Legacy software doesn't retire itself. It sits in production, accumulating technical debt, resisting change, and quietly becoming a risk—not because of what it does, but because of what it can no longer support.
That's the challenge facing leading systems integrators (SIs) working in support of government and industry. Across a portfolio of mission-critical applications, SIs and aerospace companies are managing aging Python and Java codebases that need to move to a modern, security-focused, and supportable foundation—specifically Red Hat Enterprise Linux 10 (RHEL 10).
The goal isn't just a software upgrade. It's maintaining the speed of software delivery, the speed of AI, and the security posture that government data centers, forward-deployed mission areas, or mobile systems on aircraft depend on.
This isn't theoretical for the U.S. federal government. GSA's AI governance framework and the Department of War (DoW) now require agencies and services to operationalize responsible AI, not just adopt it. For defense and mission stakeholders, that mandate isn't a policy checkbox, it's a forcing function for getting the software factory right before the agents inside it are trusted with anything that matters.
During a recent engagement, one of the firm requirements was full offline compatibility. Environments in support of national security often lack internet access by design. Any dependency on an external service (GitHub, a cloud API, a remote package registry) is a dependency that can become a vulnerability, a point of failure, or make the system radically out of compliance.
Modernizing the system manually was technically possible, but the estimated engineering effort stretched into years of human labor, making it a non-starter at the scale required. The alternative was to do nothing and continue operating aging systems with increasing operational risk. The question then became whether a third path existed—could we build a more efficient process using agentic automation, allowing engineers to supervise modernization at scale rather than perform every step by hand?
It turns out we could, and we built an agentic platform using Red Hat AI and Red Hat OpenShift AI.
The problem with legacy modernization at scale
Brownfield migration—moving real production code (not a greenfield proof of concept (POC))—is fundamentally different from building something new. You can't just prompt an AI and call it done.
Legacy codebases are often characterized by:
- Aging architectures: Systems designed around assumptions, frameworks, and infrastructure that reflect the engineering norms of an earlier era.
- Limited or uneven test coverage: Large portions of the codebase were written before automated testing became a standard discipline.
- Implicit behavioral contracts: Dependencies between modules and services that exist in practice but were never formally documented or enforced.
- Accumulated technical debt: Layers of workarounds, deprecated libraries, and compatibility fixes that have gradually become part of the production system.
For national security missions, the stakes of getting this wrong are not abstract. A failed migration doesn't just break an app, it can ground a workflow, delay a mission, or introduce a security vulnerability into infrastructure that protects people.
This is exactly the environment where large, general-purpose frontier models running behind a cloud API are not an option. You can't send sensitive code to an external endpoint. You can't tolerate unpredictable inference behavior at scale. Even if you could connect to cloud frontier models, you can't justify the token volume and compute overhead when requests expand into long reasoning chains across massive parameter spaces. At migration scale, where systems contain millions of lines of code, that quickly translates into latency, infrastructure cost, and increased operational risk.
Why small, efficient models are the right instrument
The instinct in most AI applications is to reach for the biggest model available. More parameters, more context, better answers. That logic breaks down quickly in disconnected, mission-critical, resource-constrained environments. Large frontier models often introduce excessive latency, unpredictable reasoning loops, and significant GPU memory demands that are difficult to support in controlled infrastructure.
Small language models (SLMs) are well suited for agentic workflows because these systems require reliable, repeatable execution and low-latency responses, not just raw model scale. Smaller models can deliver fast, deterministic behavior that works well for automation tasks like tool-calling, orchestration, and structured reasoning. They are also easier to fine-tune and operate locally, enabling teams to deploy fleets of domain-specific agents without relying on external endpoints. In other words, when a model only "knows" one domain well, the probability distribution becomes sharper, and it tends to produce the same answer more often.
That said, our testing revealed that model capability still correlates strongly with context length and parameter count, particularly for code migration tasks that require understanding large software systems. The models that performed well in early testing were Llama 4 variants and Claude models, largely due to their very large context windows (>256K tokens) and strong reasoning ability. Conversely, we found that Claude would sometimes overthink straightforward engineering tasks, producing unnecessarily long reasoning chains that increase token usage and latency. At migration scale, that behavior compounds quickly into significant compute cost.
