


As the usage of artificial intelligence (AI) workloads in the industry is becoming ubiquitous, the risks of using AI models are also increasing, with new unauthorized personas potentially accessing those models. AI models are now the new key for organizations requiring large investments in training and inferencing, which largely rely on accelerated computing (GPUs).
When we talk about protecting those models in Kubernetes environments, we look at protecting data in rest (storage), data in transit (networking), and data in use. Our focus here will be on data in use by leveraging confidential computing. Specifically, we will be looking at what we see as the future of confidential computing, and how confidential containers can be used as a tool to protect the AI models, both for training and inferencing, while utilizing powerful and performant GPU acceleration to protect workloads.
Confidential containers with GPU acceleration provide a path forward for regulated industries such as banking, financial services, insurance, healthcare and government, which have traditionally been limited to on premises deployments due to stringent regulatory and compliance requirements.
The confidential computing capability was added to the NVIDIA Hopper architecture, which will also be available in upcoming Blackwell GPUs. While the integration of the NVIDIA GPUs with Kubernetes is an ongoing effort, this blog presents a proof-of-concept integrating NVIDIA GPUs with Kubernetes services like Red Hat OpenShift, the stack demonstrating how organizations can transition from traditional to confidential, accelerated workloads. We’ll explore use cases for protecting Red Hat OpenShift AI models with Red Hat confidential containers and dive into a specific example of using confidential containers for model inferencing.
For the scope of this blog, the usage of NVIDIA GPUs with confidential computing is limited to the use of a CVM as the infrastructure to leverage accelerated computing capabilities.
Red Hat OpenShift confidential containers
Red Hat OpenShift sandboxed containers, built on Kata Containers, have been designed with the capability to run confidential containers (CoCo). The idea is to deploy containers within an isolated hardware enclave protecting data and code from privileged users such as cloud or cluster administrators. The CNCF confidential containers project is the foundation for the Red Hat OpenShift CoCo solution.
Confidential computing helps protect your data in use by leveraging dedicated hardware-based solutions. Using hardware, you can create isolated environments that you own and help protect against unauthorized access or changes to your workload's data while it’s being executed.
Confidential containers enable cloud native confidential computing using several hardware platforms and supporting technologies. CoCo aims to standardize confidential computing at the pod level and simplify its consumption in Kubernetes environments. By doing so, Kubernetes users can deploy CoCo workloads using their familiar workflows and tools without a deep understanding of the underlying confidential container technologies.
TEEs, attestation and secret management
CoCo integrates trusted execution environments (TEE) infrastructure with the cloud native world. A TEE is at the heart of a confidential computing solution. TEEs are isolated environments with enhanced security (e.g. runtime memory encryption, integrity protection), provided by confidential computing-capable hardware. A special virtual machine (VM) called a confidential virtual machine (CVM) that executes inside the TEE is the foundation for the Red Hat OpenShift CoCo solution.
When you create a CoCo workload, a CVM is created and the workload is deployed inside the CVM. The CVM prevents anyone who isn’t the workload's rightful owner from accessing or even viewing what happens inside it.
Attestation is the process used to verify that a TEE, where the workload will run or where you want to send confidential information, is trusted. The combination of TEEs and attestation capability enables the CoCo solution to provide a trusted environment to run workloads and enforce the protection of code and data from unauthorized access by privileged entities.
In the CoCo solution, the Trustee project provides the capability of attestation. It’s responsible for performing the attestation operations and delivering secrets after successful attestation.
Deploying confidential containers through operators
The Red Hat confidential containers solution is based on two key operators:
- Red Hat OpenShift confidential containers: A feature added to the Red Hat OpenShift sandbox containers operator that is responsible for deploying the building blocks for connecting workloads (pods) and CVMs that run inside the TEE provided by hardware.
- Confidential compute attestation operator: Responsible for deploying and managing the Trustee service in a Red Hat OpenShift cluster.
For additional information on this solution, we recommend reading Exploring the Red Hat OpenShift confidential containers solution.
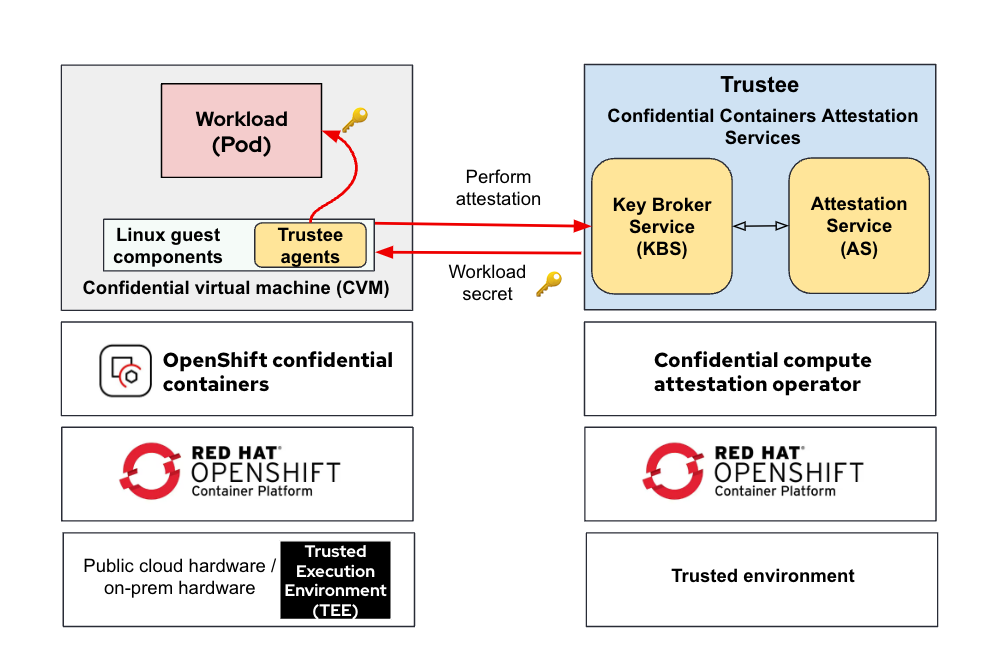
Red Hat confidential containers solution deployed by two operators
Use cases for confidential containers
- Secrets retrieval by the workload: A workload requires secrets to perform different operations, such as decrypting an encrypted large language model (LLM) file. The workload will decrypt the data inside the TEE using the decryption key received after attestation.
- Verifying signed container images: Verifying a container image's signature before launching is necessary to ensure the image has not been tampered with and contains the intended binaries.
Running an encrypted container image: Using an encrypted container image to prevent unauthorized access to the image contents. In contrast to the previous signed image use case, the concerns shifted from someone tampering with our container image to someone viewing the content of the container's image.

