
Kubeflow è una piattaforma che riunisce una gamma di strumenti adatti ai principali scenari di utilizzo di AI/ML, come l'esplorazione e le pipeline di dati, ma anche l'addestramento e il supporto dei modelli. Grazie alla piattaforma, i data scientist possono accedere a queste funzionalità tramite un portale che offre astrazioni di livello elevato per interagire con gli strumenti forniti. In questo modo, i data scientist non devono necessariamente conoscere in dettaglio come funziona l'interazione tra Kubernetes e tali strumenti. Kubeflow, tuttavia, è progettato appositamente per essere eseguito su Kubernetes e ne incorpora molti dei concetti chiave, incluso il modello dell'operatore. In effetti, a eccezione del suddetto portale, Kubeflow è in realtà una raccolta di operatori.
In questo articolo esamineremo una serie di configurazioni che abbiamo adottato in una recente interazione con un cliente per far funzionare correttamente Kubeflow (versione 1.3 o successive) in un ambiente OpenShift.
Considerazioni sulla multitenancy di Kubeflow
Uno degli scenari di utilizzo affrontati da Kubeflow è la capacità di supportare un vasto numero di data scientist. A tal fine, Kubeflow adotta un approccio alla multitenancy (disponibile a partire dalla versione 1.3) in cui ogni data scientist riceve uno spazio dei nomi Kubernetes all'interno del quale operare (esistono anche meccanismi per condividere gli artefatti negli spazi dei nomi, che per ora non sono stati approfonditi).
È importante comprendere questo approccio, perché il supporto di questa funzionalità su OpenShift ha influito su gran parte del lavoro per rendere operativo Kubeflow. Uno spazio dei nomi per utente rispetto a uno per applicazione (che è il modello più comune nel deployment di OpenShift) potrebbe richiedere una rielaborazione del deployment di OpenShift, a seconda di come è organizzata l'autenticazione/autorizzazione.
Affinché la multitenancy di Kubeflow funzioni correttamente, è necessario che l'utente sia autenticato e che venga aggiunta un'intestazione attendibile a tutte le richieste (quella predefinita è kubeflow-userid, ma si può configurare). A questo punto entrerà in campo Kubeflow, creando lo spazio dei nomi per l'utente nel caso in cui non esista già.
L'altro aspetto della multitenancy di Kubeflow è il concetto di Profile (profilo), ovvero una Custom Resource (CR, risorsa personalizzata) che rappresenta l'ambiente di un utente e che viene associata a uno spazio dei nomi gestito da Kubeflow. L'intestazione kubeflow-userid deve corrispondere a un profilo esistente affinché Kubeflow possa instradare correttamente le richieste.
Dopo che un profilo è stato costituito e associato a un utente, Kubeflow crea lo spazio dei nomi corrispondente, in cui verranno eseguite tutte le attività successive per quell'utente.
Kubeflow è anche strettamente integrato con Istio. Sebbene non sia strettamente necessario eseguire Istio con Kubeflow, è consigliabile farlo, perché la sicurezza di quest'ultimo si basa su costrutti Istio. Quando l'esecuzione avviene su Istio, uno degli approcci più semplici per supportare la multitenancy consiste nel creare spazi dei nomi per i profili Kubeflow appartenenti alla service mesh e un singolo gateway di ingresso attraverso il quale scorre tutto il traffico.
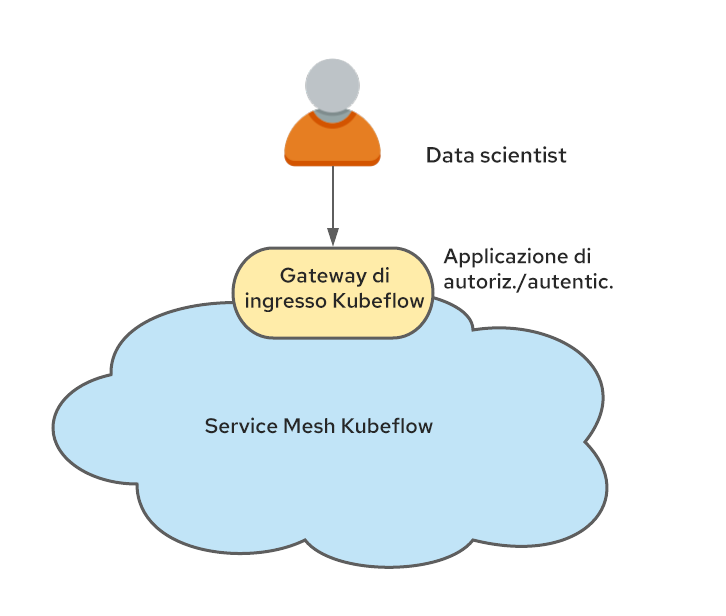
Questo punto di passaggio diventa la scelta più naturale per eseguire l'autenticazione dell'utente e impostare l'intestazione kubeflow-userid menzionata in precedenza.