For this reason, we are currently running Meta Maverick locally, with parallel testing using Mistral models due to the GPU memory requirements of the larger models. We are also re-evaluating Llama 4 Scout, which performs well but similarly pushes the limits of available compute in the current environment.
As a practical workaround, we implemented a hybrid model strategy that uses smaller models while refactoring workflows to mitigate context limitations as they appear.
Our current model selections for the agent harness:
- mistralai/Devstral-Small-2-24B-Instruct: Designated for coding agents. 256K token context, strong performance on coding benchmarks, optimized for software analysis and refactoring tasks.
- mistralai/Ministral-3-14B-Reasoning: Designated for non-coding agents. 256K token context, effective for structured reasoning, dependency analysis, and orchestration across migration workflows.
In addition to the agent models, the system uses specialized models for knowledge indexing and retrieval:
- gpt-oss-120B: Used for building the GraphRAG knowledge graph representing the global structure of the codebase.
- intfloat/e5-mistral-7B-instruct: Embedding model used for GraphRAG indexing and vector retrieval.
These were not compromise choices. They were fit-for-purpose engineering decisions based on the available compute environment. The context limitations we encounter are a function of GPU capacity, not a constraint of the architecture itself. As infrastructure scales, the agent harness and model selection strategy can scale with it.
The agent mesh architecture: An agentic "harness of harnesses" built on OpenShift AI
The heart of this platform is an agentic harness, a modular orchestration framework that coordinates multiple specialized AI agents, each responsible for a specific part of the migration workflow. This harness runs on OpenShift AI, leveraging vLLM for efficient, low-latency model inference. Over time, this pattern evolves toward what we describe as an agent mesh — a "harness of harnesses" architecture where multiple agentic workflows can interoperate, coordinate tasks, and share state across complex modernization programs.
Here’s what the architecture is doing today:
Coding agents — powered by Devstral — analyze legacy Python 2 or Java source code, identify deprecated APIs, generate refactored equivalents, and produce characterization tests that capture the original behavior before anything changes. They don't just translate syntax, they are working to preserve behavioral intent.
Non-coding agents — powered by Ministral — perform reasoning tasks across the broader workflow, including dependency mapping, migration planning, and progress tracking. Deterministic orchestration logic governs the execution flow, so agents coordinate around what has been migrated, validated, blocked, and what should happen next.
A custom tracking management agent handles integration with GitLab (and can be swapped out entirely for disconnected environments). This component is fully inspectable code rather than a black box, enabling organizations to integrate the harness with their existing development and governance systems.
The harness itself is designed for modularity and replaceability, combining custom-built agents with open source agents such as OpenCode. When organizations ask whether the system is a black box, the honest answer is nuanced: the LLM inference layer, like any neural network, is inherently opaque. However, the orchestration logic, agent code, outputs, and decision trails are fully traceable, auditable, and inspectable, which is critical for organizations operating under DoW security and assurance requirements.
vLLM, serving as the inference engine within OpenShift AI, is a critical enabler. Efficient inference is not just a performance optimization—in environments with constrained GPU resources, it is what makes multi-agent workflows viable. vLLM’s optimized serving allows the platform to handle the iterative, multistep reasoning loops required for migration workflows without exhausting compute resources on a single task.
As additional agentic harnesses emerge for adjacent tasks such as testing, security review, documentation generation, or deployment validation, these harnesses can interconnect through the broader agent mesh, enabling coordinated automation across entire modernization pipelines.
The migration workflow: Python first, Java next
The initial phase of this engagement targets Python 2 to Python 3 migration, which serves as both a real deliverable and a validation of the framework. Python 2 reached end-of-life in 2020, and systems still running on it are operating with unpatched vulnerabilities and no upstream support. For government and enterprise systems, this is not a theoretical risk.
Our hypothesis, validated in testing, is that the cost of migration scales with external dependency complexity. Applications that are tightly coupled to deprecated third-party packages require significantly more agent iterations to migrate cleanly. This informed the model design: fewer agentic subtasks per flow, tighter scoping per iteration, more deterministic validation steps between them.
The 30-day target: 80% test coverage, no GitLab dependency required, functional equivalence validated between Python 2 and Python 3 versions.

