No artigo anterior, focamos no recurso que transforma grandes modelos de linguagem (LLMs) de ferramentas de uso geral em instrumentos de pesquisa por meio da personalização de domínio específico. Com modelos ajustados, as equipes de pesquisa codificam o conhecimento de domínio, a pesquisa institucional e os padrões de raciocínio em sistemas que ajudam a acelerar a descoberta, em vez de simplesmente auxiliá-la.
Mas os modelos personalizados são apenas metade da equação. Para que esses modelos se tornem úteis em escala institucional, eles precisam de uma plataforma para treiná-los, disponibilizá-los, governar o acesso e integrá-los ao ambiente de computação de pesquisa mais amplo. Essa plataforma deve unir os mundos em que pesquisadores já vivem: clusters tradicionais de computação de alto desempenho (HPC) que executam o gerenciador de cargas de trabalho Slurm e o ecossistema de IA nativo em nuvem em rápida expansão baseado no Kubernetes.
Neste artigo, exploramos como essa plataforma se concretiza: a arquitetura que permite às instituições de pesquisa convergir HPC e cargas de trabalho nativas em nuvem, operacionalizar modelos personalizados como serviços compartilhados e entregar recursos de IA generativa (gen IA) em organizações inteiras sem sacrificar a governança, a reprodutibilidade ou o controle de custos.
Arquitetura da plataforma: como as peças se encaixam
Com o caso de personalização estabelecido, vejamos como a plataforma completa se concretiza. A arquitetura é generalizada e se aplica independentemente de você implementá-la em uma universidade de pesquisa, em um centro de pesquisa e desenvolvimento financiado pelo governo, em um hospital universitário, em uma empresa de energia ou em um grupo de pesquisa de serviços financeiros. Os componentes são os mesmos, mas a configuração para cada domínio é diferente.
A base é o Red Hat OpenShift, uma distribuição do Kubernetes que oferece orquestração de containers, governança de namespaces, controle de acesso baseado em função (RBAC), integração de armazenamento persistente e ferramentas operacionais de que a engenharia de plataforma precisa para executar uma infraestrutura de IA compartilhada em escala institucional.
Sobre o OpenShift, o Red Hat OpenShift AI oferece recursos específicos de IA, incluindo serviço de modelos, personalização de modelos, orquestração de pipelines, ambientes de notebook para cientistas de dados e observabilidade para cargas de trabalho de IA. O OpenShift AI transforma a plataforma Kubernetes base em um ambiente onde pesquisadores podem treinar, ajustar, avaliar, implantar e monitorar modelos por meio de uma interface de autosserviço governada, sem que cada equipe precise gerenciar sua própria infraestrutura de machine learning.
O engine de inferência é o vLLM, servido pela camada de disponibilização de modelos do OpenShift AI. O processamento contínuo em lotes e os mecanismos de atenção com eficiência de memória do vLLM fazem dele a escolha adequada para ambientes de inferência compartilhados, nos quais várias equipes de pesquisa consomem endpoints de modelos simultaneamente. Em um ambiente com recursos limitados — o qual é a realidade da maioria das instituições de pesquisa — a diferença entre uma inferência eficiente e ineficiente representa uma parte significativa do orçamento de GPU.
A camada de hardware Red Hat AI Factory with NVIDIA é onde a colaboração entre a Red Hat e a NVIDIA se torna diretamente relevante. O Red Hat AI Factory with NVIDIA une o hardware de GPU da NVIDIA e o framework NVIDIA Inference Microservices (NIM) aos recursos de orquestração e governança do OpenShift AI. Os containers NIM empacotam configurações de modelos otimizadas e validadas prontas para veiculação no hardware da NVIDIA e, como são executados no OpenShift, herdam a governança de namespaces, o RBAC e o stack de observabilidade da plataforma.
Para instituições de pesquisa que estão adquirindo infraestrutura de GPU da NVIDIA — a maioria delas — a arquitetura de referência do Red Hat AI Factory with NVIDIA oferece um caminho validado e com suporte do hardware para a execução de serviços de inferência, ajudando a evitar meses de trabalho de integração. O catálogo NIM da NVIDIA inclui modelos base das principais famílias de modelos; o pipeline de personalização do OpenShift AI amplia essas bases com ajuste fino específico de domínio. A combinação é um caminho prático de "temos GPUs" para "temos um modelo clínico ajustado servindo nossos pesquisadores".
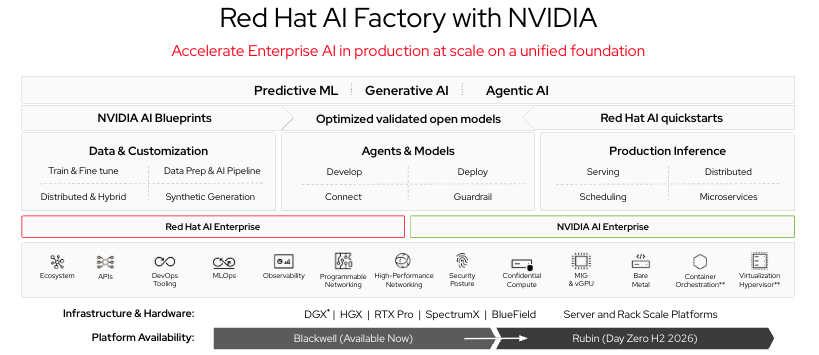
Figura 1: Red Hat AI Factory with NVIDIA
União de HPC e cloud-native: o operador Slinky
O Slurm alimenta muitos dos principais supercomputadores do mundo e é a interface padrão para envio de trabalhos de HPC em instituições de pesquisa. Os pontos fortes do Slurm são reais, incluindo reservas exclusivas de GPU, desempenho previsível, enfileiramento de prioridades maduro e integração profunda com sistemas de arquivos paralelos e cargas de trabalho no estilo MPI (message passing interface). A maioria dos usuários de HPC das instituições de pesquisa conhece o Slurm, e seus pipelines são geralmente escritos para o Slurm.
O desafio sempre foi a lacuna entre o mundo do Slurm e o mundo do Kubernetes: dois escalonadores, dois sistemas de contabilização de recursos, duas maneiras de solicitar uma GPU e duas equipes operacionais. Os artefatos de dados são movidos manualmente entre ambientes, e a capacidade da GPU geralmente fica ociosa no cluster de HPC durante janelas de baixa utilização, enquanto o ambiente Kubernetes enfileira tarefas.
