Lo scorso ottobre abbiamo annunciato l'anteprima per gli sviluppatori del monitoraggio dell'alimentazione per Red Hat OpenShift, che presentava Kepler, un componente integrato dell'iniziativa della community upstream per l' elaborazione sostenibile. L'iniziativa ha permesso ai primi utenti che l'hanno adottata di sperimentare questa promettente tecnologia. Sin dall'annuncio, il nostro team ha lavorato per creare pipeline e strumenti capaci di rispettare gli standard di sicurezza e test dei prodotti Red Hat.
Con grande entusiasmo, oggi condividiamo un nuovo traguardo nel nostro percorso: la versione in anteprima tecnologica del monitoraggio dell'alimentazione in Red Hat OpenShift. Un sincero ringraziamento va ai primi che hanno adottato la tecnologia e ai sostenitori tecnologie rivoluzionarie che hanno partecipato attivamente al deployment di questa innovazione, condividendo feedback di grande valore.
Per coloro che non hanno avuto la possibilità di provarla, questa innovazione consiste in un set di strumenti con i quali monitorare il consumo energetico dei carichi di lavoro in esecuzione in un cluster OpenShift. Le informazioni acquisite possono essere utilizzate in vari modi, ad esempio per individuare gli spazi dei nomi che consumano più energia o per formulare piani strategici per la riduzione dei consumi.
Se ti interessa sperimentare questa versione di anteprima, di seguito troverai informazioni dettagliate su come iniziare. Leggi la dichiarazione dell'anteprima tecnologica per ulteriori informazioni sul supporto ufficiale.
Installazione del monitoraggio dell'alimentazione per Red Hat OpenShift
Poiché miriamo a fornire un'esperienza unificata, questi passaggi dell'installazione sono molto simili a quelli della versione precedente del monitoraggio dell'alimentazione, che si basava sull'operatore sviluppato dalla community.
- Abilita il monitoraggio dei carichi di lavoro degli utenti seguendo le istruzioni contenute nella documentazione di Red Hat OpenShift.
- Per evitare conflitti, innanzitutto disinstalla qualsiasi precedente versione dell'operatore kepler installata tramite il catalogo degli operatori della community.
- Installa l'operatore dalla console di OpenShift 4.14 (o versioni successive) accedendo a Operators -> OperatorHub. Utilizza quindi la casella di ricerca per individuare il monitoraggio dell'alimentazione per Red Hat OpenShift, fai clic su di esso e seleziona la casella "Install".
- Una volta installato l'operatore, crea un'istanza della CRD di Kepler facendo clic su "View Operator" e successivamente su "Creare instance" nell'API di Kepler.
Ecco fatto. Una volta installato Kepler, nella scheda dell'Interfaccia utente Observe>Dashboards della console di OpenShift Console saranno visibili due nuovi dashboard:
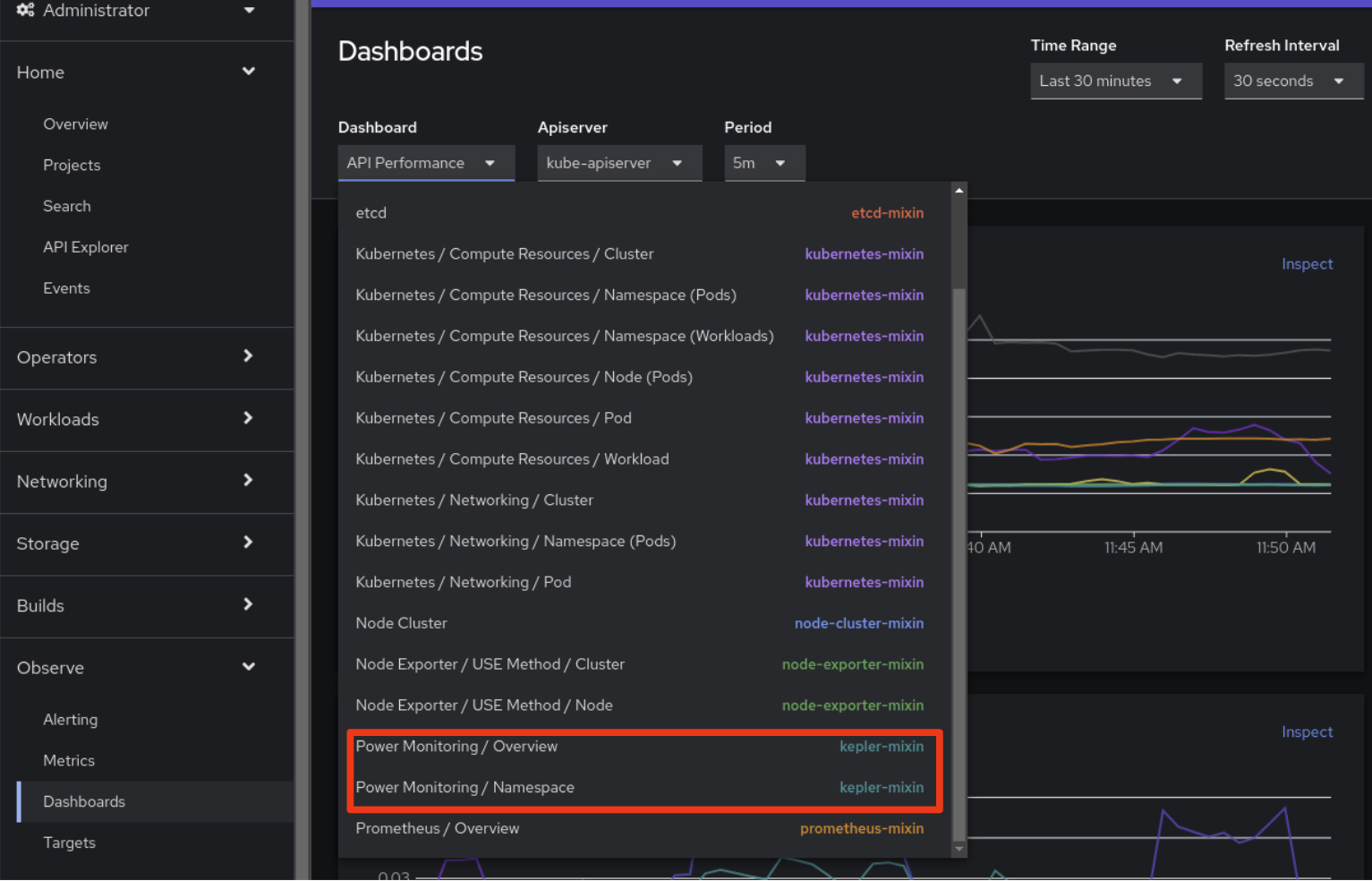
Per ulteriori informazioni sul monitoraggio dell'alimentazione, raccomandiamo la lettura della documentazione ufficiale sul monitoraggio dell'alimentazione nella documentazione di OpenShift.
Vantaggi del monitoraggio
Questi dashboard permettono di ottenere informazioni dettagliate sul cluster e sui relativi carichi di lavoro. Potrai infatti:
- Monitorare l'energia totale consumata nel cluster nelle ultime 24 ore, con l'indicazione dell'architettura della CPU selezionata e del numero di nodi monitorati.
- Visualizzare gli spazi dei nomi più energivori.
- Individuare quali container e pod consumano la maggior quantità di energia. È possibile ottenere questi dati analizzando le metriche presentate da Kepler nella scheda "Observe -> Metrics".
- Suggerimento: puoi eseguire query relative a tutte le metriche disponibili per il monitoraggio dell'alimentazione utilizzando l'espressione regolare seguente: { __name__ =~ "kepler.+"}
Come accennato prima, queste metriche sono disponibili grazie all'integrazione di Kepler in OpenShift. L'insieme delle metriche ottenute da Kepler dipende dall'hardware e dalla configurazione del cluster alla base. Al momento, Kepler fornisce misurazioni accurate relative a uno specifico set di configurazioni cloud, in particolare quelle basate su hardware Intel capace di esporre le configurazioni Running Average Power Limit (RAPL) e Advanced Configuration and Power Interface (ACPI) nei deployment bare metal.
Per le altre configurazioni, viene fornito un modello di machine learning iniziale; Red Hat collabora con l'intera community per migliorare ulteriormente la precisione dei calcolatori basati sul machine learning. Attualmente, le stime sono tendenzialmente coerenti, e possono quindi essere considerate attendibili quando mostrano le variazioni tra le esecuzioni dello stesso carico di lavoro. Tuttavia, è importante notare che si tratta di approssimazioni del consumo energetico effettivo.
Per capire più facilmente se i valori forniti da Kepler si basano sulle metriche o sui modelli, abbiamo aggiunto la colonna "Components Source" nel riquadro Node - CPU Architecture della pagina Overview.
Questa miglioria offre maggiore trasparenza e permette agli utenti di capire la provenienza delle metriche, ad esempio rapl-sysfs o rapl-msr. Nel caso in cui Kepler non sia in grado di acquisire le metriche sul consumo energetico dell'hardware, la sorgente visualizzata sarà "estimator". In questi casi, Kepler ricorre al modello di machine learning e ai calcolatori risultanti sopra citati. Al momento, le attività di sviluppo si incentrano sul perfezionamento di questi modelli, per migliorare sia la precisione che l'ambito degli ambienti a cui sono applicabili.

