Confidential computing represents the next frontier in hybrid and multicloud security, offering hardware-level memory protection (data in use) through technologies such as AMD SEV and Intel TDX. However, implementing storage solutions in these environments presents unique challenges that traditional approaches can't address.
In this article, we'll explore different approaches to adding storage to Red Hat OpenShift confidential container environments, what to watch out for, and how AltaStata—a Red Hat partner—simplifies the process with encryption and protection for AI.
The challenge: Storage in confidential computing
Confidential containers (CoCo) protect the workload’s data in use, but some workloads also require storage for persistence. When adding storage to confidential containers, we need to address a number of security challenges on top of data in use, which confidential computing protects against:
- Data at rest: Files stored in cloud-encrypted storage remain accessible to anyone with bucket access
- Data in transit: Network communications need end-to-end encryption
- Compliance: GDPR, HIPAA, SOC 2, NIST RMF, AI Act, and CCPA require audit trails and version control
- Multicloud: Organizations need to maintain consistent security across diverse cloud environments and hybrid data centers
AI-specific storage security challenges
Confidential containers are emerging as a tool to protect AI models, weights, and data, especially when performing inferencing. For additional information on confidential containers for AI use cases, we recommend reading this article about the power of confidential containers on Red Hat OpenShift with NVIDIA GPUs.
In most cases, AI workloads running with confidential containers also require storage. This includes training datasets storage, AI model hub, and RAG documents storage. The key challenges are:
- Data poisoning vulnerability: According to this Google report, an attacker only needs to access 0.01% of a dataset to completely poison the model training, so securing data storage is critical
- Loss of data control: Organizations send data outside their perimeter to AI data centers and cannot control who has access to it, so we need tools that make sure the data remains private
For additional details, we recommend watching this webinar: Data Security for AI - Webinar at MIT.
The following diagram introduced by Google researchers shows data security risks at different stages of the AI model lifecycle (training, deployment, and inference):
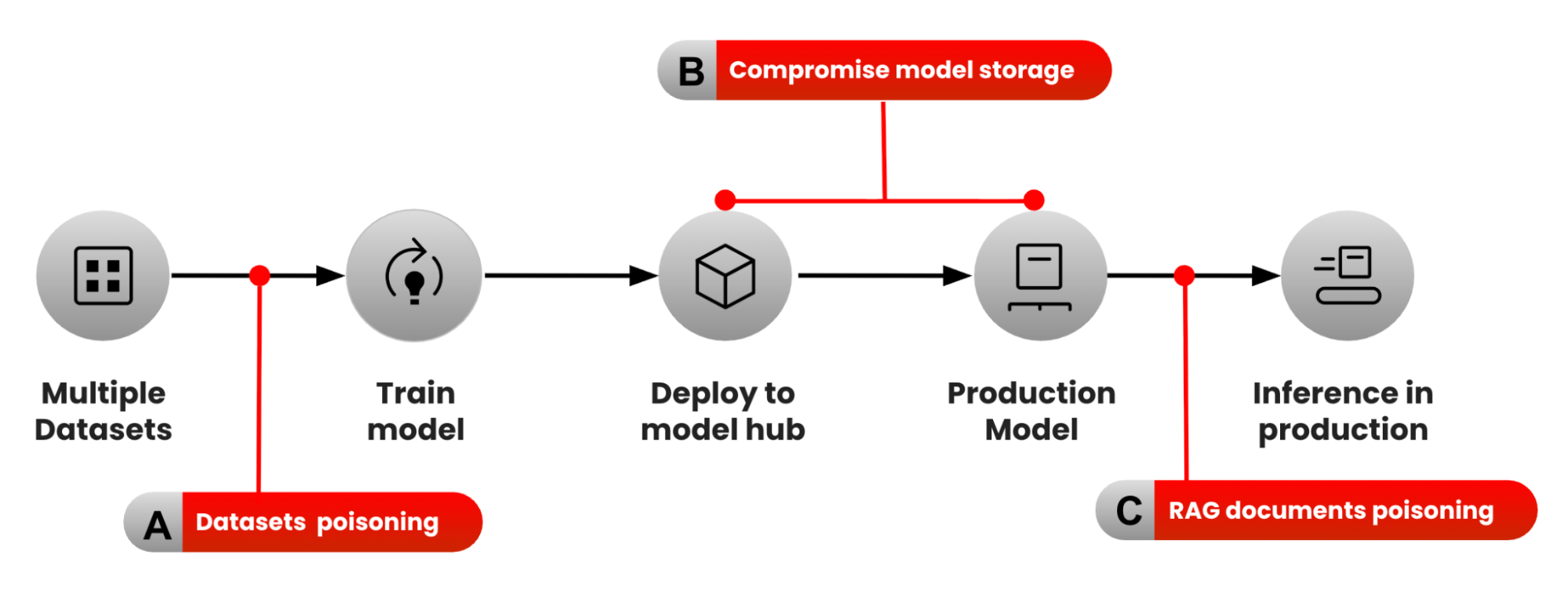
Let's dive deeper into each of the risks mentioned.
A. Training: Dataset poisoning attack
Small data corruptions in AI training datasets can have disproportionately high impacts, making even minor errors potentially life-threatening. Several attack types illustrate this risk.

