
Siamo entusiasti di presentare, in occasione del Ray Summit di quest'anno, lo stack infrastrutturale in corso di realizzazione con IBM Research, che comprende Ray e CodeFlare per i carichi di lavoro distribuiti con l'IA generativa. Le tecnologie sono state introdotte e sviluppate all'interno di community open source come Open Data Hub, prima di entrare a far parte di Red Hat OpenShift AI, su cui si basano anche i modelli di base di IBM watsonx.ai e IBM utilizzati da Red Hat Ansible Automation Platform. Red Hat OpenShift AI si avvale di un'efficace suite di strumenti e tecnologie progettati per semplificare e rendere scalabile ed efficiente il processo di fine tuning e di distribuzione dei modelli di base. La piattaforma offre questi strumenti per un'ottimizzazione, un addestramento e una distribuzione coerenti dei modelli, sia on premise che nel cloud. La nostra ultima opera presenta diverse opzioni di fine tuning e distribuzione dei modelli di base e offre ai professionisti specializzati in data science e MLOps funzionalità quali l'accesso in tempo reale alle risorse del cluster o la possibilità di pianificare i carichi di lavoro per l'elaborazione in batch.
Questo blog illustra come eseguire un fine tuning lineare, per poi distribuire un modello HuggingFace GPT-2 composto da 137 milioni di parametri su un set di dati WikiText utilizzando Red Hat OpenShift AI. Per quanto riguarda la fase di fine tuning, la porteremo a termine grazie allo stack Distributed Workloads con KubeRay alla base per la parallelizzazione e utilizzeremo lo stack KServer/Caikit/TGIS per il deployment e il monitoraggio del modello di base GPT-2 sottoposto a fine tuning.
Lo stack Distributed Workloads è costituito da due elementi principali:
- KubeRay: operatore Kubernetes per il deployment e la gestione di cluster Ray remoti che eseguono carichi di lavoro di elaborazione distribuiti; e
- CodeFlare: Kubernetes che si occupa del deployment e della gestione del ciclo di vita di tre componenti:
- CodeFlare-SDK: strumento per la definizione e il controllo dell'infrastruttura e dei processi di elaborazione distribuiti in remoto. L'operatore CodeFlare distribuisce un notebook con CodeFlare-SDK.
- Multi-Cluster Application Dispatcher (MCAD): un controller Kubernetes per la gestione dei processi in batch in un ambiente composto da uno o più cluster.
- InstaScale: strumento per la scalabilità on demand delle risorse aggregate in qualsiasi versione di OpenShift con configurazione MachineSets (autogestita o gestita, come Red Hat OpenShift on AWS o Open Data Hub).