The Linux guest components initiate an attestation sequence via the Trustee agents running in the VM TEE (CVM) to confirm the TEE's trustworthiness and obtain the container image signing key.
For additional information on the previously mentioned use cases, trustee components and more, we recommend reading Use cases and ecosystem for Red Hat OpenShift confidential containers.
Red Hat OpenShift AI and Red Hat OpenShift confidential containers
The Red Hat OpenShift AI operator
The Red Hat OpenShift AI operator lets developers perform both the training and inferencing phases with Red Hat OpenShift. Training and development use notebooks or pipelines, while inferencing is performed via model serving.
The Red Hat OpenShift AI operator also offers a variety of models and development environments to develop an AI model, including the Text Generation Inference Service (TGIS) toolkit.
In a typical flow, we have three phases: develop and train, model uploading and inference.
Phase 1: Develop and train
Developing and training in Red Hat Openshift AI is performed via workbenches, which offer the data scientist all the tools and libraries to implement and also train an AI model automatically with pipelines.
The training part is usually performed with the help of what Red Hat OpenShift AI calls accelerators, which for the most common use cases are GPUs.
Phase 2: Model uploading
Once the model is ready and trained, we must store it somewhere. Red Hat OpenShift AI offers data connections, which provide a very intuitive way to connect workbenches with S3 storage providers.
Phase 3: Inference
The model is then deployed and ready to be used and available in the outside world. Red Hat OpenShift AI offers model servers that automatically connect the designated data connection with the pod running the model, which then automatically downloads the model binary from the S3 bucket and runs it locally.
In this phase, the model is exposed to new data and tries to produce valuable results based on its implementation and training. Inference also requires accelerators, especially when running LLMs.
Running Red Hat OpenShift AI workloads with confidential containers
