It is indispensable to ensure that a system/service built is able to withstand chaotic conditions as failures are inevitable. Chaos engineering helps in boosting confidence in a system's resilience by “breaking things on purpose.” While it may seem counterintuitive, it is crucial to deliberately inject failures into a complex system like OpenShift/Kubernetes and check whether the system recovers gracefully without any downtime and doesn’t suffer in terms of performance and scalability. Chaos engineering is a discipline to identify potential problems and enhance the system’s resilience.
Kraken to the Rescue
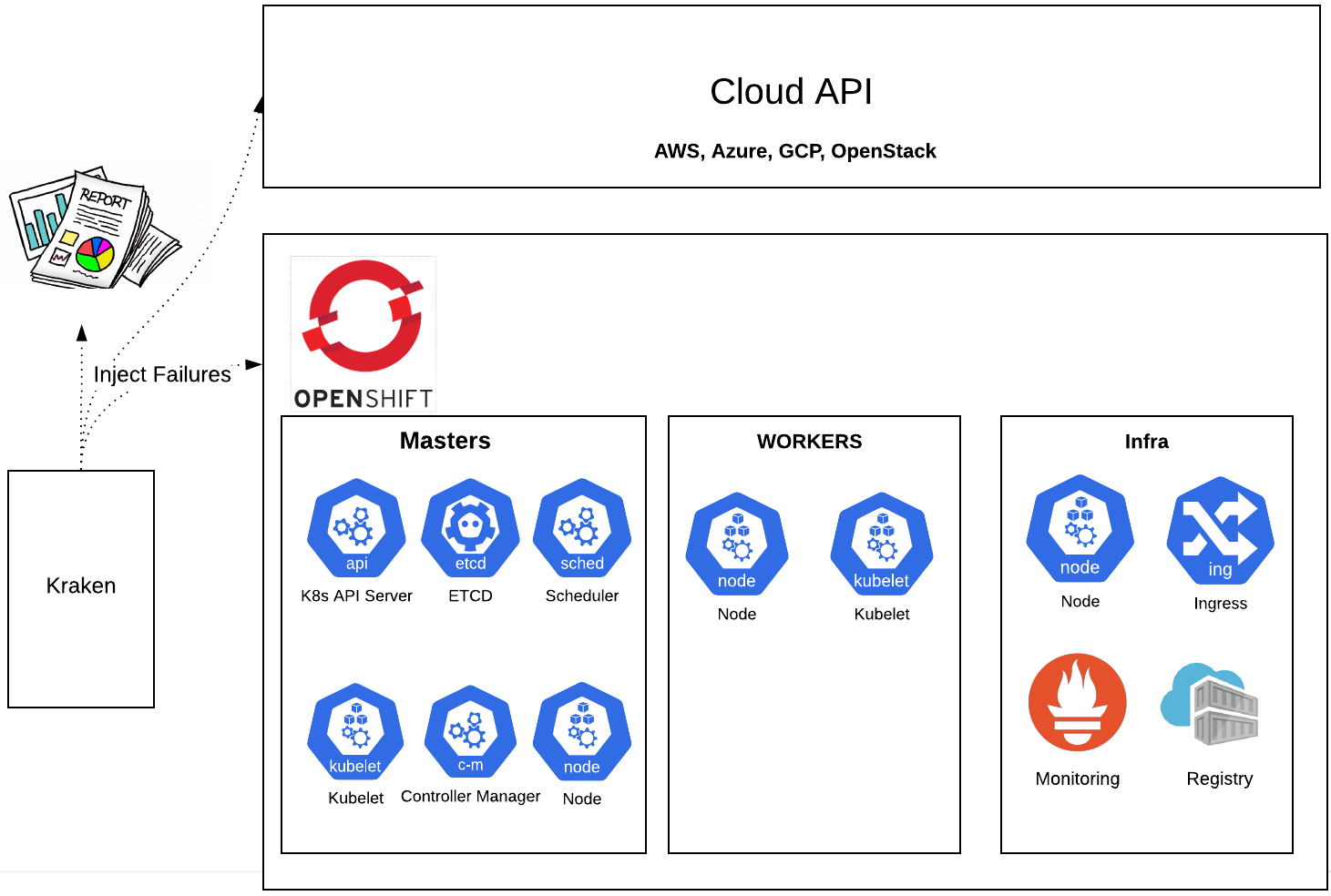
We developed a chaos tool named Kraken with the aim of “breaking things on purpose” and identifying future issues. Kraken enables the user to effortlessly inject chaos in a Kubernetes/OpenShift cluster. The user can continuously cause chaos and watch how the cluster responds to various failure injections over a long run. Additionally, one can validate if the cluster completely recovers from chaos and returns to its normal healthy state after a single set of failure injections.
PowerfulSeal
We at Red Hat believe in the Upstream approach where we leverage the available open source tools and contribute as much code as we can back to the open source communities because everyone gets better when we do that. Kraken utilizes Bloomberg’s PowerfulSeal, an open source tool for testing Kubernetes. The tool deliberately injects failures into Kubernetes clusters to detect problems as early as possible. We have opened many enhancement issues in PowerfulSeal to improve the coverage of the tool as well as been able to contribute to the tool’s code base directly. So far, we have added the ability to find pods in a namespace that match a given regex pattern.
Cerberus Integration
Chaos scenarios injected by Kraken can sometimes break other components unassociated with the targeted components. In the previous blog posts (OpenShift Scale-CI: Part 4: Introduction to Cerberus - Guardian of Kubernetes/OpenShift Clouds, Reinforcing Cerberus: Guardian of OpenShift/Kubernetes Clusters) we looked at a tool called Cerberus which monitors diverse cluster components and takes action when the cluster health starts degrading. The go/no-go signal from Cerberus can be used in Kraken to determine if the cluster recovered from failure injection as well as to decide whether to continue with the next chaos scenario.
Overview of Chaos Scenarios Supported by Kraken
Pod Chaos Scenarios
A pod is the basic execution unit of a Kubernetes application and is the smallest and simplest unit in the Kubernetes object model that can be created or deployed. It encapsulates an application's container, storage resources, and a unique network identity. A pod’s health state is not only about whether it is up and running, but also whether it is capable of receiving and responding to requests as well as the ability for the pod to recover from chaos injection. The user can kill pods in any namespace by tweaking one of the below configuration files or creating their own. Kraken currently has scenarios to kill pods in the following namespace with the expected results:
- Etcd: Verify chaos within the persistence of resources doesn’t disrupt the clusters ability to continue to keep up with records.
- Openshift-apiserver: Kill a pod replica and see if we are still able to access the OpenShift API without any downtime.
- Openshift-kube-apiserver: Disrupt the validity of the api objects which include pods, services, replicationcontrollers, etc and confirms the configuration is not affected.
- Prometheus: Wreak havoc on the alerting and monitoring components of OpenShift and see no disruption in alerts.
- Random OpenShift namespaces: Large-scale pod killing that has the ability to test the resiliency of all areas of OpenShift and user applications.
Node Chaos Scenarios