Figura 1. Interazioni tra i componenti e il flusso di lavoro dell'utente in Distributed Workloads.
Come illustrato nella Figura 1, in Red Hat OpenShift AI l'ottimizzazione del modello di base inizia con CodeFlare, un framework dinamico in grado di snellire e semplificare i processi di creazione, addestramento e perfezionamento dei modelli. Inoltre puoi avvalerti delle potenzialità di Ray, un framework di elaborazione distribuito, e utilizzare KubeRay per distribuire in modo efficiente le attività di fine tuning, riducendo notevolmente i tempi di ottimizzazione delle prestazioni del modello. Una volta definito il carico di lavoro di fine tuning, MCAD mette in coda il carico di lavoro Ray finché non risultano soddisfatti i requisiti in termini di risorse e crea il cluster Ray soltanto quando è possibile pianificare tutti i pod.
Per quanto riguarda la distribuzione, lo stack KServe/Caikit/TGIS è composto da:
- KServe: Custom Resource Definition Kubernetes per i modelli di distribuzione in produzione che gestisce il ciclo di vita del deployment dei modelli
- Text Generation Inference Server (TGIS): infrastruttura di back-end o server di distribuzione che carica i modelli e fornisce il motore inferenziale
- Caikit: toolkit/runtime di IA che gestisce il ciclo di vita del processo TGIS e fornisce moduli ed endpoint inferenziali per la gestione dei vari tipi di modelli
- OpenShift Serverless (operatore indispensabile): si basa sul progetto open source Knative che permette agli sviluppatori di creare e distribuire applicazioni serverless e guidate dagli eventi di livello enterprise
- OpenShift Service Mesh (operatore indispensabile): si basa sul progetto open source Istio che fornisce una piattaforma di analisi comportamentale e controllo operativo sui microservizi in rete all'interno di una service mesh.
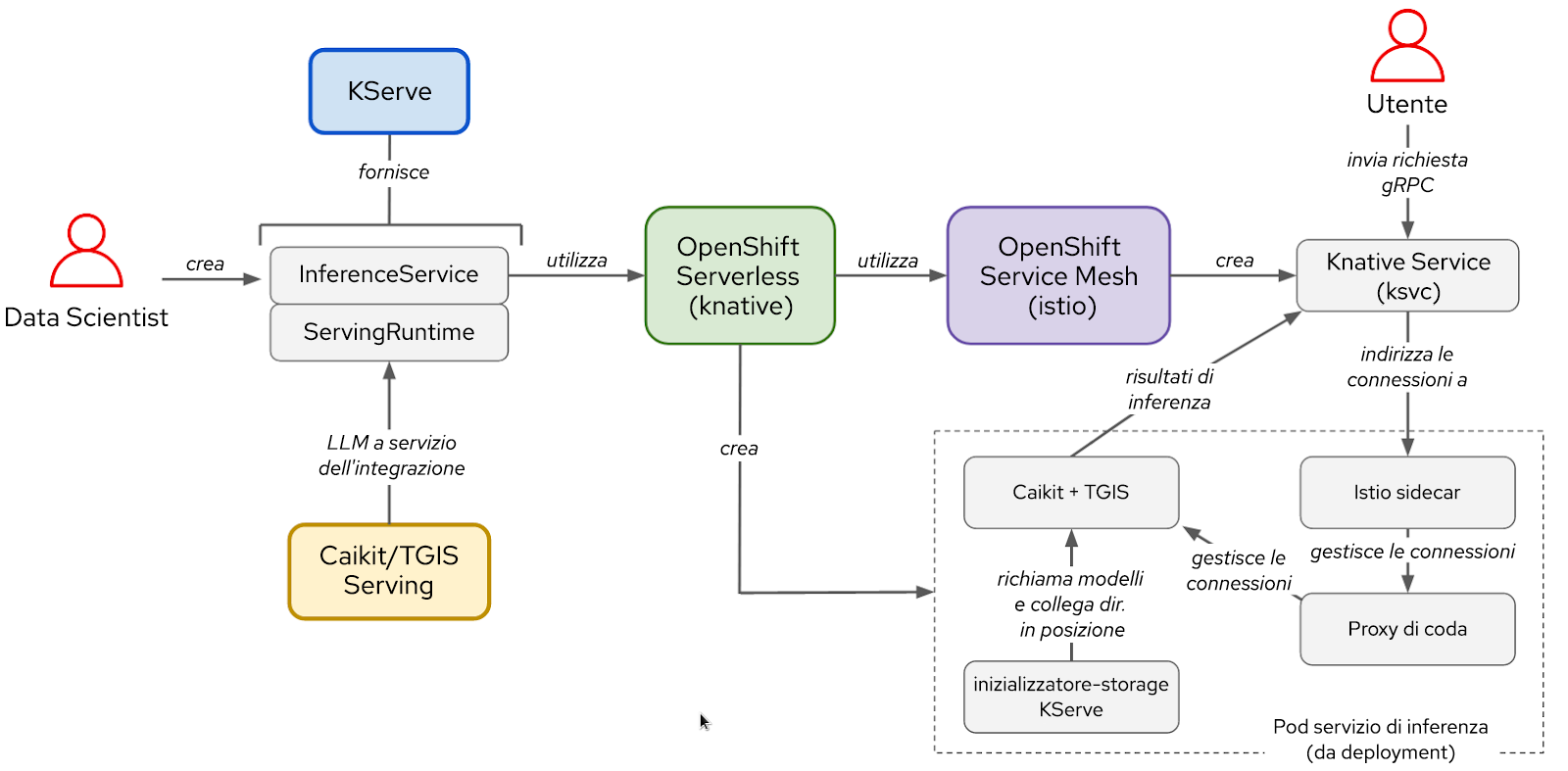
Figura 2. Interazioni tra i componenti e il flusso di lavoro dell'utente nello stack KServe/Caikit/TGIS.
Una volta completato il fine tuning del modello, è possibile eseguirne il deployment con il back-end e il runtime di distribuzione Caikit/TGIS, semplificando e snellendo le operazioni di scalabilità e manutenzione con KServe, che offre un'infrastruttura di distribuzione affidabile e avanzata. In background, Red Hat OpenShift Serverless (Knative) si occupa del deployment serverless del modello e Red Hat OpenShift Service Mesh (Istio) gestisce tutti i flussi di rete e di traffico (vedere Figura 2).
Configurazione dell'ambiente
Questa demo presuppone che sia stato installato o aggiunto come componente aggiuntivo un cluster OpenShift con l'operatore Red Hat OpenShift Data Science. La demo può essere eseguita anche utilizzando Open Data Hub come piattaforma alla base.
