
Security is one of the key concerns for both infrastructure and application teams when operating in an OpenShift environment. Infrastructure teams need to be cognizant of the level of access for which they grant consumers of the platform, while application teams need to have an understanding of the level of access that they will need for their applications. Failure to adhere to these principles increases the potential for a security compromise. As the utilization of cloud-based services (such as databases and storage backends) continues to rise, it becomes increasingly important that only those authorized actors are able to consume the associated services. Access is typically managed through an Identity and Access Management (IAM) system within the cloud provider where policies are managed and associated to principals, such as users and groups. One of the approaches for accessing cloud services in Kubernetes is to attach IAM roles to the individual node members of the cluster. However, doing so would violate the principles of least privilege as any pod running on the node will be able to take advantage of the level of access that has been granted to the node in addition to any of the permissions that are configured by default as part of the base OpenShift deployment. Multitenancy, one of the key traits of OpenShift, is also breached. Instead, a desired implementation would make use of separate IAM roles for each application. Through advances in both the level of support provided in cloud providers and functionality added to Kubernetes and OpenShift, it is now possible to support this type of architecture for leveraging IAM roles at an application level.
The community has seen a need for restricting access to IAM roles at a pod level for some time now and in turn several projects (kube2iam and kiam for instance) were created in order to address these concerns. However, while these solutions enable the use of IAM roles for applications, they actually add another security concern as they use iptables rules to intercept and restrict access to the AWS API. By requiring access to the underlying networking services of the Kubernetes nodes, it made the solution unfit in most managed Kubernetes hosted platforms. In late 2019, AWS unveiled support as part of their Elastic Kubernetes Services (EKS) to leverage fine grained access to IAM roles within Service Accounts in pods. The implementation uses a feature introduced in Kubernetes version 1.12 called a ProjectedServiceAccountToken which automatically mounts an OpenID Connect (OIDC) Json Web Token (JWT) in a pod that can be used in conjunction with a publicly accessible OIDC discovery provider containing the signing keys which can accept and validate those issued by the platform to communicate with external IAM systems. As of the release of OpenShift 4.4, support for the ProjectedServiceAccountToken feature was made available. However, even though support was added to OpenShift, volumes containing the service account token are not automatically added to pods. The AWS EKS team open sourced a project called the amazon-eks-pod-identity-webhook which makes use of a MutatingWebhookConfiguration to modify the configuration of pods at runtime. The remainder of this article will describe how OpenShift is configured along with the steps that application teams need to perform in order to take advantage of this feature.
