
Cet article détaille le travail réalisé par les équipes d'ingénierie de Red Hat concernant l'exécution d'un système Oracle Database 19c à une instance sur Red Hat OpenShift Virtualization. Il fournit une architecture de référence complète, des résultats de validation (fonctionnalités, performances, évolutivité et migration à chaud), ainsi que des liens vers des artéfacts de test hébergés sur GitHub.
Nous démontrerons qu'OpenShift Virtualization offre des performances robustes pour les charges de travail de production exigeantes telles que les bases de données Oracle, ce qui en fait une solution de virtualisation particulièrement viable qui ne néglige pas les performances. Les résultats devraient surtout intéresser les responsables technologiques, les architectes, les équipes d'ingénierie et les responsables de projet impliqués dans l'évaluation et l'adoption d'un système Oracle Database à une instance exécuté sur OpenShift Virtualization.
Les principes de conception de l'architecture s'articulent autour de l'allocation des ressources, du partitionnement et de l'optimisation de la couche d'abstraction pour le calcul, le réseau et le stockage. Les tests de performances réalisés à l'aide de HammerDB avec la référence TPC-C prouvent qu'un système Oracle Database peut s'exécuter correctement sur OpenShift Virtualization avec un système de stockage NVMe local, dépassant les performances obtenues avec Red Hat OpenShift Data Foundation. Cet article aborde également l'observabilité et la surveillance, mises en œuvre à l'aide de Prometheus et Grafana pour fournir des informations propres à Oracle et à l'infrastructure.
Contexte
De nombreux clients cherchent des solutions de virtualisation qui ne négligent pas les performances. OpenShift Virtualization offre des performances robustes pour les charges de travail de production exigeantes, notamment les bases de données d'entreprise.
Dans les architectures logicielles traditionnelles, l'un des composants les plus courants est le système Oracle Database. Pour aider les clients qui souhaitent évaluer et adopter un système Oracle Database exécuté sur OpenShift Virtualization, nous proposons des ressources d'ingénierie dédiées qui leur permettent de bénéficier d'une expérience optimisée de l'utilisation d'Oracle Database sur OpenShift Virtualization.
Cet article s'adresse aux lecteurs qui maîtrisent Red Hat OpenShift Container Platform. Nous n'avons pas l'intention d'aborder l'architecture générique du système Oracle Database ni l'optimisation des performances. En revanche, nous présenterons les options de l'architecture qui permettent d'installer et de configurer OpenShift Virtualization pour que le système Oracle Database atteigne des performances maximales.
Cet article s'adresse aux professionnels impliqués dans l'évaluation, la validation et la prise de décision concernant l'adoption du système Oracle Database à une instance exécuté sur OpenShift Virtualization :
- Responsables technologiques (vice-présidents, directeurs techniques, etc.) : parties prenantes chargées d'optimiser le retour sur investissement (ROI) et le coût total de possession (TCO) des opérations quotidiennes liées à l'exécution des charges de travail Oracle Database dans un cloud hybride ou sur site.
- Architectes : les architectes client peuvent analyser l'architecture de référence et les résultats des tests afin de déterminer si OpenShift Virtualization est une plateforme viable pour héberger les charges de travail Oracle Database au sein de leur entreprise. Cet article présente les exigences de l'architecture et doit permettre aux architectes de réaliser des validations indépendantes.
- Équipes d'ingénierie : les équipes d'ingénierie peuvent exploiter les tests de performances utilisés par Red Hat lors de cette évaluation, ainsi que les artéfacts réutilisables disponibles sur GitHub, pour accélérer la configuration des tests et l'automatisation, rationalisant ainsi le processus de validation.
- Responsables de projet : les responsables de projet peuvent utiliser les architectures de référence pour identifier les composants concernés et les équipes responsables. Ils peuvent également utiliser les tests standardisés.
Présentation de l'architecture d'OpenShift Virtualization
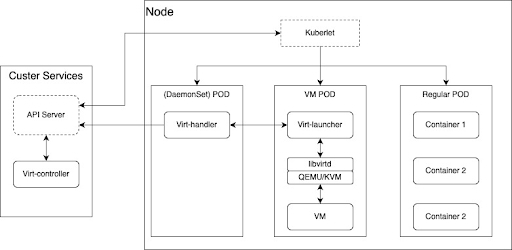
La solution OpenShift Virtualization est la mise en œuvre du projet Open Source KubeVirt, développée par Red Hat. Elle repose sur la plateforme OpenShift standard. Une machine virtuelle s'exécute dans un pod conteneurisé. OpenShift Container Platform gère les machines virtuelles de la même manière qu'un pod. Une instance de machine virtuelle a accès aux mêmes services de plateforme (sécurité, réseau et stockage) qu'une application de conteneur standard. La seule différence est que la machine virtuelle est gérée directement au niveau du pod, contrairement aux applications de charges de travail normales qui s'exécutent dans des conteneurs.
Composants de l'architecture :
- Kernel-based Virtual Machine (KVM) : l'hyperviseur de machines virtuelles sur OpenShift fait partie du noyau Linux.
- Instance de machine virtuelle : chaque machine virtuelle représentée par une instance de machine virtuelle est créée par QEMU à l'aide de KVM pour émuler le matériel. QEMU crée un isolement au niveau de l'espace utilisateur.
