This post describes the technical details of the resources needed for deploying a Red Hat Advanced Cluster Management for Kubernetes high availability and disaster recovery (HA/DR) framework.
You can read part 1 here: Red Hat Advanced Cluster Management for Kubernetes: High availability and disaster recovery (part 1)
Understand Red Hat Advanced Cluster Management HA and DR requirements
Confirm that the standby hub cluster has Red Hat Advanced Cluster Management installed and configured according to the customer's standards. It is also important to verify that any additional operator needs are installed on the same versions.
- The steps described in the next sections are required in all hub clusters (Active/Standby).
Enable the backup and restore operator
The backup and restore operator is not enabled by default when Red Hat Advanced Cluster Management is installed and configured. To enable it on all clusters, you must edit the MultiClusterHub resource on each Red Hat Advanced Cluster Management cluster, setting the cluster-backup field to true. Here is an example:
$ oc edit -n open-cluster-management multiclusterhub
apiVersion: operator.open-cluster-management.io/v1
kind: MultiClusterHub
metadata:
creationTimestamp: "2023-07-04T16:35:40Z"
finalizers:
- finalizer.operator.open-cluster-management.io
generation: 2
name: multiclusterhub
namespace: open-cluster-management
resourceVersion: "66615"
uid: e39427a9-dc60-4c2c-9063-8ef6b9d51021
spec:
availabilityConfig: High
enableClusterBackup: false
ingress:
sslCiphers:
- ECDHE-ECDSA-AES256-GCM-SHA384
- ECDHE-RSA-AES256-GCM-SHA384
- ECDHE-ECDSA-AES128-GCM-SHA256
- ECDHE-RSA-AES128-GCM-SHA256
nodeSelector:
node-role.kubernetes.io/infra: ""
overrides:
components:
- enabled: true
name: console
- enabled: true
name: insights
- enabled: true
name: grc
- enabled: true
name: cluster-lifecycle
- enabled: true
name: volsync
- enabled: true
name: multicluster-engine
- enabled: true
name: search
- enabled: true
name: app-lifecycle
- enabled: true
name: cluster-backup
separateCertificateManagement: false
Deploy object storage
If you do not have an object storage solution, you can deploy a Noobaa-based Standalone Object Gateway. You can also use Minio or any S3-compatible solution you want.
Warning: In a production environment, object storage must reside on resilient infrastructure (the cloud, for example) so that it does not become a single point of failure.
Set the S3 storage secret
A secret containing the S3 storage access credentials is required for the operator to store backup data.
- For example, if you are using Minio and the credentials used to access the Minio console are admin/redhat123, the file must contain this information.
Create a file containing the S3 storage credentials with contents similar to the one below:
$ cat credentials [backupStorage] aws_access_key_id=admin aws_secret_access_key=redhat123
You must create the secret in the open-cluster-management-backup namespace:
$ oc create secret generic cloud-credentials --namespace open-cluster-management-backup --from-file cloud=<CREDENTIALS_FILE_PATH>
Check if the secret was created:
$ oc get secrets -n open-cluster-management-backup cloud-credentials -o yaml
Note: The name of the profile created in the credentials file (backupStorage in the example above) can be set to any value suitable for the client's environment. This name will be referenced later. You can add multiple profiles to the same credential file if needed.
Configure the ManagedServiceAccount
This feature automatically connects managed clusters (clusters that already exist and were manually imported into Red Hat Advanced Cluster Management) to the new hub cluster. The ManagedServiceAccount is available with the backup and restore component as of Red Hat Advanced Cluster Management 2.7.
The backup controller available with Red Hat Advanced Cluster Management 2.7 uses the ManagedServiceAccount component on the main hub cluster to create a token for each of the managed clusters that were manually imported.
See below for more details.
Edit the MultiClusterEngine
Enable the ManagedServiceAccount component on the MultiClusterEngine by editing the MultiClusterEngine resource and setting the enable: true value for the managedserviceaccount-preview component. See the following example:
$ oc edit -n open-cluster-management multiclusterengine
apiVersion: multicluster.openshift.io/v1
kind: MultiClusterEngine
metadata:
creationTimestamp: "2023-07-04T16:37:56Z"
finalizers:
- finalizer.multicluster.openshift.io
generation: 2
labels:
installer.name: multiclusterhub
installer.namespace: open-cluster-management
multiclusterhubs.operator.open-cluster-management.io/managed-by: "true"
name: multiclusterengine
resourceVersion: "63543"
uid: a0711500-5db9-40da-85f5-dacfc5bc3637
spec:
availabilityConfig: High
nodeSelector:
node-role.kubernetes.io/infra: ""
overrides:
components:
- enabled: true
name: local-cluster
- enabled: true
name: assisted-service
- enabled: true
name: cluster-lifecycle
- enabled: true
name: cluster-manager
- enabled: true
name: discovery
- enabled: true
name: hive
- enabled: true
name: server-foundation
- enabled: true
name: cluster-proxy-addon
- enabled: true
name: hypershift-local-hosting
- enabled: true
name: managedserviceaccount-preview
- enabled: false
name: hypershift-preview
- enabled: true
name: console-mce
targetNamespace: multicluster-engine
tolerations:
- effect: NoSchedule
key: node-role.kubernetes.io/infra
operator: Exists
Confirm it was enabled:
$ oc get -n open-cluster-management MultiClusterEngine -o yaml | grep -B1 managedserviceaccount-preview
- enabled: true
name: managedserviceaccount-preview
Confirm the cluster backup operator
Verify that the cluster-backup operator is active on the hub cluster. See the following example:
$ oc get -n open-cluster-management multiclusterhub -o yaml | grep -B1 cluster-backup$
- enabled: true
name: cluster-backup
Attention: If you have not already enabled the backup-operator, editing the above component installs the OpenShift APIs for Data Protection (OADP) operator in the open-cluster-management-backup namespace. Make sure you are using a supported version as described at the beginning of this document.
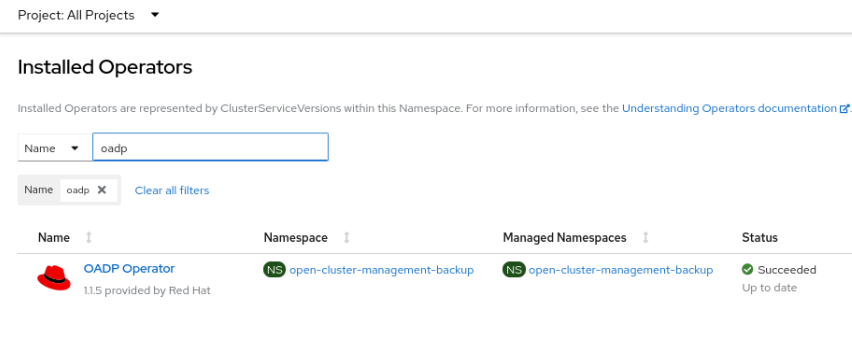
OADP Version 1.1.5 is suitable for Red Hat Advanced Cluster Management
Backup configuration on the hub cluster
You need to create a resource named Data Protection Application on your hub clusters.
Set the DataProtectionApplication
The DataProtectionApplication (DPA) provides all necessary settings for performing backups and restores. The following is an example of DPA using S3 storage:
$ cat dpa.yaml
apiVersion: oadp.openshift.io/v1alpha1
kind: DataProtectionApplication
metadata:
name: dpa
namespace: open-cluster-management-backup
spec:
configuration:
velero:
defaultPlugins:
- openshift
- aws
restic:
enable: false
backupLocations:
- name: default
velero:
provider: aws
default: true
objectStorage:
bucket: acm-backup
prefix: hubcluster2
config:
s3Url: "http://192.168.15.133:9000"
s3ForcePathStyle: "true"
region: homecloud
profile: "backupStorage"
credential:
name: cloud-credentials
key: cloud
Verify that the DPA settings are correct:
$ oc get -n open-cluster-management-backup dataprotectionapplications.oadp.openshift.io -o yaml
Setup details
- objectStorage.bucket must be set to the bucket created on S3 storage.
- objectStorage.prefix is an optional parameter, but it can help with cluster identification.
- config.s3Url must be set to the S3 storage access URL. If necessary, also include the TCP port number for the connection.
- config.s3ForcePathStyle is needed in some cases, like Minio and Noobaa object storage. On some object storage solutions this parameter may be unnecessary.
- config.region must reflect the region configured on the object storage bucket. It can also be your on-premises cluster name.
- config.profile should reflect the name of the profile created earlier in the secret for S3 storage.
Important: The name parameter in the DPA needs to be relatively short as a route (expose) will be created as part of the provisioning process. Long cluster names may exceed the 63-character limit, which will prevent the solution from working correctly.
Finish the setup
That's it for this process. The next part demonstrates dealing with backup tasks, such as scheduling and restoration.
Sobre el autor

