À mesure que l'IA devient un moteur de la compétitivité nationale, le concept d'IA souveraine, c'est-à-dire la capacité d'exploiter des systèmes d'IA sans influence externe, gagne en importance, mais le chemin qui y mène est semé d'embûches. Une étude récente menée auprès de plus de 900 responsables informatiques et ingénieurs spécialisés en IA au sujet de l'adoption de l'IA met en évidence un « déficit de valeur » significatif, montrant que, malgré un grand enthousiasme (72 %), seulement 7 % des entreprises de la région EMEA (Europe, Moyen-Orient et Afrique) obtiennent des résultats.
L'étude met en évidence que la confidentialité des données et les silos d'infrastructure paralysent les efforts de développement de l'IA. C'est ainsi que l'IA souveraine est rapidement passée du statut de « défi du cloud » à celui de nécessité pratique. En atténuant les risques spécifiques identifiés dans l'enquête Red Hat, l'IA souveraine permet aux entreprises réglementées de passer en toute confiance d'un projet pilote à un environnement de production sans compromettre les éléments suivants :
- Conformité réglementaire : Le respect de réglementations strictes, telles que le règlement général sur la protection des données (RGPD), la loi européenne sur l'IA et les lois sur l'hébergement des données qui régissent le maintien des données des citoyens à l'intérieur de certaines frontières.
- Résilience opérationnelle : La possibilité de poursuivre l'exploitation en cas d'instabilité géopolitique mondiale ou de déconnexion d'Internet.
- Autonomie stratégique : Les entreprises évitent toute dépendance vis-à-vis d'un fournisseur et conservent un contrôle total sur la propriété intellectuelle, notamment sur les modèles et les pondérations, générées à partir de données sensibles.
La solution Red Hat OpenShift AI constitue la base de cette souveraineté et permet aux entreprises de créer une usine d'IA « air gap » tout en conservant un contrôle absolu de la sécurité, des données, des modèles et des résultats.
Dans cet article, nous examinons des exemples spécifiques de défis auxquels nos clients sont confrontés avec l'IA souveraine, nous analysons les principaux thèmes à aborder et nous proposons une solution à ces problèmes.
Témoignage utilisateur : Le problème de l'« indépendance vis-à-vis de l'IA »
Le protagoniste : Dr Aris (personnage composite créé à partir de défis concrets), directeur des données au sein du ministère de la Santé d'un pays européen de taille moyenne.
Le défi : Le ministère possède une mine de données qui contient des dizaines d'années de dossiers de patients anonymisés, des séquences génomiques et un historique épidémiologique local. Dr Aris souhaite créer un « LLM de santé national » pour aider les médecins à diagnostiquer les maladies rares propres à leur population.
Le ministère est confronté à un problème d'« IA fantôme ». Des chercheurs frustrés chargent à l'insu de l'utilisateur des extraits anonymisés dans des LLM publics pour effectuer leur travail, ce qui présente un risque de fuite de données. Ils ont besoin d'une plateforme interne approuvée, entièrement sécurisée et aussi simple à utiliser que le cloud public.
Le conflit :
- Le piège du cloud : Les principaux fournisseurs d'IA qui proposent des modèles de type MaaS (Models-as-a-Service) exigent le chargement des données sensibles dans des clouds publics basés aux États-Unis. Ce processus peut enfreindre le règlement général sur la protection des données (RGPD), les lois sur l'hébergement des données et les protocoles de sécurité nationale.
- Le cauchemar des plateformes « faites maison » : Dr Aris tente de construire la plateforme à partir de zéro. Son équipe est rapidement paralysée par le chaos opérationnel lié à la gestion de l'accès au cluster de 500 GPU. Résultat : des conflits de ressources constants où des expériences critiques attendent indéfiniment pendant que le matériel réservé reste inactif.
La solution : Le ministère crée une plateforme d'IA souveraine sur OpenShift AI, en utilisant également Kubeflow et Feast.
- Le changement : Au lieu de s'appuyer sur des API cloud propriétaires, l'équipe du Dr Aris crée une « usine de modèles » sur sa propre infrastructure protégée et « air gap ». OpenShift AI, qui inclut les composants Kubeflow, dissocie le matériel du cluster GPU, ce qui permet à l'équipe d'entraîner des modèles massifs sans envoyer un seul octet à l'extérieur du pays. Feast contribue à centraliser la gestion des caractéristiques au cours de l'entraînement et de l'inférence, de sorte que les caractéristiques qui alimentent les modèles soient définies de manière cohérente, ce qui favorise la gouvernance et la traçabilité.