While this type of implementation is not restricted to a single cloud provider, the following will demonstrate how OpenShift can use IAM roles defined within Amazon Web Services (AWS) to provide access to an S3 bucket defined within the cloud provider and accessible by an application.This approach requires actions first by both OpenShift administrators to make the feature available within the platform, followed by configurations set by application teams to grant OpenShift access to their managed services. The following table describes the key steps that will be performed throughout the course of this article by each team:
|
OpenShift Infrastructure Team |
Application Team |
|
|
A diagram of the end state architecture is found below
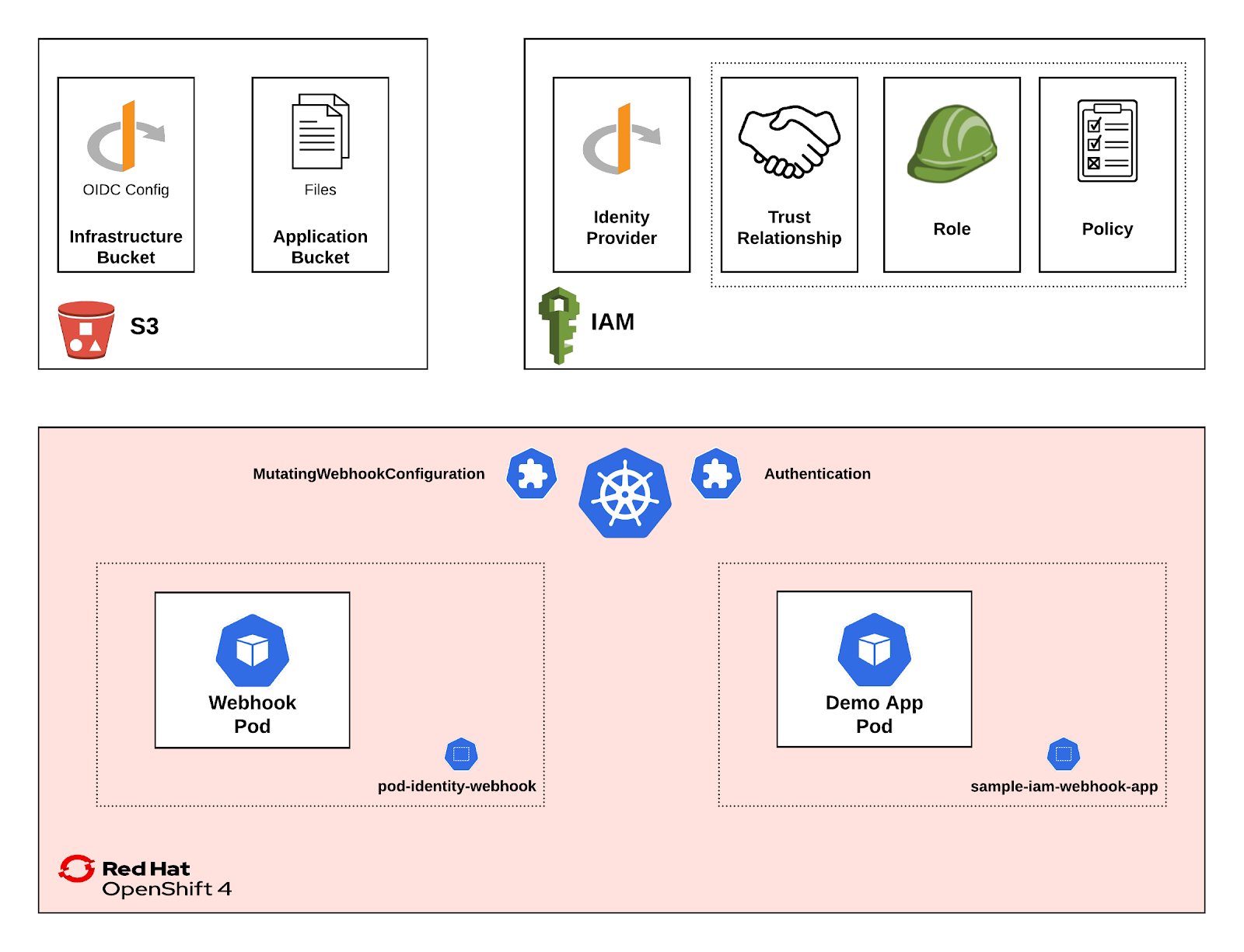
In order to complete this approach in your OpenShift cluster, you must have cluster-admin access along with access to manage AWS IAM resources. The openshift-aws-iam-webhook-integration repository contains tooling to support and implement the scenario. Clone the repository to your local machine:
$ git clone https://github.com/sabre1041/openshift-aws-iam-webhook-integration.git
A script called iam-webhook-s3-example.sh is provided in the repository which fully provisions both the OpenShift and AWS resources. If desired, steps on how to execute the script along with any necessary prerequisites can be found in the repository README. Otherwise, we will walk through each of the steps that the script automates in order to better understand the architecture and implementation.
Establishing an OIDC Endpoint
Since OpenShift and the ProjectedServiceAccountToken feature use OIDC JWT tokens as one of the core components, the first step is to create an OIDC Identity provider with AWS IAM. While EKS provides a public OIDC discovery endpoint, other distributions of Kubernetes, such as OpenShift, require one to be established. A OIDC discovery endpoint provides the location of the OIDC provider and the assets can be hosted on any web server accessible by AWS and OpenShift. For simplicity sake, a dedicated S3 bucket will be used. This is a different bucket that the bucket will be eventually used by the example application as part of this implementation as it allows for further separation of concerns between infrastructure related resources and application related resources. An overview of how S3 buckets can be used to host static web content can be found here.
Using the AWS CLI or the AWS Web Console, create a new S3 bucket with a name of your choosing (such as ocp-iam-role-oidc). After specifying the name of the bucket and when specifying the set of permissions that should be applied to the bucket, uncheck the “Block all public access” option as some of the access needs to be available without any authentication. Acknowledge the warning message and complete the bucket creation process.