O operador Slinky resolve essa lacuna. Conforme discutido neste artigo sobre a execução de cargas de trabalho do Slurm no OpenShift, o Slinky é um operador do Kubernetes que implanta e gerencia componentes do Slurm — entre eles o slurmctld e slurmd — como cargas de trabalho em containers dentro do OpenShift. Isso automatiza a implantação, a escala e o gerenciamento do ciclo de vida do cluster do Slurm, para que ele possa coexistir com cargas de trabalho nativas do Kubernetes no mesmo hardware.
O que isso significa na prática para engenheiros de plataforma de pesquisa:
- Agendamento unificado de recursos: as tarefas em lote do Slurm e as cargas de trabalho de IA nativas do Kubernetes compartilham o mesmo pool de GPU. A capacidade ociosa entre grandes tarefas de simulação pode ser alocada para cargas de trabalho de inferência ou ajuste fino sem intervenção manual ou reatribuição de hardware.
- Fluxos de trabalho de pesquisadores preservados: pesquisadores de HPC que enviam tarefas por meio do sbatch não precisam alterar o fluxo de trabalho. A interface do Slurm que eles conhecem ainda está lá, mas agora também é executada no OpenShift, com toda a observabilidade, gerenciamento do ciclo de vida e governança que o Kubernetes oferece.
- Ambientes reproduzíveis: as tarefas do Slurm são executadas como containers, o que significa que o ambiente é definido pela imagem de container, e não pelo que estiver instalado no nó de computação. Isso melhora significativamente a reprodutibilidade e simplifica a colaboração entre instituições que desejam compartilhar pipelines.
- Superfície operacional única: engenheiros de Plataforma mantêm um cluster, uma stack de observabilidade e um modelo de RBAC. O Slinky não exige nem cria uma segunda infraestrutura: ele integra o agendamento de HPC à plataforma que já está em uso.
A aquisição da SchedMD pela NVIDIA, principal desenvolvedora do Slurm, sinaliza o rumo dessa convergência no setor. Os limites entre agendamento de HPC, orquestração de Kubernetes e infraestrutura de IA estão sendo intencionalmente apagados. O Slinky é a contribuição da Red Hat para essa convergência, disponível agora para execução em produção.
Para uma universidade de pesquisa que opera um cluster de HPC para ciência computacional e um ambiente OpenShift para pesquisa de IA, o Slinky ajuda a fazer com que esses dois investimentos funcionem como um só.
Models-as-a-Service (MaaS): modelo de plataforma de IA compartilhada para as instituições de pesquisa
A convergência de plataformas resolve o problema de infraestrutura, mas há outro problema igualmente importante e menos discutido: a maioria das equipes de pesquisa não inclui liderança de engenharia de infraestrutura. Uma equipe de informática clínica que desenvolve um chatbot voltado para a equidade na saúde não quer gerenciar namespaces do Kubernetes. Um laboratório de genômica que precisa de um modelo ajustado para anotação de variantes não quer configurar implantações de vLLM. Um departamento de ciências sociais computacionais que deseja executar análise de documentos baseada em LLM não quer escrever Helm charts.
O modelo operacional que resolve isso é o Models-as-a-Service (MaaS).
O que é MaaS?
MaaS é uma abordagem em que engenheiros de plataforma implantam, gerenciam e operam modelos de IA como serviços compartilhados, expondo-os aos consumidores por meio de APIs. No contexto de uma instituição de pesquisa, a equipe de plataforma de computação de pesquisa opera o cluster de GPU, gerencia o ciclo de vida do modelo, lida com o controle de versão e as atualizações e mantém a infraestrutura de serviço. Enquanto isso, as equipes de pesquisa consomem os endpoints do modelo como um serviço, da mesma forma que consomem uma alocação de computação ou uma montagem de armazenamento.
As implicações para a produtividade da pesquisa são significativas. Analise como é o fluxo de trabalho hoje e como seria sob um modelo MaaS.
Hoje, sem MaaS
Uma equipe de pesquisa precisa de um modelo com ajuste fino para seu projeto. Eles passam semanas configurando um ambiente de GPU, instalando dependências, configurando um framework de serviço e depurando problemas de infraestrutura. A pesquisa começa quando a infraestrutura finalmente funciona, o que pode ocorrer meses após o início do projeto. Quando terminam, o modelo reside na workstation de uma pessoa ou em uma alocação temporária de cluster recuperada.
Com MaaS no Red Hat OpenShift AI
A equipe de pesquisa traz o conjunto de dados e os requisitos de domínio para a equipe de plataforma. Eles trabalham com engenheiros de plataforma para configurar e executar um trabalho de ajuste fino por meio do Training Hub no Red Hat OpenShift AI. O modelo resultante é servido como um endpoint de API com controle de versão e governança no cluster compartilhado. Outras equipes de pesquisa com necessidades relacionadas podem acessar o mesmo endpoint. Quando o modelo precisa ser atualizado com novos dados, o pipeline de treinamento é executado novamente e a nova versão é promovida pelo mesmo processo de governança.
A equipe de plataforma cuida da infraestrutura, enquanto a equipe de pesquisa cuida da ciência. Essa divisão de trabalho ajuda a escalar os recursos de IA em uma instituição.