- Le résultat : Un data scientist envoie alors une demande d'entraînement, et le système met automatiquement en route un cluster distribué, récupère des caractéristiques de Feast, entraîne le modèle, puis le supprime, le tout, dans le centre de données national « air gap ». Dr Aris parvient à l'« autonomie de l'IA » grâce à une plateforme d'IA évolutive et déconnectée, selon les conditions de son pays.
Les trois piliers de l'IA souveraine
Pour passer d'une « colonie numérique », c'est-à-dire une nation (ou communauté) qui s'appuie tellement sur une infrastructure technologique étrangère qu'elle perd le contrôle de sa propre économie numérique, de ses données et de son développement futur, à la « souveraineté numérique », une nation doit contrôler trois couches clés de la pile technologique de l'IA.
La souveraineté technique (la base)
Principe : La souveraineté impose une chaîne de contrôle et une résilience transparente contre l'instrumentalisation de la chaîne d'approvisionnement. En adoptant une couche de plateforme indépendante du matériel, les pays peuvent optimiser leurs progrès en matière d'IA à l'aide d'une stratégie multifournisseur. Leur autonomie stratégique est ainsi préservée, quels que soient les changements qui surviennent dans la chaîne d'approvisionnement mondiale. La plateforme souveraine doit dissocier les logiciels du matériel et combiner la propriété stricte de l'infrastructure avec la flexibilité nécessaire pour s'adapter à la disponibilité du marché. Lorsqu'elles respectent les normes Open Source, les capacités d'IA d'une entreprise peuvent faire l'objet d'inspections, d'audits et d'une maintenance indépendamment de la feuille de route ou du monopole matériel d'un seul fournisseur. Elles conservent ainsi une autorité absolue sur la continuité des services.
Validation : L'enquête Red Hat sur l'IA confirme que 92 % des responsables informatiques considèrent que l'Open Source d'entreprise est essentiel à leur stratégie d'IA. Elle offre la cohérence et la transparence nécessaires pour contrôler la chaîne d'approvisionnement de l'IA.
Souveraineté des données (l'actif)
Principe : La gravité des données est absolue. Les données sensibles doivent être stockées sur des supports de stockage physiquement situés dans le périmètre souverain et sont uniquement soumises aux lois locales. Le défi consiste donc à fournir aux data scientists la facilité de sélection et de récupération des données que l'on trouve dans le cloud, tout en limitant physiquement les déplacements de données vers un réseau interne sécurisé.
Souveraineté opérationnelle (le contrôle)
Principe : Le « plan de contrôle » doit être local. Les workflows essentiels ne peuvent pas reposer sur une console SaaS (Software-as-a-Service) hébergée sur un autre continent pour gérer les ressources de calcul ou l'accès des utilisateurs. Une plateforme souveraine nécessite un plan de contrôle autonome qui prend en charge la gestion des identités et des accès (IAM) et l'orchestration des ressources entièrement dans le périmètre local.
Solution technique
Notre solution repose sur une architecture en couches où Red Hat AI sert de plateforme souveraine unifiée. Elle orchestre les capacités d'entraînement de Kubeflow et de gestion des données de Feast.
Cette solution repose sur des normes Open Source, notamment Red Hat OpenShift, qui fournit une base Kubernetes, ainsi que le projet Kubeflow. En utilisant les composants inclus (registre de modèles, KServe, pipeline et entraînement, et Feast pour la distribution de fonctionnalités), les entreprises peuvent conserver l'intégralité de la propriété de leur pile technologique. Cette transparence permet aux entreprises d'examiner le code à la recherche de vulnérabilités et de contribuer directement à la feuille de route du projet. Nous nous intéressons ici à la manière dont Kubeflow Trainer et Feast répondent à ces exigences de souveraineté.
Le modèle ouvert pour la souveraineté de l'IA : Red Hat AI
Pour exploiter tout le potentiel de la souveraineté, la plateforme sous-jacente doit être aussi fiable que les données qu'elle traite. La gamme Red Hat AI fournit une base d'entreprise renforcée qui répond aux besoins spécifiques des usines d'IA protégées et autonomes.