Corrupted image attacks can cause self-driving car AI to confuse a stop sign with a speed limit sign, leading to dangerous outcomes. Backdoor poisoning involves subtle triggers—such as a small yellow marker in a corner invisible to humans—that activate misclassification only when present, meaning the system behaves normally until the trigger is encountered. Feature collision attacks inject subtle noise into data, causing misinterpretation—for example, a handwritten “3” with added noise might be recognized as an “8,” resulting in recognition errors. Each of these attack types demonstrates how small manipulations in training or input data can produce severe consequences for AI systems.
B. Compromising model storage: AI model replacement attack
Hugging Face is a centralized platform for hosting, sharing, and using AI models, trusted by developers and serving as a foundation for many AI projects. In a Wiz ethical hacking case study, researchers demonstrated a step-by-step attack on this ecosystem.
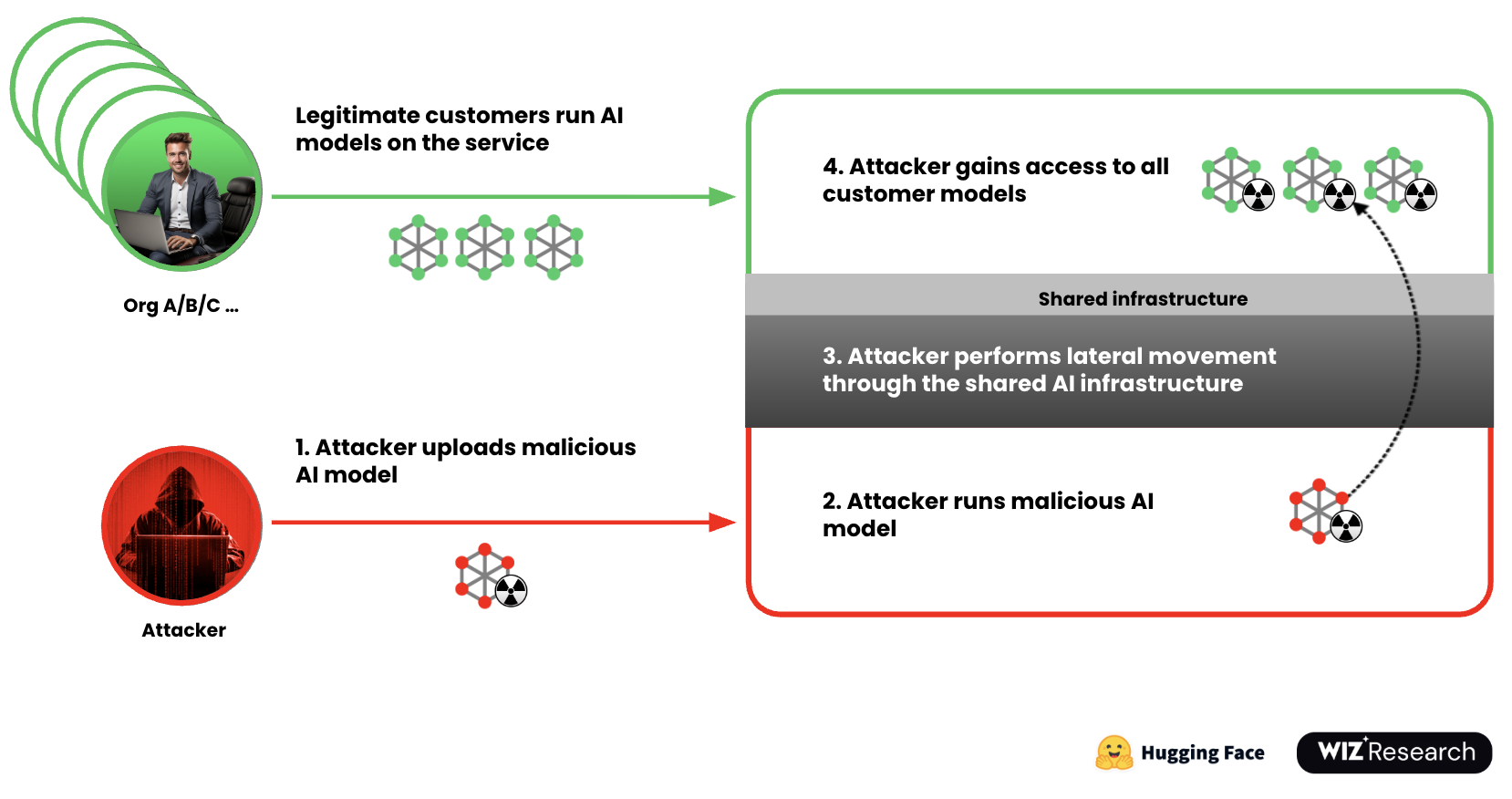
For carrying out this ethical hack, an attacker first uploaded a malicious model based on GPT‑2. Next, through prompt injection, specially crafted prompts containing executable commands were processed by the model as operating system instructions, activating a backdoor and granting administrative control. The attacker then replaced legitimate models with malicious versions. Since models are effectively black boxes, traditional scanning techniques failed to detect the compromise, and the malicious payload was able to generate harmful SQL queries and program code. Finally, the attack spread through the AI supply chain as legitimate developers downloaded the compromised models and integrated the generated code into their projects, resulting in widespread deployment of the malicious code.