A Kubernetes/OpenShift cluster consists of a set of worker machines, called nodes, that run containerized applications. The worker node(s) host the pods and are managed by the main control plane of the cluster.
Kraken supports the following node chaos scenarios:
- Stop the node: chaos scenario to stop the node instance for specified duration. Kraken also gives the user the ability to start the node instance after it is stopped.
- Reboot the node: chaos scenario to reboot the node instance.
- Terminate the node: chaos scenario to terminate the node instance, thus ceasing its existence in a cluster.
- Crash the node: chaos scenario to cause kernel panic, thus crashing the node.
- Stop the node’s kubelet: kubelet is a primary node agent that makes sure that containers within a pod are running and are healthy. Kraken provides a scenario to stop the node’s kubelet. It also gives the user the ability to start the kubelet after it is stopped.
Currently Kraken supports chaos scenarios to stop, reboot and terminate any node instance for the AWS cloud type.
Cluster Shutdown Scenario
Kraken provides a chaos scenario to shutdown all the nodes including the control plane and restart them after a specified duration to see if the cluster recovers from the chaos injection, is stable, and is able to serve the requests.
How to Ensure if the Targeted Components Recovered
In addition to comprehensive cluster health checks provided by Cerberus, the user has the ability to scrutinize if the targeted components recovered from chaos injections as expected in a reasonable amount of time. The user can associate several custom checks with a chaos scenario to validate the resiliency of cluster components. The user can bring in custom checks in diverse forms such as a Python script or a Bash script, or one can leverage the validation checks provided by PowerfulSeal.
How to Get Started
Kraken as a Kubenetes Deployment
Kraken can be run internally to the cluster as a Kubernetes deployment. However, it is recommended to run Kraken externally to the cluster to ensure that chaos injection does not accidentally kill the pod Kraken is running on. For more detailed information and exact steps on how to get started, you can refer to this README.
Building Your Own Image
Instructions on building your image can be found in this README.
Demo
What’s Next?
The future scope of Kraken lies in tying chaos and performance together where a simple benchmark is run to capture the performance data before injecting a failure, check how long it takes for the system to recover gracefully, and then run the benchmark again to find out if the failure has any impact on the performance of a specific component or on the system as a whole.
We are always looking for new ideas and enhancements to this project. Feel free to create issues on github or open your own pull request for future improvements you would like to see.
Sugli autori

Altri risultati simili a questo
Smetti di gestire il passato e inizia a costruire il futuro dell'IT
Il prossimo punto di svolta dell'IA: trasformare gli agenti in superutenti aziendali
Scaling For Complexity With Container Adoption | Code Comments
Edge computing covered and diced | Technically Speaking
Ricerca per canale

Automazione
Novità sull'automazione IT di tecnologie, team e ambienti

Intelligenza artificiale
Aggiornamenti sulle piattaforme che consentono alle aziende di eseguire carichi di lavoro IA ovunque

Hybrid cloud open source
Scopri come affrontare il futuro in modo più agile grazie al cloud ibrido

Sicurezza
Le ultime novità sulle nostre soluzioni per ridurre i rischi nelle tecnologie e negli ambienti

Edge computing
Aggiornamenti sulle piattaforme che semplificano l'operatività edge

Infrastruttura
Le ultime novità sulla piattaforma Linux aziendale leader a livello mondiale

Applicazioni
Approfondimenti sulle nostre soluzioni alle sfide applicative più difficili
Virtualizzazione
Il futuro della virtualizzazione negli ambienti aziendali per i carichi di lavoro on premise o nel cloud