Red Hat AI propose une indépendance totale au niveau de l'infrastructure. Cette solution prend en charge le déploiement dans les environnements bare metal « air gap », les clouds privés ou les clouds souverains de partenaires fiables. Cette approche permet de choisir ses propres fournisseurs de matériel (NVIDIA, Intel, AMD, etc.) et de conserver une autorité absolue sur la continuité des services.
- Chaîne d'approvisionnement de logiciels fiable : La souveraineté commence par la source. Red Hat AI fournit un catalogue d'outils d'IA certifiés, analysés et signés numériquement afin d'éviter que les logiciels exécutés dans votre périmètre « air gap » ne présentent de vulnérabilités connues, un prérequis essentiel pour la sécurité nationale.
- Plan de contrôle MLOps unifié : La plateforme rassemble toute la pile technologique d'IA fragmentée en une seule interface. Elle aide à gérer les dépendances complexes entre le système d'exploitation (Red Hat Enterprise Linux), le matériel (GPU) et la couche applicative (Kubeflow/Feast), afin que les data scientists puissent concentrer leurs efforts sur la modélisation plutôt que sur les canalisations de l'infrastructure.
- Abstraction matérielle évolutive : Qu'elle soit exécutée sur des racks bare metal ou dans un cloud privé virtualisé, la gamme Red Hat AI dissocie les ressources physiques. Elle utilise des opérateurs pour ajuster et exposer automatiquement le matériel spécialisé, tel que les GPU dans un superordinateur national, ce qui permet de renforcer l'architecture multi-client sans compliquer l'expérience pour l'utilisateur.
Une fois cette base sécurisée établie, nous nous appuyons sur Red Hat OpenShift AI. Cette plateforme d'IA distribuée dans le cadre de la gamme Red Hat AI permet aux entreprises de créer, d'ajuster, de déployer et de gérer des modèles et des applications d'IA. Elle agit comme un système neuronal central qui orchestre trois capacités essentielles et intégrées : un moteur d'entraînement hautes performances, une couche de gestion des données précise et un cadre optimisé de mise à disposition des modèles.
Calcul intégré : Kubeflow Trainer
Pour une usine d'IA souveraine, l'utilisation d'une infrastructure de cloud public n'est souvent pas une option viable en raison d'exigences strictes en matière de contrôle et de résidence des données. Pour garantir une véritable souveraineté, vous devez posséder le matériel et l'exploiter. Cette indépendance implique toutefois la responsabilité de gérer efficacement celle-ci, notamment la planification des tâches distribuées complexes, la gestion des défaillances de nœuds et l'utilisation efficace des ressources de superinformatique à forte valeur ajoutée.
Kubeflow Trainer (un composant d'OpenShift AI) résout ce paradoxe opérationnel. Il apporte une facilité d'utilisation « cloud-native » à votre infrastructure privée, ce qui en fait un moteur hautes performances qui rationalise l'entraînement distribué sur Kubernetes. Il remplace les workflows fragmentés par une API TrainJob unifiée, ce qui permet aux data scientists de mettre à l'échelle des frameworks tels que PyTorch et TensorFlow sans réécrire le code d'une infrastructure complexe.
- Simplification : En dissociant l'infrastructure souveraine sous-jacente, cette solution fournit une interface unique et cohérente pour les tâches d'entraînement distribuées considérables.
- Fiabilité : Basée sur l'API JobSet de Kubernetes, elle s'assure que l'ensemble du groupe est géré correctement (ordonnancement « tout ou rien ») en cas de défaillance d'un nœud d'un cluster d'entraînement distribué. Cela contribue à réduire le gaspillage des ressources, car les tâches d’entraînement à grande échelle s’exécutent soit complètement, soit redémarrent correctement.
- Intégration : Cette solution s'intègre de manière native à Kueue (un composant de la pile de planification d'OpenShift AI) pour gérer les quotas de tâches et les files d'attente, allouant ainsi de manière dynamique des ressources GPU à partir du pool de nœuds OpenShift sous-jacent, afin que les ressources de calcul nationales soient utilisées plus efficacement.