Figure 1: Agentic software factory workflow of coding agents, non-coding agents, and tools on OpenShift AI.
The 30/60/90 day roadmap then pivots to Java migration targeting OpenJDK and Corretto versions (7, 8, 11, 17, 21) toward Java 25, with migration paths that differ depending on whether the target environment is RHEL 8 or RHEL 9/10. It's worth stating this isn't a magic button or a one-size-fits-all solution. The agentic framework is a starting point, and each agent within it is purpose-built for a specific task in the migration workflow, which is exactly what makes it extensible to Java without rebuilding from scratch.
Measuring what actually matters: Brownfield KPIs
Many agentic and traditional software development KPIs are written for greenfield development. They assume you know the architecture, have access to documentation, and are building something new. They reward velocity.
In brownfield legacy migration, velocity without correctness is not success, it's technical debt generation at AI speed.
The KPI framework we've defined for this engagement is tiered around 3 questions:
Does it work? Functional equivalence rate, integration test pass rate, change failure rate. These are go/no-go metrics. If the refactored code doesn't produce identical outputs to the original given identical inputs, nothing else matters.
Do we understand how it works? Developer acceptance rate, test coverage delta, migration completion rate. A migration isn't done when the code runs. It's done when the developers who will own it can read it, trust it, and maintain it.
Can the team own it long-term? Developer confidence score, time-to-first-contribution, developer capacity gain. The ultimate return on investment (ROI) metric isn't token cost per task. It's how much time the engineering team reclaims from repetitive migration work to focus on higher-value mission contributions.
Velocity metrics—throughput, iteration latency, agent actions per minute—belong on an engineering dashboard for tuning the system. They don't belong in a program review as measures of success.
What Red Hat AI and OpenShift AI make possible
None of this works without a platform that can actually support it. OpenShift AI provides the foundational layer for everything described here:
- Model serving with vLLM: Efficient, scalable inference for the coding and reasoning models that power the agent harness.
- Model customization workflows: Supporting fine-tuning, LoRA, and quantization for models that need to run in resource-constrained environments.
- Disconnected cluster support: The platform is designed to run in environments without internet access, which is a baseline requirement here.
- Audit logging and observability: The traceability and explainability that mission stakeholders require, built into the platform rather than bolted on.
- Modular, containerized architecture: Agents are containerized, swappable, and deployable through existing OpenShift infrastructure that systems integrators, aerospace companies, and the federal government already understand.
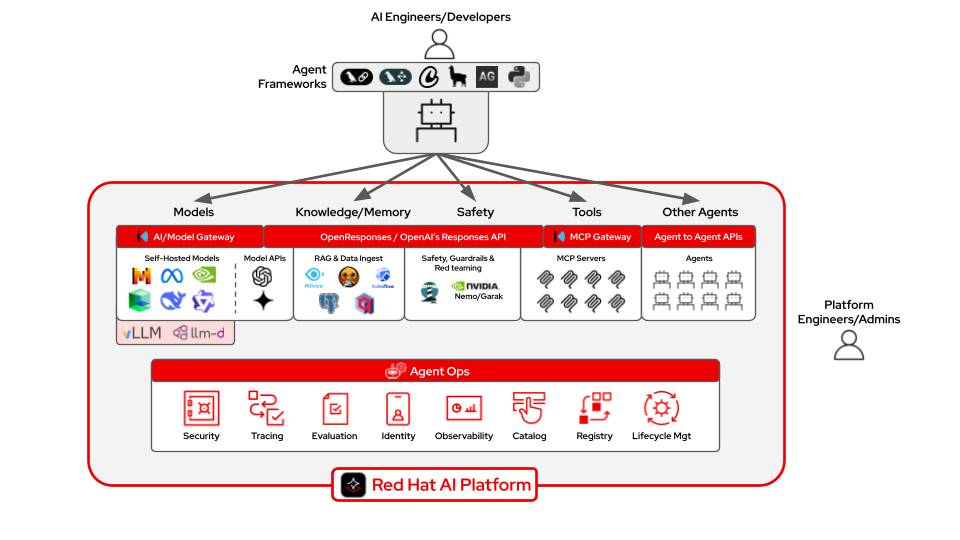
Figure 2: Components and capabilities of building agents with Red Hat AI.
The addition of RHEL 10 as the target runtime environment is not incidental. RHEL 10 brings security hardening, updated runtime support for modern Python and Java, and the operational reliability that government systems require. Migrating to it isn't just a software lifecycle decision—it's a security and mission readiness decision.
The bigger pattern: Agent mesh across mission areas
This engagement is a single instance of something we expect to repeat across the defense industrial base, federal government, and industry more broadly. Legacy software estates are enormous. The engineering resources to migrate them manually don’t exist at the scale the problem demands. And the security window for running unsupported software is closing.
Agentic AI on a platform like OpenShift AI is a force multiplier that allows a skilled engineering team to oversee the migration of a codebase that would take years to modernize manually, in a fraction of the time, with the rigor and traceability that mission-critical environments require.
In this model, agentic harnesses coordinate specialized agents to perform discrete modernization tasks. As these harnesses expand to adjacent functions (e.g. testing, security review, deployment validation), they begin to form an agent mesh—a harness-of-harnesses architecture coordinating complex engineering workflows across large software estates.
The agents do repetitive work. The engineers do the architecture, the oversight, agent evaluations, and the exception handling. That division of labor is the model.
Small models. Efficient inference. Modular agents. Disconnected operation. Mission-aligned system modernization.
Closing thought
Frontier models are extraordinary reasoning engines. Purpose-built agentic platforms are mission instruments.
For government agencies, this isn't about adopting the latest AI trend. It's about having the infrastructure and the AI capability to keep critical systems secure, modern, and in service of the mission.
We're building that with Red Hat AI.
Learn more
Sobre los autores

