Running Llama 70B as an on-demand cloud inference endpoint costs roughly $16,000 per month. Running Llama 8B costs about $734. For teams where an 8B model meets the quality bar for their workload, that gap is very hard to ignore.
The question enterprise teams are asking is rarely, "how do we get the most powerful model?" It is almost always, "how do we get a model that's fast enough, accurate enough, and affordable enough to run reliably in our environment?" Those are different questions, and they often lead to different answers, pointing toward smaller models more often than teams expect.
The cost of going big
Model size is measured in parameters, the learned weights that shape how a model understands and generates language. The field has settled on a rough taxonomy—small models run from around 0.5 to 8 billion parameters, medium from 8 to 70 billion, and large from 70 billion to 1 trillion and beyond.
Parameter count drives hardware requirements, which drives cost. Llama 8B fits on a single NVIDIA A10 GPU. Llama 70B at full precision needs eight NVIDIA A100s 40GB. Llama 405B requires eight NVIDIA H100s 80GB. The cost difference across those tiers is exponential.
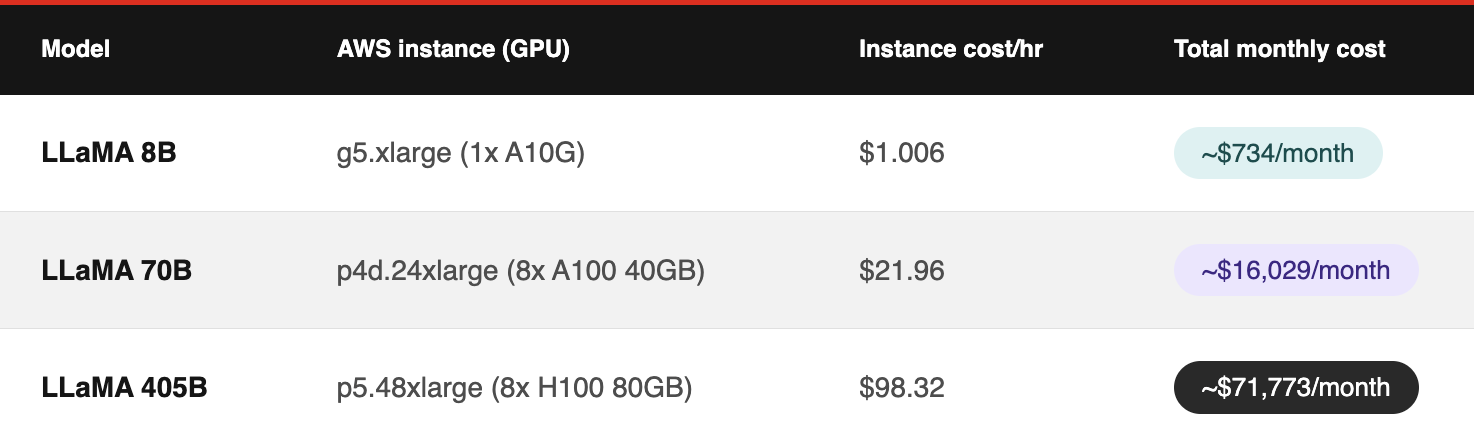
Figure 1: Monthly inference costs for on-demand cloud instances by model size.
Table assumptions: Pricing reflects on-demand Linux/Unix (x86) rates with no Savings Plans or Reserved Instances applied. Region: US East (N. Virginia, us-east-1). GPU counts verified from AWS documentation. Costs assume continuous 730-hour monthly usage and exclude storage, EBS, data transfer, and OS licensing fees.
For many enterprise workloads, classification, extraction, summarization, routing, structured generation, and retrieval-augmented steps simply don't require a 70B model. A purpose-built smaller model, properly optimized, or a large model that has been quantized, can meet the quality bar at a fraction of the infrastructure cost. Scaling the model means scaling inference cost and time, and that math compounds quickly in production.
Going smaller without losing accuracy
The strongest objection to smaller models is lower accuracy relative to larger models, which is a fair concern. To get around this, however, you can reduce the precision of a larger model's weights and make it smaller. This is called quantization. Quantization can retain over 99% of the baseline accuracy, as seen in the test below.
