
Did you ever feel like you have too much storage?
Probably not - there is no such thing as ‘too much storage’. For a long time, we have used userland tools like gzip and rar for compression. Now with Virtual Data Optimizer (VDO), all required pieces for a transparent compression/deduplication layer are available in the just-released Red Hat Enterprise Linux 7.5. With this technology, it is possible to trade CPU/RAM resources for disk space. VDO becoming available is one of the results of Red Hat acquiring Permabit Technology Corporation in 2017. The code is available in the source RPMs, and upstream projects are getting established.
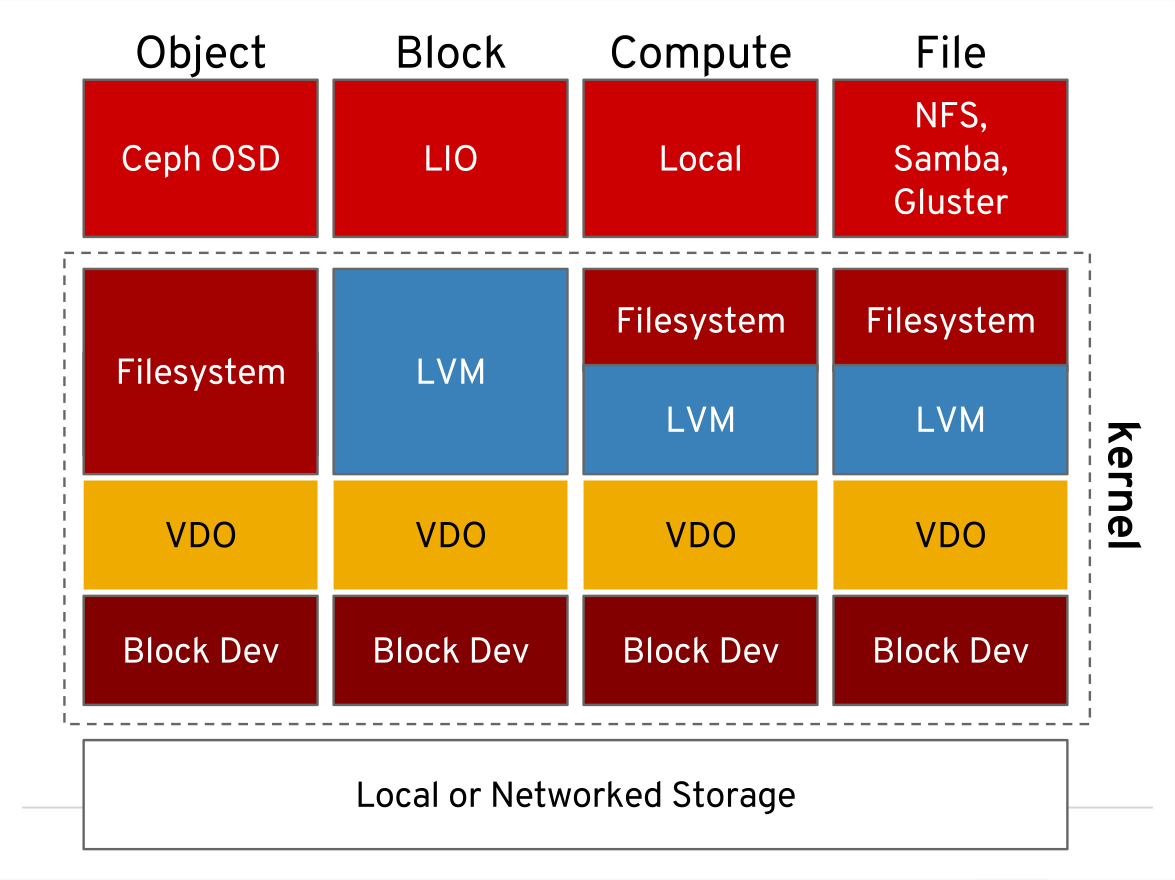
Regarding use cases, VDO can, for example, be used under local filesystems, iSCSI or Ceph. File servers can use it as base for local filesystems, and hand out NFS, CIFS or Gluster services. Remember dozens of Linux systems sharing read-only NFS root file systems to save storage? You could now give each of these systems its own individual image via iSCSI, stored on a common file system with VDO backend, and have VDO deduplicate and compress the common parts of these images.
When reading about VDO appearing in the Red Hat Enterprise Linux 7.5 beta, I wondered about the following:
-
How to setup and configure VDO?
-
How is VDO influencing read/write performance?
-
How much storage space can I save for my use cases?
Let’s find out!
How to setup and configure VDO?
The authoritative resource regarding VDO is the Storage Administration Guide. With Red Hat Enterprise Linux 7.5 repos available, it can be installed using:
[root@rhel7u5a ~]# yum install vdo kmod-kvdo
When configuring VDO, various things have to be taken into consideration. The smallest system I used here is a KVM guest with 2GB of RAM. While sufficient for first tests, for production one should obey the sizing recommendations in the Storage Administration Guide. They depend on the size of the storage below your VDO devices. Attention should also be paid to the order of layers: placing VDO below encryption, for example, makes no sense.
Assuming a disk available as /dev/sdc, we can use the following command to create a VDO device on top. For a 10GB disk, depending on the workload, one could decide to have VDO offer 100GB to the upper layers:
[root@rhel7u5a ~]# vdo create --name=vdoasync --device=/dev/sdc \ --vdoLogicalSize=100G --writePolicy=async Creating VDO vdoasync Starting VDO vdoasync Starting compression on VDO vdoasync VDO instance 0 volume is ready at /dev/mapper/vdoasync [root@rhel7u5a ~]#
After creating a filesystem using ‘mkfs.xfs -K /dev/mapper/vdoasync’, the device can be mounted to /mnt/vdoasync.
VDO supports three write modes.
-
The ‘sync’ mode, where writes to the VDO device are acknowledged when the underlying storage has written the data permanently.
-
The ‘async’ mode, where writes are acknowledged before being written to persistent storage. In this mode, VDO is also obeying flush requests from the layers above. So even in async mode it can safely deal with your data - equivalent to other devices with volatile write back caches. This is the right mode, if your storage itself is reporting writes as ‘done’ when they are not guaranteed to be written.
-
The ‘auto’ mode, now the default, which selects async or sync write policy based on the capabilities of the underlying storage.