Integrazione con Service Mesh
OpenShift Service Mesh è diverso da Istio in quanto un cluster OpenShift può contenere più service mesh, mentre per Istio upstream è sottinteso che la mesh si espanda all'intero cluster Kubernetes.
Nella nostra configurazione abbiamo deciso di dedicare completamente una Service Mesh agli scenari di utilizzo di AI/ML, pertanto sono inclusi solo gli spazi dei nomi AI/ML di Kubeflow.
Inoltre, per poter aggiungere e rimuovere i data scientist in qualsiasi momento, abbiamo deciso di adottare il modello consigliato con un solo profilo/spazio dei nomi per utente.
In sintesi, dovevamo trovare soluzioni per rispettare i seguenti requisiti:
- Garantire che le connessioni dei data scientist siano autenticate e che l'intestazione kubeflow-userid venga aggiunta alla richiesta in modo da evitare manomissioni.
- Fare in modo che vengano creati profili Kubeflow per ogni data scientist.
- Assicurarsi che gli spazi dei nomi creati da Kubeflow come risultato della creazione di un profilo appartengano alla service mesh AI/ML.
Garanzia dell'autenticazione per i data scientist
Come spiegato in precedenza, Kubeflow utilizza un'intestazione per rappresentare l'utente connesso. Sebbene siano disponibili opzioni per modificare il nome dell'intestazione predefinita kubeflow-userid, ciò comporta modifiche in diverse posizioni. Di conseguenza, abbiamo deciso che sarebbe stato più semplice continuare a utilizzare il nome dell'intestazione predefinito.
L'inserimento di questa intestazione può essere eseguito in diversi modi; di seguito viene descritto uno di questi approcci:
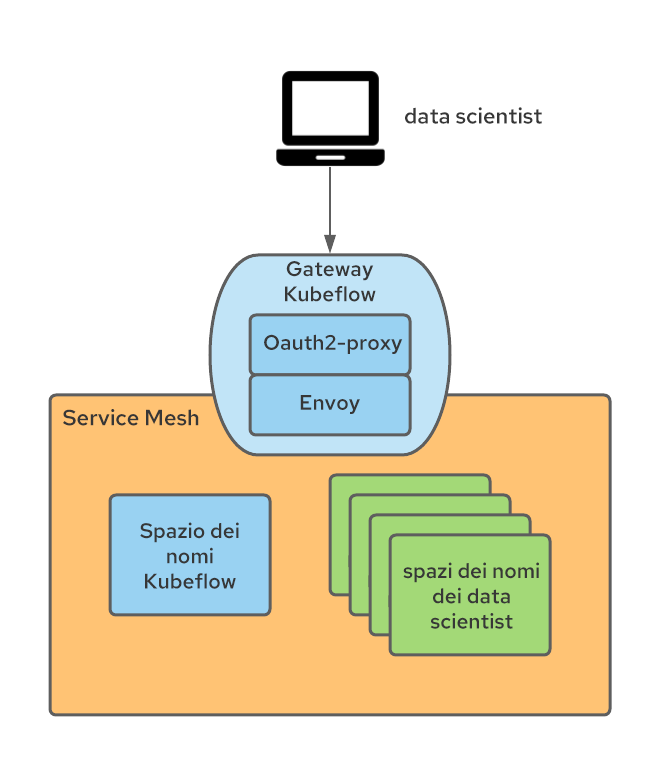
Sfruttando il fatto che Kubeflow pubblica i suoi servizi esterni su un gateway di ingresso Istio (denominato Kubeflow per impostazione predefinita), il gateway è stato progettato per applicare l'autenticazione tramite un proxy oauth che reindirizza gli utenti non autenticati al flusso di accesso di OpenShift. Questo approccio con proxy oauth è utilizzato da molti altri componenti OpenShift e prevede che solo gli utenti autenticati OpenShift con le autorizzazioni necessarie possano effettuare richieste. Puoi trovare ulteriori informazioni su come integrare il proxy oauth in questo articolo.