- KubeVirt : module complémentaire Kubernetes permettant de gérer les machines virtuelles en tant que ressources Kubernetes, comme des pods.
virt-operator: opérateur qui gère l'installation et la mise à jour des composants de KubeVirt.virt-controller: composant qui gère le cycle de vie des machines virtuelles (redémarrage en cas de défaillance, mise à l'échelle, etc.).virt-handler: démon sur un nœud avec KubeVirt qui gère des machines virtuelles sur des hôtes à l'aide de KVM/QEMU.virt-launcher: un par pod de machine virtuelle. Composant qui agit comme l'orchestrateur gérant le processus de machine virtuelle QEMU/KVM à l'intérieur du pod.- Ressources personnalisées : représentent une définition de machine virtuelle, l'exécution d'une instance de machine virtuelle et l'ordonnancement/les politiques.
- Wrapper de pod : sert de wrapper pour le processus QEMU. L'instance de machine virtuelle s'exécute dans le pod en tant que système d'exploitation invité virtualisé.
- Stockage : OpenShift Virtualization prend en charge diverses solutions de stockage, notamment des solutions natives pour Kubernetes comme OpenShift Data Foundation et Portworx, ainsi que des solutions d'entreprise plus traditionnelles comme iSCSI et le stockage SAN Fibre Channel (FC). Native pour Kubernetes, la solution de stockage OpenShift Data Foundation repose sur le projet Open Source Ceph et offre un système de stockage évolutif et redondant avec une couche d'abstraction optimisée pour les environnements Kubernetes. OpenShift Data Foundation prend également en charge le provisionnement dynamique des volumes persistants et des revendications de volume persistant, ce qui simplifie la gestion du stockage.
Pour ce projet de validation d'Oracle Database, nous allons étudier plusieurs options de stockage. Cependant, nous nous concentrerons sur OpenShift Data Foundation dans cet article parce que cette solution s'intègre de manière fluide à Kubernetes. Pour le déploiement de charges de travail Oracle Database, il est important d'évaluer et de sélectionner la solution de stockage qui répond le mieux aux exigences en matière de performances et aux besoins en matière d'exploitation.
Réseau : les machines virtuelles accèdent au réseau via Multus (méta plug-in CNI) ou la technologie SR-IOV (Single Root I/O Virtualization), où Multus est défini au niveau du pod.

Principes de conception d'Oracle Database
Lorsqu'un système Oracle Database s'exécute sur un système d'exploitation virtualisé, la machine virtuelle doit s'assurer que la base de données reçoit les ressources système adéquates pour fonctionner efficacement et rester résiliente. Les ressources réelles de l'infrastructure étant limitées, l'architecture de l'infrastructure doit être soigneusement conçue pour équilibrer l'allocation des ressources et s'adapter aux demandes variables des différentes charges de travail.
Pour augmenter les performances du système Oracle Database au niveau de l'infrastructure, il est recommandé d'appliquer les principes suivants :
- Emplacement des ressources : allouez suffisamment de ressources en matière de calcul, de stockage et de réseau pour éliminer les goulets d'étranglement.
- Partitionnement des ressources : lorsque les ressources sont limitées, partitionnez les ressources demandées et mettez en œuvre des solutions sur mesure pour répondre à certains besoins.
- Optimisation de la couche d'abstraction : évitez les couches d'abstraction inutiles ou à faible valeur ajoutée pour privilégier la flexibilité et les performances.
Les systèmes Oracle Database reposent sur trois principaux types de ressources système :
- Calcul : ce type de ressource inclut les processeurs virtuels, les threads d'E/S, la mémoire et la capacité de mise à l'échelle entre les nœuds.
- Réseau : le système Oracle Database est très sensible aux performances d'E/S. L'accès au client et l'accès au stockage ont des exigences distinctes en matière de débit et de latence. Par conséquent, les architectures Oracle Database utilisent souvent des réseaux distincts pour différents types de trafic.
- Stockage : les fichiers journaux Redo, les tables de base de données et les sauvegardes ont des besoins différents en matière de performances de lecture et d'écriture. Dans la mesure du possible, vous devez les placer sur un système de stockage physique distinct pour garantir des performances d'E/S optimales.
OpenShift Virtualization offre les capacités et la flexibilité requises pour adopter différentes approches en matière d'allocation des ressources, en fonction des besoins de partitionnement des ressources du système.
Architecture de référence
Cette section aborde les éléments à prendre en compte concernant l'architecture et les différentes options pour exécuter Oracle Database sur OpenShift Virtualization.
Calcul
Lorsqu'Oracle Database dispose de ressources de calcul suffisantes, la plateforme OpenShift Virtualization offre un contrôle direct sur les éléments suivants :
- Configuration de l'allocation des ressources vCPU et RAM pour la mise à l'échelle verticale des ressources
- Extensibilité du cluster OpenShift Virtualization pour l'évolutivité horizontale
- Contrôle de l'allocation du nombre de threads d'E/S des machines virtuelles pour éliminer les goulets d'étranglement d'E/S au niveau des pods
- Contrôle de l'allocation des ressources pour les machines virtuelles qui hébergent des charges de travail Oracle Database pour éviter toute situation de surallocation (allocation de plus de processeurs virtualisés ou de mémoire qu'il n'y a de ressources physiques sur le système)
Réseau
Le trafic du système Oracle Database présente des exigences de performances différentes en matière de latence du réseau, de débit et de fiabilité. Le plug-in Multus d'OpenShift Container Platform permet de partitionner le trafic réseau et d'utiliser plusieurs protocoles réseau. Tenez compte des éléments suivants :
- Mettez en œuvre différents chemins réseau pour le plug-in réseau OpenShift SDN, le stockage et les machines virtuelles.