Per il fine tuning del modello, devi installare l'operatore della community CodeFlare disponibile in OperatorHub. L'operatore CodeFlare installa MCAD, InstaScale, l'operatore KubeRay e l'immagine del notebook CodeFlare con pacchetti come codeflare-sdk, pytorch e torchx inclusi. In caso di utilizzo di GPU, devono essere installati anche gli operatori NVIDIA GPU e Node Feature Discovery.
Per quanto riguarda la distribuzione del modello, basta eseguire questo script per installare tutti gli operatori indispensabili e l'intero stack KServer/Caikit/TGIS. Imposta TARGET_OPERATOR su rhods.
Al momento le istruzioni per l'installazione degli stack Distributed Workloads e KServe/Caikit/TGIS prevedono procedure pressoché manuali, ma entrambi saranno presto disponibili e supportati in Red Hat OpenShift AI.
Fine tuning di un modello LLM
Si parte con l'avvio del notebook CodeFlare dalla dashboard di Red Hat OpenShift Data Science (vedere Figura 3) e la clonazione del repository demo contenente il notebook e gli altri file necessari per la demo.
Figura 3. Immagine del notebook CodeFlare mostrata nella dashboard di OpenShift Data Science.
All'inizio devi definire i parametri per il tipo di cluster desiderato (ClusterConfiguration), con dettagli quali il nome del cluster, lo spazio dei nomi nel quale eseguire il deployment, le risorse di CPU, GPU e memoria necessarie, i tipi di macchine e se intendi usufruire della funzionalità di scalabilità automatica di InstaScale. Se lavori in un ambiente on-premise, puoi ignorare il parametro machine_types e impostare instascale=False. In seguito si crea l'oggetto cluster, che viene poi inviato a MCAD per attivare il cluster Ray.
Non appena il cluster Ray è pronto ed è possibile visualizzarne i dettagli con il comando cluster.details() nel notebook, puoi definire il processo di fine tuning, indicando un nome, lo script da eseguire, gli eventuali argomenti e l'elenco delle librerie richieste, e inviarlo al cluster Ray appena attivato. L'elenco degli argomenti specifica il modello GPT-2 da utilizzare e il set di dati WIkiText con cui eseguire il fine tuning del modello. CodeFlare SDK permette di monitorare comodamente lo stato, i log e altre informazioni tramite interfaccia a riga di comando o di visualizzarli in una dashboard Ray.
Una volta terminato il fine tuning del modello, l'output di job.status() diventa SUCCEEDED e i log presenti nella dashboard Ray indicano che il processo è stato completato (vedere Figura 4). Con un worker Ray eseguito su una GPU NVIDIA T4 con 2 CPU e 8 GB di memoria, il fine tuning del modello GPT2 ha richiesto circa 45 minuti.

