
In the first part of this series, we described how environments represent everything that developers need to run their applications and introduced the concept of "Environments as a Service" including an approach for provisioning developer environments in a self-service fashion. In the second part, we built upon that and demonstrated how to make credentials available in the environments for which they are needed.
What we have yet to discuss thus far is how developers can actually deploy their applications in these environments. That is the focus of this article.
As the title suggests, we are going to propose a GitOps-based approach for tenants. This GitOps approach will be largely based on the approaches that we already use for the infrastructure. In both cases we describe a desired configuration state via a set of manifest files, so it stands to reason that GitOps should work fine also for tenants.
So, from a tenant’s perspective, there are no more imperative CD pipelines to get applications deployed to environments — one has to simply make a pull request to a given repository and the GitOps operator takes it from there.
The first question we need to ask ourselves is how we should organize the Git repositories along with the GitOps operator instances to deliver a quality developer experience, while also building a platform that is scalable and secure (i.e. tenants are properly isolated)?
This is the platform engineering side of the equation and is what we are going to focus on in this article.
High-level architectural options
In terms of Git repository organization, a guideline on which there seems to be wide agreement is that Git repositories represent ownership boundaries. With that in mind, there should be a separate Git repository for each owner. The exact granularity of ownership (per application, per team, per business unit) does vary per organization/implementation.
These Git repositories become the interface between the platform and the tenants (the same technique that we saw in the prior articles). Since each repository is owned by separate entities, they can set up their desired organizational structure and approval processes.
