
Votre cloud privé s'apparente-t-il à un buffet gratuit ouvert à tous ? Vous savez que cette infrastructure génère de la valeur, mais lorsque la facture arrive, il devient presque impossible de déterminer qui consomme quoi.
Dans les environnements cloud dynamiques actuels, attribuer correctement les coûts aux utilisateurs internes revêt une importance croissante, en particulier pour les entreprises qui gèrent leur propre infrastructure cloud. La responsabilisation des équipes s'avère indispensable pour répartir équitablement les coûts entre les services ou pour les encourager à dimensionner correctement leurs charges de travail, l'obtention d'une visibilité claire constituant la première étape.
Avec la version fonctionnelle 5 (FR5) de Red Hat OpenStack Services on OpenShift 18, nous proposons un élément essentiel pour vous aider à résoudre ce casse-tête : la possibilité d'effectuer une tarification basée sur l'utilisation mesurée de vos clients.
Nous introduisons CloudKitty, le service de tarification natif d'OpenStack, désormais en disponibilité générale dans la version FR5. Ce service comble le fossé entre vos métriques techniques brutes et vos opérations financières.
Pourquoi CloudKitty est-il important ?
CloudKitty fournit une couche de traduction qui transforme les données d'utilisation des serveurs en informations exploitables pour établir les budgets des services. Considérez CloudKitty comme l’agent chargé du relevé des compteurs : il se positionne entre vos métriques collectées et votre solution FinOps ou de facturation. Il extrait des données techniques brutes, telles que le nombre d'heures de fonctionnement d'une machine virtuelle (VM) ou la quantité de stockage consommée, et applique vos règles de tarification spécifiques pour générer un rapport. Cette solution vous aide à atteindre deux objectifs majeurs :
- Récupération transparente des coûts : Vous pouvez désormais visualiser une répartition claire et détaillée de l'utilisation des ressources par client. Cette approche vous permet de recouvrer précisément les dépenses d'exploitation sans surprendre vos clients internes avec des frais opaques.
- Confiance et optimisation : Lorsque les clients constatent l'impact de leur propre consommation (ventilée par projet, type d’instance et métrique) sur leurs coûts, ils peuvent prendre des décisions éclairées, comme l'archivage de données obsolètes ou l'optimisation de l'utilisation de leurs machines virtuelles.
Notez que CloudKitty fait office de moteur de visibilité et de tarification uniquement ; il ne procède pas à l'application active de budgets et ne bloque pas la création de ressources (telles que des instances Nova) lorsqu'un client dépasse un certain seuil de coûts.
Comment fonctionne CloudKitty ?
Bien qu'il ne s'agisse pas d'une solution de facturation complète, CloudKitty fournit le lien essentiel entre l'utilisation et le coût. En termes simples, le workflow se déroule ainsi :
Définition des règles de tarification → Collecte des métriques → Génération des rapports de tarification
Définition des règles
Prenons l'exemple d'un client de notre liste fictive : le ministère des données. Historiquement, le ministère lance d'imposantes machines virtuelles pour ses charges de travail analytiques, et les laisse fonctionner bien après la fin des calculs.
Pour assurer une récupération transparente des coûts, nous devons suivre leur empreinte de calcul. Pour ce faire, nous suivrons la métrique ceilometer_cpu. Cette métrique spécifique permet de déterminer le temps de fonctionnement basé sur le type d’instance. Ainsi, pour chaque période d'activité d'une instance de machine virtuelle, CloudKitty peut calculer un tarif différent selon sa taille.
Étape 1 : Création du service
Dans un premier temps, nous devons créer un conteneur de niveau supérieur pour notre métrique. Le nom du service doit correspondre exactement au nom de la métrique ou au alt_name défini dans metrics.yaml. (We’ll discuss this file in more detail later.)
openstack rating hashmap service create ceilometer_cpu
+----------+--------------------------------------+
| Nom | ID de service |
+----------+--------------------------------------+
| ceilometer_cpu | <uuid> |
+----------+--------------------------------------+Conservez cet ID de service (UUID), car vous en aurez besoin pour les commandes suivantes !
En créant un service nommé ceilometer_cpu, nous contribuons à garantir que chaque point de données de processeur provenant du collecteur sera acheminé directement vers cette nouvelle règle de tarification.