Sync mode commits the data out to media before trying to either identify duplicates or pack the compressed version with other compressed blocks on media. This means sync mode will always be slower on sequential writes, even if reads are much faster than writes. However, sync mode introduces less latency, so random IO situations can be much faster. Sync mode should never be used in production without backed storage (typically using batteries or capacitors) designed for this use case.
Using ‘auto’ to select the mode is recommended for users. The Storage Admin Guide has further details regarding the write modes.
How is VDO influencing read/write performance?
So if we put the VDO layer between a file system and a block device, how will it influence the I/O performance for the filesystem?
The following data was collected using spinning disks as backend, on a system with 32 GB RAM and 12 cores at 2.4Ghz.
Column ‘deploy to file system’ shows the time it took to copy a directory with ~5GB of data from RAM (/dev/shm) to the filesystem. Column ‘copy on file system’ shows the time required to make a single copy of the 5GB directory which was deployed in the first step. The time was averaged over multiple runs, always after removing the data and emptying the file system caches. Publicly available texts from the Project Gutenberg were used as data, quite nicely compressible.
|
filesystem backend |
deploy to file system |
copy on file system |
|
XFS ontop of normal LVM volume |
28sec |
35sec |
|
XFS on VDO device, async mode |
55sec |
58sec |
|
XFS on VDO device, sync mode |
71sec |
92sec |
Deployment to VDO backend is slower than to plain LVM backend.
I was initially wondering whether copies on top of a VDO backed volume would be faster than copies on top of a LVM volume - they are not. When data on a VDO backed file system is copied, for example with ‘cp’, then the copy is by definition a duplicate. After VDO identifies this as candidate for duplicate data, it does a read comparison to be sure.
When using SSD or NVDIMM as backend, extra tuning should be done. VDO is designed to properly deal with many parallel I/O requests in mind. In my tests here I did not optimize for parallelization, I just used single instances of ‘rsync’, ‘tar’ or ‘cp’. Also for these, VDO can break up requests from applications to write big files into many small requests - if the underlying media is, for example, a high-speed NVMe SSD, then this can help performance.
Something good to know for testing: I noticed GNU tar reading data incredibly fast when writing to /dev/null. Turns out that ‘tar’ is detecting this situation and not reading at all. So ‘tar cf /dev/null /usr’ is not doing what you probably expect, but ‘tar cf - /usr|cat >/dev/null’ is.
How much storage space can I save for my use cases?
This depends of course on how compressible your data is - creating a test setup and storing your data directly on VDO is a good way to find out. You can also to some degree decide how many cpu/memory resources you want to invest and tune for your use case: deduplication and compression can be enabled separately for VDO volumes.