Figura 2: Convergir HPC, cloud-native e Modelos como Serviço para pesquisas científicas
Para engenheiros de plataforma, MaaS no Red Hat OpenShift AI ("Pesquisa como Serviço", se preferir) oferece os controles operacionais necessários: cotas de recursos no nível do namespace que impedem que um único projeto de pesquisa monopolize a capacidade da GPU, controle de versão do modelo por um registro, RBAC que controla quem pode implantar e quem pode apenas consumir e observabilidade em todas as cargas de trabalho em serviço por meio de um dashboard unificado.
Para instituições de pesquisa com vários grupos de pesquisa (por exemplo, uma faculdade de medicina, um departamento de biologia computacional, uma faculdade de informática ou um instituto de ciência de dados executados na mesma plataforma), o MaaS é a forma como as equipes de plataforma se mantêm à frente da demanda sem escalar o quadro de funcionários linearmente com o número de projetos de pesquisa.
Gravidade dos dados: leve a IA para onde a pesquisa acontece
A área de pesquisa tem um problema de gravidade dos dados. Os conjuntos de dados de maior valor (registros clínicos, sequências genômicas, resultados de simulações) já são grandes, distribuídos e, muitas vezes, imovíveis devido a restrições de custo, latência ou governança. Mover petabytes de dados para um endpoint de nuvem é ineficiente e, muitas vezes, impossível.
A plataforma discutida aqui traz a IA para os dados, e não o contrário. Ao executar o treinamento de modelos, o ajuste fino e a inferência onde os dados já residem (on-premise, no laboratório, em ambientes de pesquisa protegidos etc.), você evita a movimentação desnecessária de dados e preserva o desempenho e a conformidade.
No final das contas, isso não é apenas uma otimização: é realmente um requisito de arquitetura. Quanto mais próximo o modelo estiver dos dados, mais rápido será o ciclo de iteração, menor será o custo e mais prático será operacionalizar a IA em fluxos de trabalho de pesquisa em larga escala.
Onde essa arquitetura se aplica: pesquisa em diversos setores
É claro que essa plataforma não é específica para pesquisa acadêmica. A arquitetura é aplicável a qualquer instituição onde o conhecimento de domínio seja importante, a governança de dados limite a implantação nativa em nuvem e as cargas de trabalho de pesquisa abranjam todo o espectro de HPC a nativo em nuvem.
- Universidades de pesquisa e centros de pesquisa e desenvolvimento financiados pelo governo federal (FFRDCs): universidades e centros de pesquisa e desenvolvimento financiados pelo governo federal, como laboratórios nacionais, costumam ter a infraestrutura que essa arquitetura atende: clusters de HPC para pesquisas com simulação intensa, demanda crescente de IA nativa em nuvem por grupos de ciência de dados e equipes de engenharia de plataforma que tentam atender dezenas de grupos de pesquisa com diferentes requisitos de computação.
- Instituições médicas e hospitais universitários: a IA clínica é uma das áreas de investimento em pesquisa que mais crescem, sendo uma das mais exigentes em termos de precisão do modelo, governança de dados e requisitos de segurança. Modelos de nuvem de uso geral geralmente são inviáveis devido às obrigações de privacidade de dados dos pacientes. Essas organizações precisam de modelos ajustados executados on-premise, com registros de auditoria e controles de acesso, servidos por uma plataforma institucional governada.
- Pesquisa de defesa e inteligência: FFRDCs e prestadores de serviços de defesa que operam em ambientes confidenciais ou controlados compartilham as mesmas necessidades de governança de dados que a pesquisa clínica, somadas a requisitos de classificação que proíbem o uso de APIs de nuvem. Isso exige a disponibilização de modelos on-premise, operação desconectada e modelos ajustados que contenham conhecimento de domínio confidencial internamente.
- Serviços financeiros e pesquisa quantitativa: grupos de pesquisa em serviços financeiros (por exemplo, pesquisa quantitativa, modelagem de risco e análise regulatória) trabalham com dados proprietários e operam sob restrições regulatórias que limitam o que pode ser enviado para APIs externas. Esses grupos precisam de modelos ajustados treinados em pesquisas internas, servidos on-premise via MaaS e acessíveis por meio de APIs governadas que se integrem aos fluxos de trabalho de pesquisa existentes.