Étape 2 : Création d'un groupe (facultatif)
We dont want the Ministry's compute charges getting tangled up with their storage or networking bills. Les groupes nous aident à organiser les mappages associés et à isoler les calculs les uns des autres.
openstack rating hashmap group create cpu_ratingEn regroupant ces mappages, nous dissocions les différents scénarios de facturation. Si plusieurs mappages d'un même groupe correspondent, CloudKitty appliquera uniquement le plus coûteux.
Étape 3 : Création d'un mappage
Les mappages constituent les règles de tarification. Tout d'abord, établissons une base de référence pour le Ministère des Données en facturant un coût fixe par élément. En remplaçant <service_id> et <group_id> par les UUID obtenus lors des étapes précédentes, vous pouvez lier directement cette nouvelle règle à votre service ceilometer_cpu et à votre groupe cpu_rating.
openstack rating hashmap mapping create 0.02 \
-s <service_id> \
-g <group_id> \
-t flatDans ce scénario, 0,02 signifie 0,02 unité par période de collecte (toutes les heures par défaut). Chaque instance de processeur génère un coût fixe de 0,02 unité, quel que soit son taux d'utilisation.
Étape 4 : Tarification basée sur les champs (l'arme secrète)
Le ministère des Données exploite de petits serveurs web aux côtés de volumineux nœuds de base de données gourmands en ressources. L'application d'un tarif forfaitaire pour l'ensemble des ressources ne serait pas équitable. Nous souhaitons leur facturer des tarifs différents pour chacun des types d’instances de VM spécifiques qu'ils utilisent.
Tout d'abord, nous créons un champ faisant référence à la clé de métadonnées :
openstack rating hashmap field create <service_id> flavor_idEnsuite, nous créons un mappage spécifique pour cette valeur de type d’instance :
openstack rating hashmap mapping create 0.05 \
--field-id <field_id> \
--value <flavor_uuid> \
-t flatNous répéterons la création de ce mappage pour chaque type d’instance disponible dans notre environnement. Pour chaque type d’instance, nous créons une nouvelle règle afin de permettre au service de tarification de déterminer le tarif à appliquer lorsque cette taille spécifique de machine virtuelle s'exécute.
Le résultat : Fonctionnement de l'ensemble
À la fin du mois, lorsque le Ministère des Données demande à consulter sa consommation, voici comment CloudKitty applique les règles définies ci-dessus :
ceilometer_cpu (métrique)
└─> Service : ceilometer_cpu
└─> Champ : flavor_id (facultatif)
└─> Correspondance : m1.tiny = 0.01, m1.large = 0.05
└─> Mise en correspondance (directe) : 0,02 forfaitaireSi vous pouvez le mesurer, vous pouvez le tarifer
Nous avons choisi la consommation de processeur du ministère des Données (ceilometer_cpu) comme exemple principal, mais les ressources de calcul ne représentent qu'une partie de l'équation. L'efficacité de CloudKitty dans Red Hat OpenStack Services on OpenShift repose sur son intégration avec Prometheus.
N'oubliez pas que toute métrique déjà collectée peut servir à la tarification. Vous pouvez ainsi facilement créer des règles de tarification pour le reste de l'empreinte de votre client en suivant exactement les mêmes étapes que celles décrites ci-dessus. Par exemple, vous pouvez créer des mappages de coûts pour :
- Stockage en mode bloc : Le suivi de la capacité en Go-mois à l'aide de
ceilometer_disk_device_capacity - Réseau : Facturation des adresses publiques allouées à l'aide de
ceilometer_ip_floating - Bande passante sortante : L'évaluation du trafic sortant total des machines virtuelles à l'aide de
ceilometer_network_outgoing_bytes
Une fois que CloudKitty a récupéré cet ensemble de données depuis Prometheus, le processeur applique vos règles de tarification personnalisées et transmet les métriques tarifées finalisées directement à un back-end de stockage. Cet outil sert de passerelle automatisée entre votre télémétrie technique brute et vos rapports FinOps.
Générer des rapports de tarification : Le moment de vérité
Une fois vos règles créées et les métriques collectées depuis Prometheus, la dernière étape consiste à extraire les données tarifées.