VDO reserves 3-4GB of space for itself: using a 30GB block device as the VDO backend, you can use around 26GB to store your real data, so not what, for example, the filesystem above stores, but what VDO after deduplication/compression needs to store. The high overhead here is the result of the relatively small size of the device. On larger (multi-TB) devices, VDO is designed to not incur more than 2% overhead.
VDO devices can, and should use thin provisioning: this way the system reports more available space to applications than the backend actually has. Doing this, you can benefit from compression and deduplication. Like LVM volumes, VDO devices can after initial creation be grown on-the-fly.
The best data for monitoring the actual fillstate is from ‘vdostats --verbose’, for example for a 30GB volume:
[root@rhel7u5a ~]# vdostats --verbose /dev/mapper/vdoasync |grep -B6 'saving percent' physical blocks : 7864320 logical blocks : 78643200 1K-blocks : 31457280 1K-blocks used : 17023768 1K-blocks available : 14433512 used percent : 54 saving percent : 5
So this volume is 54% full. This is a thin provisioned volume with 30GB backend, so 7864320 blocks of 4k size. We show ten times of that to the upper layers, so 300GB, here appearing as ‘logical blocks’.
As we are dealing with compression/deduplication here, having a 30GB backend does not mean that you can only store 30GB: if your data can be nicely deduplicated/compressed, you can store much more. Above output of ‘vdostats’ is from a volume with 13GB of data. After making a copy of that data on the volume, ‘df’ shows 26GB of data on the filesystem. Looking at ‘vdostats’ again, we nicely see dedup in action:
[root@rhel7u5a ~]# vdostats --verbose /dev/mapper/vdoasync |grep -B6 'saving percent' physical blocks : 7864320 logical blocks : 78643200 1K-blocks : 31457280 1K-blocks used : 17140524 1K-blocks available : 14316756 used percent : 54 saving percent : 52
Thanks to dedup, the copy of these 13GB occupies just ~120MB on the VDO layer!
Let’s copy data to VDO backed devices (separating sync and async mode) and to devices with a plain block device backend. After an initial copy of a directory with 5GB data to the mountpoint, three copies of that directory on the device were created.
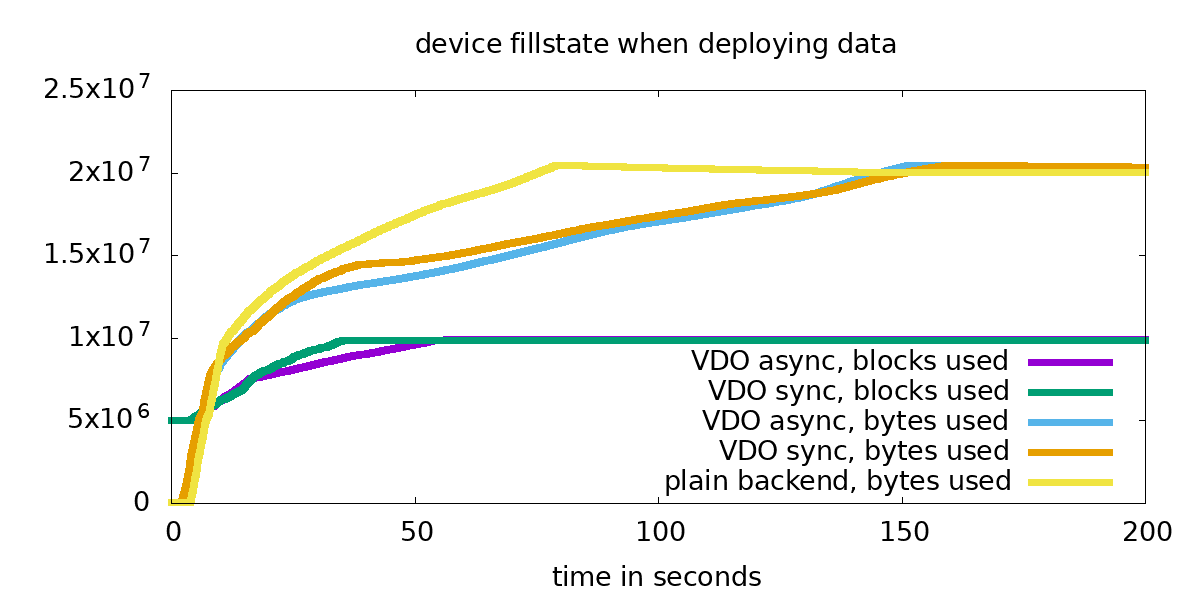
From the earlier tests we know that the initial deployment to the plain backend finishes first, this can also be seen here. The violet and green lines illustrate the blocks used by our data on VDO devices. Async and sync mode are similar in this aspect. Both VDO volumes also start with reporting ‘0 bytes occupied’ via the ‘df’ command, but we see that right from the start some blocks are used internally. For the VDO backends, we see that the initial copy takes ~50 seconds, then the copies on top of VDO start. Due to deduplication, almost no additional blocks are taken into use in that phase, but we see how ‘used bytes’, so what the filesystem layer reports, is growing.
This graph can be different, depending on the data which is copied, RAM, cpu performance and the backend which is used.
Final thoughts
When designing VDO, to date the focus was to serve as a primary storage service. It is is especially designed for high performance in environments with random IO, so using VDO as shared storage with multiple tasks on top doing I/O. Especially use cases like running multiple VMs on a single VDO volume let VDO shine.