- Pour les installations Oracle RAC, séparez davantage le trafic réseau pour assurer la communication entre les instances RAC et avec le réseau « public ».
- Pour les charges de travail essentielles sensibles à la latence et au débit, envisagez d'utiliser la technologie SR-IOV pour les interfaces réseau virtuelles créant un chemin direct depuis les machines virtuelles vers les ressources physiques sous-jacentes.
Stockage
Comme indiqué précédemment, OpenShift Virtualization prend en charge une multitude de solutions de stockage, des options natives pour Kubernetes comme OpenShift Data Foundation et Portworx aux systèmes d'entreprise traditionnels comme iSCSI et SAN Fibre Channel (FC). Cette flexibilité permet aux utilisateurs de choisir le stockage qui correspond le mieux à leurs besoins en matière de performances et d'exploitation.
Bien qu'il n'existe pas de règle universelle pour choisir la solution de stockage appropriée, il peut être recommandé de suivre les principes ci-dessous :
- Recherche d'un équilibre entre les besoins en matière de flexibilité d'exploitation (facilité de provisionnement, intégration à la plateforme) et les exigences en matière de performances (latence d'E/S, débit)
- Prise en charge de l'option multi-écriture (volume partagé entre deux machines virtuelles ou plus) qui peut être requise pour la base de données Oracle RAC
Configuration matérielle
La conception utilisée dans les tests de performances initiaux a été adaptée avec un ensemble de ressources matérielles actuellement disponibles sur le marché.
Spécification du cluster :
- 4 serveurs Dell R660
- 128 threads de processeur (2 sockets Intel Xeon Gold 6430)
- 256 Go de mémoire
- Disque racine de 1 To
- 4 disques NVMe de 1,5 To
- 4 cartes réseau Broadcom de 25 Gbit/s
- 2 cartes réseau Intel 810 de 25 Gbit/s
Configuration d'OpenShift Virtualization
Bien que la configuration par défaut d'OpenShift Virtualization et d'OpenShift Data Foundation offre des performances raisonnables, d'autres changements de configuration ont été apportés afin d'optimiser la plateforme de test pour les charges de travail aux E/S élevées, typiques des bases de données :
- Configuration d'OpenShift Data Foundation avec un profil de performances
- Configuration d'OpenShift Data Foundation et d'OpenShift Virtualization pour séparer le trafic de stockage d'OpenShift Data Foundation du trafic général du plug-in réseau OpenShift SDN (Chapitre 8. Configuration réseau requise | Planification du déploiement | Red Hat OpenShift Data Foundation | 4.18)
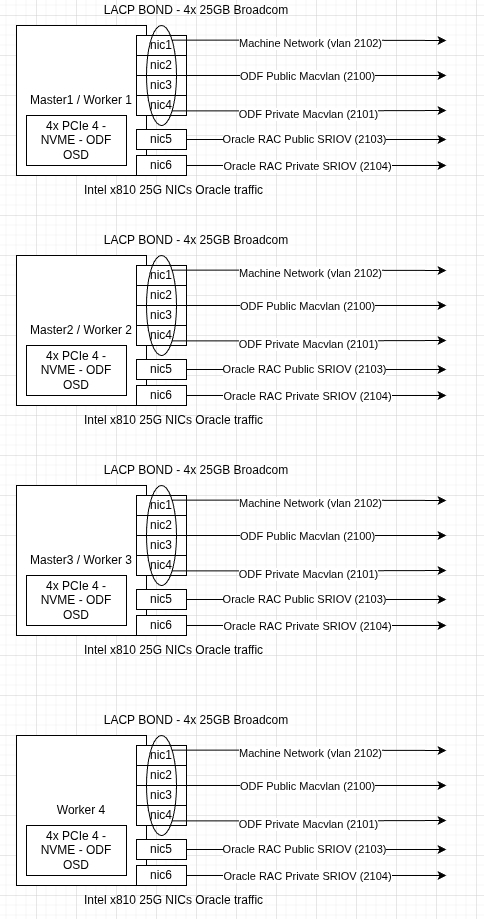
- Séparation du trafic pour les machines virtuelles (harnais de test Oracle Database et HammerDB) du stockage OpenShift Data Foundation et du plug-in réseau OpenShift SDN à l'aide d'interfaces réseau physiques distinctes. Afin de réduire la latence et d'augmenter le débit, des interfaces réseau ont été mises en place sur les machines virtuelles concernées à l'aide de la technologie SR-IOV (Single Root I/O Virtualization) (Figure 2).