Two files will need to be be created and uploaded to the bucket:
- OIDC Discovery document
- A JSON Web Key (JWK) containing the signing keys for the ProjectedServiceAccountToken that can validated by AWS IAM
The amazon-eks-pod-identity-webhook project contains a utility to easily generate the required JWK. Prebuilt binaries for Linux and OSX have been provided in the bin folder of the demo project repository to remove having golang tooling installed in order to generate the files. The tool requires that the public key for the bound service account within the OpenShift environment be provided as an input. Execute the following command to extract the certificate to a file called sa-signer-pkcs8.pub.
$ oc get -n openshift-kube-apiserver cm -o json bound-sa-token-signing-certs | jq -r '.data["service-account-001.pub"]' > sa-signer-pkcs8.pub
Navigate to the demo project repository and execute the following command to generate the JWK in a file called keys.json replacing “linux” or “darwin” based upon your operating system:
$ bin/self-hosted-<linux|darwin> -key "sa-signer-pkcs8.pub" | jq '.keys += [.keys[0]] | .keys[1].kid = ""' > “keys.json"
Now create the OIDC discovery JSON document in a file called discovery.json
{
"issuer": "https://<ISSUER_HOSTPATH>/",
"jwks_uri": "https://<ISSUER_HOSTPATH>/keys.json",
"authorization_endpoint": "urn:kubernetes:programmatic_authorization",
"response_types_supported": [
"id_token"
],
"subject_types_supported": [
"public"
],
"id_token_signing_alg_values_supported": [
"RS256"
],
"claims_supported": [
"sub",
"iss"
]
}
Replace the value of the <ISSUER_HOSTPATH> with the hostname of the S3 bucket previously created. The hostname takes the form s3.<AWS_REGION>.amazonaws.com/<BUCKET_NAME>. So, if our bucket was located in the us-east-2 region, the hostname would take the form s3.us-east-2.amazonaws.com/ocp-iam-role-oidc.
Note: For users with workloads in the us-east-1 region, the first period (.) is instead replaced with a dash (-) is used instead of a period (.)The first period (.) after s3 is replaced with a dash (-) instead.
With the JWK key file (keys.json) and OIDC discovery document created, upload the files to the S3 bucket. The discovery document must be placed in a file called .well-known/openid-configuration while the JWK file can retain the name keys.json and be placed at the root of the bucket. In addition, the public read ACL option must be set for both of these files so that they can be accessed without any authentication.
Instead of using the web console, the following CLI commands will upload the content to the S3 bucket:
$ aws s3 cp keys.json s3://<BUCKET_NAME>/ --acl public-read
$ aws s3 cp discovery.json s3://<BUCKET_NAME>/.well-known/openid-configuration --acl public-read
Confirm both of these files can be accessed at the following locations:
- https://s3.<AWS_REGION>.amazonaws.com/<BUCKET_NAME>/keys.json
- https://s3.<AWS_REGION>.amazonaws.com/<BUCKET_NAME>/.well-known/openid-configuration
Now that you have a valid publicly accessible OIDC discovery endpoint, create an AWS Identity Provider within the IAM service:
- Navigate to the AWS IAM Service
- Select Identity Providers and then select Create Provider
- Select OpenID Connect from the Provider Type dropdown
- The Provider URL refers to the URL of the S3 bucket (such as https://s3.<AWS_REGION>.amazonaws.com/<BUCKET_NAME>/). Authentication requests against this identity provider will be sent to this URL and leverage the assets previously configured within the bucket.
- Enter sts.amazonaws.com in the Audience field
- Click Next Step and then Create Provider
Verifying OIDC Tokens
With the Identity Provider created, OpenShift can now be configured to use the URL of the identity provider to verify OIDC JWT tokens. The authentication.config.openshift.io resource contains a field called serviceAccountIssuer that when set, will configure the --oidc-issuer-url Kubelet argument. Execute the following command to set the serviceAccountIssuer to the URL of the S3 bucket:
$ oc patch authentication.config.openshift.io cluster -p '{"spec":{"serviceAccountIssuer":"https://<BUCKET_URL>"}}' --type=merge
Deploying the Webhook (OpenShift 4.4-4.6)
The final responsibility from an OpenShift administrator's perspective to make fine grained IAM roles available for applications is to have a MutatingWebook available within the cluster to automatically inject pods with the ProjectServiceAccountToken volume, OpenShift 4.7 incorporated the pod-identity-webhook application as part of the default installation of the cluster in the openshift-cloud-credential-operator namespace. The remainder of this section can be omitted if operating using OpenShift 4.7 or higher.