Il convient de noter que CloudKitty ne constitue pas un système de facturation. Cet outil ne vise pas à générer de factures au format PDF. En revanche, cet outil est conçu pour servir de moteur de données robuste, fournissant des données JSON propres et exploitables via son API REST ou le client OpenStack. Ce fonctionnement permet d'intégrer plus facilement les données tarifées directement dans les solutions de FinOps, de showback ou de facturation existantes de votre entreprise.
La vue du projet : Le Ministère consulte ses dépenses
CloudKitty intègre un contrôle d'accès qui tient compte des projets. Lorsque le ministère des Données souhaite consulter son utilisation actuelle, ses équipes peuvent uniquement accéder à l'empreinte de leur propre projet. Toute tentative d'accès aux données d'autres projets est automatiquement bloquée ou ignorée par l'API.
Pour obtenir son résumé mensuel, le Ministère peut utiliser le client OpenStack :
# Obtenir le résumé pour un mois spécifique
openstack rating summary get --begin 2026-02-01 --end 2026-03-01La vue de l'équipe d'administration : Une vue d'ensemble
Alors que le ministère des Données est limité à son propre usage, les administrateurs cloud ont besoin d'une vision globale de l'ensemble de l'environnement afin de gérer la capacité et de faciliter la refacturation globale.
À l'aide d'un jeton d'administration, les équipes d'exploitation bénéficient d'une visibilité totale. Elles peuvent compléter la commande afin d'isoler un projet spécifique à l'aide de --tenant-id <project_uuid>.
openstack rating summary get \
--begin 2026-02-01 \
--end 2026-03-01 \
--tenant-id <project_uuid>Par ailleurs, si l'équipe FinOps a besoin d'une vue d'ensemble à exporter vers son système de facturation, l'équipe d'administration peut extraire les données tarifées pour l'ensemble du cloud en une seule fois à l'aide de l'option --all-tenants.
Connexion directe à votre solution FinOps
Si votre middleware FinOps extrait ces données de manière programmatique, il peut utiliser l'API REST pour demander une répartition détaillée regroupée selon les types de services spécifiques que nous avons configurés précédemment (par exemple ceilometer_cpu) :
curl -X GET \
-H "X-Auth-Token: $TENANT_TOKEN" \
"http://localhost:8888/v1/report/summary?begin=2026-02-01T00:00:00&end=2026-03-01T00:00:00&groupby=res_type"La sortie JSON obtenue présente clairement le type de ressource, la période ainsi que le nombre total d'unités calculées.
{
"summary": [
{
"tenant_id": "MoD-project-uuid",
"res_type": "ceilometer_cpu",
"begin": "2026-02-01T00:00:00",
"end": "2026-03-01T00:00:00",
"rate": 125.50
}
]
}En transmettant directement ces données JSON structurées et agrégées aux logiciels financiers globaux de votre entreprise, vous parvenez à boucler la boucle entre la consommation brute d'infrastructure et la responsabilisation en matière de coûts.
Sous le capot
Après avoir observé CloudKitty en action du point de vue de l'opérateur, levons le capot pour examiner le moteur sous-jacent. La compréhension de l'architecture vous aidera à appréhender l'évolutivité, à résoudre les incidents et à apprécier la logique des choix de conception retenus.