C. Inference: RAG documents poisoning attack
In retrieval-augmented generation (RAG) systems, AI models rely on external documents or knowledge bases to provide context during inference. If an attacker poisons these documents, by inserting misleading, malicious, or incorrect information, the AI retrieves and incorporates this tainted context when generating responses. As a result, the model can produce inaccurate, biased, or harmful outputs, even if the underlying model itself is intact. This sort of document poisoning undermines the reliability of RAG systems by corrupting the knowledge the AI uses to reason and answer queries.
Three approaches to storage security
When looking at storage security, let us explore a few approaches
1. Cloud server-side encryption (not end-to-end)
We can use cloud server-side encryption, which secures data by encrypting it on the cloud provider’s servers after it is uploaded and before it is written to disk, protecting it “at rest” from physical theft. In most cases, the cloud provider also handles key management. This solution is not end-to-end—f a user has access to the storage, they can read or modify all files. This differs from client-side encryption, where data is encrypted on the client before upload and the keys are never exposed to the storage provider.
How it works:
- Cloud provider encrypts data at rest with the key per container
- Encryption/decryption handled by cloud infrastructure
- Simple to implement with cloud APIs
Limitations of this approach:
- ❌ Insider threats: Anyone with bucket access can read/modify all files
- ❌ No end-to-end security: Data is exposed during transferring and processing
- ❌ Vendor lock-in: Solution is tied to specific cloud provider
2. Master key end-to-end encryption
In this approach, a storage master key acts as a user-controlled key that encrypts individual files before they leave a device. This means only the key owner can decrypt them, even if the cloud provider is breached. This prevents the cloud provider or sysadmin from seeing your data, but this requires robust key management by the user. It does add true confidentiality, however, by keeping the actual data key secret from the service, shifting trust from the cloud provider to your own key security.
We can use the master key to encrypt the data end-to-end, but if the attacker has access to the key, they have access to all files. The key management and key exchange also require a proprietary approach. As the number of users and data silos in the system grows, the likelihood of data compromise increases. This approach is also not seamlessly integrated with the data science and AI tools such as PyTorch, TensorFlow, LangChain, and Databricks. Finally, the data should be entirely decrypted before being processed, which slows down the data processing.
How it works:
- Single master key encrypts all files
- File-specific keys derived from master key + file path
- Manual key management and rotation
Limitations of this approach:
- ❌ Single point of failure: Everyone with the key can access and modify any file
- ❌ Performance issues: Entire file must be decrypted before processing
- ❌ Key management complexity: Manual rotation, distribution, and storage
- ❌ Security risk scaling: More users means more attack vectors
- ❌ Multiple AI silos: More training files and RAG documents means more attack vectors
- ❌ No AI/ML integration: Not seamlessly integrated with AI tools and platforms
3. AltaStata enterprise solution
AltaStata is a data security solution for AI that implements a patented, end-to-end encryption method to create "Fortified Data Lakes." It works by protecting data with zero-trust security principles throughout the entire AI supply chain (from training to inference), without requiring users to change their existing AI applications or code. Security is applied invisibly, allowing data scientists to focus on their core tasks while AltaStata transparently handles protection in the background.
The technology is based on a U.S. patent describing an automatic key management system and a data structure that enables fast processing of encrypted data, with decryption occurring only in memory and only for the partitions currently being processed. The technology complements confidential containers, which secure the memory component—and together these enable true end-to-end security.
AltaStata is a multi-user system and supports scenarios in which, for example, a data owner shares specific files with a data scientist who runs an AI training application within a confidential container on Red Hat OpenShift AI. Unlike the previous approaches mentioned, each file is encrypted with a separate AES-GCM-256 key, providing fine-grained access control and data integrity verification. With AltaStata, users can belong to different organizations and can access only their own files and shared files in read-only mode.
The following diagram shows the AltaStata Toolkit, which enables the formation of a Fortified Data Lake on hybrid storage, such as public clouds or private AI data centers. AltaStata Toolkit includes user-friendly applications for data scientists and engineers, and SDK (Java libraries, Python package, S3 Gateway, jupyter-datascience container for Openshift AI, and more) that enables integration with prevalent data platforms.