Testing this with Granite 3.1 8B Instruct tells an interesting story. Using LLM Compressor to apply 4-bit integer (INT4) quantization, the model drops from 16GB to 4GB, a 4x reduction in size. On the OpenLLM Leaderboard V1, the quantized model scores 69.8 versus 70.3 for the base brain floating Point 16-bit (BF16) model. That is a 99.3% accuracy recovery. On a retrieval-augmented generation (RAG) inference scenario on vLLM with an NVIDIA A6000 GPU at 1024 prompt and 128 decode tokens, inference time drops from 3.4 seconds to 1.5 seconds.
4x smaller. More than 2x faster. Less than 1% accuracy loss.
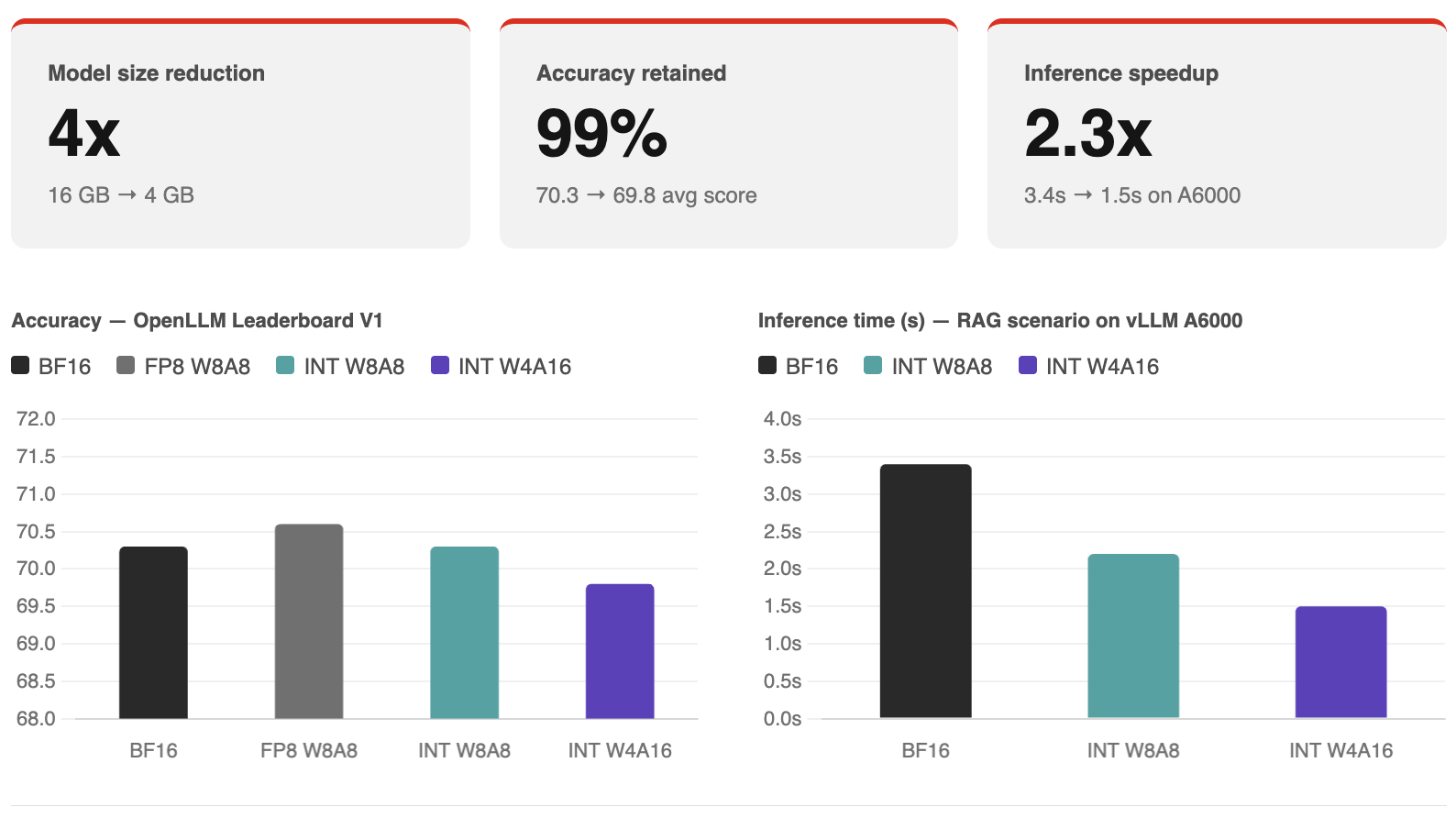
Figure 2: Granite 3.1 8B Instruct benchmarks after INT4 quantization using LLM Compressor, evaluated with LM Evaluation Harness and served with vLLM.
Sources:
Those results are possible because of how compression techniques work.
- Quantization reduces the numerical precision of a model's weights, moving from 16-bit floating point to lower precision formats like 8-bit floating point (FP8) orINT4, while preserving most of the model's useful behavior. Large language models (LLMs) that Red Hat has optimized and open sourced on Hugging Face all recover to 99% or more of their baseline accuracy.
- Distillation trains a smaller model to replicate the outputs of a larger one.
- Sparsity zeroes out weights that contribute least to the model's predictions so they can be skipped entirely during inference.
LLM Compressor ties these together into a repeatable, production-ready pipeline. It applies algorithms—including GPTQ, SparseGPT, SmoothQuant, and more—to produce a compressed model checkpoint in the compressed tensors format, and integrates directly with vLLM for serving.
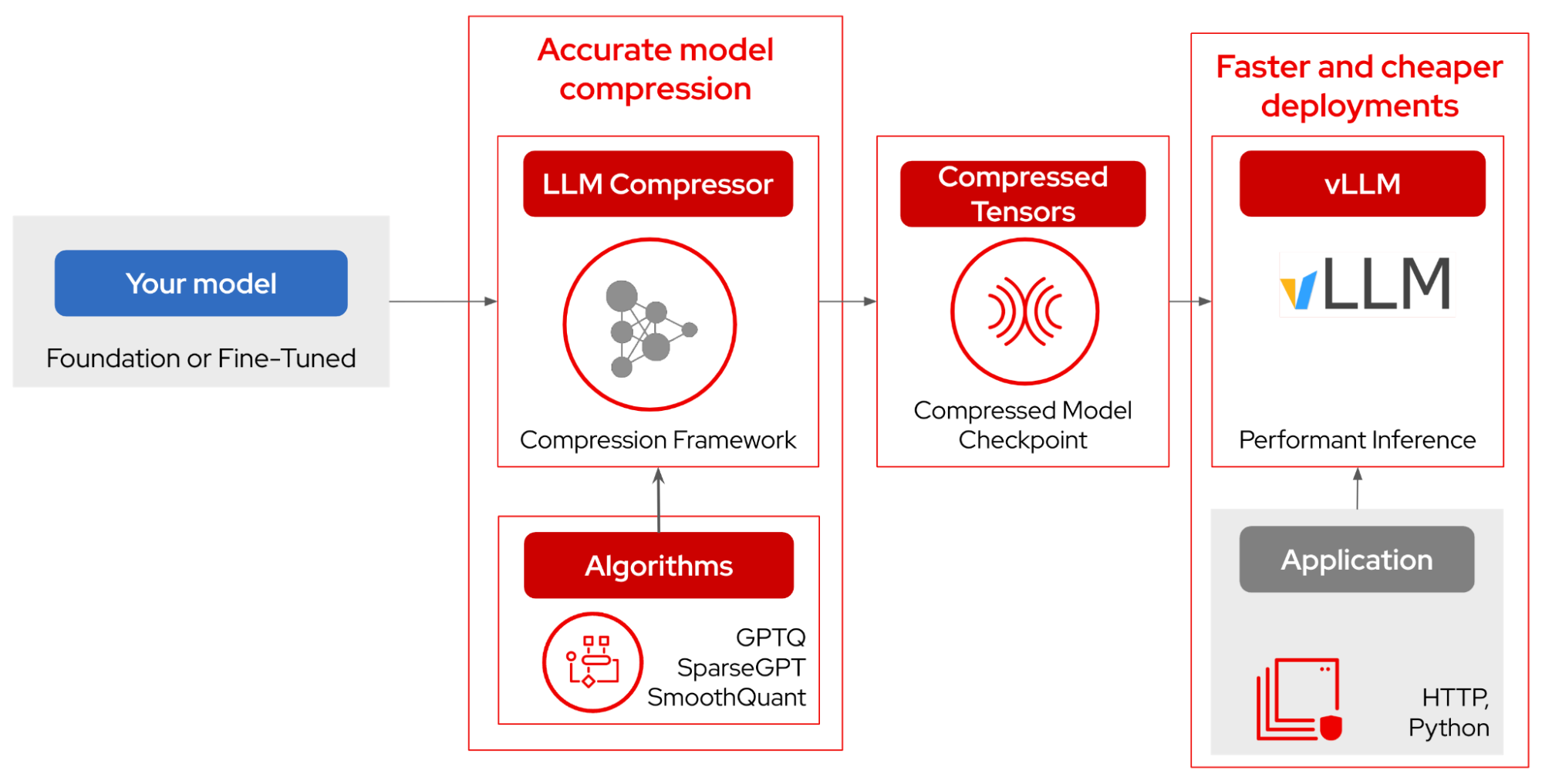
Figure 3: The LLM Compressor pipeline from model input to production inference.
The case for running locally
Cost and speed are not the only reasons to think carefully about model size. For many enterprise teams, the more important argument is control.
Running models locally or on-premises keeps sensitive data inside environments the organization controls. This control matters in healthcare, financial services, legal, and any regulated context where routing data through an external inference endpoint creates compliance risk. It also means owning the full inference stack—batching, concurrency, key-value (KV) cache behavior, quantization level, speculative decoding, GPU placement, and networking.
