
¿Sientes que tu nube privada es un bufet ilimitado sin control? Sabes que aporta valor, pero cuando llega la factura, es casi imposible saber quién come qué.
En los entornos de nube dinámicos actuales, es cada vez más importante atribuir correctamente los costos a los usuarios internos, sobre todo en el caso de las empresas que ejecutan su propia infraestructura de nube. Debes establecer la responsabilidad para distribuir los costos de manera justa entre los departamentos o motivar a los equipos a ajustar el tamaño de sus cargas de trabajo, y obtener visibilidad es el primer paso.
Con la Feature Release 5 (FR5) de Red Hat OpenStack Services on OpenShift 18, presentamos una pieza clave para resolver ese rompecabezas: la capacidad de realizar la tarificación en función del uso medido de tus tenants.
Presentamos CloudKitty, el servicio de tarificación nativo de OpenStack, que ya cuenta con disponibilidad general en la FR5. Este servicio cubre la brecha entre tus métricas técnicas sin procesar y tus operaciones financieras.
¿Por qué es importante CloudKitty?
CloudKitty ofrece una capa de traducción que convierte los datos de uso del servidor en información que puede servir de base para los presupuestos departamentales. Piensa en CloudKitty como un lector de contadores: se sitúa entre tus métricas recopiladas y tu solución de FinOps o facturación. Toma datos técnicos sin procesar, como la cantidad de horas que funcionó una máquina virtual (VM) o el almacenamiento consumido, y aplica tus reglas de tarificación específicas para generar un informe. Esto te ayuda a alcanzar dos objetivos principales:
- Recuperación transparente de costos: Ahora puedes ver un desglose claro y detallado del uso de recursos por tenant. Esto te permite recuperar los gastos operativos con precisión, sin sorprender a los clientes internos con cargos opacos.
- Confianza y optimización: Cuando los tenants ven cómo su propio consumo (desglosado por proyecto, flavor y métrica) afecta a sus costos, pueden tomar decisiones informadas, como archivar datos obsoletos u optimizar el uso de sus VM.
Ten en cuenta que CloudKitty funciona únicamente como un motor de visibilidad y tarificación; no aplica presupuestos de forma activa ni bloquea la creación de recursos (como instancias de Nova) si un tenant supera cierto umbral de costos.
¿Cómo funciona CloudKitty?
Si bien no es una solución de facturación completa, CloudKitty proporciona el vínculo fundamental entre el uso y el costo. En pocas palabras, el flujo de trabajo es el siguiente:
Configurar Rating Rules → Recopilar Metrics → Generar Rating reports
Establecer las reglas
Te presentamos un tenant de ejemplo de nuestra lista ficticia: el Ministerio de datos. Históricamente, el ministerio ha estado creando máquinas virtuales (VM) de gran tamaño para sus cargas de trabajo de análisis y las deja funcionando mucho después de que finalizan los cálculos.
Para lograr una recuperación transparente de costos, debemos realizar un seguimiento de su huella de computación. Lo haremos mediante el seguimiento de la métrica ceilometer_cpu. Esta métrica específica nos permite ofrecer un tiempo de actividad basado en el flavor, lo que significa que, por cada período en que se ejecute una instancia de VM, CloudKitty puede calcular una tarifa diferente en función de su tamaño.
Paso 1: Crear el servicio
Primero, debemos crear un contenedor de nivel superior para nuestra métrica. El nombre del servicio debe coincidir exactamente con el nombre de la métrica o con el alt_name definido en metrics.yaml. (Analizaremos este archivo con más detalle más adelante).
openstack rating hashmap service create ceilometer_cpu
+----------+--------------------------------------+
| Name | ID de servicio |
+----------+--------------------------------------+
| ceilometer_cpu | <uuid> |
+----------+--------------------------------------+¡Guarda ese ID de servicio (UUID), ya que lo necesitarás para los siguientes comandos!
Al crear un servicio llamado ceilometer_cpu, ayudamos a garantizar que cada punto de datos de la CPU que provenga del recolector se dirija directamente a esta nueva regla de tarificación.
