, or in response to some monitoring telling us the system is becoming overloaded.
Autoscaling
We don’t really want to have to manually increase or decrease pod numbers as demand fluctuates. Instead the system should automatically take care of this by responding to changes in a given metric.
In OpenShift 3.1 this can be achieved with the Horizontal Pod Autoscalar controller from Kubernetes. The autoscaler works in tandem replication controller -- the component responsible for ensuring a given number of instances of a pod are running. If there are less pods running than the requested number of instances (either because the number was recently changed or pods exited unexpectedly) the replication controller will start new pods. Similarly, If there are more pods than requested, the replication controller will stop some.
The Horizontal Pod Autoscalar works with the replication controller by adjusting the specified number of instances (or replicas in Kubernetes parlance). The autoscalar periodically queries CPU utilization for each pod. The utilization is compared against the specified desired value, and if necessary, the autoscalar will adjust the number of replicas requested from the replication controller.
Christian Hernandez has a detailed walkthrough on how to configure horizontal autoscaling on his OpenShift blog.
Conclusion
We’ve taken a look at what OpenShift Enterprise looks like in a production environment and how this differs from development. We dove into the individual components which make up a production OpenShift cluster and the tasks they perform. This was followed by an in-depth look how OpenShift can be used to automatically scale up applications in response to increased demand.
OpenShift is built on top of the Kubernetes orchestration system and makes use of its advanced features for scheduling and scaling applications as we saw in this post. OpenShift extends Kubernetes to provides a complete, robust hosting platform that supports the full software lifecycle from development to production. A major feature is the powerful web UI for managing and configuring the cluster. Importantly, OpenShift uses proven Red Hat software throughout the stack, including Red Hat Enterprise Linux or Red Hat Enterprise Linux Atomic Host for running nodes, and container images from the Red Hat Registry. With the additional features of OpenShift, the end result is like Kubernetes on steroids.
À propos de l'auteur

Plus de résultats similaires
Cessez de gérer le passé et commencez à bâtir l'avenir de l'informatique
Le catalogue MCP est maintenant disponible : découvrez, déployez et connectez sur Red Hat OpenShift AI
Collaboration In Product Security | Compiler
Keeping Track Of Vulnerabilities With CVEs | Compiler
Parcourir par canal

Automatisation
Les dernières nouveautés en matière d'automatisation informatique pour les technologies, les équipes et les environnements

Intelligence artificielle
Actualité sur les plateformes qui permettent aux clients d'exécuter des charges de travail d'IA sur tout type d'environnement

Cloud hybride ouvert
Découvrez comment créer un avenir flexible grâce au cloud hybride

Sécurité
Les dernières actualités sur la façon dont nous réduisons les risques dans tous les environnements et technologies

Edge computing
Actualité sur les plateformes qui simplifient les opérations en périphérie

Infrastructure
Les dernières nouveautés sur la plateforme Linux d'entreprise leader au monde

Applications
À l’intérieur de nos solutions aux défis d’application les plus difficiles
Virtualisation
L'avenir de la virtualisation d'entreprise pour vos charges de travail sur site ou sur le cloud