Garantisci l'accesso condiviso all'IA con operazioni centralizzate sui modelli
- Agli ingegneri dell'IA, MaaS offre un accesso più rapido ai modelli ad alte prestazioni tramite le API, eliminando la necessità di scaricare i modelli, gestire le dipendenze o richiedere allocazioni di GPU tramite lunghi ticket IT.
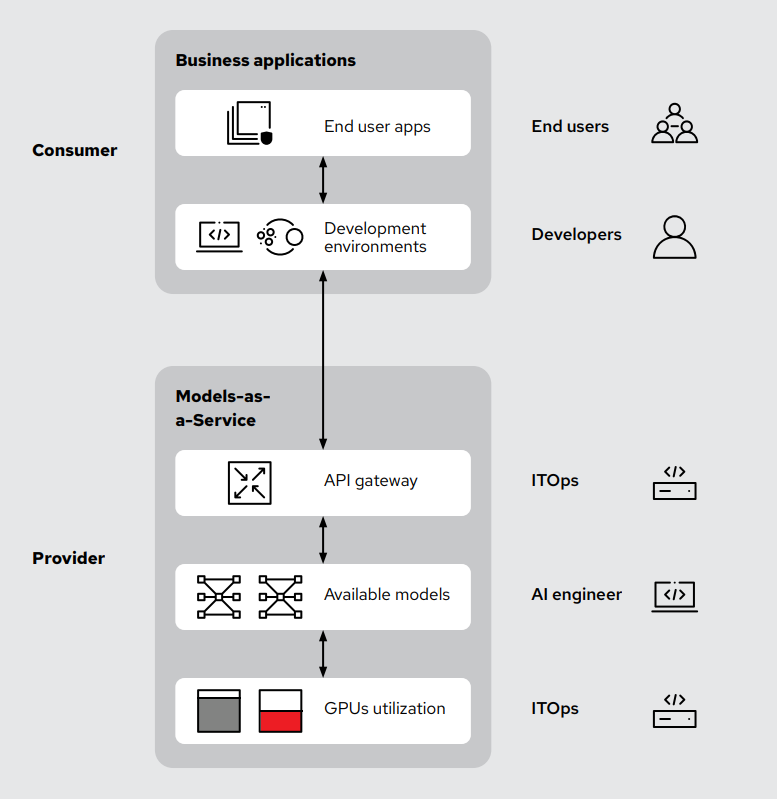
MaaS funziona impostando un team operativo di IA come proprietario centrale delle risorse di IA condivise. I modelli vengono distribuiti su una piattaforma scalabile (come Red Hat® OpenShift® AI o altre piattaforme simili) e quindi esposti tramite un gateway API. Questa configurazione consente a più utenti, sviluppatori e business unit di offrire un accesso semplificato agli utenti finali, soddisfacendo al contempo le priorità di sicurezza e governance per i team IT e finanziari. Questa definizione delle priorità può includere funzionalità di chargeback, con la possibilità di usare i modelli senza la necessità di accedere direttamente all'hardware o di avere competenze tecniche approfondite. L'obiettivo è fornire un accesso intuitivo ai modelli di IA e non alle risorse necessarie per eseguirli, come GPU e unità di elaborazione tensoriale (TPU). Tutto questo nel rispetto dei requisiti di conformità e prestazioni aziendali e senza complicare l'accesso per gli utenti finali.
In pratica, gli utenti interagiscono solo con le API che forniscono risposte generate dal modello. Così come i provider di IA pubblici astraggono le complessità hardware dagli utenti finali, i deployment MaaS interni offrono la stessa semplicità. Gli utenti non gestiscono direttamente l'infrastruttura hardware o software, non aspettano che un ticket IT venga risolto per loro conto né restano in attesa mentre un ambiente viene configurato su loro richiesta. Al contrario, i team dedicati alle operazioni IT e all'IA gestiscono centralmente il ciclo di vita dei modelli, la sicurezza, gli aggiornamenti e la scalabilità dell'infrastruttura, offrendo agli utenti un accesso semplificato ma controllato.
Questa centralizzazione non solo semplifica le operazioni interne di IA, ma migliora anche la sicurezza e la governance. L'accesso ai modelli di IA è strettamente controllato con la gestione delle credenziali tramite un gateway API. Le organizzazioni possono monitorare tempestivamente l'utilizzo, impostare meccanismi interni di chargeback, assicurarsi che le linee guida di conformità alla privacy vengano seguite e stabilire limiti operativi chiari, il che rende l'IA per le aziende gestibile e pratica. Il monitoraggio dell'utilizzo a livello di token (in entrata e in uscita) è il metodo più accurato e granulare, e molto più preciso di qualsiasi metrica a livello di GPU.