The other main architectural decision at hand is in regard to the way the Argo CD instance is configured and deployed. This, however, is less straightforward as there are a number of options to choose from.
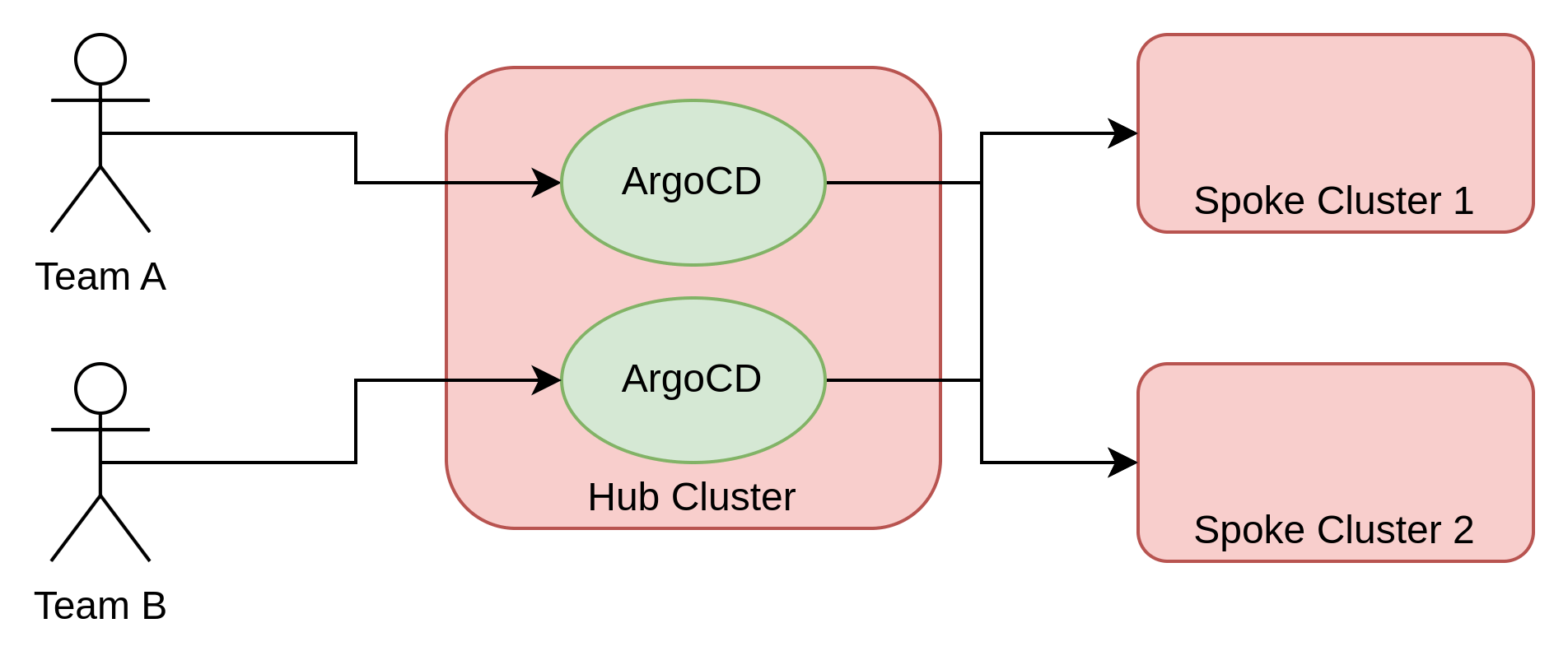
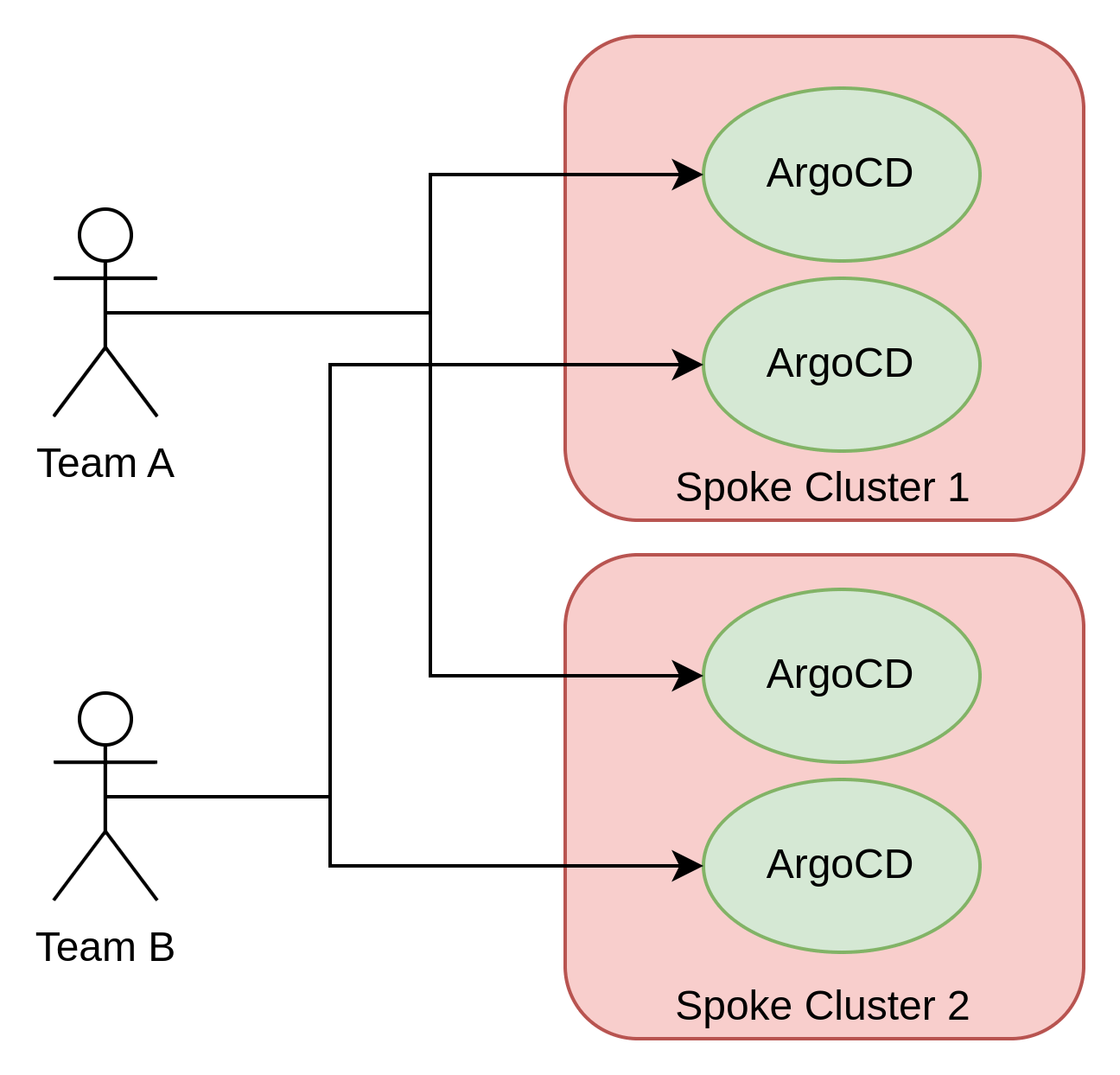
The first choice is whether the Argo CD is centralized or decentralized. In a multicluster hub-and-spoke setting, Argo CD is either deployed in the hub cluster in such a way that it controls the configurations on the spoke clusters or individual instances are deployed directly within the spoke clusters.
The second choice is whether the Argo CD instances are monotenant or multitenant. In other words, is there a separate Argo CD instance that is owned by each team or do multiple teams share a single Argo CD instance?
The following table visually summarizes these options.
Centralized | Decentralized | |
Monotenant |
|
|
Multitenant |
|

|
Let’s review these choices and the considerations behind each approach:
Centralized vs Decentralized
A centralized deployment assumes the existence of a hub cluster. This is not always the case, but, in situations in which an organization is managing a fleet of clusters, having a centralized hub to control the fleet is typically a good idea. With Red Hat tooling, this design can be achieved with Red Hat Advanced Cluster Management for Kubernetes.
The centralized mode represents a push model and cannot be expected to scale infinitely with the number clusters it manages. However, organizations and the open source community have made strides in improving the scalability of Argo CD. Additional details on these efforts can be found here.
The centralized management model is also not appropriate or applicable for all environments. Edge deployment, in particular, is one such environment where a push model is not recommended due to scalability as well as networking constraints. Instead, a pull model where Argo CD is deployed on each target cluster is more appropriate.
The centralized model is also a single point of failure: if we lose the hub cluster, we lose the ability to change the configuration of the spoke clusters. All of the limitations of the centralized model are often offset by the fact that the centralized model limits the sprawl of Argo CD instances and simplifies their overall management.