Présentation de l'architecture
CloudKitty s'exécute sous la forme de deux processus indépendants, dotés chacun d'une responsabilité distincte :
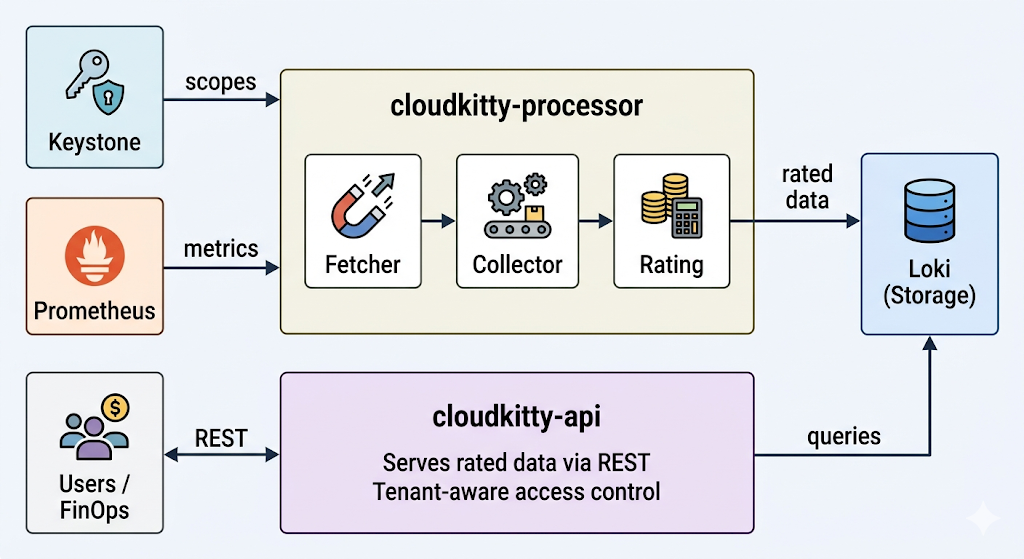
Figure 1. L'architecture de CloudKitty. Le processus cloudkitty-processor récupère les scopes de Keystone et les métriques de Prometheus, tarifie les données, puis les stocke dans Loki. Le processus cloudkitty-api fournit les données tarifées de Loki aux utilisateurs et aux outils FinOps via REST.
cloudkitty-processor constitue le moteur de tarification. À chaque période de collecte (1 heure par défaut), ce processus exécute un pipeline en quatre étapes :
- Récupération : Demande à Keystone la liste des projets OpenStack (périmètres) à évaluer.
- Collecte : Pour chaque périmètre, interroge Prometheus afin d'obtenir les valeurs de métriques brutes définies dans
metrics.yaml. - Tarification : Applique les règles de la table de hachage (les services, les champs et les mappages configurés précédemment) afin de convertir la consommation brute en données évaluées.
- Stockage : Transmet les DataFrames de données évaluées résultantes à Loki à des fins de persistance.
cloudkitty-api constitue le frontal REST. Ce composant traite l'ensemble des requêtes entrantes provenant des clients, des administrateurs et des outils FinOps externes. Lorsqu'un utilisateur demande un résumé de tarification, ce frontal interroge Loki et renvoie les résultats. Ce processus sans état permet une mise à l'échelle horizontale afin de traiter un plus grand nombre de requêtes simultanées.
Les deux processus étant dissociés, vous pouvez les mettre à l'échelle indépendamment : ajoutez d'autres répliques d'API pour gérer la charge de requêtes, ou ajustez le parallélisme du processeur afin de tarifer davantage de périmètres simultanément.
Pourquoi Loki ?
L'utilisation de Grafana Loki comme back-end de stockage pour les données évaluées peut sembler atypique, Loki étant principalement connu comme système d'agrégation de journaux. Cette solution s'avère pourtant particulièrement adaptée :
- Conception native pour les séries chronologiques : Les données évaluées présentent par nature un caractère temporel : coût par périmètre et par période de collecte. Loki facilite l'exécution de requêtes efficaces sur des plages temporelles au sein de flux structurés.
- Déjà présent dans la pile : Les déploiements d'OpenStack Services on OpenShift intègrent déjà une instance LokiStack pour la gestion des journaux. CloudKitty réutilise la même infrastructure gérée par l'opérateur, ce qui évite de devoir déployer ou administrer une base de données supplémentaire.
- Adossé à un stockage d'objets : Loki assure la persistance des données sur un stockage d'objets compatible S3, ce qui limite l'empreinte opérationnelle (sans PVC ni cluster de bases de données supplémentaire à gérer).
- Métadonnées structurées : À l'avenir, CloudKitty stockera des métadonnées indexées (client, type de métrique, type d’instance) directement au sein de chaque entrée de journal. Cette méthode permettra de filtrer rapidement les requêtes sans analyse JSON complète, améliorant ainsi de manière significative les performances d'exécution à grande échelle.