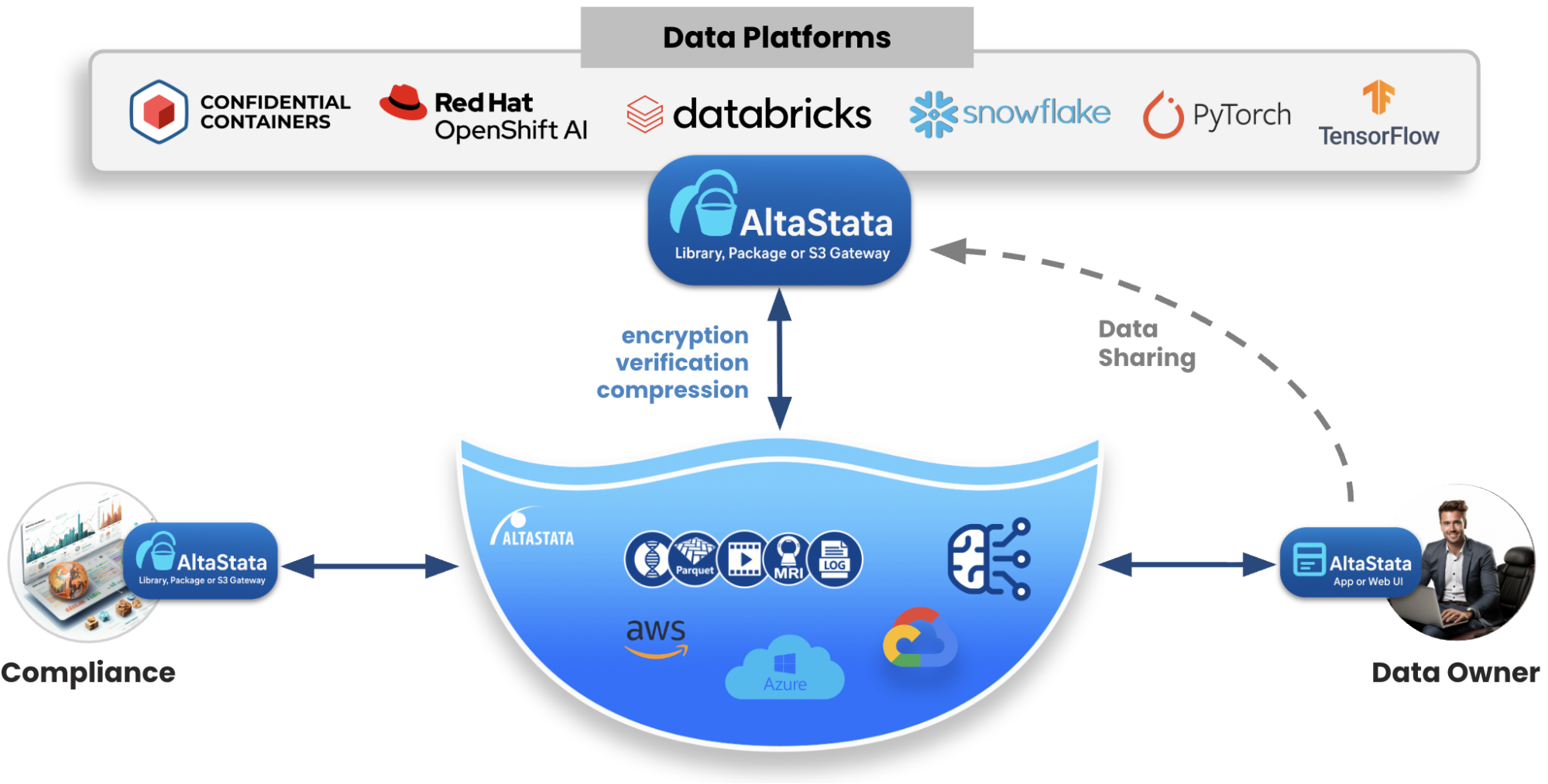
AltaStata helps organizations automatically adhere to industry standards such as GDPR, NIST RMF, and the AI Act. All sharing events and new file versions are reported to the enterprise custodian system and can be analyzed in real time for compliance.
Performance optimizations
The AltaStata data structure is optimized for fast processing, enabling decryption only of the partitions of the files that are processed at this moment, without memory spikes or performance slowdowns for large files. The data compression boosts the speed up to 3x, and also lowers storage costs of up to 63%.
Multicloud storage support for confidential containers
AltaStata works in the multicloud environment, protecting the datasets, models, and documents for RAG. You can run the confidential containers on Microsoft Azure, but store the data using Google Cloud, AWS, IBM, MinIO, or POSIX storage.
AltaStata can also support different users in different regions. For example, in Azure one user's data can be stored in Switzerland North, while another's can be stored in Germany North.
Since confidential containers target multicloud and cloud-bursting deployments, storage solutions decoupled from cloud providers fit well together.
AltaStata key advantages
- ✅ Zero-trust architecture: Protection against insider threat; Data integrity and immutability; Full access control even beyond the organization's perimeters.
- ✅ Optimization: 3x speed boost; 63% storage cost reduction with compression.
- ✅ AI/ML native: Seamless integration with Openshift AI, PyTorch, TensorFlow, LangChain, Databricks, Snowflake, and more. Data scientists can focus on their core tasks, while AltaStata handles security transparently in the background.
- ✅ Automated compliance: Built-in GDPR, HIPAA, SOC 2, CCPA, AI Act, NIST RMF support.
- ✅ Custodian: Real-time analysis of all data modifications and data sharing events
- ✅ Multicloud: You can run confidential containers on Microsoft Azure, and store data on AWS, GCP, IBM, MinIO, or POSIX. Data sovereignty is supported per region.
