
Red Hat OpenShift Virtualization 4.19 augmente considérablement les performances et la rapidité des charges de travail aux entrées/sorties (E/S) élevées, comme les bases de données. Cette solution inclut une nouvelle fonction de threads d'E/S multiples, qui permet de répartir les E/S de disque des machines virtuelles entre plusieurs threads de calcul sur l'hôte. Ces derniers sont ensuite associés à des files d'attente de disque à l'intérieur de la machine virtuelle. Ce processus permet à la machine virtuelle d'utiliser efficacement le processeur virtuel et le processeur hôte pour les E/S multiflux, avec, à la clé, de meilleures performances.
Cet article complète la présentation de cette fonction écrite par Jenifer Abrams. Je présente les résultats de nos tests afin de vous montrer comment régler votre machine virtuelle pour améliorer le débit d'E/S.
Les tests ont été effectués avec une charge de travail d'E/S synthétique fio et des machines virtuelles Linux. D'autres tests sont prévus avec des applications ainsi que sur Microsoft Windows.
Pour en savoir plus sur la mise en œuvre de cette fonction dans KVM, lisez cet article sur IOThread Virtqueue Mapping ainsi que cet article complémentaire sur l'amélioration des performances des charges de travail de base de données sur les machines virtuelles exécutées dans un environnement Red Hat Enterprise Linux.
Description du test
Nous avons testé le débit d'E/S dans deux configurations :
- Un cluster avec un système de stockage local qui utilise le gestionnaire de volumes logiques provisionné par l'opérateur Local Storage Operator (LSO)
- Un cluster distinct qui utilise OpenShift Data Foundation (ODF)
Les configurations sont très différentes et ne peuvent pas être comparées.
Les tests ont été effectués sur des pods (comme valeur de référence) et des machines virtuelles, auxquelles 16 cœurs et 8 Go de RAM ont été alloués. J'ai utilisé des fichiers de test de 512 Go avec une machine virtuelle et de 256 Go avec deux machines virtuelles. J'ai utilisé des E/S directes dans tous les tests. Pour les machines virtuelles, j'ai utilisé des revendications de volume persistant (PVC) en mode bloc et au format ext4, et pour les pods, des PVC en mode système de fichiers également au format ext4. Tous les tests ont été exécutés avec le moteur d'E/S libaio.
J'ai testé la matrice ci-dessous :
Paramètre | Configuration |
Type de volume de stockage | Local (LSO), ODF |
Nombre de pods/machines virtuelles | 1, 2 |
Nombre de threads d'E/S (machines virtuelles uniquement) | Aucun (valeur de référence), 1, 2, 3, 4, 6, 8, 12, 16 |
Opérations d'E/S | Lectures et écritures séquentielles et aléatoires |
Taille des blocs d'E/S (en octets) | 2 000, 4 000, 32 000, 1 million |
Tâches simultanées | 1, 4, 16 |
Nombre d'E/S simultanées (iodepth) | 1, 4, 16 |
J'ai utilisé ClusterBuster pour orchestrer les tests. Les machines virtuelles utilisaient CentOS Stream 9 et les pods utilisaient une base d'image de conteneur CentOS Stream.
Stockage local
Le cluster de stockage local comptait 5 nœuds (3 de gestion et 2 de calcul) de type Dell R740xd contenant 2 processeurs Intel Xeon Gold 6130, chacun avec 16 cœurs et 2 threads (32 processeurs), soit 32 cœurs et 64 processeurs au total. Chaque nœud disposait de 192 Go de RAM. Le sous-système d'E/S contenait quatre disques NVMe Dell Kioxia CM6 MU de 1,6 To, configurés comme un périphérique agrégé RAID0 avec des paramètres par défaut. Les PVC ont été exclues de ce périphérique à l'aide de l'opérateur lvmcluster. Malheureusement, je n'avais accès qu'à cette configuration modeste. Il est fort possible qu'un système d'E/S plus rapide offre davantage d'améliorations avec des threads d'E/S multiples.
OpenShift Data Foundation
Le cluster ODF comptait 6 nœuds (3 de gestion et 3 de calcul) de type Dell PowerEdge R7625 contenant 2 processeurs AMD EPYC 9534, chacun avec 64 cœurs et 2 threads (128 processeurs), soit 128 cœurs et 256 processeurs au total. Chaque nœud disposait de 512 Go de RAM. Le sous-système d'E/S contenait deux disques NVMe de 5,8 To par nœud, avec une réplication tridirectionnelle sur un réseau de pods de 25 GbE par défaut. Je n'avais pas accès à un réseau plus rapide pour ce test. Du matériel réseau plus récent aurait probablement permis d'améliorer davantage les performances.