Spécification du cluster :
- Version d'OpenShift : 4.18.9
- OpenShift Virtualization : activation via OperatorHub
- Nœuds :
- 3 nœuds hybrides (plan de contrôle/calcul/stockage)
- 1 nœud de calcul
- Mise en réseau (adresse propre aux machines virtuelles Oracle Database) :
- Liaison LACP avec 4 cartes réseau Broadcom de 25 Gbit/s partitionnées pour séparer le plug-in réseau OpenShift SDN, le client de stockage OpenShift Data Foundation et le trafic de réplication du stockage d'OpenShift Data Foundation
- 2 cartes réseau Intel x810 de 25 Gbit/s pour le trafic des machines virtuelles avec 2 sous-réseaux différents (public et privé) configurés pour être présentés aux machines virtuelles à l'aide de la technologie SR-IOV
- Stockage (propre aux machines virtuelles Oracle Database) : stockage OpenShift Data Foundation (avec 4 disques NVMe de 1,5 To) configuré avec un profil de performances et utilisant un réseau de stockage séparé

Configuration du système Oracle Database
La taille modérée de la machine virtuelle qui héberge le système Oracle Database permet d'éviter une surallocation des ressources et de comparer les résultats des tests sur différentes options matérielles. Le système Oracle Database n'a pas été spécifiquement optimisé pour le test TPC-C (Transaction Processing Performance Council Benchmark C) et utilise en grande partie une configuration par défaut, à l'exception des quelques changements d'optimisation courants basés sur les meilleures pratiques.
Nous avons sélectionné les paramètres d'optimisation en fonction de la taille de la machine virtuelle, des caractéristiques de la charge de travail du test d'évaluation des performances et des informations de surveillance. Nous avons évalué l'efficacité de chaque changement en comparant les résultats des tests avec des valeurs de référence. La configuration d'Oracle Database peut être davantage optimisée en suivant les recommandations du guide Database Performance Tuning Guide.
La Figure 3 montre que l'accès client à Oracle Database et HammerDB s'effectuait sur le même réseau. Les volumes de données pour les machines virtuelles sont configurés pour préallouer de l'espace disque afin d'améliorer les opérations d'écriture.
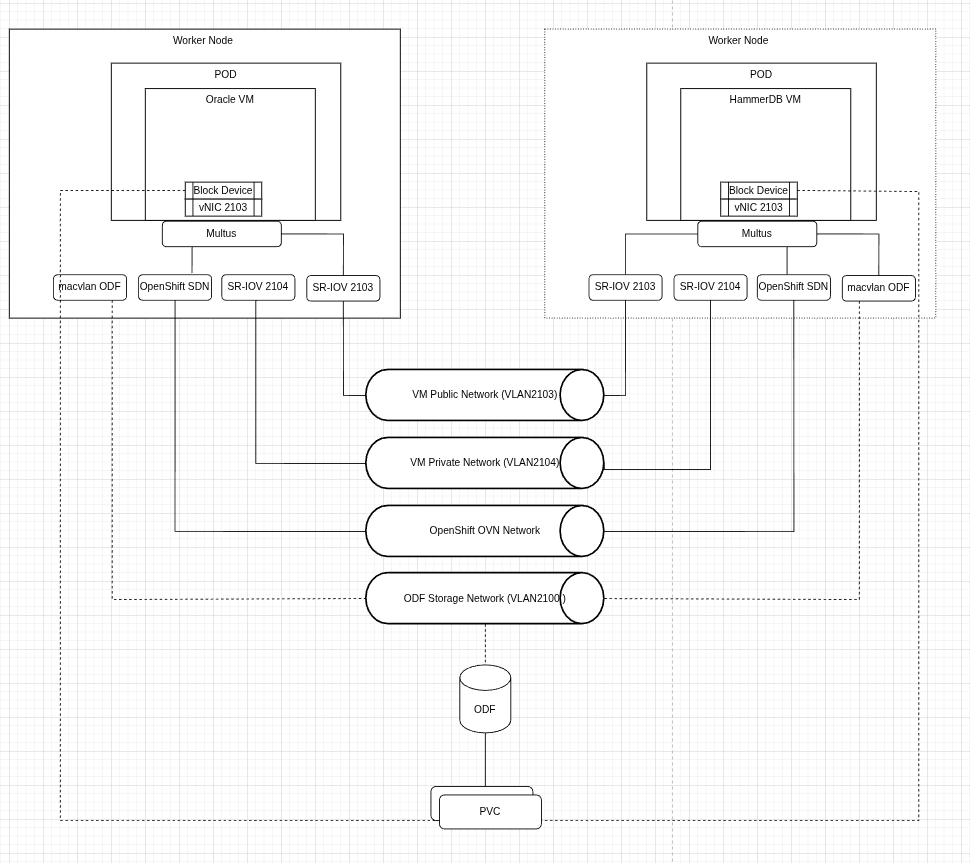
Nous avons effectué des tests ad hoc distincts pour évaluer les effets du stockage sur les performances de la base de données en ajoutant des disques de stockage NVMe à l'aide d'un opérateur de stockage local.
Spécification de la machine virtuelle :
- Système d'exploitation : RHEL 8.10
- Nombre de machines virtuelles : 1
- Processeurs virtuels : 16
- Mémoire : 48 Go
- Stockage : 250 Go (racine et données du système résidant sur le même volume) sous forme de périphérique en mode bloc à partir de Red Hat OpenShift Data Foundation
- Volume de données : créé à l'aide du paramètre « preallocation: true » (provisionnement statique)
- Réseau : connecté au sous-réseau public à l'aide de la technologie SR-IOV
Configuration d'un système Oracle Database à une instance :
Version du système Oracle Database : 19c Enterprise Edition Release Update 26 (version 19.26)
- La base de données est configurée avec un système de fichiers comme cible pour les fichiers de données (volume racine avec stockage basé sur OpenShift Data Foundation) à l'aide du service OMF (Oracle Managed Files).