Security comparison
To summarize this section let us compare the 3 storage security approaches mentioned:
Feature | Cloud server-side | Master key | AltaStata |
End-to-end security | ❌ Admin access | ⚠️ Single key per dataset | ✅ Per-file encryption |
Performance | ✅ Fast | ❌ Full decryption | ✅ Selective decryption |
Seamless AI/ML aata platform integration | ✅ Native | ❌ Manual | ✅ Supporting PyTorch, TensorFlow, LangChain, Databricks, Snowflake, etc. |
Multicloud | ❌ Vendor lock-in | ✅ Unified | ✅ Unified |
Key management | ❌ Cloud dependent | ❌ Manual | ✅ Automatic |
Data integrity | ❌ No protection | ❌ Any user can replace any file | ✅ built-in data verification |
Cost optimization | ❌ No optimization | ❌ No optimization | ✅ 63% cost reduction |
Integration with confidential containers
The following diagram shows a typical deployment of OpenShift AI with confidential containers:
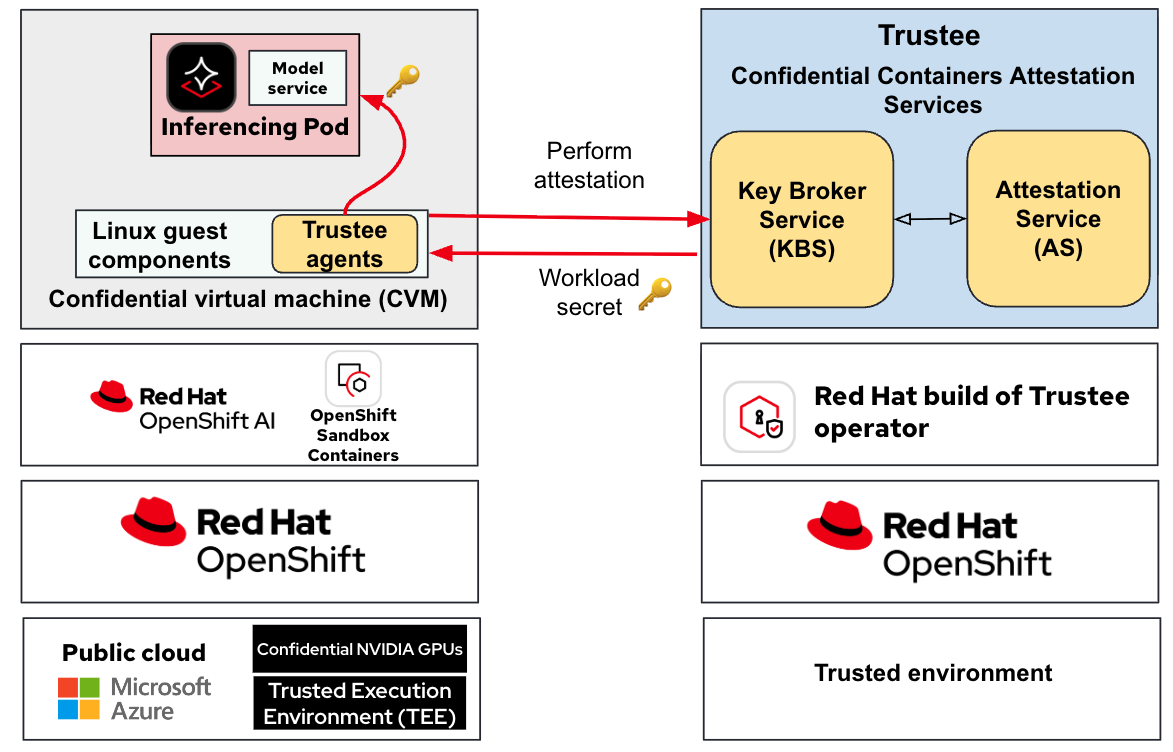
The deployment consists of a cluster running in a public cloud that supports confidential computing (such as Microsoft Azure), where confidential inference pods are created on confidential virtual machines (the left OpenShift cluster in the diagram above). Another cluster runs in a “trusted environment" (the right OpenShift cluster in the diagram above) where the attestation and key management services run.
Confidential containers integrate trusted execution environments (TEE) infrastructure with the cloud-native world. A TEE is at the heart of a confidential computing solution. TEEs are isolated environments with enhanced security (e.g., runtime memory encryption and integrity protection), provided by hardware capable of confidential computing. A special virtual machine (VM) called a confidential virtual machine (CVM) that executes inside the TEE is the foundation for OpenShift confidential containers solution. For additional information on how this solution works, we recommend reading, Exploring the OpenShift confidential containers solution.
For additional information on confidential containers for AI use cases, we recommend reading, AI meets security: POC to run workloads in confidential containers using NVIDIA accelerated computing. For further information on the attestation solution, we recommend reading, Introducing Confidential Containers Trustee: Attestation Services Solution Overview and Use Cases.
AltaStata and confidential containers for AI workloads
Confidential containers and AltaStata together provide end-to-end protection for AI data pipelines—securing data at rest, in transit, and in use. Since AltaStata decrypts data only at the final endpoint (the application or AI agent) that runs within the TEE, the data itself is shielded from the underlying infrastructure, host operating system, and unauthorized administrators. This means there is no single point of vulnerability throughout the entire pipeline.
AltaStata relies on user credentials to access cloud or private storage and on cryptographic keys to encrypt and decrypt data, so these secrets must be securely stored and protected from the infrastructure admins. Within this architecture, AltaStata leverages confidential containers sealed secrets to provide this sensitive information to the container at runtime.This injection occurs only after a successful remote attestation verifies the integrity and trustworthiness of the environment. The “sealed-secrets” functionality simplifies deploying Kubernetes workloads as confidential containers. A sealed secret is an encapsulated secret accessible only within a TEE after verifying the integrity of the TEE environment. Using a sealed secret is the same as using any other Kubernetes secret.
In the following diagram, we show how AltaStata’s secure storage can be used to provide confidential containers with secure storage:

The following steps are performed in the diagram above
- The inferencing pod performs an attestation transaction with Trustee
- Upon successful attestation, Trustee provides the inference pod with the user storage access information and decryption keys
- Using the user storage access information (from step 2), the inferencing pod application leverages the AltaStata Toolkit to securely retrieve encrypted data from the data lake
- Using the decryption key (from step 2), the inference pod application leverages the AltaStata Toolkit to decrypt the encrypted data
Real-world examples
Securing PyTorch model training example
The goal of our first case study is to demonstrate an architecture that enables a Data Partner to upload a dataset outside the organization’s perimeter while retaining control over each file and securely sharing it with a Data Scientist who runs the model training and inference. The combination of CoCo and AltaStata prevents training data poisoning and model replacement, and maintains data integrity and immutability throughout training and inference.