Red Hat OpenShift AI already leverages Red Hat OpenShift features to support data at rest and in transit. For example, the model data could be provided as encrypted storage or model uploading/downloading can be done through encrypted network connections. But what about the data being processed while training or inference? Both these datasets could contain real customer user data. In training, we want to provide the best examples to make the model learn the exact use case, whether it’s through retrieval-augmented generation (RAG) or training from scratch, while when performing inference, the data is always coming from the user input.
Given the standard scenario above, we identify the following attacker: A malicious infrastructure or cluster administrator can access or alter the model parameters and related data without proper authorization. For instance, they could access the memory of the worker node and get access to the data, like the credit card transactions or queries performed to the model, or the model parameters.
The reason for using confidential containers is to protect the model from any external entity while it's in use.
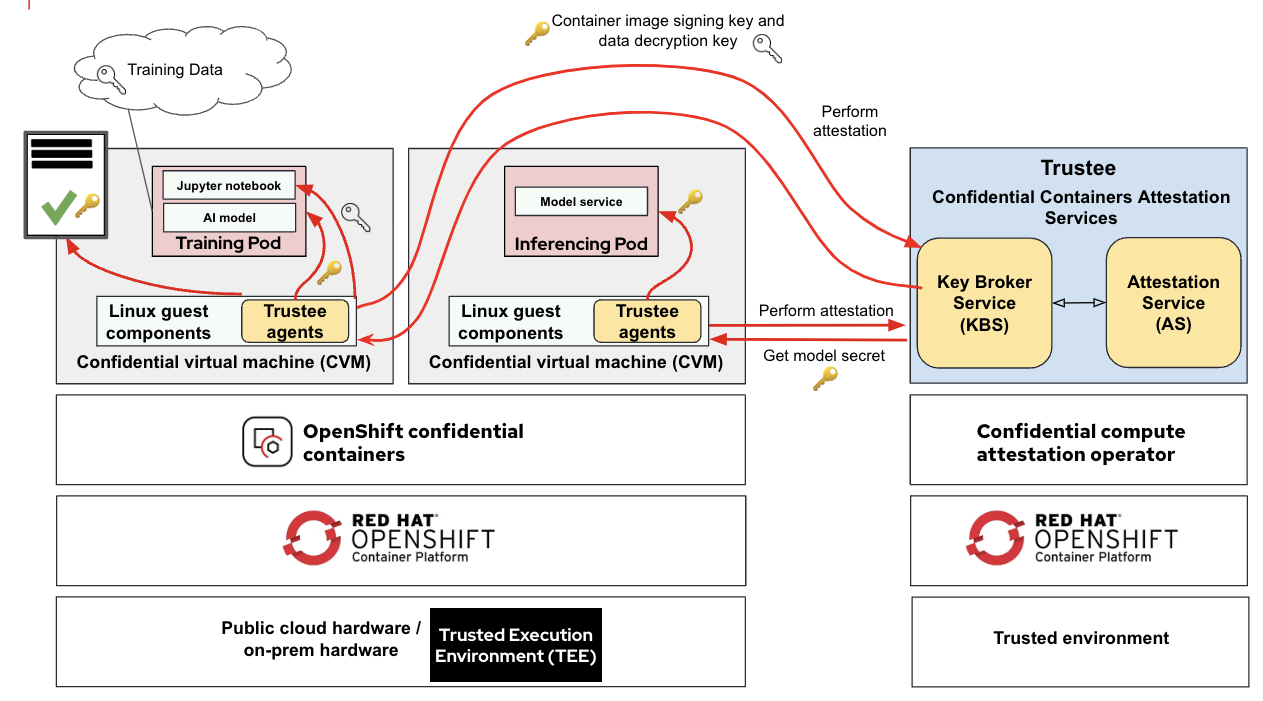
In the above diagram, we can notice the following similarities between the two model phases.
- Both phases are run as separate confidential containers. Each container runs in a confidential VM supported by the hardware TEE.
- The underneath platform for the CoCo pods could be public cloud as well on-prem deployments.
- The confidential compute attestation operator, working as attester and secret key provider, runs in a separate, secure environment. In this example, it ran in a Red Hat OpenShift cluster located in a trusted environment.
- Both confidential containers leverage the confidential compute attestation operator to attest the confidential virtual machine stack (hardware and software) to make sure nothing was altered by a malicious platform or administrator.
- The container image used in both confidential containers is signed. The goal is to make sure that nobody is able to tamper the training or inference code, nor be able to modify it. The key to verify the signed container image is provided by the attestation operator, but only if attestation is successful.