Données souveraines : Feast Feature Store
Bien qu'une véritable souveraineté des données nécessite une stratégie complète, un composant spécialisé est nécessaire pour établir le lien entre l'utilisation des données brutes et des modèles. En complément du moteur de calcul, Feast fait office de « mémoire » de la solution. Exécutée sur OpenShift, la solution Feast dissocie le modèle de l'infrastructure de données brutes, ce qui améliore la conformité et la reproductibilité.
Feast gère l'exactitude ponctuelle : le modèle est donc entraîné sur les données exactes disponibles à un moment donné, ce qui évite les fuites de données et permet une auditabilité totale.
- Store hors ligne (MinIO, par exemple) : Il se connecte de manière sécurisée au magasin d'objets compatible S3 « air gap » afin de traiter les données historiques à haut débit pour l'entraînement.
- Magasin en ligne (Redis, par exemple) : Il gère les fonctions à faible latence pour l'inférence, de sorte que les décisions en temps réel sont prises dans le périmètre souverain.
- Registre de fonctionnalités : Il fournit une source unique de référence pour les définitions de fonctions, de sorte que tous les data scientists de la plateforme calculent de la même manière les indicateurs de mesure critiques (par exemple, « l'âge du patient »), ce qui préserve l'intégrité des informations souveraines.
Fin du cycle de vie : Mise à disposition de modèles souverains
La véritable souveraineté ne se limite pas à l'entraînement et doit englober l'ensemble du cycle de vie du MLOps. Une fois qu'un modèle est entraîné par Kubeflow, il doit être déployé pour traiter des données en direct sans jamais quitter le périmètre sécurisé.
La solution OpenShift AI met fin à cette boucle grâce à des fonctionnalités de distribution de modèles intégrées. Avec des outils tels que KServe, vLLM et llm-d pour la prise en charge de l'inférence distribuée au sein de la plateforme, les entreprises peuvent déployer leurs artefacts de modèle immédiatement dans le cluster souverain « air gap » où ils ont été entraînés. Cela signifie que :
- L'inférence reste au sein de l'entreprise : Avec les projets vLLM et llm-d, les requêtes de l'utilisateur (les demandes de diagnostic d'un médecin, par exemple) et les flux de données en direct sont traités localement, sans jamais transiter par une API publique. Ces technologies optimisent l'utilisation de la mémoire GPU via PagedAttention et permettent de partitionner des modèles de fondation massifs sur plusieurs GPU plus petits. Grâce à cette capacité optimisée, les entreprises peuvent héberger des systèmes d'IA générative hautes performances sur leur propre infrastructure existante, ce qui évite d'avoir à louer des API cloud coûteuses et non souveraines.
- Souveraineté unifiée : De l'accélération matérielle à la surveillance des modèles, l'ensemble du flux, Gather (Feast) → Entraînement (Kubeflow) → Serve (OpenShift AI), s'exécute sur une infrastructure souveraine, sous votre contrôle.
Cette capacité relie directement la phase de « développement » aux phases d'intégration et de « surveillance », ce qui signifie qu'une entité réglementée peut exécuter une usine d'IA de bout en bout de classe mondiale entièrement en interne.
Architecture
Le schéma ci-dessous illustre la manière dont OpenShift AI agit en tant que couche de plateforme souveraine, encapsulant l'orchestration, la sécurité et la gestion du matériel nécessaires pour exécuter Kubeflow et Feast dans un environnement « air gap ».
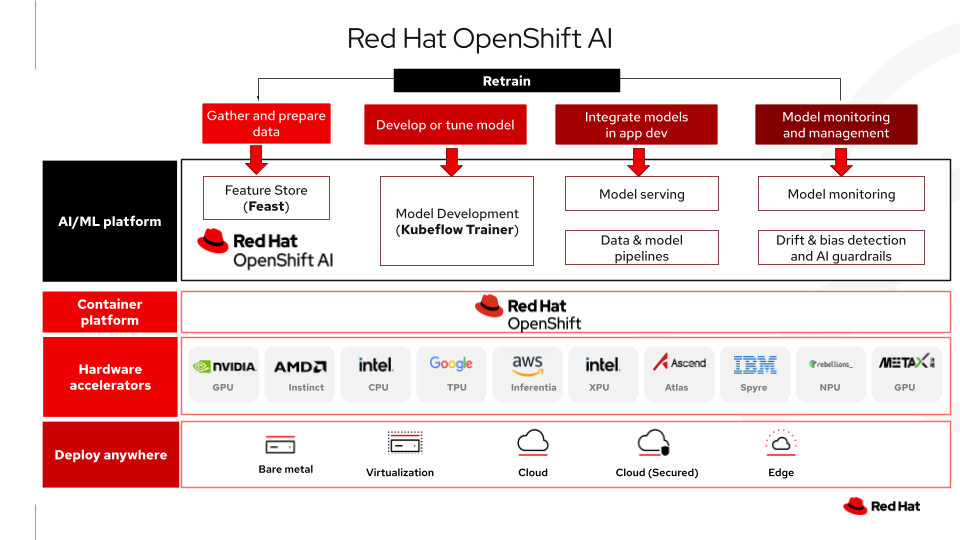
Conclusion
Pour mettre en œuvre l'IA souveraine, il ne suffit pas de disposer de matériel local : il faut également adopter une architecture logicielle qui respecte l'importance des données et la complexité des workflows d'IA modernes.