- Pour garantir la compatibilité du test avec les futures versions d'Oracle Database, la base de données a été créée à l'aide de l'architecture Container Database (CDB).
- L'allocation de mémoire a utilisé 32 Go de mémoire au total pour l'assistant de création de bases de données (afin de permettre à l'installation d'Oracle Database d'évaluer automatiquement le partage SGA/PGA).
- Paramètres d'optimisation supplémentaires :
- 4 fichiers de données étendus manuellement à 32 Go
- Taille du journal REDO ajustée à 4 Go
- 4 groupes de disques de journaux REDO
- FILESYSTEMIO_OPTIONS : SETALL (autorise les E/S asynchrones et les E/S directes)
- USE_LARGE_PAGES : AUTO (permet d'optimiser l'utilisation du processeur pour une SGA de grande taille)
Remarque : pour les tests de performances avec le stockage NVMe, un système de fichiers distinct a été monté à l'aide du périphérique NVMe et attribué comme destination cible aux fichiers de données.
Observabilité et surveillance
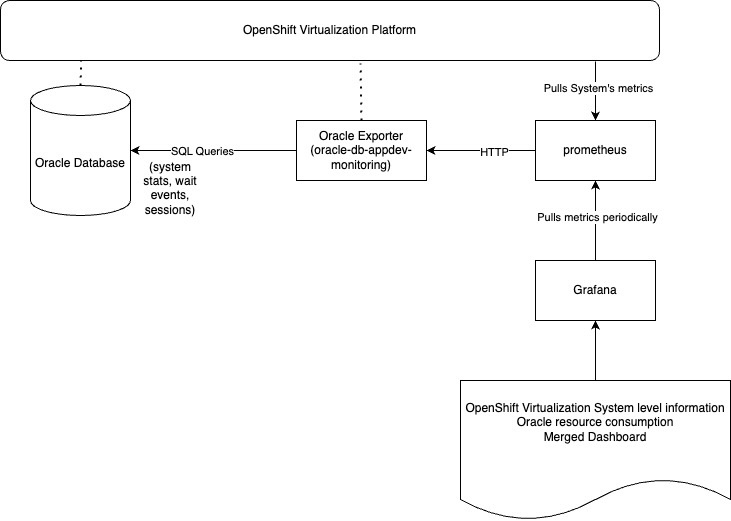
La solution OpenShift offre une plateforme d'observabilité intégrée et puissante qui centralise la surveillance des couches d'infrastructure et d'application. Elle prend en charge de manière native la collecte d'indicateurs de mesure, la journalisation et les alertes, et peut être enrichie avec des données d'observabilité provenant d'applications externes comme Oracle Database. Cette approche unifiée réduit la complexité de l'exploitation tout en offrant une visibilité de bout en bout.
La solution d'observabilité pour OpenShift Virtualization s'intègre en toute transparence à la même plateforme, ce qui permet de surveiller des machines virtuelles, des ressources système et des charges de travail (c'est-à-dire les systèmes Oracle Database dans une pile de surveillance unique et cohérente).
L'outil Oracle Database Observability Exporter, déployé dans OpenShift, collecte les indicateurs de mesure des performances et les métadonnées des systèmes Oracle Database, qui sont exposées à Prometheus. Grafana visualise ces indicateurs de mesure et fournit des tableaux de bord en temps réel pour détecter les schémas anormaux, les ressources sous pression et les problèmes de performances dans les couches des machines virtuelles et des systèmes Oracle Database.
Pour améliorer l'analyse au niveau de la base de données, il est possible d'utiliser l'outil HammerDB pendant les tests de performances afin de capturer des instantanés et de générer des rapports AWR (Automatic Workload Repository). En association avec les indicateurs de mesure de Prometheus et de Grafana, ces rapports permettent de mieux comprendre le comportement des charges de travail et les goulets d'étranglement potentiels.
Par ailleurs, la solution Oracle Database Enterprise Manager vient compléter l'infrastructure avec des diagnostics détaillés et des fonctionnalités de surveillance spécialisées qui sont adaptées aux systèmes Oracle Database. Utilisée en association avec la plateforme d'observabilité unifiée d'OpenShift, cette solution garantit une couverture complète pour les informations d'exploitation propres à l'infrastructure et aux systèmes Oracle Database.