Monotenant vs Multitenant
In multitenant deployments, there needs to be a mechanism to isolate tenants in a way that each can only see their own applications/configurations along with restricting their ability to deploy resources in other tenants’ environments. Given the capabilities provided by Argo CD, this type of isolation requires the combination of Argo CD role-based access control (RBAC) and Kubernetes RBAC configurations.
Some organizations may not fully trust Argo CD to be able to provide the necessary level of isolation and may decide to implement another approach by creating monotenant instances of Argo CD. Another reason for advocating the use of monotenant Argo CD instances is that the tenant can be made the administrator of the instance itself.
While some organizations are choosing to go with this model, there is the assumption that every tenant will have the necessary skills needed to properly manage an Argo CD instance. This assumption is, in fact, rarely the case. Instead, a model that has been successful in many organizations is that a platform team is tasked with the responsibility of managing all Argo CD instances.
Another detriment of the monotenant instance approach is that it also promotes the proliferation of Argo CD instances and the costs associated with maintaining and running each instance (both from a management and resource perspective [the default deployment of OpenShift GitOps reserves around 2CPUs and 2.5GBi of memory]) may outweigh the benefits as more tenants are added.
Given these considerations, there does not appear to be a single option that clearly rises above the rest. Instead, each implementation has to be assessed individually to determine which option applies best to each situation. It’s probably fair to say that the monotenant and distributed option will have significant costs in terms of maintenance and actual resources needed to run the required number of Argo CD instances and should be evaluated with extreme care before pursuing.