Un approfondimento sulle metriche
Per capire meglio, osserviamo un esempio. Dopo aver installato Kepler seguendo la documentazione ufficiale, abbiamo installato un generatore di traffico HTTP/2 e un mock, per far lavorare un po' il sistema.
Possiamo ora esaminare l'impatto del consumo energetico sul nostro cluster OpenShift. Nella console di OpenShift, nel dashboard Observe -> Dashboards -> Power Monitoring Overview, osserviamo che:
- I nodi mostrati nel riquadro Architecture riportano risultati basati su metriche, come mostra rapl-sysfs nella colonna Components Source.
- Il cluster è stato attivo per qualche tempo, poi è diventato inattivo, quindi non ha consumato molti kWh.
- Viene visualizzato anche un elenco degli spazi dei nomi che incidono maggiormente sui consumi energetici.

Per comprendere i profili di consumo energetico e di alimentazione, esaminiamo il secondo dashboard, Power Monitoring / Namespace. Dopo aver selezionato lo spazio dei nomi che ci interessa (hermes-ns):
- La prima cosa che possiamo osservare è che, dopo un paio di picchi, il consumo energetico in watt è costante nel tempo; il componente PKG è quello che consuma di più. Il dominio Package (PKG) misura il consumo energetico dell'intero socket, e include il consumo di tutti i core, della grafica integrata e anche dei componenti non core (cache degli ultimi livelli, controller di memoria). Non sembra ci siano problemi e non vengono rilevati accumuli, poiché il consumo di energia corrisponde alla velocità dell'energia.
- Possiamo anche vedere che il consumo di energia aumenta nel tempo. In questo caso, il contributo della DRAM (che misura il consumo energetico della RAM collegata al controller di memoria integrato) sembra trascurabile.
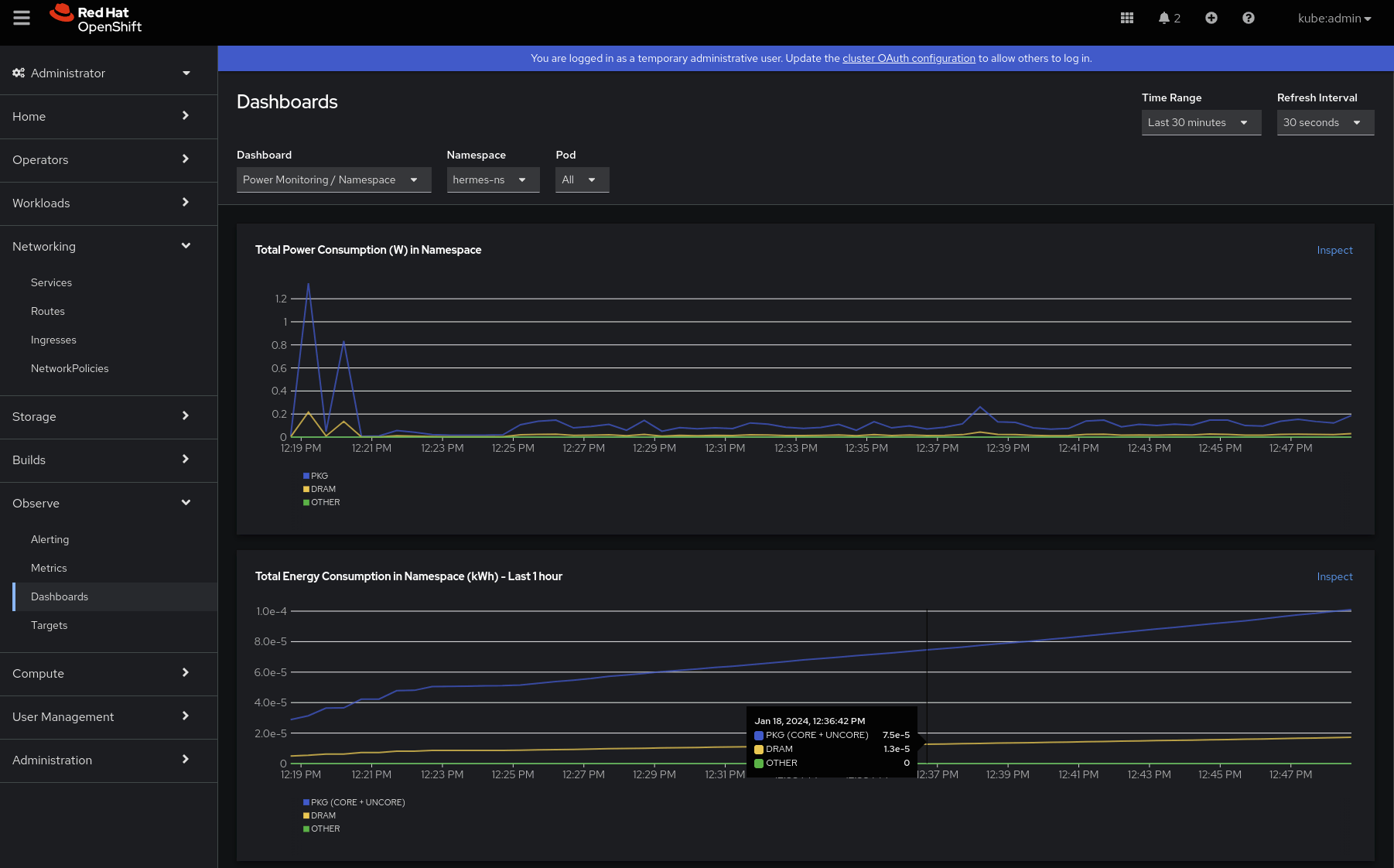
Scendendo in basso, possiamo ulteriormente analizzare i contributi di PKG e DRAM per container. Immediatamente evidente è che i primi picchi sembrano essere causati da un carico di lavoro precedente. Questo aspetto è interessante e potrebbe essere necessario eseguirne il debug nella nostra app/nel mock.
Al termine del secondo deployment, osserviamo che entrambi i container contribuiscono in egual misura al consumo energetico.