Paso 2: Crear un grupo (opcional)
No queremos que los cargos de computación del ministerio se mezclen con sus facturas de almacenamiento o de red. Los grupos nos ayudan a organizar las asignaciones relacionadas y a aislar los cálculos entre sí.
openstack rating hashmap group create cpu_ratingAl agrupar estas asignaciones, separamos los diferentes escenarios de facturación. Si coinciden varias asignaciones del mismo grupo, CloudKitty solo aplicará la más costosa.
Paso 3: Crear una asignación
Las asignaciones son las reglas de costos. Primero, establezcamos un punto de referencia para el Ministerio de datos cobrando un costo fijo por elemento. Al sustituir <service_id> y <group_id> por los UUID devueltos en los pasos anteriores, puedes vincular esta nueva regla directamente a tu servicio ceilometer_cpu y a tu grupo cpu_rating.
openstack rating hashmap mapping create 0.02 \
-s <service_id> \
-g <group_id> \
-t flatIn este escenario, 0.02 significa 0.02 unidades por período de recolección (por defecto, cada hora). Cada instancia de CPU tiene un cargo fijo de 0.02 unidades, independientemente de cuánto se use.
Paso 4: Tarificación basada en campos (el arma secreta)
El Ministerio de Datos ejecuta servidores web diminutos junto con nodos de bases de datos enormes que consumen muchos recursos. No sería justo cobrar una tarifa fija por todo. Queremos cobrarles precios diferentes por cada uno de los tipos específicos de VM que utilicen.
Primero, creamos un campo que hace referencia a la clave de metadatos:
openstack rating hashmap field create <service_id> flavor_idLuego, creamos una asignación específica para ese valor especifico:
openstack rating hashmap mapping create 0.05 \
--field-id <field_id> \
--value <flavor_uuid> \
-t flatRepetiremos esta creación de asignaciones para cada tipo disponible en nuestro entorno. Para cada tipo, creamos una regla nueva para que el servicio de tarificación sepa qué tarifa calcular cuando se ejecute ese tamaño de VM específico.
El resultado: Cómo funciona todo en conjunto
Cuando llega el fin de mes y el Ministerio de Datos solicita ver su consumo, así es como CloudKitty procesa las reglas que creamos anteriormente:
ceilometer_cpu (métrica)
└─> Service: ceilometer_cpu
└─> Field: flavor_id (optional)
└─> Mapping: m1.tiny = 0.01, m1.large = 0.05
└─> Mapping (direct): 0.02 flatSi puedes medirlo, puedes tarificarlo
Usamos el consumo de CPU del Ministerio de Datos (ceilometer_cpu) como nuestro ejemplo principal, pero el cómputo es solo una parte del rompecabezas. El verdadero poder de CloudKitty en Red Hat OpenStack Services on OpenShift es su integración con Prometheus.
Recuerda que puedes usar cualquier métrica que ya se haya recopilado para la tarificación. Esto significa que puedes crear fácilmente reglas de tarificación para el resto de la huella de tu tenant siguiendo exactamente los mismos pasos que describimos anteriormente. Por ejemplo, puedes crear asignaciones de costos para:
- Almacenamiento en bloque: Seguimiento de la capacidad en GB-mes mediante
ceilometer_disk_device_capacity - Redes: Cobro por las direcciones públicas asignadas mediante
ceilometer_ip_floating - Ancho de banda de salida: Tarificación del tráfico de salida total de las máquinas virtuales mediante
ceilometer_network_outgoing_bytes
Una vez que CloudKitty obtiene este conjunto de datos de Prometheus, el procesador aplica tus reglas de tarificación personalizadas y envía las métricas tarificadas y finalizadas directamente a un backend de almacenamiento. Sirve como el puente automatizado definitivo entre tu telemetría técnica sin procesar y tus informes de FinOps.
Generar informes de tarificación: El momento de la verdad
Una vez que hayas creado tus reglas y recopilado las métricas de Prometheus, el último paso consiste en extraer los datos tarificados.