Synthèse des résultats
Ce test évalue des threads d'E/S multiples avec des backends d'E/S spécifiques qui ne sont pas forcément représentatifs de votre cas d'utilisation. Les différences dans les caractéristiques de stockage peuvent jouer un rôle important dans le choix du nombre de threads d'E/S.
Voici les résultats des tests.
- Débit d'E/S maximal : pour le stockage local, le débit maximal était d'environ 7,3 Go/s en lecture et 6,7 Go/s en écriture, tant pour les pods que pour les machines virtuelles, indépendamment du paramètre iodepth ou du nombre de tâches exécutées sur le stockage local. Ces résultats sont bien inférieurs à ce qui est globalement attendu du matériel. Les périphériques (chacun composé de 4 disques PCIe gen4) sont censés atteindre 6,9 Go/s en lecture et 4,2 Mo/s en écriture. Je n'ai pas cherché à comprendre ce phénomène, mais celui-ci peut s’expliquer par mon matériel, qui n'était pas vraiment récent. Les meilleures performances sont clairement supérieures à celles d'un disque seul, ce qui indique que l'agrégation par bandes a eu un effet positif. Pour ODF, nous avons obtenu 5 Go/s en lecture et 2 Go/s en écriture au maximum.
- Les E/S du grand bloc (1 Mo) ont présenté peu d'améliorations, si ce n'est aucune, car les performances étaient déjà limitées par le système.
- Le choix optimal pour le nombre de threads d'E/S varie en fonction des caractéristiques de la charge de travail et du stockage. Comme prévu, il y a eu peu d'améliorations pour les charges de travail ayant une faible simultanéité d'E/S.
- Stockage local : pour les machines virtuelles avec une simultanéité d'E/S importante, on commence généralement par 4 à 8 threads. Il peut être utile d'en prévoir davantage pour les charges de travail qui utilisent de petites E/S et une haute simultanéité.
- ODF : nous avons obtenu peu de résultats significatifs avec plus d'un thread d'E/S. Dans de nombreux cas, aucun n'a été nécessaire. La lenteur du réseau de pods est probablement en cause. Un réseau plus rapide aurait sûrement produit des résultats différents.
- Les threads d'E/S multiples se sont avérés plus efficaces lorsque plusieurs tâches étaient exécutées en simultané. Nous avons noté moins d'améliorations avec des E/S asynchrones profondes, du moins lors de ce test.
- Le comportement est resté stable avec une et deux machines virtuelles exécutées simultanément, jusqu'à ce que le débit d'E/S agrégé maximal (mentionné ci-dessus) soit atteint.
- Les threads d'E/S multiples n'ont pas complètement comblé l'écart avec les pods lorsque le nombre de tâches ou la valeur du paramètre iodepth étaient faibles. Avec une valeur iodepth élevée et de petites opérations, les machines virtuelles ont même largement dépassé les performances des pods en matière d'écriture.
Quelques chiffres
Voici le débit d'E/S global que j'obtiens avec des threads d'E/S multiples sur mon système de stockage local. Avec des charges de travail qui impliquent de petites E/S et qui se rapprochent beaucoup d'un système d'E/S rapide, les bénéfices sont considérables. Vous trouverez ci-dessous les autres améliorations obtenues avec différents nombres de threads d'E/S. Avec un bloc de 1 Mo, j'ai constaté peu d'améliorations, car les performances étaient déjà très proches de la limite du système sous-jacent. Les threads d'E/S supplémentaires donneraient probablement de bons résultats avec de grands blocs sur du matériel encore plus rapide.