Il sidecar proxy oauth nel gateway di ingresso crea un'intestazione denominata x-forwarded-user con l'ID dell'utente autenticato (secondo le best practice http), quindi è sufficiente aggiungere una regola di trasformazione (implementata come CR EnvoyFilter) sul gateway di ingresso per copiare il valore in una nuova intestazione denominata kubeflow-userid. Inoltre, il sidecar proxy oauth è configurato in modo che possano accedere solo gli utenti con autorizzazione GET sui pod negli spazi dei nomi Kubeflow (qui è possibile configurare qualsiasi set di autorizzazioni per distinguere tra utenti Kubeflow e non Kubeflow).
Questo approccio offre i seguenti vantaggi:
- Tutti gli utenti Kubeflow sono anche utenti OpenShift (si noti che il contrario non è necessariamente vero). Possiamo sfruttare quanto configurato all'interno di OCP in termini di integrazione con il sistema di autenticazione aziendale, migliorando notevolmente la portabilità dell'approccio.
- Poiché esiste un solo metodo di ingresso nella mesh Kubeflow (tramite la protezione del gateway di ingresso Kubeflow), garantiamo che solo gli utenti autenticati possano sfruttare i servizi Kubeflow.
Garanzia della creazione di profili Kubeflow
È necessario un oggetto Profile (CR) per registrare e gestire correttamente un utente in Kubeflow. La creazione dell'oggetto Profile è denominata "registration" (registrazione). È possibile consentire ai nuovi utenti di registrarsi autonomamente, ma abbiamo optato per un processo di registrazione automatico: quando un utente accede per la prima volta, creiamo automaticamente il profilo corrispondente.
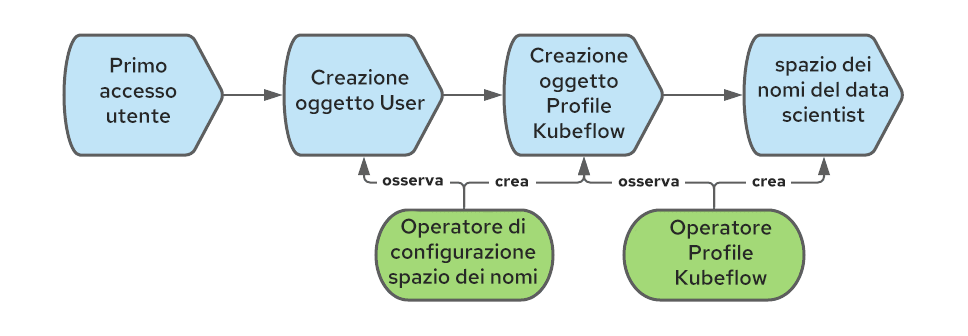
In OpenShift, viene creato un oggetto User al primo accesso di un utente. Si può sfruttare quell'evento per creare anche l'oggetto Profile.