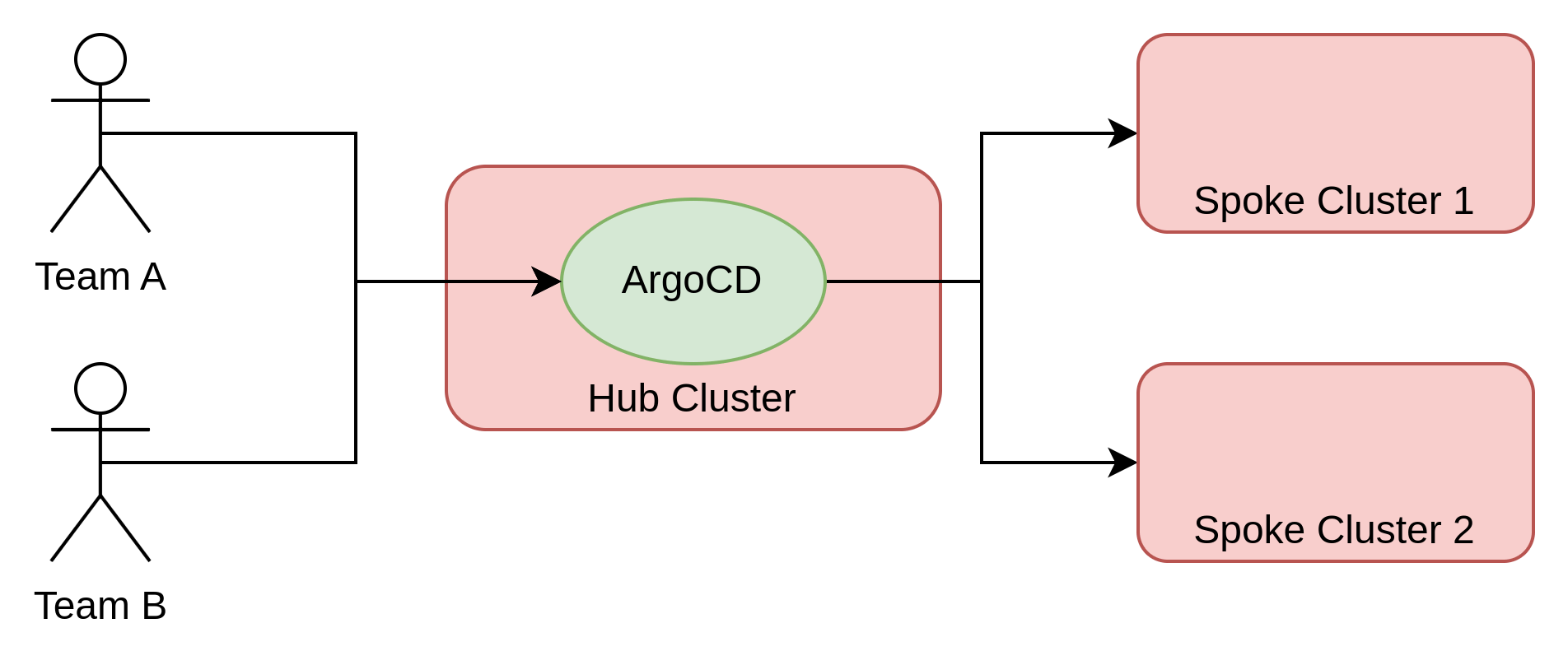
I personally prefer the centralized multitenant option given that it requires a limited set of resources in total and allows tenants to see all of their applications across every environment in a single Argo CD UI. Also, once you learn how to set up this approach, it’s always easy to move to a monotenant or distributed based architecture.
This approach is the type of architecture that will be implemented in this article.