Meilleure amélioration par rapport à la machine virtuelle de référence avec des threads d'E/S supplémentaires | ||||||||||
(Stockage local) | tâches | iodepth | ||||||||
1 | 4 | 16 | ||||||||
taille | opération | 1 | 4 | 16 | 1 | 4 | 16 | 1 | 4 | 16 |
2 048 | randread | 18 % | 31 % | 30 % | 30 % | 103 % | 192 % | 151 % | 432 % | 494 % |
randwrite | 81 % | 59 % | 24 % | 153 % | 199 % | 187 % | 458 % | 433 % | 353 % | |
read | 67 % | 58 % | 25 % | 64 % | 71 % | 103 % | 252 % | 241 % | 287 % | |
write | 103 % | 64 % | 0 % | 143 % | 99 % | 84 % | 410 % | 250 % | 203 % | |
Total pour 2 048 | 67 % | 53 % | 20 % | 97 % | 118 % | 141 % | 318 % | 339 % | 334 % | |
4 096 | randread | 18 % | 34 % | 28 % | 33 % | 101 % | 208 % | 156 % | 432 % | 492 % |
randwrite | 95 % | 69 % | 20 % | 149 % | 200 % | 187 % | 471 % | 543 % | 481 % | |
read | 26 % | 53 % | 27 % | 24 % | 46 % | 66 % | 142 % | 155 % | 165 % | |
write | 103 % | 69 % | 0 % | 144 % | 86 % | 48 % | 438 % | 256 % | 161 % | |
Total pour 4 096 | 60 % | 56 % | 19 % | 87 % | 108 % | 127 % | 302 % | 346 % | 325 % | |
32 768 | randread | 16 % | 23 % | 26 % | 23 % | 71 % | 124 % | 99 % | 160 % | 129 % |
randwrite | 75 % | 71 % | 28 % | 108 % | 132 % | 116 % | 203 % | 123 % | 115 % | |
read | 21 % | 57 % | 25 % | 21 % | 42 % | 32 % | 77 % | 54 % | 32 % | |
write | 79 % | 64 % | 26 % | 104 % | 59 % | 24 % | 195 % | 45 % | 27 % | |
Total pour 32 768 | 48 % | 53 % | 26 % | 64 % | 76 % | 74 % | 143 % | 96 % | 76 % | |
1 048 576 | randread | 5 % | 2 % | 0 % | 9 % | 0 % | 0 % | 17 % | 0 % | 0 % |
randwrite | 10 % | 0 % | 1 % | 6 % | 0 % | 2 % | 9 % | 0 % | 2 % | |
read | 12 % | 18 % | 0 % | 9 % | 0 % | 0 % | 16 % | 0 % | 0 % | |
write | 19 % | 0 % | 0 % | 7 % | 0 % | 0 % | 9 % | 0 % | 0 % | |
Total pour 1 048 576 | 11 % | 5 % | 0 % | 8 % | 0 % | 1 % | 13 % | 0 % | 0 % | |
Voici le nombre de threads d'E/S nécessaires pour atteindre 90 % du meilleur résultat possible, sans dépasser 16 threads d'E/S. Par exemple, si le meilleur résultat obtenu avec une opération, une taille de bloc, des tâches et une valeur iodepth spécifiques est de 1 Go/s, l'indicateur sera le plus petit nombre de threads nécessaires pour atteindre 900 Mo/s. On peut ainsi limiter le nombre de threads tout en optimisant les performances.
Nombre minimal de threads d'E/S pour atteindre 90 % des meilleures performances | ||||||||||
(Stockage local) | tâches | iodepth | ||||||||
1 | 4 | 16 | ||||||||
taille | opération | 1 | 4 | 16 | 1 | 4 | 16 | 1 | 4 | 16 |
2 048 | randread | 1 | 1 | 1 | 1 | 4 | 8 | 3 | 12 | 12 |
randwrite | 1 | 1 | 1 | 3 | 16 | 12 | 8 | 12 | 12 | |
read | 1 | 1 | 1 | 1 | 4 | 4 | 4 | 6 | 8 | |
write | 1 | 1 | 0 | 2 | 12 | 6 | 8 | 6 | 6 | |
Total pour 2 048 | 1 | 1 | 1 | 2 | 9 | 8 | 6 | 9 | 10 | |
4 096 | randread | 1 | 1 | 1 | 1 | 4 | 8 | 3 | 12 | 12 |
randwrite | 1 | 1 | 1 | 3 | 16 | 12 | 8 | 12 | 12 | |
read | 1 | 1 | 1 | 1 | 2 | 3 | 3 | 6 | 8 | |
write | 1 | 1 | 0 | 3 | 12 | 4 | 8 | 6 | 4 | |
Total pour 4 096 | 1 | 1 | 1 | 2 | 9 | 7 | 6 | 9 | 9 | |
32 768 | randread | 1 | 1 | 1 | 1 | 3 | 6 | 2 | 4 | 3 |
randwrite | 1 | 1 | 1 | 2 | 12 | 6 | 4 | 3 | 3 | |
read | 1 | 1 | 1 | 1 | 2 | 2 | 2 | 2 | 2 | |
write | 1 | 1 | 1 | 2 | 6 | 2 | 4 | 2 | 1 | |
Total pour 32 768 | 1 | 1 | 1 | 2 | 6 | 4 | 3 | 3 | 2 | |
1 048 576 | randread | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 |
randwrite | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | |
read | 1 | 1 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | |
write | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | |
Total pour 1 048 576 | 1 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | |
Résultats détaillés
Pour chaque cas de figure, j'ai calculé les facteurs de mérite suivants :
- Mesure du débit d'E/S
- Meilleures performances des machines virtuelles (qui ne sont pas directement indiquées)
- Nombre minimal de threads d'E/S pour atteindre 90 % des meilleures performances des machines virtuelles
- Rapport entre les meilleures performances des machines virtuelles et les performances des pods
- Amélioration des performances des machines virtuelles par rapport aux performances de la base de référence
Je n'indique pas le nombre de threads qui donne les meilleures performances, car dans de nombreux cas, les différences étaient minimes et inférieures à la variation normale dans l'état des performances d'E/S.