I build real-world GenAI solutions for organizations that can’t afford to get it wrong.
My career spans national security, enterprise software, and next-generation AI platforms, with more than a decade focused on solving complex problems at the intersection of data, intelligence, and technology. I began in the intelligence community, serving eight years with the NSA and across the IC in intrusion defense, intelligence analysis, and mission-critical cyber operations. That experience in high-stakes security, pattern recognition, and adversarial thinking continues to shape how I approach GenAI strategy and deployment today.
Since then, I’ve led product and platform initiatives in digital ecosystems, advised startups, and worked across the data science landscape helping organizations move from experimentation to production. Much of my work focuses on making generative AI models more knowledgeable and reliable by grounding them in domain-specific data, mission context, and real operational constraints across national security, research, and healthcare.
Today, as an AI Solutions Advisor at Red Hat and IBM, I partner with government agencies, research institutions, and enterprises across North America to design scalable GenAI systems that work in the real world. The goal is never novelty — it’s better decisions, faster execution, and durable advantage.

Tola is a seasoned full-stack engineer and AI field architect with deep experience building and modernizing enterprise software platforms.
Having worked across organizations such as Pivotal and Red Hat, she brings strong expertise in Java development, Kubernetes-native architectures, and the practical realities of modern cloud platforms. Her background spans software engineering, machine learning, and data science, enabling her to bridge application development, AI systems, and platform infrastructure.
Throughout her career, she has worn many technical hats, including team lead, primary developer, and principal architect across both public and private sector environments. She has helped design and deliver complex systems operating at enterprise scale while guiding teams through evolving technology landscapes.
Today, as an AI field engineer, she works with organizations to translate emerging AI capabilities into production-ready solutions. Her focus is on helping enterprises modernize applications, operationalize machine learning, and integrate generative AI into existing software ecosystems.
Grounded in practical engineering, she partners closely with platform teams and developers to ensure AI-driven modernization efforts are secure, scalable, and aligned with real operational needs.

Más como éste
Red Hat and NVIDIA: Setting standards for high-performance AI inference
Red Hat AI tops MLPerf Inference v6.0 with vLLM on Qwen3-VL, Whisper, and GPT-OSS-120B
Technically Speaking | Build a production-ready AI toolbox
Technically Speaking | Platform engineering for AI agents
Navegar por canal

Automatización
Las últimas novedades en la automatización de la TI para los equipos, la tecnología y los entornos

Inteligencia artificial
Descubra las actualizaciones en las plataformas que permiten a los clientes ejecutar cargas de trabajo de inteligecia artificial en cualquier lugar

Nube híbrida abierta
Vea como construimos un futuro flexible con la nube híbrida

Seguridad
Vea las últimas novedades sobre cómo reducimos los riesgos en entornos y tecnologías

Edge computing
Conozca las actualizaciones en las plataformas que simplifican las operaciones en el edge

Infraestructura
Vea las últimas novedades sobre la plataforma Linux empresarial líder en el mundo

Aplicaciones
Conozca nuestras soluciones para abordar los desafíos más complejos de las aplicaciones
Virtualización
El futuro de la virtualización empresarial para tus cargas de trabajo locales o en la nube