For OpenShift versions 4.4-4.6, the pod-identity-webhook must be deployed manually. Deploy the webhook by executing the following command from the demo repository:
$ oc apply -f manifests/pod-identity-webhook
Note: Due to potential race conditions, you may need to run the command twice
A new namespace called pod-identity-webhook will be created for which the resources will then be added to. Wait until the deployment rolls out successfully:
$ oc rollout status deploy/pod-identity-webhook -n pod-identity-webhook
Once the pod starts up, it will create a CertificateSigningRequest (CSR). Use the following command to list out the CSR’s.
$ oc get csr -o jsonpath="{ .items[?(@.spec.username==\"system:serviceaccount:pod-identity-webhook:pod-identity-webhook\")].metadata.name}"
Once a CSR displays, approve it:
$ for csr in `oc get csr -o jsonpath="{ .items[?(@.spec.username==\"system:serviceaccount:pod-identity-webhook:pod-identity-webhook\")].metadata.name}"`; do oc adm certificate approve $csr; done
With the new certificate approved, delete the existing running pod so the webhook will be able to function as expected,
$ oc delete pod -n pod-identity-webhook -l=app.kubernetes.io/name=pod-identity-webhook
Now, create the MutatingWebhookConfiguration which will redirect requests to create new pods to the webhook endpoint. Before it can be created the Certificate Authority (CA) bundle from the cluster must be obtained and stored in a local variable:
$ CA_BUNDLE=$(oc get configmap -n kube-system extension-apiserver-authentication -o=jsonpath='{.data.client-ca-file}' | base64 | tr -d '\n')
Create the MutatingWebHookConfiguration
(
cat <<EOF
apiVersion: admissionregistration.k8s.io/v1beta1
kind: MutatingWebhookConfiguration
metadata:
name: pod-identity-webhook
namespace: pod-identity-webhook
webhooks:
- name: pod-identity-webhook.amazonaws.com
failurePolicy: Ignore
clientConfig:
service:
name: pod-identity-webhook
namespace: pod-identity-webhook
path: "/mutate"
caBundle: ${CA_BUNDLE}
rules:
- operations: [ "CREATE" ]
apiGroups: [""]
apiVersions: ["v1"]
resources: ["pods"]
EOF
) | oc apply -f-
So, when the endpoint defined by the MutatingWebHook configuration is invoked, what role action is performed? Not every pod that is created on the platform requires the use of a ProjectedServiceAccountToken volume. If you inspect the Deployment for the pod-identity-webhook, you will notice a parameter called --annotation-prefix=sts.amazonaws.com. This refers to the presence of an annotation on the ServiceAccount used to run the pod and if one is found matching the value sts.amazonaws.com, the pod will be mutated accordingly by the webhook container.
At this point, the majority of the infrastructure related activities needed in order to support fine grained IAM roles by applications is complete. Focus for the remainder of this discussion will shift to the perspective of application teams and the tasks they need to complete in order to take advantage of this functionality.
Application Team Prerequisites
As application teams look to leverage fine grained IAM roles within their application, there are a set of steps that need to be completed in order to integrate containers running on the platform with services from the cloud provider. In the demonstration scenario described previously, an application running on OpenShift is looking to consume an S3 bucket hosted on AWS.
Let's go ahead and create an S3 bucket (it can be called ocp-iam-role-app, for example). Unlike the previously created bucket hosting OIDC assets, the default set of permissions with regards to public access can be used as the contents of the bucket will remain private.
Next, an IAM role must be created that will be used by the application running on OpenShift to access the bucket. With an ongoing focus on security and least privilege access, a new policy will be created to restrict access to only the previously created bucket.
From the AWS console and the IAM service, select Policies and then Create Policy
Click on the JSON tab and paste in the following policy definition.
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"s3:ListAllMyBuckets"
],
"Resource": "arn:aws:s3:::*"
},
{
"Effect": "Allow",
"Action": ["s3:ListBucket"],
"Resource": ["arn:aws:s3:::<APP_BUCKET_NAME>"]
},
{
"Effect": "Allow",
"Action": [
"s3:PutObject",
"s3:GetObject",
"s3:DeleteObject"
],
"Resource": ["arn:aws:s3:::<APP_BUCKET_NAME>/*"]
}
]
}
Replace the <APP_BUCKET_NAME> with the name of the bucket previously created and click Review Policy.
Enter a name for the policy (such as ocp-iam-app-policy) and then click Create Policy.