En utilisant des technologies telles que Kubeflow Trainer et Feast dans OpenShift AI, les entreprises peuvent créer une usine d'IA souveraine qui est :
- Renforcée dès la conception : Les données circulent directement dans le périmètre protégé, du stockage vers le calcul, régies par le contrôle d'accès basé sur les rôles (RBAC) pour les entreprises de Red Hat et la conformité avec les normes FIPS (Federal Information Processing Standards) en option.
- Évolutive : Utilisation de la puissance de l'entraînement distribué sur Kubernetes avec gestion automatisée du matériel fournie par OpenShift AI et Kubeflow Trainer.
- Reproductible : Utilisation de magasins de fonctions pour prendre en charge la traçabilité des données vérifiables.
Cette solution permet aux pays et aux entreprises d'exploiter la puissance de l'IA sans compromettre leur indépendance, transformant ainsi le défi de la souveraineté en avantage concurrentiel.
Vous souhaitez créer votre propre usine d'IA souveraine ?
- Aspects techniques : Vous souhaitez consulter le code qui sous-tend l'architecture ? Il existe un tutoriel technique détaillé sur le blog Red Hat Developer : Amélioration de la récupération RAG avec Feast et Kubeflow Trainer
- Découvrez la plateforme : Si vous souhaitez en savoir plus, rendez-vous sur Red Hat OpenShift AI pour découvrir comment notre plateforme d'entreprise aide les entreprises à créer, déployer et gérer des applications d'IA souveraines et protégées à grande échelle.
Ressource
L'entreprise adaptable : quand s'adapter à l'IA signifie s'adapter aux changements
À propos de l'auteur

Umberto Manganiello is a Staff Engineer at Red Hat since 2025. Prior to this, he spent over 15 years as a Principal Architect and Engineer in the Financial and Telecommunications sectors. He specializes in designing high-availability systems that operate at massive scale, leveraging deep expertise in Kubernetes, Kafka, and Cloud modernization. Currently, he applies this architectural discipline to the challenges of MLOps, with a focus on GenAI, OpenShift AI, and Kubeflow, blending cloud-native resilience with AI model training workflows.
Plus de résultats similaires
Cessez de gérer le passé et commencez à bâtir l'avenir de l'informatique
De l'inférence aux agents : mise à l'échelle de l'IA en entreprise avec Red Hat AI 3.4
Technically Speaking | Build a production-ready AI toolbox
Technically Speaking | Platform engineering for AI agents
Parcourir par canal

Automatisation
Les dernières nouveautés en matière d'automatisation informatique pour les technologies, les équipes et les environnements

Intelligence artificielle
Actualité sur les plateformes qui permettent aux clients d'exécuter des charges de travail d'IA sur tout type d'environnement

Cloud hybride ouvert
Découvrez comment créer un avenir flexible grâce au cloud hybride

Sécurité
Les dernières actualités sur la façon dont nous réduisons les risques dans tous les environnements et technologies

Edge computing
Actualité sur les plateformes qui simplifient les opérations en périphérie

Infrastructure
Les dernières nouveautés sur la plateforme Linux d'entreprise leader au monde

Applications
À l’intérieur de nos solutions aux défis d’application les plus difficiles
Virtualisation
L'avenir de la virtualisation d'entreprise pour vos charges de travail sur site ou sur le cloud