Je sépare les résultats pour le stockage local et pour ODF en raison de leur grande différence de caractéristiques.
Tous les graphiques de performance ci-dessous montrent les résultats pour les pods (pod), pour une machine virtuelle de référence sans thread d'E/S (0) et pour le nombre spécifié de threads d'E/S sur l'axe des abscisses.
Stockage local
Les performances brutes montrent qu'au moins dans certains cas, l'utilisation de plusieurs threads d'E/S entraîne des progrès considérables. Par exemple, sur le stockage local avec 16 tâches et une E/S asynchrone dotée d'une valeur iodepth de 1, des threads d'E/S supplémentaires peuvent donner des résultats très intéressants :
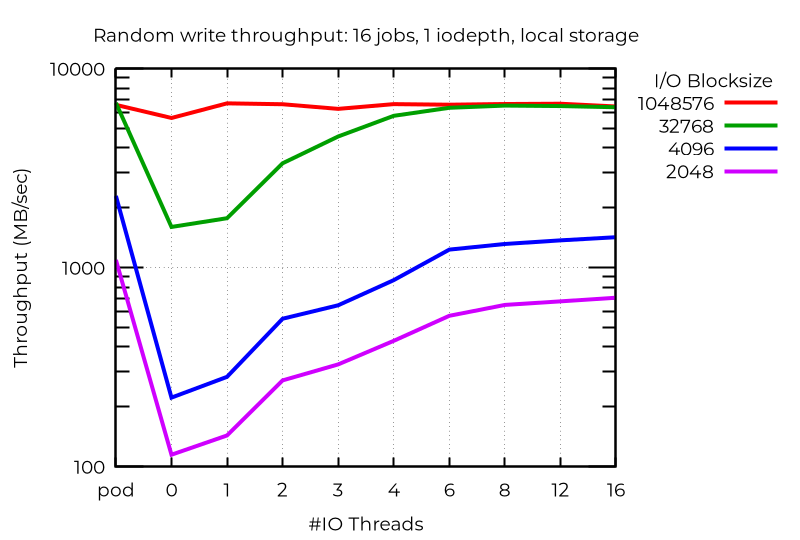
Même avec un seul flux d'E/S, l'utilisation d'un thread d'E/S supplémentaire peut apporter des bénéfices. Sans surprise, aucune amélioration ne survient si l'on en utilise plusieurs :

Il existe aussi des anomalies dans lesquelles les threads d'E/S supplémentaires s'avèrent contre-productifs. Dans ce cas, avec des E/S asynchrones profondes et de petits blocs, les meilleures performances (plus élevées que celles des pods) sont obtenues avec des machines virtuelles qui n'utilisent pas de threads d'E/S dédiés. Je ne peux l'expliquer.
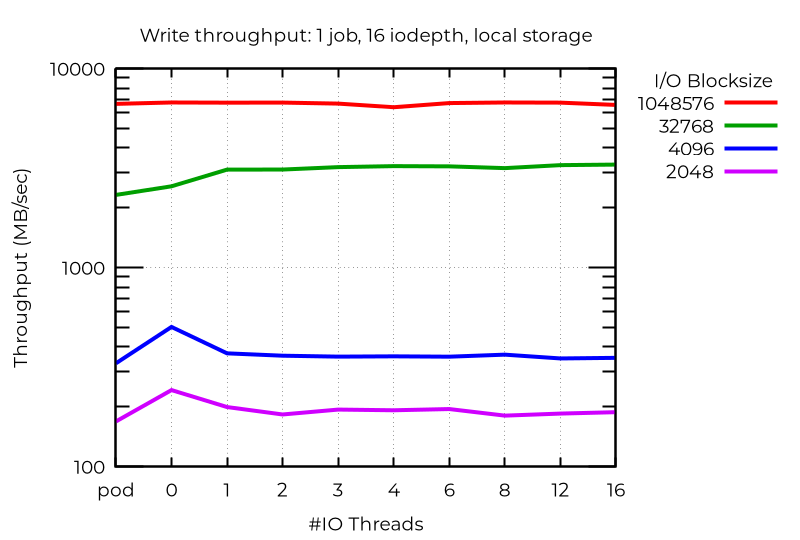
Ainsi, pour obtenir les meilleures performances avec plusieurs threads d'E/S, il faut effectuer des tests avec votre charge de travail spécifique.