Since the goal of this approach is to be able to leverage an IAM role from within an application in order to access cloud services, create an IAM role that uses the previously created policy to access the S3 bucket.
In the AWS IAM console, select Roles and then Create Role.
Under the type of Trusted Entity, select Web Identity and then choose the Identity Provider previously created in the Identity Provider dropdown. Then click Next: Permissions.
In the Attach Permission Policies page, select the policy that was previously created and then select Next: Tags. Enter any tags that you would like to add and then select Next: Review.
Enter a desired name for the newly created IAM role (such as ocp-iam-role) along with an optional description and then click Create Role.
Once the role has been created, you will then need to configure the Trust Policy associated with the role. A trust policy specifies the members who are able to assume the role. In the case of OpenShift, this would be the service account that is configured to run the application pod.
Locate the role that was previously created and click on the Trust Relationships tab and then click on Edit Trust Relationships.
When the role was defined, it created a default trust policy. OIDC identity federation, that we enabled previously, allows users to leverage the AWS Secure Token Service (STS) to receive a JWT token that can be used to assume the IAM role. This is enabled through the sts:AssumeRoleWithWebIdentity IAM action. Update the Trust Policy to specify the IAM action and reference the OIDC provider configured for the OpenShift environment as shown below:
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Principal": {
"Federated": "<OIDC_IDENTITY_PROVIDER_ARN>"
},
"Action": "sts:AssumeRoleWithWebIdentity"
}
]
}
In a typical environment, an OpenShift infrastructure team would be responsible for configuring the OIDC identity provider and they would need to provide the Amazon Resource Name (ARN) to the application team which would replace the placeholder in the Trust Policy provided previously. Since you are acting in the capacity of both the OpenShift infrastructure team and application team roles, locate and replace the ARN for the OIDC identity provider which is found on the Summary Page for the Identity Provider previously created.
This Trust Policy allows any service account running in OpenShift the ability to assume the role. Additional conditions can be added to the Trust Policy to limit the namespaces for which Service Accounts are part of or to allow only specific user accounts. An example of how to limit access to a specific ServiceAccount is shown below:
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Principal": {
"Federated": "<OIDC_IDENTITY_PROVIDER_ARN>"
},
"Action": "sts:AssumeRoleWithWebIdentity",
"Condition": {
"__doc_comment": "scope the role to the service account (optional)",
"StringEquals": {
"<OIDC_PROVIDER_URL>:sub": "system:serviceaccount:<OCP_NAMESPACE>:<OCP_SERVICE_ACCOUNT>"
}
}
}
]
}
Replace <OIDC_PROVIDER_URL>, <OCP_NAMESPACE>, and <OCP_SERVICE_ACCOUNT> with the value displayed on the Identity Provider summary page along with the name, name of the namespace the application is deployed within, and the name of the service account respectively.
Once the desired Trust Policy has been updated, click Update Trust Policy to apply the manifest.
At this point, all of the necessary configurations on the AWS side have been completed. Focus can now shift to the deployment of a sample application that assumes the IAM role to access the S3 bucket.
Application Deployment
A sample application has been provided containing the AWS CLI utility to demonstrate the use of accessing cloud services using fine grained IAM roles.
First, create a new namespace for the application called sample-iam-webhook-app by executing the following command from the root of the demonstration repository:
$ oc apply -f manifests/sample-app/namespace.yaml
Next, create a new Service Account called s3-manager
$ oc create sa s3-manager -n sample-iam-webhook-app
If you recall, the amazon-eks-pod-identity-webhook makes use of an annotation (beginning with eks.amazonaws.com (OpenShift 4.7+) or sts.amazonaws.com (OpenShift 4.4-4.6) in our deployment) present on Service Accounts to determine whether to mutate the pod before being admitted to the cluster. This annotation should contain the ARN of the IAM Role that is desired for use by the pod.
Locate the ARN of the role on the summary page for the role previously created by navigating to the Roles page in the AWS IAM web console. Annotate the service account by executing the following command:
OpenShift 4.7+
$ oc annotate -n sample-iam-webhook-app serviceaccount s3-manager eks.amazonaws.com/role-arn=<ROLE_ARN>
OpenShift 4.4-4.6
$ oc annotate -n sample-iam-webhook-app serviceaccount s3-manager sts.amazonaws.com/role-arn=<ROLE_ARN>
Finally, deploy the sample application:
$ oc apply -f manifests/sample-app/deployment.yaml
After a few moments, the pod should be in a running state.