- Pesquisa industrial e de energia: organizações de petróleo e gás, serviços públicos e pesquisa industrial executam cargas de trabalho de simulação computacionalmente intensivas com pipelines de machine learning crescentes para pesquisa de materiais, manutenção preditiva e análise geofísica. O Slinky é particularmente relevante neste setor, pois fluxos de trabalho de simulação baseados em Slurm são o padrão e a análise orientada por machine learning é cada vez mais necessária no downstream dessas simulações.
Em todos esses contextos, o padrão de arquitetura é consistente: convergir HPC e escalonamento nativo em nuvem, personalizar modelos para especificidades de domínio, servi-los com eficiência por meio de uma plataforma MaaS compartilhada e governar o acesso no nível institucional.
Em resumo: o que a plataforma permite
Como exemplo, veja o que a arquitetura completa permite para uma instituição de pesquisa que a implantou:
Uma liderança em pesquisa de genômica computacional envia uma tarefa de chamada de variante em larga escala via Slurm, da mesma forma que envia tarefas de HPC há anos. O operador Slinky a escala como uma carga de trabalho em containers no Red Hat OpenShift, nos mesmos nós de GPU que também atendem endpoints de inferência ajustados. Após a conclusão da tarefa, as saídas são armazenadas em um armazenamento de objetos compartilhado, acessível aos ambientes HPC e Kubernetes.
Uma liderança em pesquisa de PNL clínica em uma faculdade de medicina precisa de um modelo ajustado com notas clínicas desidentificadas para uma tarefa de reconhecimento de entidade nomeada. A liderança trabalha com o time da plataforma para executar uma tarefa de ajuste fino de Low-Rank adaptation (LoRA) por meio do Training Hub no OpenShift AI, usando um modelo base do catálogo do NVIDIA NIM. O modelo resultante possui controle de versão e é servido como um endpoint de MaaS. Um <1>grupo de pesquisa de cibersegurança em um FFRDC precisa analisar relatórios de inteligência sobre ameaças em escala usando um LLM.
Um grupo de pesquisa de cibersegurança em um FFRDC precisa analisar relatórios de inteligência sobre ameaças em escala usando um LLM. Como os dados possuem restrições de confidencialidade que proíbem o uso de APIs na nuvem, o modelo é executado inteiramente on-premise no cluster do OpenShift. O modelo passou por ajuste fino no conjunto de dados confidencial usando a geração de dados sintéticos do InstructLab para aumentar o pequeno conjunto de dados rotulados. O endpoint é acessível somente para namespaces com as associações de RBAC apropriadas.
A engenharia de plataforma que gerencia todas essas cargas de trabalho no mesmo cluster visualiza um único dashboard de observabilidade com a utilização de GPU em cargas de trabalho de Slurm e Kubernetes, latência de disponibilização de modelos por endpoint, profundidade de fila de tarefas de treinamento e utilização de cota de recursos por namespace. O scheduler unificado resolve a contenção de recursos entre cargas de trabalho, sem necessidade de intervenção manual.
Cada um desses recursos está disponível hoje no Red Hat AI e no OpenShift AI, integrados ao hardware da NVIDIA pelo Red Hat AI Factory com a arquitetura de referência da NVIDIA e estendidos aos fluxos de trabalho de HPC pelo operador Slinky.
Considerações finais
Pesquisadores que conduzirão a próxima geração de descobertas usarão LLMs como ferramenta principal e parte essencial do fluxo de trabalho de pesquisa, não como um complemento aos métodos existentes.
O que eles precisam da plataforma é de recursos que possam usar sem se tornarem especialistas em infraestrutura. Eles precisam de modelos com ajuste fino que conheçam seu domínio, inferência rápida e confiável, fluxos de trabalho de HPC que não exijam mudança de contexto para um cluster diferente e acesso compartilhado por meio de um serviço governado.
Juntos, o Red Hat OpenShift, o Red Hat AI, a NVIDIA e o operador Slinky podem oferecer essa plataforma.
Recurso
Introdução à IA empresarial: um guia para iniciantes
Sobre os autores