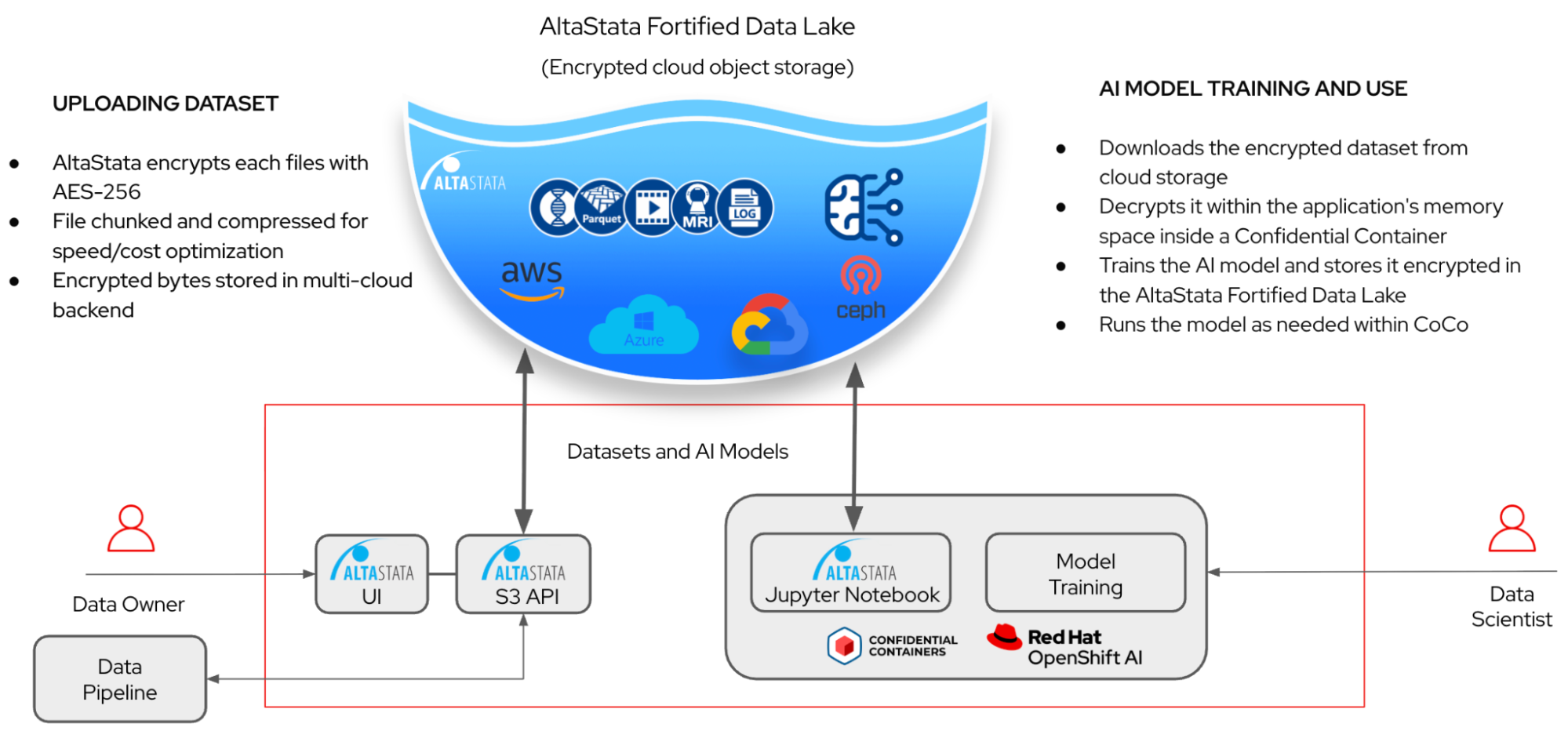
Architecture flow:
The Data Partner (Alice) uses the AltaStata UI application to ingest encrypted training data into AWS object storage and shares access to the training dataset with the Data Scientist. The Data Scientist (Bob) then initiates ML model training within a confidential container running at Azure, which accesses the dataset via the AltaStata custom PyTorch Dataset class. Once the model is trained, it is saved to AWS in encrypted form. Model inference is also performed inside the confidential container, with end-to-end protection provided by CoCo and AltaStata.

Key features demonstrated:
- Multicloud deployment: Training on Azure Confidential Container while data is on AWS
- Seamless integration: Custom AltaStataPyTorchDataset class
- Provenance tracking: Automatic audit trail of training data
The following YouTube shows this demo in practice:
For this video, we used the AltaStata Jupyter Data Science container, deployed to CoCo. It is based on the Red Hat Jupyter Data Science image. Under the hood, it provides a ready-to-use environment with AltaStata pre-installed from PyPI (https://pypi.org/project/altastata/) for protected data science workflows.