Application Verification
With the application deployed, let’s verify that the cloud assets can be accessed. First, display the contents of the manifest of the running pod to confirm the webhook successfully mutated the pod.
Notice the inclusion of the following environment variables:
- name: AWS_ROLE_ARN
value: <ROLE_ARN>
- name: AWS_WEB_IDENTITY_TOKEN_FILE
value: /var/run/secrets/eks.amazonaws.com/serviceaccount/token
Most importantly, note the ProjectedServiceAccountToken volume within the volumes section:
volumes:
- name: aws-iam-token
projected:
defaultMode: 420
sources:
- serviceAccountToken:
audience: sts.amazonaws.com
expirationSeconds: 86400
path: token
First, ensure that your context is in the sample-iam-webhook-app project
$ oc project sample-iam-webhook-app
To demonstrate the use of fine grained IAM roles within the application, let’s start a remote shell to the running pod.
$ oc rsh $(oc get pod -l app.kubernetes.io/name=awscli -o jsonpath='{.items[0].metadata.name}')
The default IAM policy that was attached to the IAM role provided the ability to not only access the contents of a single bucket, but also the ability to list all other buckets. Using the AWS CLI included within the application, execute the following command to list all of the buckets in your account:
$ aws s3 ls
If the command ran successfully, the names of the buckets should be displayed and confirms that fine grained IAM roles are being injected properly.
Let’s create a new text file and upload it to our S3 bucket.
Create a file called ocp-validation.txt with some sample content
$ echo “This is a message from OpenShift” > /tmp/ocp-validation.txt
Upload the file to the bucket:
$ aws s3 cp /tmp/ocp-validation.txt s3://<BUCKET_NAME>/ocp-validation.txt
upload: tmp/ocp-validation.txt to s3://<BUCKET_NAME>/ocp-validation.txt
Using the AWS web console or the CLI tool, confirm the file is present in the bucket
$ aws s3 ls s3://<BUCKET_NAME>
2020-07-08 04:00:02 39 ocp-validation.txt
Finally, you can assert the level of permissions are being handled properly by attempting to upload the ocp-validation.txt file to another bucket that was displayed previously (If no other buckets were returned, feel free to create another bucket to demonstrate this scenario).
$ aws s3 cp /tmp/ocp-validation.txt s3://<INVALID_BUCKET_NAME>/ocp-validation.txt
upload failed: tmp/ocp-validation.txt to s3://<INVALID_BUCKET_NAME>/ocp-validation.txt An error occurred (AccessDenied) when calling the PutObject operation: Access Denied
Since the policy that was applied to the role only included access to the single bucket we created initially from an application perspective, the response was the expected result.
As illustrated in this article, the ability to make use of fine grained IAM roles within applications offers a variety of benefits for both an application team as well as from an OpenShift infrastructure team perspective. While there is a number of steps that needs to be taken in order to enable this type of functionality, future versions of OpenShift are expected to help eliminate some of the separate components that are required to be deployed and managed, to provide the same type of integrated experience as many of the other features that are included with the platform.
Sull'autore
Andrew Block is a Distinguished Architect at Red Hat, specializing in cloud technologies, enterprise integration and automation.
Altri risultati simili a questo
Smetti di gestire il passato e inizia a costruire il futuro dell'IT
Il prossimo punto di svolta dell'IA: trasformare gli agenti in superutenti aziendali
Crack the Cloud_Open | Command Line Heroes
Edge computing covered and diced | Technically Speaking
Ricerca per canale

Automazione
Novità sull'automazione IT di tecnologie, team e ambienti

Intelligenza artificiale
Aggiornamenti sulle piattaforme che consentono alle aziende di eseguire carichi di lavoro IA ovunque

Hybrid cloud open source
Scopri come affrontare il futuro in modo più agile grazie al cloud ibrido

Sicurezza
Le ultime novità sulle nostre soluzioni per ridurre i rischi nelle tecnologie e negli ambienti

Edge computing
Aggiornamenti sulle piattaforme che semplificano l'operatività edge

Infrastruttura
Le ultime novità sulla piattaforma Linux aziendale leader a livello mondiale

Applicazioni
Approfondimenti sulle nostre soluzioni alle sfide applicative più difficili
Virtualizzazione
Il futuro della virtualizzazione negli ambienti aziendali per i carichi di lavoro on premise o nel cloud