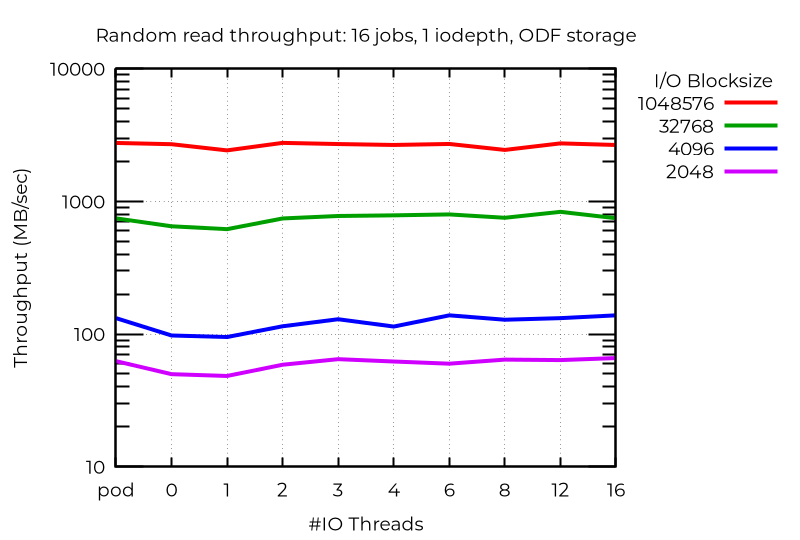
Résultats du cluster ODF
Contrairement au stockage local, où l'écriture aléatoire avec de petits blocs et plusieurs threads d'E/S s'est montrée efficace, j'ai constaté peu d'améliorations avec ODF, même en exécutant de nombreuses tâches. Il est probable qu'un réseau plus rapide ou à latence plus faible donne de meilleurs résultats. Les opérations de lecture, en particulier en mode aléatoire, ont présenté quelques avancées, mais les opérations d'écriture et les petits nombres de tâches n'ont presque pas évolué (voire pas du tout).
Conclusion
Les threads d'E/S multiples pour OpenShift Virtualization sont une nouvelle fonction très intéressante d'OpenShift 4.19 qui peut améliorer considérablement les performances d'E/S des charges de travail avec des E/S simultanées, en particulier pour les systèmes d'E/S rapides, tels que le stockage NVMe local utilisé dans mes tests. Les sous-systèmes d'E/S plus rapides devraient bénéficier davantage de plusieurs threads d'E/S, car il faut plus de processeurs pour assurer le bon fonctionnement des E/S bare metal sous-jacentes. Comme toujours pour les E/S, les différences entre les systèmes d'E/S et les charges de travail globales peuvent avoir un effet important sur les performances. C'est pourquoi je vous recommande de tester vos propres charges de travail afin de tirer le meilleur parti de cette nouvelle fonction. J'espère que les résultats de mon test vous guideront dans vos choix de threads d'E/S.
Essai de produit
Red Hat OpenShift Virtualization Engine | Essai de produit
À propos de l'auteur
Plus de résultats similaires
La virtualisation en 2026 : création d'une plateforme pour les VM, les conteneurs et l'IA
Cessez de gérer le passé et commencez à bâtir l'avenir de l'informatique
Parcourir par canal

Automatisation
Les dernières nouveautés en matière d'automatisation informatique pour les technologies, les équipes et les environnements

Intelligence artificielle
Actualité sur les plateformes qui permettent aux clients d'exécuter des charges de travail d'IA sur tout type d'environnement

Cloud hybride ouvert
Découvrez comment créer un avenir flexible grâce au cloud hybride

Sécurité
Les dernières actualités sur la façon dont nous réduisons les risques dans tous les environnements et technologies

Edge computing
Actualité sur les plateformes qui simplifient les opérations en périphérie

Infrastructure
Les dernières nouveautés sur la plateforme Linux d'entreprise leader au monde

Applications
À l’intérieur de nos solutions aux défis d’application les plus difficiles
Virtualisation
L'avenir de la virtualisation d'entreprise pour vos charges de travail sur site ou sur le cloud