Smaller models make local deployment practical. They fit on hardware most organizations already have, or can run on a single GPU node rather than a multinode cluster. This ability makes them a useful sandbox for building agents or RAG pipelines without upfront infrastructure investment. Teams can prototype, benchmark, and iterate before committing to larger deployments.
Smaller models in agentic workflows
Most agent pipelines involve a mix of tasks with very different capability requirements. A routing decision, a classification call, a structured extraction, a retrieval-augmented lookup—none of these require the same model that handles open-ended reasoning or complex synthesis. Smaller purpose-built models can handle well-scoped steps in an agent pipeline efficiently and reliably, while larger model capacity is reserved for the steps that genuinely need it.
The right model for any workload is an empirical question, not a theoretical one. GuideLLM helps teams benchmark serving performance across model variants and hardware configurations. LM Evaluation Harness provides task-level quality comparisons across model sizes and quantization levels. Together, they give teams the data to make model selection decisions based on evidence rather than assumptions.
The Red Hat AI repository on Hugging Face is a practical starting point. It's a collection of validated and optimized models including Llama, Granite, Mistral, Qwen, Gemma, DeepSeek, Phi, Molmo, and Nemotron, tested with GuideLLM and LM Evaluation Harness, and compressed with LLM Compressor using the latest quantization algorithms.
The goal is not to minimize model size for its own sake, it's to find the model that meets the quality bar for the task while fitting the latency, cost, and deployment constraints of the production environment. For a large share of enterprise workloads, that model is smaller than most teams may initially assume.
Experiment for yourself
Browse pre-quantized and validated models at the Red Hat AI repository on Hugging Face. For serving benchmarks, see GuideLLM. For model compression, see LLM Compressor. For quality evaluation across model sizes, see LM Evaluation Harness.
Ressource
Bien débuter avec l'inférence d'IA
À propos des auteurs

