
In today’s Storage Tutorial, Brian chats with Red Hat’s Paul Cuzner of the storage business unit. Paul has been focused on finding new ideas and strategies where Red Hat Storage can make a difference for customers and, most recently, has spent time working with Splunk. Watch the video below to find out just how Paul and Red Hat work with customers to make the most of Splunk and their storage, but we’ve broken down one salient bit for you right here…keep reading!
Understanding Splunk data flows
Data arriving within a Splunk indexer, as it’s being parsed, is placed into a structure named a bucket – a directory in a file structure. This bucket is considered “hot” because its index is being actively built, or files are constantly being added or removed from it. When it reaches a certain size, or age, it moves to “warm” storage, meaning the index is built and closed, so no further information is added and it becomes a point of record.
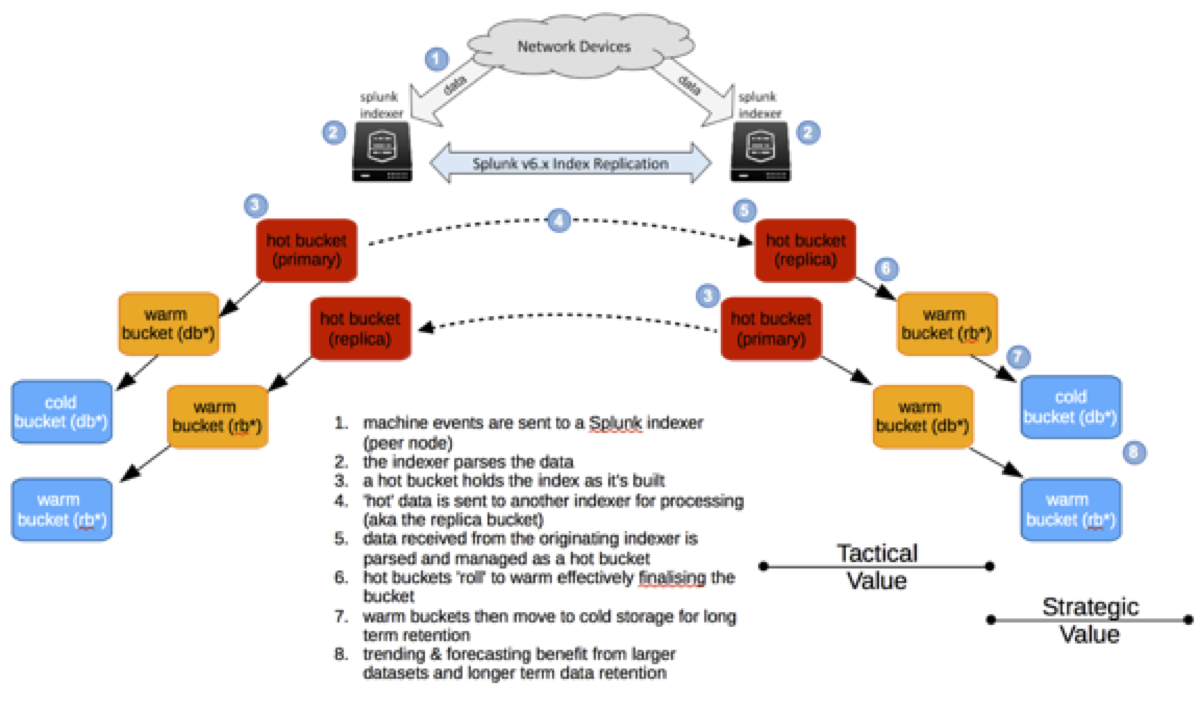 The Splunk data migration flow, illustrated!
The Splunk data migration flow, illustrated!
Hot and warm buckets, because they are considered to be in use or readily available, are typically placed on very fast storage – 10,000 or 15,000 RPM hard disks or flash storage, for example.
Eventually warm buckets are rolled into “cold” buckets. These are also not written to and are available for search. This storage, because it isn’t accessed quite as often, is typically placed on slower storage with very high capacity…and this is where customers struggle to choose a platform.
Be sure to check out the video, next:
À propos de l'auteur
Plus de résultats similaires
Au-delà de l'automatisation : pourquoi la montée des vulnérabilités de sécurité liées à l'IA exige une expertise technique humaine
Amélioration des capacités post-quantiques de SSH dans Red Hat Enterprise Linux
Untangling Networks | Compiler
Technically Speaking | Defining sovereign AI with open source
Parcourir par canal

Automatisation
Les dernières nouveautés en matière d'automatisation informatique pour les technologies, les équipes et les environnements

Intelligence artificielle
Actualité sur les plateformes qui permettent aux clients d'exécuter des charges de travail d'IA sur tout type d'environnement

Cloud hybride ouvert
Découvrez comment créer un avenir flexible grâce au cloud hybride

Sécurité
Les dernières actualités sur la façon dont nous réduisons les risques dans tous les environnements et technologies

Edge computing
Actualité sur les plateformes qui simplifient les opérations en périphérie

Infrastructure
Les dernières nouveautés sur la plateforme Linux d'entreprise leader au monde

Applications
À l’intérieur de nos solutions aux défis d’application les plus difficiles
Virtualisation
L'avenir de la virtualisation d'entreprise pour vos charges de travail sur site ou sur le cloud