Figura 4. I log presenti nella dashboard Ray indicano che il processo di fine tuning del modello è stato completato.
A questo punto devi creare una nuova directory nel notebook, salvarvi il modello e scaricarlo nell'ambiente locale per convertirlo e in seguito caricarlo in un bucket MinIO. Tieni presente che in questa demo stiamo utilizzando un bucket MinIO, ma puoi utilizzare un altro tipo di bucket S3, PVC o qualsiasi altro storage.
Distribuzione del modello LLM
Una volta completato il fine tuning del modello di base, è il momento di metterlo all'opera. Dallo stesso notebook in cui è stato eseguito il fine tuning del modello, devi creare un nuovo spazio dei nomi in cui:
- eseguire il deployment del runtime di distribuzione Caikit+TGIS;
- eseguire il deployment della connessione dati S3; e
- eseguire il deployment del servizio di inferenza con puntamento al modello situato in un bucket MinIO
Un runtime di distribuzione è una Custom Resource Definition progettata per creare un ambiente finalizzato al deployment e alla gestione dei modelli in produzione. Si occupa della creazione dei modelli per i pod che possono caricare e scaricare in modo dinamico modelli di vari formati on demand ed esporre un endpoint di servizio per le richieste di inferenza. Eseguirai il deployment del runtime di distribuzione che consente di usufruire della scalabilità verticale dei pod di runtime una volta rilevato un servizio di inferenza. Per l'inferenza viene utilizzata la porta 8085.
Un servizio di inferenza è un server che accetta i dati in ingresso, li passa al modello, esegue quest'ultimo e restituisce l'output dell'inferenza. Nell'InferenceService oggetto del deployment, devi specificare il runtime distribuito in precedenza, abilitare il percorso diretto per l'inferenza gRPC e far puntare il server al bucket MinIO in cui si trova il modello sottoposto a fine tuning.
Dopo aver verificato che il servizio di inferenza sia pronto, devi eseguire una chiamata di inferenza chiedendo al modello di completare una frase a scelta.
Terminata questa procedura, avrai completato il fine tuning di un modello linguistico di grandi dimensioni GPT-2 con lo stack Distributed Workloads e lo avrai distribuito con lo stack KServe/Caikit/TGIS in OpenShift AI.
Le prossime novità
Innanzitutto vorremmo ringraziare le community Open Data Hub e Ray per il loro supporto. Questo blog presenta soltanto qualcuno dei potenziali scenari di utilizzo di AI/ML con OpenShift AI. Per saperne di più sulle funzionalità dello stack CodeFlare, guarda il video dimostrativo che illustra in maggiore dettaglio le parti di questa demo riguardanti CodeFlare SDK, KubeRay e MCAD.
Continua a seguirci perché molto presto integreremo gli operatori CodeFlare e KubeRay in OpenShift Data Science e svilupperemo l'interfaccia utente per lo stack KServe/Caikit/TGIS, rilasciato di recente in OpenShift Data Science come funzionalità a disponibilità limitata.
Sull'autore
Selbi Nuryyeva is a software engineer at Red Hat in the OpenShift AI team focusing on the Open Data Hub and Red Hat OpenShift Data Science products. In her current role, she is responsible for enabling and integrating the model serving capabilities. She previously worked on the Distributed Workloads with CodeFlare, MCAD and InstaScale and integration of the partner AI/ML services ecosystem. Selbi is originally from Turkmenistan and prior to Red Hat she graduated with a Computational Chemistry PhD degree from UCLA, where she simulated chemistry in solar panels.
Altri risultati simili a questo
L'IA agentica richiede nuove tecnologie per l’infrastruttura: AMD e Red Hat rispondono a questa esigenza
Smetti di gestire il passato e inizia a costruire il futuro dell'IT
Technically Speaking | Defining sovereign AI with open source
Technically Speaking | Inside open source AI strategy
Ricerca per canale

Automazione
Novità sull'automazione IT di tecnologie, team e ambienti

Intelligenza artificiale
Aggiornamenti sulle piattaforme che consentono alle aziende di eseguire carichi di lavoro IA ovunque

Hybrid cloud open source
Scopri come affrontare il futuro in modo più agile grazie al cloud ibrido

Sicurezza
Le ultime novità sulle nostre soluzioni per ridurre i rischi nelle tecnologie e negli ambienti

Edge computing
Aggiornamenti sulle piattaforme che semplificano l'operatività edge

Infrastruttura
Le ultime novità sulla piattaforma Linux aziendale leader a livello mondiale

Applicazioni
Approfondimenti sulle nostre soluzioni alle sfide applicative più difficili
Virtualizzazione
Il futuro della virtualizzazione negli ambienti aziendali per i carichi di lavoro on premise o nel cloud