Cosa significa? Significa forse che un generatore di traffico con una logica complessa e strumenti con OpenTelemetry, metriche e tracciamento consuma la stessa quantità di energia di un semplice mock che dichiara "200 OK" e lo mostra sulla console? Malgrado la nostra passione per l'osservabilità moderna, di tanto in tanto è necessario eseguire una stampa standard dei risultati.
func exampleHandler(w http.ResponseWriter, r *http.Request) {
time.Sleep(2 * time.Millisecond)
fmt.Println("Request received. URI:", r.RequestURI, "Method:", r.Method)
w.WriteHeader(200)
}Il generatore di traffico è scritto in C++ e il mock in Go. Studi recenti hanno dimostrato che, in determinate condizioni, C++ può essere 2,5 volte più efficiente dal punto di vista energetico rispetto a Go, ma questo approfondimento va oltre lo scopo di questo blog. Apprezziamo ogni linguaggio e ognuno eccelle in qualche aspetto. Ci interessa molto scoprire come utilizzerai il monitoraggio dell'alimentazione. Con questi dati a portata di mano, puoi anche affrontare il conflitto tra linguaggio di programmazione e consumo energetico.
Qual è la prossima mossa?
Continueremo a impegnarci per integrare i feedback ricevuti, apportare modifiche e introdurre migliorie. Proseguirà anche la nostra collaborazione con la community, perché vogliamo contribuire all'iniziativa globale per monitorare i consumi energetici in modo più efficace. Le prospettive sono promettenti, con proposte e piani che vanno dall'integrazione del monitoraggio dei consumi energetici in iniziative di sostenibilità su più vasta scala, al supporto offerto agli sviluppatori nell'esame del codice nella piattaforma OpenShift o all'esportazione dei dati tramite OpenTelemetry.
Approfondimenti
- Documentazione ufficiale di Red Hat OpenShift
- Introducing developer preview of Kepler: power monitoring for Red Hat OpenShift
- https://sustainable-computing.io/
- Exploring Kepler’s potentials: unveiling cloud application power consumption | CNCF
- Which Programming Languages Use the Least Electricity? - The New Stack
- Ambito del supporto - Anteprima per sviluppatori - Red Hat Customer Portal
- Funzionalità dell'anteprima tecnologica - Ambito del supporto - Red Hat Customer Portal
- Anteprime tecnologiche e per sviluppatori a confronto - Red Hat Customer Portal
- Abilitazione del monitoraggio per i progetti definiti dall'utente | Monitoraggio | Red Hat OpenShift Platform 4.14
Sull'autore