Es importante tener en cuenta que CloudKitty no es un sistema de facturación. No intenta generar una factura atractiva en PDF. En su lugar, está diseñado para funcionar como un motor de datos sólido que proporciona datos JSON limpios y analizables a través de su API REST o del cliente de OpenStack. Esto te permite conectar los datos tarificados con mayor facilidad al middleware de facturación, showback o FinOps de tu empresa.
La vista del tenant: El ministerio verifica sus cuentas
CloudKitty cuenta con un control de acceso integrado que reconoce los tenants. Cuando el Ministerio de Datos quiere consultar su consumo actual, solo puede acceder al de su propio proyecto. La API bloquea o ignora automáticamente cualquier intento de ver los datos de otros tenants.
Para obtener su resumen mensual, el Ministerio puede utilizar el cliente de OpenStack:
# Obtener el resumen de un mes específico
openstack rating summary get --begin 2026-02-01 --end 2026-03-01La vista del administrador: La perspectiva global
Mientras que el Ministerio de Datos se limita a su propio consumo, los administradores de la nube necesitan una visión integral de todo el entorno para gestionar la capacidad y facilitar el reembolso global.
Con un token de administrador, los operadores tienen visibilidad completa. Pueden ampliar el comando para aislar un tenant específico mediante --tenant-id <project_uuid>.
openstack rating summary get \
--begin 2026-02-01 \
--end 2026-03-01 \
--tenant-id <project_uuid>Por otra parte, si el equipo de FinOps necesita exportar el panorama completo a su sistema de facturación, el administrador puede obtener los datos tarificados de toda la nube de una sola vez con la opción --all-tenants.
Conexión directa a tu solución de FinOps
Si tu middleware de FinOps extrae estos datos mediante programación, puede usar la API REST para solicitar un desglose detallado agrupado por los tipos de servicio específicos que configuramos antes (like ceilometer_cpu):
curl -X GET \
-H "X-Auth-Token: $TENANT_TOKEN" \
"http://localhost:8888/v1/report/summary?begin=2026-02-01T00:00:00&end=2026-03-01T00:00:00&groupby=res_type"La salida JSON resultante muestra claramente el tipo de recurso, el período de tiempo y el total de unidades calculadas.
{
"summary": [
{
"tenant_id": "MoD-project-uuid",
"res_type": "ceilometer_cpu",
"begin": "2026-02-01T00:00:00",
"end": "2026-03-01T00:00:00",
"rate": 125.50
}
]
}Al canalizar estos datos JSON estructurados y agregados directamente al software financiero general de tu empresa, logras cerrar el ciclo entre el consumo bruto de infraestructura y la responsabilidad de los costos.
Funcionamiento interno
Ahora que hemos visto CloudKitty en acción desde la perspectiva del operador, veamos cómo funciona por dentro y examinemos su motor interno. Comprender la arquitectura te ayudará a analizar la escalabilidad, solucionar problemas y entender por qué se tomaron ciertas decisiones de diseño.
Descripción general de la arquitectura
CloudKitty se ejecuta como dos procesos independientes, cada uno con una responsabilidad distinta:
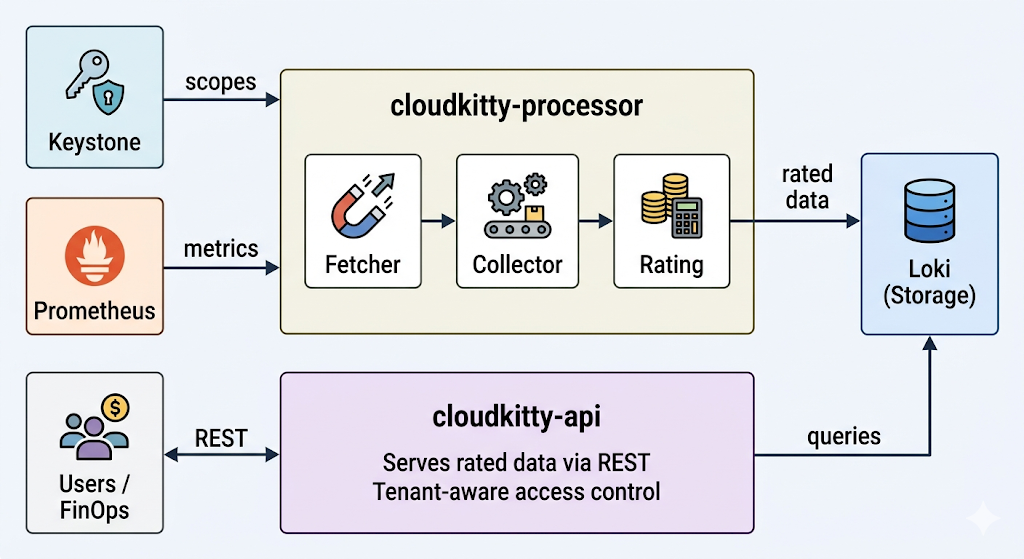
Figura 1. La arquitectura de CloudKitty. cloudkitty-processor obtiene los ámbitos de Keystone y las métricas de Prometheus, califica los datos y los almacena en Loki. cloudkitty-api sirve los datos calificados de Loki a los usuarios y las herramientas de FinOps a través de REST.