Per automatizzare la creazione dell'oggetto Profile, possiamo utilizzare l'operatore di configurazione dello spazio dei nomi. Il diagramma seguente illustra la sequenza di eventi che creano l'oggetto Profile quando un utente accede per la prima volta a OpenShift:
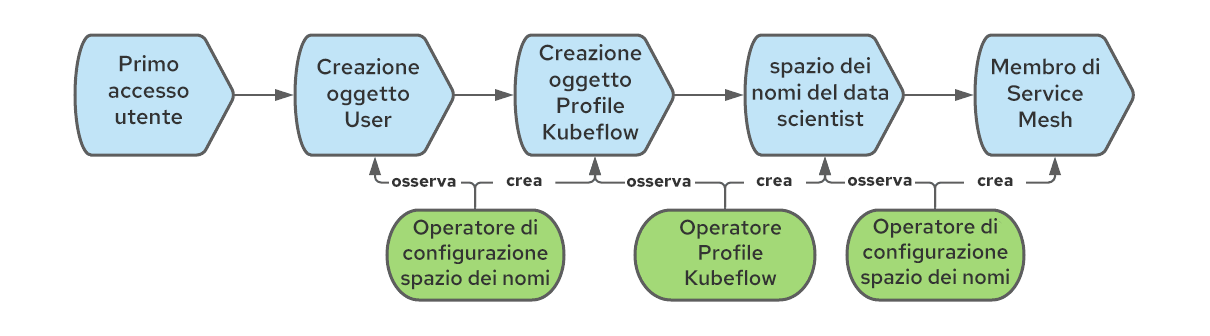
Aggiunta degli spazi dei nomi Kubeflow alla service mesh AI/ML
Quando creiamo un oggetto Profile, Kubeflow crea anche lo spazio dei nomi Kubernetes corrispondente e aggiunge diverse risorse al nuovo spazio dei nomi, come le quote, le regole Istio RBAC e gli account di servizio. Kubeflow presuppone che gli spazi dei nomi appartengano alla mesh, ma questo non è il caso di OpenShift Service Mesh, in cui ogni spazio dei nomi deve essere unito in modo esplicito a una determinata mesh (può essercene più di una). Per risolvere questo problema, possiamo utilizzare ancora una volta l'operatore di configurazione dello spazio dei nomi, creando una regola che si attiva alla creazione degli spazi dei nomi e li fa aderire alla mesh. Il flusso di lavoro completo è così costituito:
Dopo aver impostato correttamente il flusso di lavoro, quando un data scientist esegue l'accesso la schermata dovrebbe apparire come in questa immagine:
Il nome all'interno del cerchio rosso è la conferma che l'utente è stato riconosciuto da Kubeflow.
Abilitazione dei nodi GPU e della scalabilità automatica dei nodi
A questo punto, i data scientist possono accedere alla dashboard principale di Kubeflow e iniziare a utilizzare la funzionalità fornita. Naturalmente, una delle funzioni necessarie per supportare molti degli scenari di utilizzo di AI/ML è la possibilità di accedere alle GPU.
L'abilitazione dei nodi GPU è semplice, purché vengano soddisfatti i prerequisiti necessari. Questo articolo descrive il processo nei dettagli.
I nodi GPU, tuttavia, sono risorse costose, quindi è necessario rispettare due requisiti per ridurre al minimo le spese:
- Sui nodi GPU devono essere consentiti solo carichi di lavoro relativi ad AI/ML.
- I nodi GPU devono potersi adattare automaticamente in base alla maggiore o minore necessità di risorse.
Separazione dei carichi di lavoro AI/ML da quelli normali
Per separare i carichi di lavoro AI/ML dagli altri che potrebbero essere presenti nel cluster e che non richiedono nodi GPU, possiamo utilizzare contaminazioni e tolleranze. Basta creare i nodi GPU con una contaminazione che impedisca ai carichi di lavoro di arrivare su quei nodi per impostazione predefinita.
Per garantire che i tenant che non sono AI/ML non possano contrassegnare i carichi di lavoro per indicare che tollerano la contaminazione, possiamo utilizzare questa annotazione dello spazio dei nomi:
scheduler.alpha.kubernetes.io/tolerationsWhitelist: '[]'
Per semplificare il lavoro del data scientist e aggiungere automaticamente la tolleranza ai carichi di lavoro in esecuzione negli spazi dei nomi AI/ML, è possibile applicare la seguente annotazione a tutti gli spazi dei nomi Kubeflow:
scheduler.alpha.kubernetes.io/defaultTolerations: '[{"operator": "Equal", "effect": "NoSchedule", "key": "workload", "value": "ai-ml"}]'In questo esempio, i nodi abilitati alla GPU sono stati etichettati con "workload: ai-ml".
Si noti che si tratta di annotazioni alpha che al momento non sono supportate da Red Hat, ma, in base ai nostri test, funzionano correttamente.
Come accennato in precedenza, Kubeflow creerà gli spazi dei nomi dei data scientist al momento del loro primo accesso. Poiché non abbiamo il controllo sulla modalità di creazione degli spazi dei nomi, è necessario implementare un processo per poter applicare le annotazioni corrette. Questa operazione può essere eseguita utilizzando una configurazione del webhook per le mutazioni. Questo webbook può intercettare la creazione dello spazio dei nomi e aggiungere le annotazioni necessarie. Abbiamo utilizzato Open Policy Agent (OPA) e il progetto Gatekeeper, che integra OPA con Kubernetes, distribuendolo tramite l'operatore Gatekeeper.