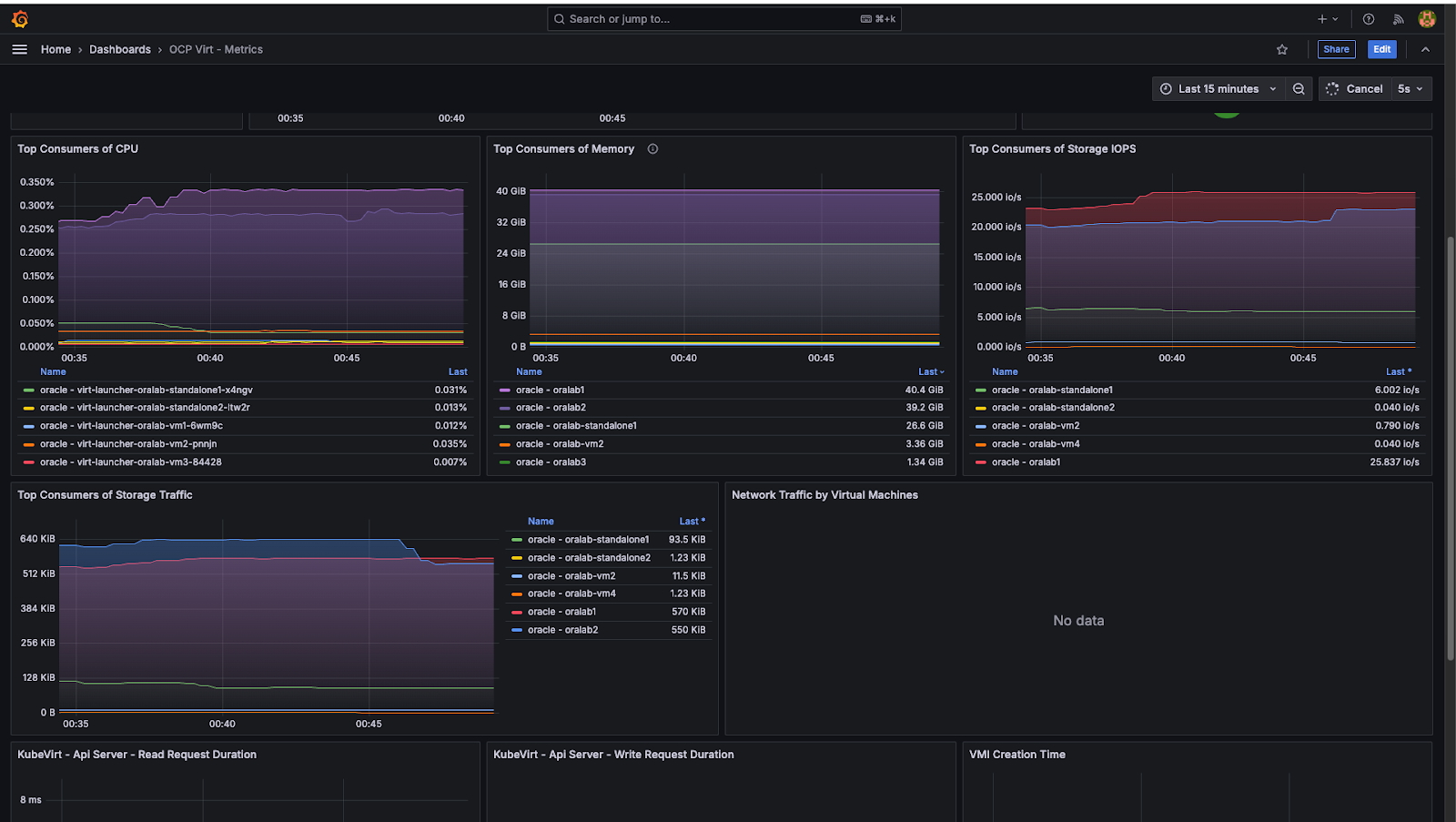
La Figure 5 montre un exemple de tableau de bord Grafana déployé dans le cadre de la configuration de l'observabilité et de la surveillance de la plateforme OpenShift Virtualization.

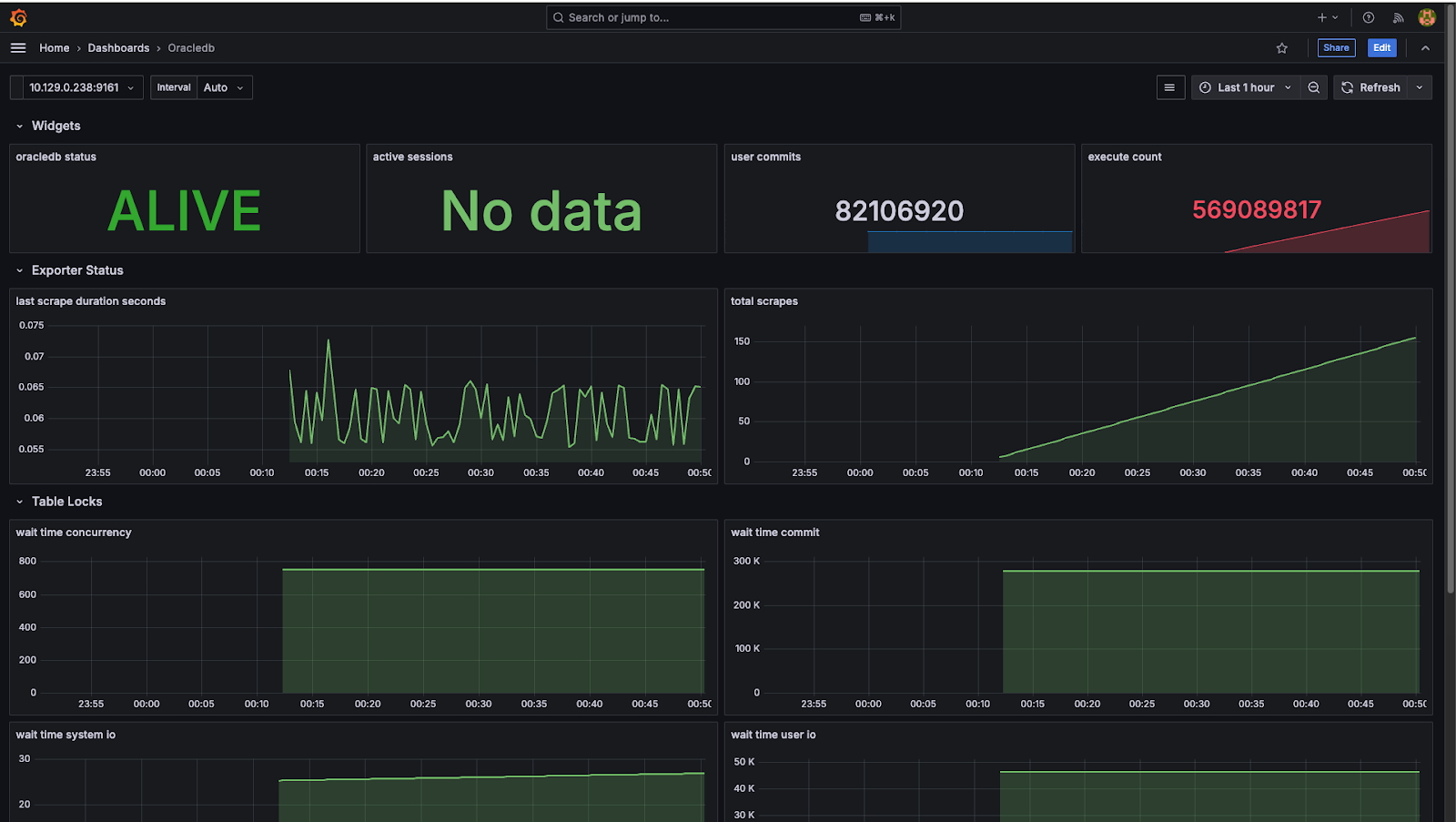
La Figure 6 montre un exemple de tableau de bord Grafana pour un système Oracle Database déployé sur la plateforme OpenShift Virtualization.

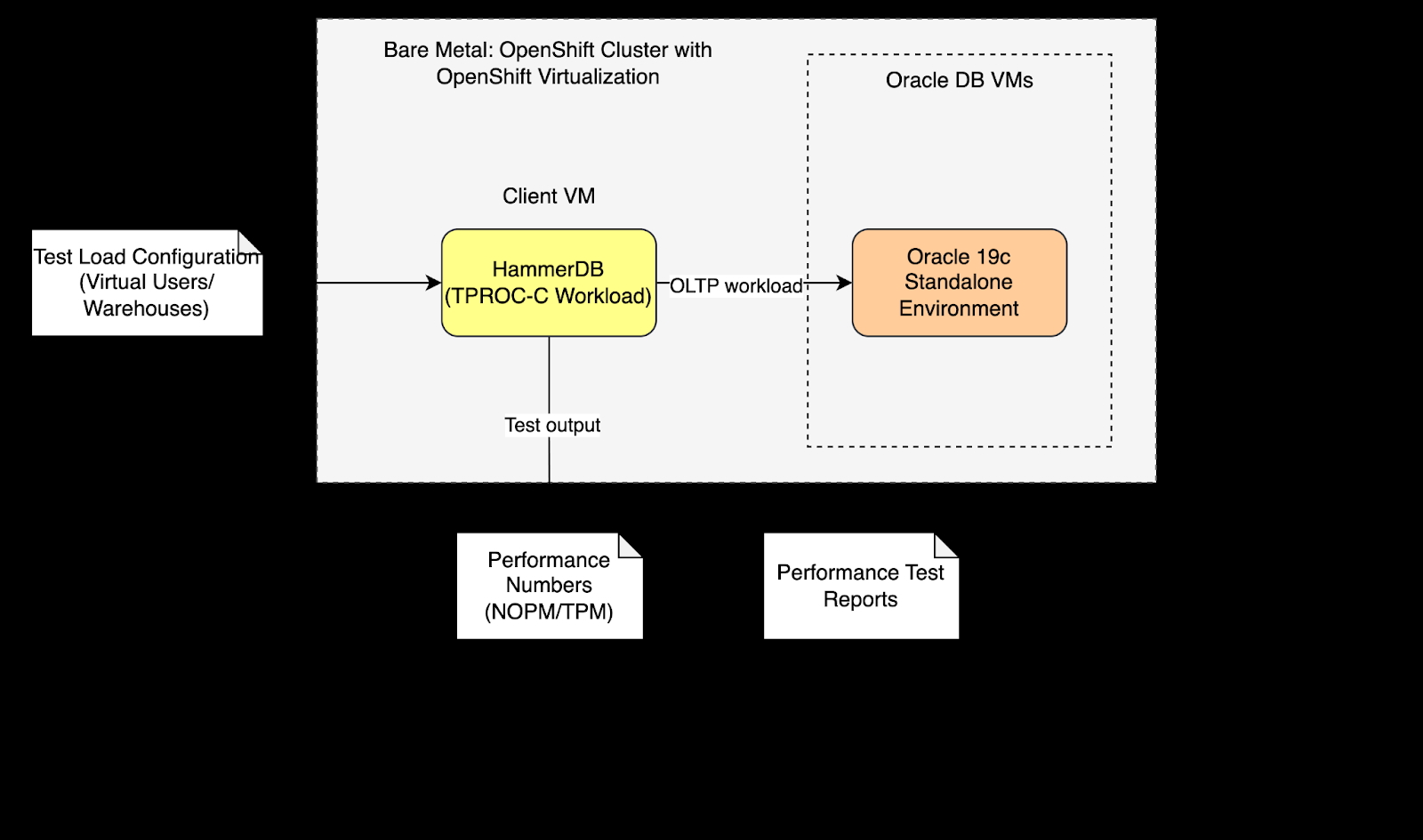
Évaluation des performances du système
Le test de performances a été conçu pour mesurer le débit des transactions de la base de données et la latence des requêtes pour les charges de travail OLTP (Online Transaction Processing). Nous avons utilisé HammerDB, un logiciel de test des performances de base de données Open Source, pour simuler des charges de travail OLTP avec la référence TPC-C sur un système Oracle Database à une instance avec les caractéristiques mentionnées précédemment. Le test TPC-C simule un système de gestion des commandes en conditions réelles, avec un mélange de 80 % d'opérations d'écriture et de 20 % d'opérations de lecture, notamment des commandes client fréquentes, des paiements, des vérifications d'inventaire et des livraisons par lots. L'exécution du test implique la génération de charges de travail TPC-C par HammerDB sur le système Oracle Database dans OpenShift Virtualization.