cloudkitty-processor es el motor de calificación. En cada período de recopilación (1 hora de forma predeterminada), ejecuta una canalización de 4 etapas:
- Obtención: Solicita a Keystone la lista de proyectos de OpenStack (ámbitos) que necesita calificar.
- Recopilación: Para cada ámbito, consulta en Prometheus los valores de las métricas sin procesar definidos en
metrics.yaml. - Calificación: Aplica las reglas de hashmap (los servicios, los campos y las asignaciones que configuramos anteriormente) para convertir el consumo sin procesar en datos calificados.
- Almacenamiento: Envía los dataframes de datos calificados resultantes a Loki para su persistencia.
cloudkitty-api es la interfaz REST. Gestiona todas las consultas entrantes de los inquilinos, administradores y herramientas externas de FinOps. Cuando un usuario solicita un resumen de calificación, consulta a Loki y devuelve los resultados. Este proceso no tiene estado y se puede escalar horizontalmente para gestionar más solicitudes simultáneas.
Como los dos procesos están desacoplados, puedes escalarlos de forma independiente: añade más réplicas de la API para gestionar la carga de consultas o ajusta el paralelismo del procesador para calificar más ámbitos de forma simultánea.
¿Por qué Loki?
El uso de Grafana Loki como backend de almacenamiento para los datos calificados puede parecer una opción poco convencional, ya que se conoce a Loki principalmente como un sistema de agregación de registros, pero en realidad se adapta a la perfección:
- Nativo de series temporales: Los datos calificados son intrínsecamente temporales: costo por ámbito y por período de recopilación. Loki está diseñado específicamente para realizar consultas eficientes de rangos de tiempo sobre flujos estructurados.
- Ya está en el stack: Las implementaciones de OpenStack Services on OpenShift ya incluyen LokiStack para la gestión de registros. CloudKitty reutiliza la misma infraestructura gestionada por el operador, por lo que no es necesario implementar ni mantener una base de datos adicional.
- Respaldado por almacenamiento de objetos: Loki almacena los datos de forma persistente en un almacenamiento de objetos compatible con S3, lo que mantiene una huella operativa reducida, sin necesidad de gestionar PVC adicionales ni clústeres de bases de datos.
- Metadatos estructurados: En el futuro, CloudKitty almacenará los metadatos indexados (tenant, tipo de métrica, flavor) directamente en cada entrada de registro. Esto permitirá realizar consultas filtradas rápidas sin un análisis JSON completo, lo que mejorará significativamente el rendimiento de las consultas a gran escala.