Abilitazione della scalabilità automatica dei nodi
Per ridurre al minimo il numero dei costosi nodi GPU, è necessario abilitare la scalabilità automatica sui nodi AI/ML.
La scalabilità automatica dei nodi è una funzionalità pronta all'uso di OpenShift e può essere abilitata seguendo i passaggi della documentazione ufficiale.
Utilizzando questa funzionalità, è emersa la necessità di migliorare le seguenti situazioni:
Innanzitutto, con questa funzionalità i nodi vengono aggiunti solo quando i pod sono bloccati allo stato "pending" (in sospeso). Questo comportamento reattivo si traduce in un'esperienza dell'utente negativa, dato che per avviare i carichi di lavoro bisogna attendere la creazione dei nodi (circa 5 minuti su AWS) e la disponibilità dei driver GPU (circa 3-4 minuti in più). Per migliorare questa situazione, abbiamo utilizzato l'operatore proactive-node-scaling-operator (come spiegato in questo articolo).
In secondo luogo, quando si utilizzano i nodi GPU, la scalabilità automatica tende a creare più nodi del necessario. Ciò è dovuto al fatto che i nodi appena creati non possono pianificare immediatamente i pod in sospeso, siccome questi nodi inizialmente non sono abilitati per la GPU (mentre l'operatore GPU esegue i passaggi di inizializzazione, come la compilazione e l'inserimento dei driver del kernel della GPU). Per risolvere questo problema, è necessario aggiungere un'etichetta specifica (cluster-api/accelerator: "true") al modello del nodo, come illustrato qui. Questa etichetta informa che un certo nodo deve avere determinate funzionalità (come il supporto per le GPU) abilitate, anche quando non sono attualmente presenti.
Abilitazione dell'accesso al data lake
Per quasi tutte le attività che un data scientist deve svolgere, che si tratti di esplorare i dati per comprenderne la struttura e le possibili correlazioni interne, addestrare i modelli di reti neurali tramite set di dati di esempio o recuperare un modello per poter fornire supporto, l'accesso ai dati è fondamentale. In AI/ML, il repository di dati, che contiene dati di tutti i tipi (relazionali, valori chiave, documenti, albero e altro), viene definito data lake.
Proteggere l'accesso al data lake può essere complicato, soprattutto in un ambiente multitenant. Inoltre, vogliamo semplificare il lavoro dei data scientist riducendo al minimo il numero di concetti di Kubernetes e di gestione delle credenziali che devono imparare.
Nel nostro caso, il data lake era costituito da un set di bucket AWS S3, ma tipi di repository di storage alternativi possono sfruttare molti degli stessi concetti.
Il team di sicurezza ha anche richiesto che le credenziali necessarie per accedere al data lake rappresentino un carico di lavoro, non una persona specifica. Inoltre, la credenziale dovrebbe essere di breve durata. L'obiettivo era evitare di distribuire ai data scientist credenziali statiche che potrebbero essere perse o utilizzate in modo improprio.
Per risolvere questo problema, abbiamo utilizzato token dell'account di servizio associati e l'integrazione OpenShift - STS, adattandola ai carichi di lavoro degli utenti. Vediamo come si possono combinare queste due tecnologie.
Con i token dell'account di servizio associati, si può fare in modo che OpenShift generi un token JWT che rappresenta il carico di lavoro e che viene montato come un volume previsto, in modo simile al funzionamento dei token dell'account di servizio per qualsiasi altro carico di lavoro. Questo tipo di token è di breve durata (il Kubelet è responsabile dell'aggiornamento) e può essere personalizzato definendone la proprietà audience (destinatari).