Legare Kerrison is a Technical Marketing Manager and Developer Advocate working on Red Hat's Artificial Intelligence offerings. She is passionate about open source AI and making technical knowledge accessible to all. She is based out of Boston, MA.

Plus de résultats similaires
Cessez de gérer le passé et commencez à bâtir l'avenir de l'informatique
De l'inférence aux agents : mise à l'échelle de l'IA en entreprise avec Red Hat AI 3.4
Technically Speaking | Build a production-ready AI toolbox
Technically Speaking | Platform engineering for AI agents
Parcourir par canal

Automatisation
Les dernières nouveautés en matière d'automatisation informatique pour les technologies, les équipes et les environnements

Intelligence artificielle
Actualité sur les plateformes qui permettent aux clients d'exécuter des charges de travail d'IA sur tout type d'environnement

Cloud hybride ouvert
Découvrez comment créer un avenir flexible grâce au cloud hybride

Sécurité
Les dernières actualités sur la façon dont nous réduisons les risques dans tous les environnements et technologies

Edge computing
Actualité sur les plateformes qui simplifient les opérations en périphérie

Infrastructure
Les dernières nouveautés sur la plateforme Linux d'entreprise leader au monde

Applications
À l’intérieur de nos solutions aux défis d’application les plus difficiles
Virtualisation
L'avenir de la virtualisation d'entreprise pour vos charges de travail sur site ou sur le cloud