La configuration des métriques
Le fichier metrics.yaml se situe au cœur de l'étape de collecte. Ce fichier indique à CloudKitty quelles métriques Prometheus collecter et comment les traiter. Voici un extrait représentatif de la configuration fournie :
métriques :
ceilometer_cpu:
unit: instance
alt_name: instance
groupby:
- resource
- user
- project
- flavor_name
- flavor_id
mutate: NUMBOOL
extra_args:
aggregation_method: max
ceilometer_image_size:
unit: MiB
factor: 1/1048576
groupby:
- resource
- project
metadata:
- container_format
- disk_format
extra_args:
aggregation_method: maxChaque entrée contrôle la manière dont CloudKitty collecte et interprète une métrique Prometheus spécifique :
unit: L'unité de facturation qui apparaît dans les rapports de tarification (par exemple, instance, Gio, B, ip).alt_name: Un autre nom pour la métrique. Lors de la création de services hashmap, vous pouvez utiliser soit le nom de la métrique Prometheus (ceilometer_cpu), soit lealt_name(instance).groupby: Les étiquettes Prometheus utilisées pour désagréger la métrique. Pour ceilometer_cpu, le regroupement par flavor_name et flavor_id permet d'activer les règles de tarification basées sur les type d’instances configurées précédemment.mutate: Une transformation appliquée à la valeur brute. NUMBOOL convertit toute valeur non nulle en 1, ce qui convient tout à fait à la sémantique « cette ressource est-elle active ? », car nous ne nous intéressons pas au compteur de processeur brut, mais seulement au fait que l'instance soit en cours d'exécution.factor: Un facteur de multiplication pour la conversion d'unités. Par exemple,ceilometer_image_sizeutilise 1/1048576 pour fixer les octets bruts en Mio.metadata: Étiquettes Prometheus supplémentaires à transmettre aux données évaluées à des fins d'information (par exemple,container_format,disk_formatpour les images).extra_args: Arguments spécifiques au back-end.aggregation_method: maxindique au collecteur Prometheus d'utiliser la valeur maximale au cours de chaque période de collecte.
Puisque le collecteur de CloudKitty communique directement avec Prometheus, la tarification de toute métrique disponible est simple : ajoutez une nouvelle entrée dans metrics.yaml avec les étiquettes et l'unité appropriées, et CloudKitty commencera à la collecter et à la tarifer lors du cycle de traitement suivant.
Inspection des données brutes
Alors que la commande openstack rating summary get fournit des totaux agrégés, vous devez parfois examiner les données de plus près. Que vous vérifiiez que vos règles de tarification sont correctement appliquées, que vous déboguiez une métrique manquante ou que vous essayiez de comprendre ce que CloudKitty stocke, la commande openstack rating dataframes get vous permet d'inspecter les points de données tarifés individuels qui résident dans Loki.
Considérez les récapitulatifs comme le relevé mensuel et les dataframes comme les lignes individuelles du reçu.
Pour récupérer les dataframes bruts tarifés pour une période spécifique :
openstack rating dataframes get --begin 2026-03-01T00:00:00Z --end 2026-03-01T01:00:00ZChaque ligne de la sortie représente un point de données tarifé unique pour une seule période de collecte :
| Début | Fin | Type de métrique | Unité | Qté | Prix | Grouper par | Métadonnées |
|---|---|---|---|---|---|---|---|
2026-03-01T00:00:00Z |
2026-03-01T01:00:00Z |
ceilometer_cpu |
instance |
1 |
0.05 |
flavor_id=<uuid>, flavor_name=m1.large, project=<project_uuid>, resource=<vm_uuid> |
|
2026-03-01T00:00:00Z |
2026-03-01T01:00:00Z |
ceilometer_cpu |
instance |
1 |
0.01 |
flavor_id=<uuid>, flavor_name=m1.tiny, project=<project_uuid>, resource=<vm_uuid> |
Voici ce que chaque colonne vous indique :
- Début/Fin : La période de collecte que couvre ce point de données. Par défaut, CloudKitty collecte les données toutes les heures. Vous verrez donc des créneaux d'une heure.