Résumé des tests
Avec le harnais de test HammerDB, le profil « scale-run » a été configuré pour simuler des charges de travail importantes avec un nombre d'utilisateurs virtuels compris entre 20 et 100, dans 500 entrepôts, chaque test étant exécuté pendant 20 minutes. Nous avons conçu cette configuration pour refléter des scénarios de production réalistes et évaluer les performances du système lors de mises à l'échelle de charges transactionnelles.
Sur la base de la configuration de l'architecture de référence, les résultats des tests ont montré que les indicateurs des nouvelles commandes par minute (NOPM) et des transactions par minute (TPM) sont élevés pour le système Oracle Database à une instance avec le stockage OpenShift Data Foundation. Cependant, le système Oracle Database à une instance avec un périphérique de stockage NVMe local a enregistré de meilleures performances que la configuration basée sur OpenShift Data Foundation. Bien que la latence moyenne soit relativement stable, nous avons observé des pics occasionnels.
Conclusion
OpenShift Virtualization est une plateforme viable et pertinente pour déployer des charges de travail Oracle Database 19c. La facilité de configuration d'OpenShift Virtualization permet de simplifier la création de machines virtuelles. Par conséquent, OpenShift Virtualization s'impose comme une excellente alternative aux technologies de virtualisation concurrentes. La validation actuelle des performances d'Oracle Database 19c fait état de performances de niveau professionnel sur la plateforme OpenShift Virtualization.
Nous avons effectué des tests ad hoc avec un périphérique de stockage NVMe local pour évaluer les effets des solutions de stockage hautes performances. Nous avons observé que la mise à niveau vers des solutions de stockage hautes performances de type SAN FC pouvait améliorer considérablement les performances globales.
Pour les charges de travail hautes performances, envisagez les options suivantes :
- Des solutions de stockage hautes performances de type SAN FC pour les fichiers de données d'Oracle Database et les journaux redo pour optimiser les performances
- La segmentation du réseau pour les machines virtuelles,le plug-in réseau OpenShift SDN et le réseau de stockage, en utilisant de préférence des périphériques physiques distincts sur les nœuds OpenShift Virtualization
- La technologie SR-IOV (Single Root I/O Virtualization), si elle est prise en charge par le matériel, pour optimiser les performances des interfaces réseau virtuelles des machines virtuelles qui hébergent la charge de travail Oracle Database
- HugePages avec le paramètre d'Oracle Database
USE_LARGE_PAGESen fonction des exigences des charges de travail : cette configuration ajuste la taille de la page de la mémoire, recommandée pour améliorer les performances, en particulier avec des SGA plus grandes que les paramètres par défaut.
Vous trouverez les scripts de test HammerDB dans ce référentiel GitHub.
Le projet GitHub oracle-db-appdev-monitoring vise à fournir des fonctionnalités d'observabilité pour Oracle Database, afin que les utilisateurs puissent comprendre les performances et diagnostiquer facilement les problèmes dans toutes les applications et bases de données. Lisez les instructions pour configurer le projet sur la plateforme OpenShift.
Essai de produit
Souscription Red Hat Learning | Essai de produit
À propos des auteurs
Plus de résultats similaires
La virtualisation en 2026 : création d'une plateforme pour les VM, les conteneurs et l'IA
Cessez de gérer le passé et commencez à bâtir l'avenir de l'informatique
Parcourir par canal

Automatisation
Les dernières nouveautés en matière d'automatisation informatique pour les technologies, les équipes et les environnements

Intelligence artificielle
Actualité sur les plateformes qui permettent aux clients d'exécuter des charges de travail d'IA sur tout type d'environnement

Cloud hybride ouvert
Découvrez comment créer un avenir flexible grâce au cloud hybride

Sécurité
Les dernières actualités sur la façon dont nous réduisons les risques dans tous les environnements et technologies

Edge computing
Actualité sur les plateformes qui simplifient les opérations en périphérie

Infrastructure
Les dernières nouveautés sur la plateforme Linux d'entreprise leader au monde

Applications
À l’intérieur de nos solutions aux défis d’application les plus difficiles
Virtualisation
L'avenir de la virtualisation d'entreprise pour vos charges de travail sur site ou sur le cloud