La configuración de las métricas
En el centro de la etapa de recopilación se encuentra metrics.yaml. Este archivo indica a CloudKitty qué métricas de Prometheus recopilar y cómo gestionarlas. A continuación, se muestra un extracto representativo de la configuración incluida:
metrics:
ceilometer_cpu:
unit: instance
alt_name: instance
groupby:
- resource
- user
- project
- flavor_name
- flavor_id
mutate: NUMBOOL
extra_args:
aggregation_method: max
ceilometer_image_size:
unit: MiB
factor: 1/1048576
groupby:
- resource
- project
metadata:
- container_format
- disk_format
extra_args:
aggregation_method: maxCada entrada controla cómo CloudKitty recopila e interpreta una métrica específica de Prometheus:
unit: La unidad de facturación que aparece en los informes de tarificación (por ejemplo, instance, GiB, B, ip).alt_name: Un nombre alternativo para la métrica. Al crear servicios de hashmap, puedes usar el nombre de la métrica de Prometheus (ceilometer_cpu) o elalt_name(instance).groupby: Las etiquetas de Prometheus utilizadas para desglosar la métrica. Para ceilometer_cpu, la agrupación por flavor_name and flavor_id es lo que habilita las reglas de tarificación basadas en flavor que configuramos anteriormente.mutate: Una transformación aplicada al valor sin procesar. NUMBOOL convierte cualquier valor distinto de cero en 1, lo que es perfecto para la semántica de "¿está activo este recurso?": no nos importa el contador de CPU sin procesar, solo que la instancia esté en ejecución.factor: Un factor de multiplicación para la conversión de unidades. Por ejemplo,ceilometer_image_sizeutiliza 1/1048576 para convertir los bytes sin procesar en MiB.metadata: Etiquetas de Prometheus adicionales para trasladar a los datos calificados con fines informativos (por ejemplo,container_format,disk_formatpara las imágenes).extra_args: Argumentos específicos del backend.aggregation_method: maxindica al recopilador de Prometheus que utilice el valor máximo dentro de cada período de recopilación.
Como el recopilador de CloudKitty se comunica directamente con Prometheus, la calificación de cualquier métrica disponible es sencilla: añade una nueva entrada a metrics.yaml con las etiquetas y la unidad adecuadas, y CloudKitty comenzará a recopilarla y calificarla en el próximo ciclo de procesamiento.
Inspección de los datos sin procesar
Aunque el comando openstack rating summary get te ofrece totales agregados, a veces necesitas profundizar más. Ya sea que estés verificando que tus reglas de calificación se aplican correctamente, depurando una métrica ausente o intentando comprender qué está almacenando CloudKitty, el comando openstack rating dataframes get te permite inspeccionar los puntos de datos calificados individuales que residen en Loki.
Piensa en los resúmenes como el estado de cuenta mensual y en los dataframes como las líneas individuales del recibo.
Para recuperar los dataframes calificados sin procesar para un intervalo de tiempo específico:
openstack rating dataframes get --begin 2026-03-01T00:00:00Z --end 2026-03-01T01:00:00ZCada fila de la salida representa un único punto de datos calificado para un período de recopilación:
| Begin | End | Metric Type | Unit | Qty | Price | Group By | Metadata |
|---|---|---|---|---|---|---|---|
2026-03-01T00:00:00Z |
2026-03-01T01:00:00Z |
ceilometer_cpu |
instance |
1 |
0.05 |
flavor_id=<uuid>, flavor_name=m1.large, project=<project_uuid>, resource=<vm_uuid> |
|
2026-03-01T00:00:00Z |
2026-03-01T01:00:00Z |
ceilometer_cpu |
instance |
1 |
0.01 |
flavor_id=<uuid>, flavor_name=m1.tiny, project=<project_uuid>, resource=<vm_uuid> |
Analicemos lo que te indica cada columna:
- Begin/End: El período de recopilación que abarca este punto de datos. De forma predeterminada, CloudKitty recopila cada hora, por lo que verás ventanas de una hora.
- Metric Type: El nombre de la métrica de
metrics.yaml(p. ej.,ceilometer_cpu,ceilometer_ip_floating). - Unit: La unidad de facturación, tal como se define en
metrics.yaml - Qty: La cantidad bruta tras cualquier transformación mutate o de factor. Para
ceilometer_cpuconNUMBOOL, será 1 si la instancia estaba en ejecución. - Price: El valor calculado tras aplicar tus reglas de hashmap. Aquí es donde puedes comprobar que se aplicó la asignación correcta: si estableces
m1.largeen 0,05, eso es lo que debería aparecer aquí. - Group By: Los valores de las etiquetas de los campos
groupbyenmetrics.yaml. Así es como CloudKitty desglosa los datos, lo que te permite profundizar en recursos, sabores o proyectos específicos. - Metadata: Cualquier etiqueta adicional que se transmita a través del campo de metadatos en
metrics.yaml.