Centralized, multitenant ArgoCD configuration walkthrough
The following diagram illustrates the design that will be implemented:

The first thing we need to do is define a folder structure for the tenant Git repositories. The naming convention aligns with the following:
/argo-applications
/<cluster>/<namespace>/<application>The first folder contains Argo CD applications. These applications may consist of any of the supported Argo CD formats. But, in most cases, they are either Kustomize or Helm. These applications may point to remote resources. But, if they need to reference local resources, they refer to the second directory in this folder structure design. Given this design, the application-specific resources are sorted by cluster, namespace and finally the application itself. The application-specific folder will normally contain a Kustomization overlay or an Helm chart value file.
The specific implementation details are purposefully omitted to provide developer teams the freedom to organize their resources as they see fit.
The expectation is that developer teams will have full control on these repositories: they will create the Argo CD applications along with any of the resources referenced by the Application. They will define the approval and promotion processes as well.
Some organizations are not comfortable giving so much freedom to development teams. In those situations, this approach will have to be modified and somewhat constrained based on the desired level of freedom that is deemed acceptable by the organization.
Perhaps, rather than constraining developers, it is better to make it easier for them to do the “right thing”. This is where the concept of the golden path comes into play. Golden paths are outside the scope for this article, but a more detailed article along with their benefits can be found here. These two articles can be considered complementary: once you have implemented a GitOps-for-tenants approach, it is relatively straightforward to start adding golden paths on top of it.
There will be one Git repository per team. If you recall from the previous articles of this series, there are two teams: team-a and team-b. With that in mind, there will be two repositories (I created them here and here). We could orchestrate the provisioning of GitOps repositories behind a Red Hat Developer Hub (RHDH) template to further improve the user experience, but that is also outside the scope of this article,
The next step is to deploy the tenant Argo CD instance. You can find the configurations located here. It contains several components, so let’s break them down in further detail.
First, each team should have a namespace within the hub cluster in which their Argo CD Applications will be created. This means that we will need to have the “applications in any namespace” feature enabled. We use a simple App of Apps approach to generate these applications. The root application is owned by the infrastructure team and defined here. These Argo CD Applications will be pointing to namespaces in remote clusters. Argo CD manages connections to remote clusters via secrets. These secrets will need to be created so that they are scoped to act only on those specific namespaces. Secrets are defined here and there will be further explanation on their usage later on.
To control what each team can see and do in the Argo CD UI and prevent team-a from seeing Applications from team-b, we use the concept of Argo CD Projects. The AppProject resources are defined here.
This tenant-dedicated instance of Argo CD is configured with single sign-on (SSO) support with our Open ID Connect (OIDC) provider (Keycloak is the implementation for our setup if you recall from a previous article in this series). When users login, the Keycloak groups they belong to are propagated as JSON Web Token (JWT) token claims.
Notice that most of the previously mentioned configurations are parameterized based on the team. So, as we define more teams (groups) in our OIDC provider, the configuration grows automatically without the platform team having to maintain additional configurations manually. This provides a scalable solution and supports large enterprise wide adoption of such a platform. To enable the parameterization based on the team, we use the namespace-configuration-operator.
Regarding the secrets that are used to connect to the remote clusters, Argo CD unfortunately indexes the connections based on the API URL and not on the name of the cluster. As a consequence, Argo CD is unable to distinguish between two connections to the same cluster using different credentials. To work around this limitation, connections are defined with an additional URL parameter which has no implication on the connectivity to the remote cluster in the form: https://<cluster-url>:6443/?id=<team-name>. While this approach works, it does cause an increase in the memory used by some of the Argo CD pods. An issue is open in the ArgoCD repository to improve this aspect of Argo CD.
At this point, you might be wondering how credentials are minted for each combination of cluster and team with the exact permission that a team should have.
To do so, we use the Vault Kubernetes secret engine. This secret engine can create service account tokens on the fly. Behind the scenes, this secret engine invokes the Kubernetes Token Request API.
To set up this configuration, we need each spoke cluster to define a Kubernetes secret engine that references the cluster it is defined within.
Once that part is complete, we need to define service accounts (one per team in each cluster) that will have the exact level of access needed for each team. Service account tokens will be generated from these service accounts.