- Both container images need a workload secret: for training, the decryption key for the dataset (if it's encrypted), for inference, the decryption key for the trained model. The keys to decrypt either the data or the model are different and again provided by the attestation operator only if attestation is successful.
Secured AI workloads: confidential containers and confidential GPU
Combining CPU and GPU attestation
GPUs are essential to run AI workloads, whether the goal is training or inference. NVIDIA H100 Tensor Core GPUs have confidential computing acceleration built into the hardware and when integrated with platforms like Red Hat OpenShift confidential AI, workloads present a potential for significant boosts to the model performance. Additionally, there is support for all varieties of model sizes when compared with traditional CC-enabled HPC offerings.
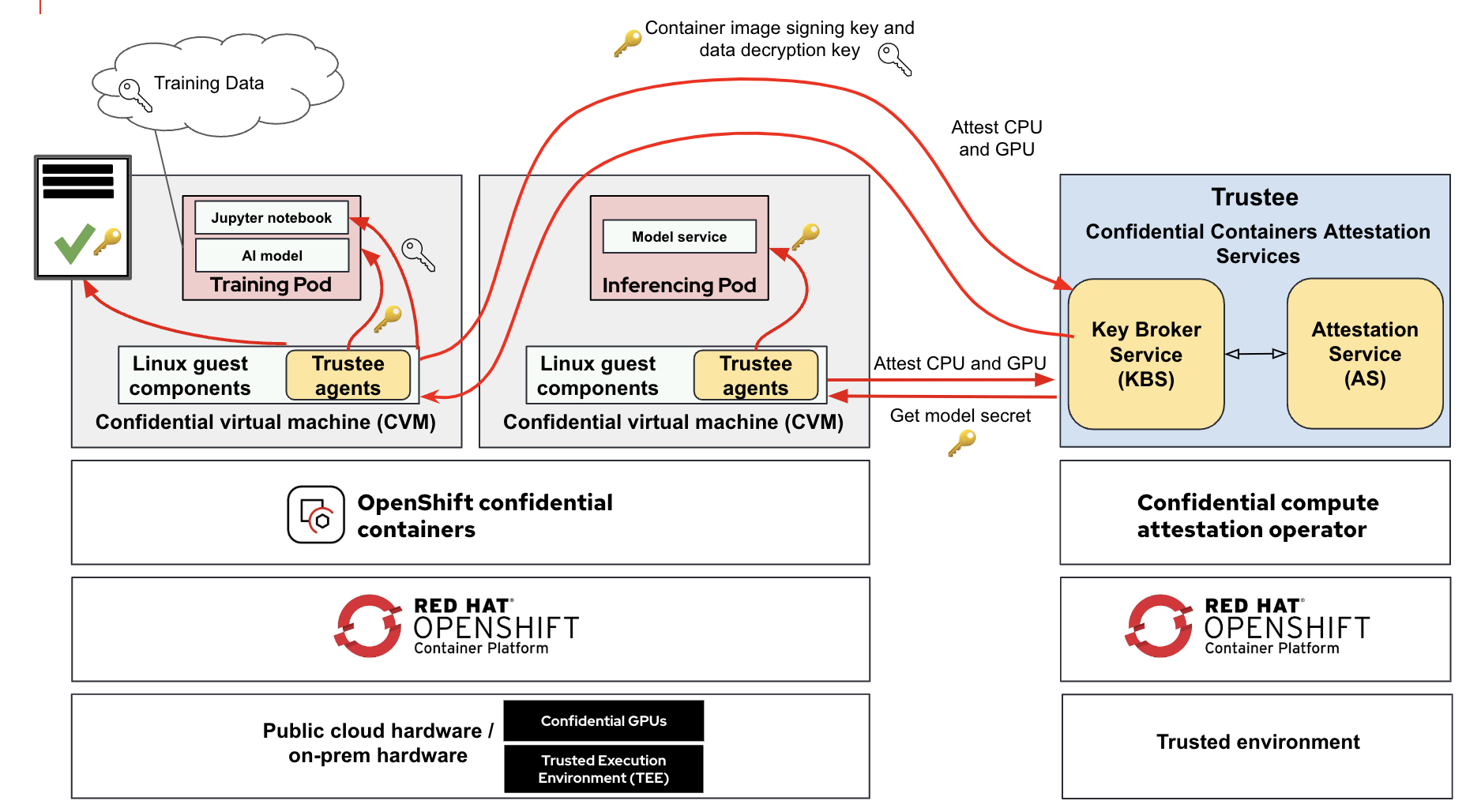
The following images show Red Hat OpenShift AI training and inferencing pods in confidential containers running inside a CVM with access to NVIDIA H100 Tensor Core GPUs.
The main difference here is that the confidential compute attestation operator would only provide the secret to the confidential container if attestation on the hardware (CPUs and GPUs) and software (confidential VM, guest components, and agents) is successful.
Confidential containers and confidential GPUs for inferencing
Why inferencing? We believe that this is the most important phase in a model lifecycle. Inference means handling new, real user data. On the other hand, training could also be performed with synthetic data, or a generic dataset available online, and only enhanced with advanced techniques like RAG to fine tune the model with customer use case data that could be run in a smaller, trusted environment. Inference usually requires a lot of resources, with the help of GPUs and various accelerators, and almost always handles sensitive data.
For the inferencing pod, our focus is on secrets retrieval by the workload. It should be noted that in a typical deployment we would have both the confidential container image signed and the model itself. Thus, such a flow would include:
- Performing attestation for obtaining a key to sign the container image (running the inferencing pod)
- Perform attestation for obtaining another key to decrypt the model itself
In order to simplify the flow, we only focus on the key for decrypting the model:

Please note,
- Using Red Hat OpenShift confidential containers, the inference pod runs in a confidential container supported by hardware TEE and NVIDIA GPUs with confidential computing.
- The underneath platform for the CoCo pods could be public cloud as well on-prem deployments.
- The confidential compute attestation operator, working as attester and secret key provider, runs in a separate, secure environment. In this example, it ran in a Red HatOpenShift cluster located in a trusted environment.
- The inference pod contains an encrypted model. The key to decrypt the model is securely stored in the attestation operator.
- The attestation operator provides the key only if attestation on the hardware (CPUs and GPUs) and software (confidential VM, guest components and agents) is successful.
Use case in practice: LLMs with confidential GPUs
In this example, we will run a standard Hugging Face LLM on a confidential container deployed through Red Hat OpenShift AI, with the support of the Red Hat OpenShift sandboxed containers operator.
The platform used for this demo leverages CVM on Azure with NVIDIA H100 GPUs. Through the demo, we will see how a confidential container running as a Red Hat OpenShift AI model server (therefore covering the inference phase) first attests its environment (CPUs and GPUs) and then decrypts the model using the key provided by the attestation operator, running in a separate trusted cluster.
The GPU-equipped confidential model is then tested and compared against a traditional CPU-only based Red Hat OpenShift AI model, showing the huge performance difference between the two.
Please look out for future blog posts that will explore the attestation process for confidential computing on NVIDIA Tensor Core GPUs and how it connects to attestation flows for CPUs.
About the authors
Emanuele Giuseppe Esposito is a Software Engineer at Red Hat, with focus on Confidential Computing, QEMU and KVM. He joined Red Hat in 2021, right after getting a Master Degree in CS at ETH Zürich. Emanuele is passionate about the whole virtualization stack, ranging from Openshift Sandboxed Containers to low-level features in QEMU and KVM.
Pradipta is working in the area of confidential containers to enhance the privacy and security of container workloads running in the public cloud. He is one of the project maintainers of the CNCF confidential containers project.
More like this
BackendTLSPolicy expands Gateway API transport security
The evolution of infrastructure automation in the age of AI: 4 key takeaways from Red Hat Summit 2026
Technically Speaking | Defining sovereign AI with open source
Technically Speaking | Inside open source AI strategy
Browse by channel

Automation
The latest on IT automation for tech, teams, and environments

Artificial intelligence
Updates on the platforms that free customers to run AI workloads anywhere

Open hybrid cloud
Explore how we build a more flexible future with hybrid cloud

Security
The latest on how we reduce risks across environments and technologies

Edge computing
Updates on the platforms that simplify operations at the edge

Infrastructure
The latest on the world’s leading enterprise Linux platform

Applications
Inside our solutions to the toughest application challenges
Virtualization
The future of enterprise virtualization for your workloads on-premise or across clouds