Esto ofrece a los operadores una herramienta concreta para rastrear el trayecto completo desde la métrica sin procesar hasta el precio final, lo que aporta transparencia al comportamiento de CloudKitty y permite depurarlo en cada paso.
¿Todo listo para calcular los costos?
Si tu objetivo es la recuperación estricta de costos de los departamentos internos así como ofrecer una visibilidad transparente del consumo de recursos, CloudKitty te proporciona los datos estructurados y confiables que necesitas para lograrlo. Cierra la brecha entre tu telemetría sin procesar de OpenStack y tu middleware empresarial de FinOps.
Se acabaron los días de tratar la nube privada como un bufet ilimitado sin control. Nos entusiasma incorporar esta capacidad nativa y altamente personalizable al ecosistema de OpenStack Services on OpenShift en el lanzamiento de la versión 5. Es hora de dejar de adivinar y empezar a tarificar.
Primeros pasos
Explora la documentación oficial para configurar y gestionar CloudKitty en tu entorno:
- Habilitación de la tarificación en la nube en un entorno de OpenStack Services on OpenShift
- Uso del servicio de tarificación
Descúbrelo en acción
Dale un vistazo a la demostración en video para ver cómo un administrador puede configurar fácilmente reglas de tarificación flavor y extraer su primer análisis mensual.
Este video es una versión editada de 2 sesiones de terminal independientes. Si quieres analizar de cerca y de forma interactiva los comandos sin procesar que se utilizan en segundo plano, puedes explorar las grabaciones completas y sin editar de Asciinema aquí:
- https://asciinema.org/a/ofDLdVKxHfMAsaNM: Implementación de CloudKitty y creación de las reglas de tarificación basadas en flavors.
- https://asciinema.org/a/P11NR7CEqfiewF4R: Verificación de los dataframes de reembolsos y extracción del resumen mensual.
Prueba del producto
Red Hat OpenShift Container Platform | Versión de prueba del producto
Sobre los autores
Juan Larriba is a software engineer specializing in cloud infrastructure and OpenStack observability. He is a contributor to the OpenStack Kubernetes Operators ecosystem, where he works on the Telemetry Operator — a project that brings together metrics collection, alarming, and rating services like CloudKitty into cloud-native Kubernetes deployments. His work focuses on bridging traditional OpenStack telemetry components with modern container-native architectures, helping operators gain visibility and cost insight into their cloud workloads. Juan is passionate about open source collaboration and has contributed to projects spanning Ceilometer, Aodh, and CloudKitty, with a focus on making rating and chargeback capabilities more accessible in production OpenStack environments.
Más como éste
OpenShift: Integración consistente para la empresa híbrida
Red Hat OpenShift 4.21: Escalado más inteligente, migración más rápida y eficiencia impulsada por la inteligencia artificial
Do We Want A World Without Technical Debt? | Compiler
Avoiding Failure In Distributed Databases | Code Comments
Navegar por canal

Automatización
Las últimas novedades en la automatización de la TI para los equipos, la tecnología y los entornos

Inteligencia artificial
Descubra las actualizaciones en las plataformas que permiten a los clientes ejecutar cargas de trabajo de inteligecia artificial en cualquier lugar

Nube híbrida abierta
Vea como construimos un futuro flexible con la nube híbrida

Seguridad
Vea las últimas novedades sobre cómo reducimos los riesgos en entornos y tecnologías

Edge computing
Conozca las actualizaciones en las plataformas que simplifican las operaciones en el edge

Infraestructura
Vea las últimas novedades sobre la plataforma Linux empresarial líder en el mundo

Aplicaciones
Conozca nuestras soluciones para abordar los desafíos más complejos de las aplicaciones
Virtualización
El futuro de la virtualización empresarial para tus cargas de trabajo locales o en la nube