Now, we can create a Kubernetes secret engine role per team (per cluster) which is associated with the previously created service accounts using the Kubernetes secret engine, allowing someone with the correct Vault credentials to generate a service account token for those service accounts.
By utilizing this approach, a scoped Argo CD cluster connection secret can be created. The configuration for achieving such an approach is found here.
While the approach of leveraging Vault to generate service accounts tokens for use by Argo CD connection secrets, it is just one of a myriad of potential use cases for this type of pattern. Other systems that might need to operate on a remote cluster include Jenkins and Tekton, among many others.
Conclusion
In this article, we explored an implementation of the centralized multitenant approach for deploying Argo CD to support tenants. The design favors automation heavily so that as more teams are on-boarded onto the platform, the load for the platform team does not increase. Flexibility is also included, particularly from a tenant’s perspective, which provides developer teams a significant amount of freedom. With that being said, this design should be a good starting point to either restrict what teams can do, or better yet, make it easy for them to do the “right thing" with golden paths.
If there is a desire to leverage one of the other Argo CD deployment patterns, then it should be relatively straightforward to refactor the configuration as necessary and achieve the desired result.
In these first three articles we have explored an approach to provision and configure namespaces, manage credentials and set up GitOps for tenants. Other approaches to solving this common set of issues exist, and I’d like to mention two of them:
- The multitenant operator developed by Stakater. This operator makes available a new CRD to express the existence of a tenant and all of the configuration that goes with it. It covers essentially the same aspects that we have covered so far. Flexibility in defining what a ready to use environment is is achieved with the use of a homegrown templating capability. The main difference with our approach is that here the platform team uses a CR to define a new tenant, in the approach described here the existence of a new tenant is deduced by the existence of namespaces and groups, which are used in concert with tube namespace-config-operator to trigger the needed configurations.
- A fully Helm-based approach. Helm charts are used to configure tenant environments. Multiple instances of these Helm charts are created by GitOps configurations managed by the platform team.
저자 소개
Raffaele is a full-stack enterprise architect with 20+ years of experience. Raffaele started his career in Italy as a Java Architect then gradually moved to Integration Architect and then Enterprise Architect. Later he moved to the United States to eventually become an OpenShift Architect for Red Hat consulting services, acquiring, in the process, knowledge of the infrastructure side of IT.
Currently Raffaele covers a consulting position of cross-portfolio application architect with a focus on OpenShift. Most of his career Raffaele worked with large financial institutions allowing him to acquire an understanding of enterprise processes and security and compliance requirements of large enterprise customers.
Raffaele has become part of the CNCF TAG Storage and contributed to the Cloud Native Disaster Recovery whitepaper.
Recently Raffaele has been focusing on how to improve the developer experience by implementing internal development platforms (IDP).
유사한 검색 결과
빠르게 진화하는 AI 위협, 더 빠른 대응
관리에서 벗어나 오케스트레이션으로 전환: Red Hat Ansible Automation Platform을 통한 Catalyst 운영 간소화
Container Roundup | Compiler
Untangling Networks | Compiler
채널별 검색

오토메이션
기술, 팀, 인프라를 위한 IT 자동화 최신 동향

인공지능
고객이 어디서나 AI 워크로드를 실행할 수 있도록 지원하는 플랫폼 업데이트

오픈 하이브리드 클라우드
하이브리드 클라우드로 더욱 유연한 미래를 구축하는 방법을 알아보세요

보안
환경과 기술 전반에 걸쳐 리스크를 감소하는 방법에 대한 최신 정보

엣지 컴퓨팅
엣지에서의 운영을 단순화하는 플랫폼 업데이트

인프라
세계적으로 인정받은 기업용 Linux 플랫폼에 대한 최신 정보

애플리케이션
복잡한 애플리케이션에 대한 솔루션 더 보기
가상화
온프레미스와 클라우드 환경에서 워크로드를 유연하게 운영하기 위한 엔터프라이즈 가상화의 미래