I build real-world GenAI solutions for organizations that can’t afford to get it wrong.
My career spans national security, enterprise software, and next-generation AI platforms, with more than a decade focused on solving complex problems at the intersection of data, intelligence, and technology. I began in the intelligence community, serving eight years with the NSA and across the IC in intrusion defense, intelligence analysis, and mission-critical cyber operations. That experience in high-stakes security, pattern recognition, and adversarial thinking continues to shape how I approach GenAI strategy and deployment today.
Since then, I’ve led product and platform initiatives in digital ecosystems, advised startups, and worked across the data science landscape helping organizations move from experimentation to production. Much of my work focuses on making generative AI models more knowledgeable and reliable by grounding them in domain-specific data, mission context, and real operational constraints across national security, research, and healthcare.
Today, as an AI Solutions Advisor at Red Hat and IBM, I partner with government agencies, research institutions, and enterprises across North America to design scalable GenAI systems that work in the real world. The goal is never novelty — it’s better decisions, faster execution, and durable advantage.

O'Neill Joseph is a Sr AI Solutions Architect in Red Hat focused on specialized AI deployments, has over 20 experience in IT Infrastructure, from telecommunications to cloud native infrastructure with a Degree in Cybersecurity and IT Networking from University of Maryland.

Working with customers to build IT solutions for over 25 years, Wes has experience integrating various technologies and approaches to produce outcomes and achieve mission objectives. Serving highly regulated industries such as healthcare and defense, Wes understands how to approach IT challenges with a secure, compliant end state in mind.
At Red Hat, Wes focuses on helping customers build cloud-native platforms where they can run AI/ML workloads, integrate heterogeneous data and facilitate outcomes anywhere in the world.
Prior to joining Red Hat, Wes was the CTO at a small technology company in DC helping build solutions for a variety of government customers.
Wes has managed global engineering teams, built services to help customers scale their missions, and designed software solutions to meet the needs of growing organizations.
Mais como este
O paradoxo agêntico e o argumento a favor da IA híbrida
Pare de gerenciar o passado e comece a construir o futuro da TI
Technically Speaking | Build a production-ready AI toolbox
Technically Speaking | Platform engineering for AI agents
Navegue por canal

Automação
Últimas novidades em automação de TI para empresas de tecnologia, equipes e ambientes

Inteligência artificial
Descubra as atualizações nas plataformas que proporcionam aos clientes executar suas cargas de trabalho de IA em qualquer ambiente

Nuvem híbrida aberta
Veja como construímos um futuro mais flexível com a nuvem híbrida

Segurança
Veja as últimas novidades sobre como reduzimos riscos em ambientes e tecnologias

Edge computing
Saiba quais são as atualizações nas plataformas que simplificam as operações na borda

Infraestrutura
Saiba o que há de mais recente na plataforma Linux empresarial líder mundial

Aplicações
Conheça nossas soluções desenvolvidas para ajudar você a superar os desafios mais complexos de aplicações
Virtualização
O futuro da virtualização empresarial para suas cargas de trabalho on-premise ou na nuvem