STS è un servizio AWS (ma ne esistono di simili per altri provider cloud) che consente di stabilire l'attendibilità da AWS ad altri sistemi di autenticazione, inclusi i provider di autenticazione OIDC. Configurando STS, possiamo indicare ad AWS di considerare attendibili i token JWT coniati da OpenShift e scambiarli con token AWS con un set specifico di autorizzazioni. Dopo lo scambio, l'applicazione in esecuzione in un pod può iniziare a consumare risorse AWS. Il diagramma seguente illustra questa architettura:
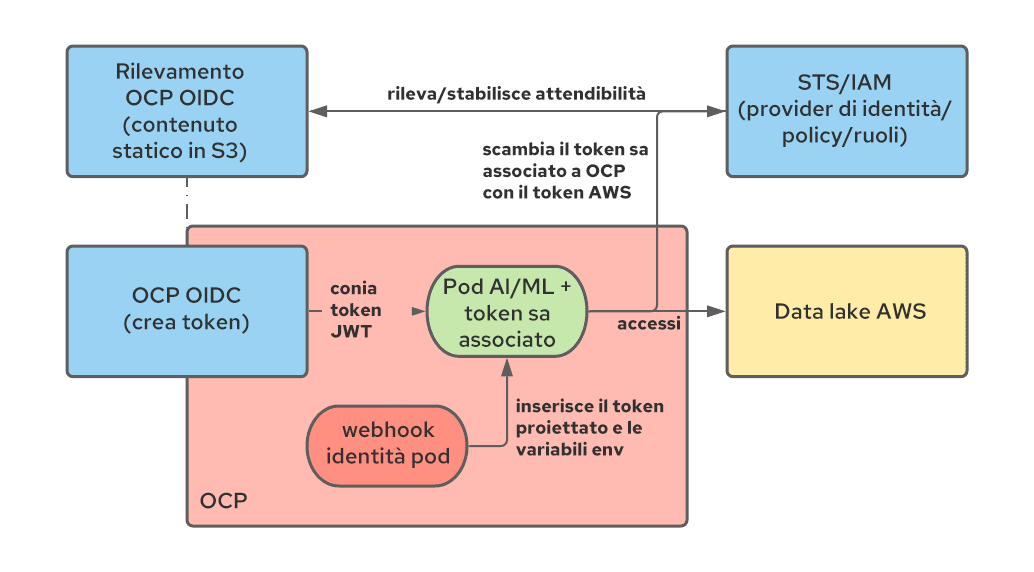
I documenti ufficiali e questo articolo possono aiutarti a configurare l'integrazione STS.
Uno dei requisiti di questo approccio è che gli account di servizio utilizzati per eseguire i pod AI/ML abbiano annotazioni specifiche allegate che indicano che questi carichi di lavoro richiedono il token dell'account di servizio associato aggiuntivo. Possiamo farlo utilizzando l'OPA e inserendo le annotazioni necessarie sugli account di servizio negli spazi dei nomi dei data scientist.
Il risultato della configurazione descritta in precedenza consente ai data scientist e, in generale, ai carichi di lavoro di AI/ML, di accedere al data lake con credenziali che rappresentano il carico di lavoro (e non un individuo in particolare) e di breve durata, per cui non devono essere mantenute ovunque. Inoltre, tutto ciò avviene in modo trasparente per i data scientist, che devono semplicemente utilizzare qualsiasi client AWS standard (che conosce il metodo di autenticazione STS) per accedere al data lake.
Integrazione con serverless
Quando si tratta di supportare un modello, il metodo predefinito in Kubeflow è Kfserving (si possono utilizzare anche altri approcci, descritti qui).
Kfserving si basa su Knative, che in OpenShift è una funzionalità che può essere abilitata installando OpenShift Serverless.
È necessario prestare attenzione quando si utilizzano Service Mesh e Serverless, poiché occorre soddisfare alcuni prerequisiti per integrarli correttamente.
In particolare, è necessario creare una regola NetworkPolicy in ogni spazio dei nomi della service mesh per consentire il traffico dagli spazi dei nomi serverless a quelli mesh.
Inoltre, poiché tutti i servizi mesh in un ecosistema Kubeflow multitenant sono protetti da AuthorizationPolicies di Istio e i componenti serverless sono esterni alla mesh, è necessario modificare i criteri RBAC per consentire le connessioni dai pod degli spazi dei nomi serverless (in particolare Kourier e Activator):
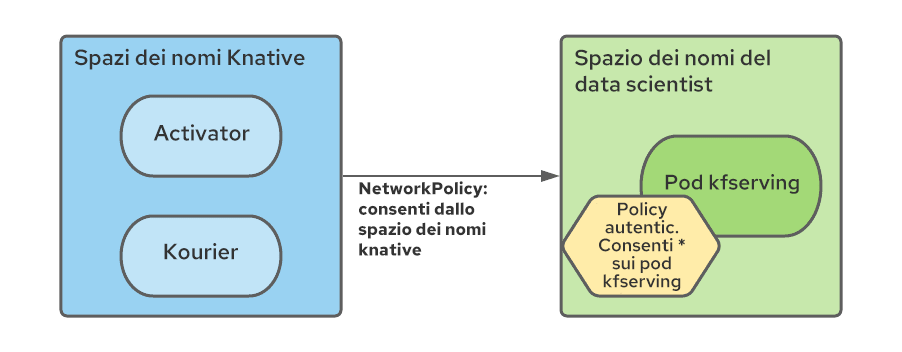
Abbiamo automatizzato la creazione di queste regole con l'operatore di configurazione dello spazio dei nomi, chiedendogli di aggiungere le risorse NetworkPolicy e AuthorizationPolicy al momento della creazione dello spazio dei nomi del data scientist.