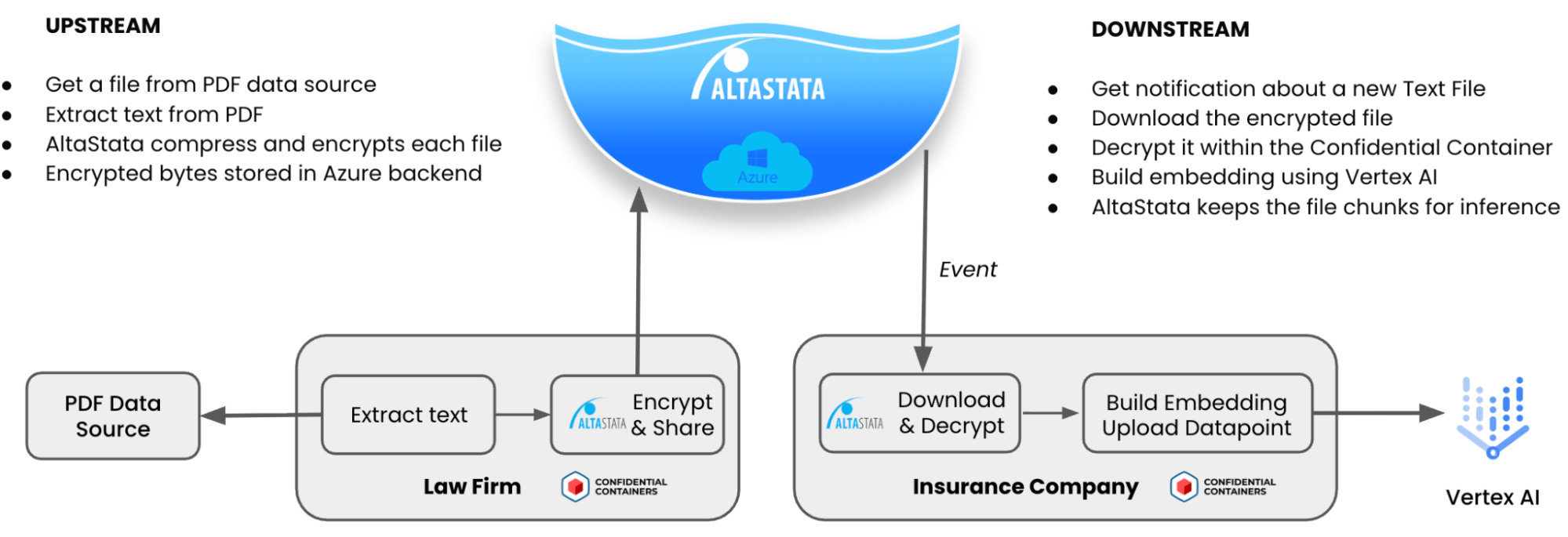
Protecting RAG pipeline example
The goal of our second case study is to demonstrate how partner organizations can collaborate via AltaStata for AI supply chain while each runs a confidential container in its own cloud environment. In this example, a law firm securely sends policies and other documents to an insurance company, which indexes them in Vertex AI and are utilized by a chatbot to augment RAG requests with relevant information. That is, with RAG, when an insurance company user asks the chatbot a question, the system "retrieves" relevant chunks from those legal documents provided by the law firm.
AltaStata integrates with LangChain, an open source framework used to build and deploy reliable AI agents for our pilot. Using AltaStata protects raw documents and data chunks from end-to-end, preventing poisoning or breaches in production. It enables automatic data protection for partner collaboration and AI supply chains, eliminating the need for VPNs or tenant isolation. Key benefits include encrypted storage, secure messaging, event logging, and multifactor authentication, along with real-time ingestion of encrypted data, immutability, and significant cost savings from data compression and zero duplication.
For document ingestion and indexing, we simulated 2 data pipelines in a multicloud environment. Each pipeline executes inside a confidential container , while all data is stored in Azure object storage protected by AltaStata. Using the first confidential container, the law firm AI agent encrypts and uploads raw documents to AltaStata, which then notifies the insurance company. The insurance company’s AI agent, isolated within a second confidential container, receives the references to the documents, transforms the documents into chunks and embeddings, and integrates them into Vertex AI to power RAG-based inference.
Users then interact with a chatbot application also running in a confidential container, which retrieves the most relevant chunks from AltaStata for RAG (see the architecture flow).