Jose is a Senior Product Manager at Red Hat OpenShift, with a focus on Observability and Sustainability. His work is deeply related to manage the OpenTelemetry, distributed tracing and power monitoring products in Red Hat OpenShift.
His expertise has been built from previous gigs as a Software Architect, Tech Lead and Product Owner in the telecommunications industry, all the way from the software programming trenches where agile ways of working, a sound CI platform, best testing practices with observability at the center have presented themselves as the main principles that drive every modern successful project.
With a heavy scientific background on physics and a PhD in Computational Materials Engineering, curiousity, openness and a pragmatic view are always expected. Beyond the boardroom, he is a C++ enthusiast and a creative force, contributing symphonic and electronic touches as a keyboardist in metal bands, when he is not playing videogames or lowering lap times at his simracing cockpit.
Altri risultati simili a questo
Strengthening the enterprise foundation: Red Hat and Oracle’s expanding collaboration
Integrating Red Hat Lightspeed with CrowdStrike for enhanced malware detection coverage
Edge computing covered and diced | Technically Speaking
Ricerca per canale

Automazione
Novità sull'automazione IT di tecnologie, team e ambienti

Intelligenza artificiale
Aggiornamenti sulle piattaforme che consentono alle aziende di eseguire carichi di lavoro IA ovunque

Hybrid cloud open source
Scopri come affrontare il futuro in modo più agile grazie al cloud ibrido

Sicurezza
Le ultime novità sulle nostre soluzioni per ridurre i rischi nelle tecnologie e negli ambienti

Edge computing
Aggiornamenti sulle piattaforme che semplificano l'operatività edge

Infrastruttura
Le ultime novità sulla piattaforma Linux aziendale leader a livello mondiale

Applicazioni
Approfondimenti sulle nostre soluzioni alle sfide applicative più difficili
Virtualizzazione
Il futuro della virtualizzazione negli ambienti aziendali per i carichi di lavoro on premise o nel cloud