We have seen that VDO is quite easy to use. I have not done any tuning here - but learned many things around benchmarking. ‘man vdo’ has details about many tuning options like read caches and so on. The Block Deduplication and Compression with VDO video from Devconf 2018 is good, more details are also in the article Understanding the concepts behind Virtual Data Optimizer (VDO) in RHEL 7.5 Beta from Nikhil Chawla.
Want to learn more about edge computing?
 Edge computing is in use today across many industries, including telecommunications, manufacturing, transportation, and utilities. Visit our resources to see how Red Hat's bringing connectivity out to the edge.
Edge computing is in use today across many industries, including telecommunications, manufacturing, transportation, and utilities. Visit our resources to see how Red Hat's bringing connectivity out to the edge.
A Red Hat Technical Account Manager (TAM) is a specialized product expert who works collaboratively with IT organizations to strategically plan for successful deployments and help realize optimal performance and growth. The TAM is part of Red Hat’s world class Customer Experience and Engagement organization and provides proactive advice and guidance to help you identify and address potential problems before they occur. Should a problem arise, your TAM will own the issue and engage the best resources to resolve it as quickly as possible with minimal disruption to your business.
Connect with TAMs at a Red Hat Convergence event near you! Red Hat Convergence is a free, invitation-only event offering technical users an opportunity to deepen their Red Hat product knowledge and discover new ways to apply open source technology to meet their business goals. These events travel to cities around the world to provide you with a convenient, local one-day experience to learn and connect with Red Hat experts and industry peers.
Sobre o autor
Christian Horn is a Senior Technical Account Manager at Red Hat. After working with customers and partners since 2011 at Red Hat Germany, he moved to Japan, focusing on mission critical environments. Virtualization, debugging, performance monitoring and tuning are among the returning topics of his daily work. He also enjoys diving into new technical topics, and sharing the findings via documentation, presentations or articles.
Mais como este
Por que agentes de IA são a evolução das aplicações
Por que o aumento das vulnerabilidades de segurança impulsionadas pela IA exige a atuação técnica de especialistas
Untangling Networks | Compiler
Technically Speaking | Defining sovereign AI with open source
Navegue por canal

Automação
Últimas novidades em automação de TI para empresas de tecnologia, equipes e ambientes

Inteligência artificial
Descubra as atualizações nas plataformas que proporcionam aos clientes executar suas cargas de trabalho de IA em qualquer ambiente

Nuvem híbrida aberta
Veja como construímos um futuro mais flexível com a nuvem híbrida

Segurança
Veja as últimas novidades sobre como reduzimos riscos em ambientes e tecnologias

Edge computing
Saiba quais são as atualizações nas plataformas que simplificam as operações na borda

Infraestrutura
Saiba o que há de mais recente na plataforma Linux empresarial líder mundial

Aplicações
Conheça nossas soluções desenvolvidas para ajudar você a superar os desafios mais complexos de aplicações
Virtualização
O futuro da virtualização empresarial para suas cargas de trabalho on-premise ou na nuvem