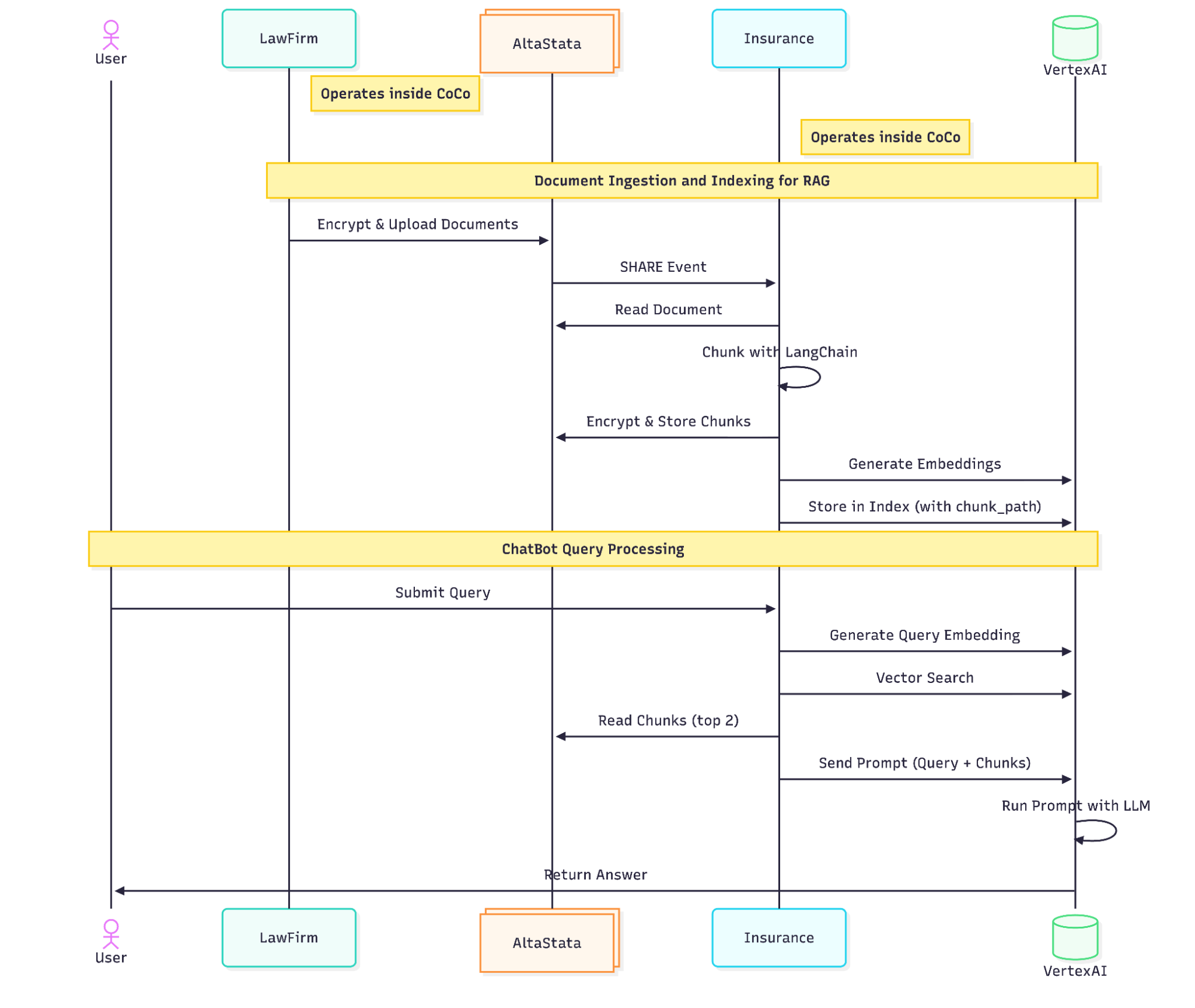
Key features demonstrated:
- Event-driven architecture: Automatically encrypted document sharing between the partner organizations
- Data integrity: Immutable versions prevent tampering
- Audit compliance: Automatic monitoring for regulations
- Zero breach: Documents are protected with end-to-end encryption during storage, transferring, and processing
Conclusion
Integrating storage into confidential computing environments demands a balance of security, performance, and compliance. The combination of AltaStata's encrypted storage solution and Red Hat OpenShift’s confidential computing capabilities delivers a straightforward, integrated approach to meeting these requirements.
For organizations requiring the highest levels of security in confidential computing environments, AltaStata provides the most comprehensive solution with built-in compliance, multicloud support, and enterprise-grade encryption.
Ready to secure your confidential container storage? Get started with AltaStata today.
Red Hat Product Security
Sobre os autores

Serge Vilvovsky is the founder of AltaStata, a company that provides a unique, patented, quantum-safe encryption approach to data security for AI. He spent eight years at MIT Lincoln Laboratory, conducting cybersecurity research funded by the DoD. Before that, Serge worked for several companies in the U.S. and Israel, including Sun Microsystems, Cisco, and multiple startups. Most recently, he led the cloud security risk group at Capital One. Serge has been a guest speaker at MIT cybersecurity classes for decision makers and conferences.


Pradipta is working in the area of confidential containers to enhance the privacy and security of container workloads running in the public cloud. He is one of the project maintainers of the CNCF confidential containers project.


Axel is a Chief Architect for Red Hat FSI in Germany. After obtaining his business administration degree in Kiel, Germany, Axel worked as a consultant for mainframe development strategy and tools. He then moved on to IBM, working in presales for 16 years, serving in different IT architecture-centered roles, and working primarily with Financial Institutions.
Mais como este
MCP security: Implementing robust authentication and authorization
AI trust through open collaboration: A new chapter for responsible innovation
Post-quantum Cryptography | Compiler
Understanding AI Security Frameworks | Compiler
Navegue por canal

Automação
Últimas novidades em automação de TI para empresas de tecnologia, equipes e ambientes

Inteligência artificial
Descubra as atualizações nas plataformas que proporcionam aos clientes executar suas cargas de trabalho de IA em qualquer ambiente

Nuvem híbrida aberta
Veja como construímos um futuro mais flexível com a nuvem híbrida

Segurança
Veja as últimas novidades sobre como reduzimos riscos em ambientes e tecnologias

Edge computing
Saiba quais são as atualizações nas plataformas que simplificam as operações na borda

Infraestrutura
Saiba o que há de mais recente na plataforma Linux empresarial líder mundial

Aplicações
Conheça nossas soluções desenvolvidas para ajudar você a superar os desafios mais complexos de aplicações
Virtualização
O futuro da virtualização empresarial para suas cargas de trabalho on-premise ou na nuvem