- Type de métrique : Le nom de la métrique issu de
metrics.yaml(par exemple,ceilometer_cpu,ceilometer_ip_floating). - Unité : L'unité de facturation, telle que définie dans
metrics.yaml. - Qté : La quantité brute après toute transformation par mutation ou facteur. Pour
ceilometer_cpuavecNUMBOOL, cette valeur sera de 1 si l'instance était en cours d'exécution. - Prix : La valeur évaluée après l'application de vos règles de hashmap. Cet espace permet de vérifier qu'un mappage correcte a été appliqué. Si vous configurez
m1.largesur 0,05, cette valeur doit s'afficher ici. - Regrouper par : Les valeurs d'étiquette des champs
groupbydansmetrics.yaml. Ce mécanisme permet à CloudKitty de désagréger les données et d'explorer en détail des ressources, des variantes ou des projets spécifiques. - Métadonnées : Toutes les étiquettes supplémentaires transmises via le champ de métadonnées dans
metrics.yaml.
Cet outil concret permet aux équipes d'exploitation de tracer le parcours complet, de la métrique brute au prix final, rendant le comportement de CloudKitty transparent et déboguable à chaque étape.
Prêt à évaluer les coûts ?
Que votre objectif consiste à récupérer rigoureusement les coûts auprès des services internes ou à offrir une visibilité transparente sur la consommation des ressources, CloudKitty fournit les données structurées et fiables nécessaires pour y parvenir. Ce service fait le lien entre la télémétrie OpenStack brute et votre middleware FinOps d'entreprise.
L'époque où l'on considérait le cloud privé comme un buffet à volonté gratuit est révolue. Nous sommes ravis d'intégrer cette fonctionnalité native et hautement personnalisable à l'écosystème OpenStack Services on OpenShift dans la version 5. Il est temps de cesser les suppositions et de commencer la tarification des coûts.
Lancez-vous
Consultez la documentation officielle pour configurer et gérer CloudKitty dans votre environnement :
- Activation de la tarification des coûts du cloud dans un environnement OpenStack Services on OpenShift
- Utilisation du service de tarification
Découvrez-le en action
Regardez la vidéo de démonstration pour découvrir comment configurer facilement des règles de tarification basées sur des variantes et extraire un premier bilan mensuel.
Cette vidéo présente une sélection de deux sessions de terminal distinctes. Pour examiner de plus près et de manière interactive les commandes brutes exécutées en coulisses, vous pouvez consulter les enregistrements Asciinema complets et non coupés ici :
- https://asciinema.org/a/ofDLdVKxHfMAsaNM : Déploiement de CloudKitty et création des règles de tarification basées sur les variantes.
- https://asciinema.org/a/P11NR7CEqfiewF4R : Vérification des dataframes de rétrofacturation et extraction du récapitulatif mensuel.
Essai de produit
Red Hat OpenShift Container Platform | Essai de produit
À propos des auteurs
Juan Larriba is a software engineer specializing in cloud infrastructure and OpenStack observability. He is a contributor to the OpenStack Kubernetes Operators ecosystem, where he works on the Telemetry Operator — a project that brings together metrics collection, alarming, and rating services like CloudKitty into cloud-native Kubernetes deployments. His work focuses on bridging traditional OpenStack telemetry components with modern container-native architectures, helping operators gain visibility and cost insight into their cloud workloads. Juan is passionate about open source collaboration and has contributed to projects spanning Ceilometer, Aodh, and CloudKitty, with a focus on making rating and chargeback capabilities more accessible in production OpenStack environments.
Plus de résultats similaires
Migration des machines virtuelles après le « lift-and-shift »
Red Hat OpenShift 4.21 : mise à l'échelle intelligente, migration accélérée et efficacité optimisée par l'IA
Transforming Your Secrets Management | Code Comments
Transforming Your Database | Code Comments
Parcourir par canal

Automatisation
Les dernières nouveautés en matière d'automatisation informatique pour les technologies, les équipes et les environnements

Intelligence artificielle
Actualité sur les plateformes qui permettent aux clients d'exécuter des charges de travail d'IA sur tout type d'environnement

Cloud hybride ouvert
Découvrez comment créer un avenir flexible grâce au cloud hybride

Sécurité
Les dernières actualités sur la façon dont nous réduisons les risques dans tous les environnements et technologies

Edge computing
Actualité sur les plateformes qui simplifient les opérations en périphérie

Infrastructure
Les dernières nouveautés sur la plateforme Linux d'entreprise leader au monde

Applications
À l’intérieur de nos solutions aux défis d’application les plus difficiles
Virtualisation
L'avenir de la virtualisation d'entreprise pour vos charges de travail sur site ou sur le cloud