Installazione
Le istruzioni dettagliate per l'installazione di ciascuno degli argomenti descritti in precedenza e le relative configurazioni sono disponibili in questo repository. Questa procedura dettagliata contiene anche altri miglioramenti minori e alcuni esempi di carichi di lavoro AI/ML per convalidare la configurazione.
Conclusioni
In questo articolo abbiamo illustrato alcune considerazioni necessarie per configurare un deployment multitenant di Kubeflow su OpenShift. Questo è solo il primo passo di un percorso di AI/ML, ma dovrebbe essere sufficiente per iniziare. Da qui, il team di data scientist può iniziare a esplorare i dati con i notebook Jupyter e a creare pipeline di dati, che possono includere l'addestramento di modelli di reti neurali. Quando i modelli di reti neurali sono pronti, Kubeflow può aiutare con lo scenario di utilizzo di supporto del modello.
È importante ricordare che l'esecuzione di Kubeflow su OpenShift non è attualmente supportata da Red Hat. Inoltre, Kubeflow è un prodotto ricco di funzionalità e, nell'ambito di questo deployment iniziale, non abbiamo verificato il corretto funzionamento di ciascuna di esse (l'elenco delle funzionalità testate è consultabile nel repository). Ad esempio, una caratteristica importante che purtroppo non è attualmente operativa, anche se potrebbe essere integrata in un secondo momento, è l'intero stack di osservabilità fornito da Kubeflow.
Ci auguriamo che questo tipo di lavoro possa essere utilizzato per dare una spinta iniziale alle organizzazioni che desiderano eseguire Kubeflow su OpenShift. Inoltre, questi concetti dovrebbero fornire molti dei concetti di base comuni che possono essere utilizzati quando si rendono operative altre piattaforme di AI/ML.
Sull'autore
Raffaele is a full-stack enterprise architect with 20+ years of experience. Raffaele started his career in Italy as a Java Architect then gradually moved to Integration Architect and then Enterprise Architect. Later he moved to the United States to eventually become an OpenShift Architect for Red Hat consulting services, acquiring, in the process, knowledge of the infrastructure side of IT.
Currently Raffaele covers a consulting position of cross-portfolio application architect with a focus on OpenShift. Most of his career Raffaele worked with large financial institutions allowing him to acquire an understanding of enterprise processes and security and compliance requirements of large enterprise customers.
Raffaele has become part of the CNCF TAG Storage and contributed to the Cloud Native Disaster Recovery whitepaper.
Recently Raffaele has been focusing on how to improve the developer experience by implementing internal development platforms (IDP).
Altri risultati simili a questo
L'IA agentica richiede nuove tecnologie per l’infrastruttura: AMD e Red Hat rispondono a questa esigenza
Smetti di gestire il passato e inizia a costruire il futuro dell'IT
Technically Speaking | Inside open source AI strategy
Technically Speaking | Build a production-ready AI toolbox
Ricerca per canale

Automazione
Novità sull'automazione IT di tecnologie, team e ambienti

Intelligenza artificiale
Aggiornamenti sulle piattaforme che consentono alle aziende di eseguire carichi di lavoro IA ovunque

Hybrid cloud open source
Scopri come affrontare il futuro in modo più agile grazie al cloud ibrido

Sicurezza
Le ultime novità sulle nostre soluzioni per ridurre i rischi nelle tecnologie e negli ambienti

Edge computing
Aggiornamenti sulle piattaforme che semplificano l'operatività edge

Infrastruttura
Le ultime novità sulla piattaforma Linux aziendale leader a livello mondiale

Applicazioni
Approfondimenti sulle nostre soluzioni alle sfide applicative più difficili
Virtualizzazione
Il futuro della virtualizzazione negli ambienti aziendali per i carichi di lavoro on premise o nel cloud