Controlla l'utilizzo, limita gli accessi e gestisci i costi
- Gli ingegneri IT e della piattaforma beneficiano di una supervisione centralizzata, che impedisce il deployment non autorizzato dei modelli, applica gli standard di sicurezza e conformità e semplifica la gestione del ciclo di vita e dell'infrastruttura.
- Per i team finanziari, il tracciamento centralizzato dell'utilizzo e i meccanismi interni di chargeback riducono gli sprechi e rendono l'utilizzo della GPU più prevedibile e responsabile, evitando spese eccessive dovute ad allocazioni hardware sottoutilizzate e specifiche per team.
Con un approccio MaaS il controllo si ottiene principalmente integrando un gateway API con l'infrastruttura di IA, che consente ai team di gestire e monitorare l'utilizzo dell'IA a un livello molto granulare.
I deployment tradizionali dell'IA spesso non sono gestiti o non sono efficienti, perché gli utenti o i team distribuiscono i modelli in modo indipendente e senza supervisione centralizzata. Questo approccio frammentato può portare a costose inefficienze, con risorse GPU inattive o sottoutilizzate. Collocare un gateway API al centro dell'infrastruttura di IA crea un punto di accesso controllato tra utenti e modelli.
Questa configurazione facilita il tracciamento preciso dell'utilizzo, fino al livello del singolo token. I team possono identificare chiaramente il consumo di ciascun utente, team o applicazione, attribuendo in modo accurato i costi di GPU e infrastruttura. Ad esempio, le organizzazioni possono determinare se un utente o un'applicazione particolare sta utilizzando le risorse in modo eccessivo e intraprendere azioni correttive, ad esempio limitando l'utilizzo o allocando i costi tramite meccanismi di chargeback interni.
Le funzionalità di throttling fornite dal gateway API garantiscono prestazioni coerenti e prevengono l'esaurimento delle risorse. La limitazione dell'uso consente ai team IT di gestire l'intensità degli accessi, impedendo ai singoli utenti di monopolizzare le risorse GPU o di compromettere le prestazioni di altri utenti.
Inoltre, i gateway API offrono una gestione granulare delle credenziali e il controllo degli accessi. Gli utenti interni possono generare le credenziali per accedere ai modelli di IA in modo indipendente, semplificando il carico amministrativo. Le credenziali possono anche essere revocate o modificate in meno tempo per rispondere ai cambiamenti dei requisiti di sicurezza o dei modelli di utilizzo.
Tutto questo significa che la gestione dei costi diventa più trasparente e responsabile. I team IT possono assegnare con precisione le spese relative a GPU e infrastruttura ai team o alle business unit che le utilizzano.
Supporta tutti i modelli, gli acceleratori e i cloud
Un principio cardine dell'approccio MaaS è il controllo. Consente alle organizzazioni di selezionare e distribuire un'ampia gamma di modelli di IA, scegliere gli acceleratori hardware preferiti e operare all'interno degli ambienti cloud o on premise esistenti. Questo approccio offre alle organizzazioni la libertà di implementare l'IA con precisione in base alle proprie esigenze tecniche, ai requisiti di sicurezza e alle preferenze operative.
- L'adozione dell'IA è soggetta a rigidi limiti. Spesso le aziende sono:
- Limitate da servizi cloud specifici.
- Bloccate in ecosistemi di modelli proprietari.
- Vincolate da infrastrutture hardware fisse.
- MaaS risolve queste limitazioni in diversi modi, tra cui:
- Supporto di modelli proprietari o open source, modelli con addestramento personalizzato e LLM più diffusi, come Llama e Mistral.
- Espansione oltre ai modelli testuali, a includere l'analisi predittiva, la visione artificiale, gli strumenti di trascrizione dell'audio e altri scenari di utilizzo dell'IA generativa multimodale, come la generazione di immagini o video.
- MaaS rimane indipendente dagli acceleratori hardware, quindi:
- Le organizzazioni possono scegliere GPU o altri acceleratori in linea con i carichi di lavoro, le strutture dei costi e le esigenze prestazionali.
- I team di IA centralizzata possono prendere decisioni critiche su dimensionamento e deployment, migliorando l'efficienza e riducendo gli errori da parte degli utenti meno tecnici.
- La gestione centralizzata consente:
- Allocazione e utilizzo ottimali dell'infrastruttura.
- Riduzione dei costi operativi e prevenzione degli errori di configurazione delle risorse.
- MaaS supporta il deployment in qualsiasi ambiente, inclusi:
- Ambienti on premise, di cloud ibrido, isolati e di cloud pubblico, che si rivela particolarmente utile per i settori altamente regolamentati che richiedono la sovranità dei dati, la conformità normativa o controlli di sicurezza rigorosi.