Andre Rocha is a Consultant at Red Hat focused on OpenStack, OpenShift, RHEL and other Red Hat products. He has been at Red Hat since 2019, previously working as DevOps and SysAdmin for private companies.
Más como éste
La paradoja agéntica y los argumentos a favor de la IA híbrida
Deja de administrar el pasado y comienza a forjar el futuro de TI
Collaboration In Product Security | Compiler
Keeping Track Of Vulnerabilities With CVEs | Compiler
Navegar por canal

Automatización
Las últimas novedades en la automatización de la TI para los equipos, la tecnología y los entornos

Inteligencia artificial
Descubra las actualizaciones en las plataformas que permiten a los clientes ejecutar cargas de trabajo de inteligecia artificial en cualquier lugar

Nube híbrida abierta
Vea como construimos un futuro flexible con la nube híbrida

Seguridad
Vea las últimas novedades sobre cómo reducimos los riesgos en entornos y tecnologías

Edge computing
Conozca las actualizaciones en las plataformas que simplifican las operaciones en el edge

Infraestructura
Vea las últimas novedades sobre la plataforma Linux empresarial líder en el mundo

Aplicaciones
Conozca nuestras soluciones para abordar los desafíos más complejos de las aplicaciones
Virtualización
El futuro de la virtualización empresarial para tus cargas de trabajo locales o en la nube