

Introduction
Il est essentiel de prévoir une stratégie de récupération après sinistre pour les machines virtuelles sur Red Hat OpenShift afin d'assurer la continuité des activités en cas de temps d'arrêt non planifié. Les entreprises qui migrent leurs charges de travail critiques vers des plateformes Kubernetes doivent pouvoir les récupérer rapidement et de manière fiable pour garantir leur disponibilité.
Bien que les machines virtuelles stateless éphémères se soient généralisées dans les environnements cloud-native, la plupart des charges de travail de machines virtuelles d'entreprise restent stateful. Ces machines virtuelles nécessitent un stockage persistant en mode bloc qui peut être rattaché après un redémarrage ou une migration. Par conséquent, la récupération après sinistre des machines virtuelles stateful pose des défis différents de ceux des anciens modèles de récupération après sinistre Kubernetes (Spazzoli, 2024), qui se concentrent généralement sur les applications stateless basées sur des conteneurs.
Cet article de blog présente les exigences propres aux machines virtuelles stateful. Nous commencerons par étudier l'impact des choix d'architectures de cluster et de stockage sur la faisabilité des basculements, le comportement de réplication et les objectifs de RPO/RTO. Nous examinerons ensuite la couche d'orchestration et verrons comment les outils natifs pour Kubernetes, tels que Red Hat Advanced Cluster Management, Helm, Kustomize et les pipelines GitOps régissent le placement des charges de travail et la récupération. Enfin, nous expliquerons comment les plateformes de stockage avancées qui répliquent à la fois le stockage en mode bloc et les manifestes Kubernetes peuvent rationaliser le processus de récupération et relier l'infrastructure à l'aide de l'automatisation au niveau des applications.
Explications terminologiques
Avant de poursuivre, prenons le temps de définir quelques termes importants.
Sinistre :
Dans le contexte de cet article, le terme « sinistre » fait référence à une « perte de site ». L'objectif d'une récupération après sinistre est de réduire au maximum les perturbations pour un service métier. Ainsi, lorsque vous perdez un site, vous devez mettre en œuvre vos plans de récupération après sinistre pour rétablir le service sur un autre site aussi rapidement et efficacement que possible.
Remarque : l'exécution d'un plan de récupération après sinistre n'intervient pas uniquement en cas de perte d'un site. Il n'est pas rare d'appliquer ces plans à des services métier individuels lorsqu'une défaillance d'un composant majeur entraîne le déplacement de services métier individuels vers un autre site pendant la restauration du composant défaillant.
Défaillance de composant :
La défaillance d'un composant désigne une panne d'un ou de plusieurs sous-systèmes qui entraîne des répercussions sur un sous-ensemble d'applications métier au sein de l'entreprise. Ce mode de défaillance oblige à basculer l'exécution vers un autre système du site principal ou à appliquer des plans individuels de récupération après sinistre pour déplacer l'exécution de l'application métier vers un site secondaire.
Objectif de point de récupération (RPO) :
Il s'agit de la quantité maximale de données (mesurée dans le temps) qui risquent d'être perdues à la suite d'un sinistre ou d'une défaillance, avant que la perte de données ne dépasse le niveau acceptable pour une entreprise.
Objectif de délai de récupération (RTO) :
Il s'agit de la durée maximale pendant laquelle une entreprise peut tolérer l'indisponibilité d'un service. Bien que les différents types d'architectures influencent le RTO, nous n'aborderons pas ce sujet en détail dans cet article de blog.
Récupération après sinistre sur site ou récupération après sinistre régionale :
Il existe deux types de récupérations après sinistre : la récupération sur site et la récupération régionale.
- La récupération après sinistre sur site s'applique lorsque les datacenters sont suffisamment proches et que les performances réseau permettent la réplication synchrone des données. La réplication synchrone permet d'atteindre un RPO égal à zéro.
- La récupération après sinistre régionale s'applique lorsqu'une réplication asynchrone est nécessaire, car les datacenters sont trop éloignés pour prendre en charge la réplication synchrone. La réplication asynchrone entraîne presque toujours une perte de données, mais la quantité de données perdues n'est pas l'objet de cet article.
Remarque : si votre infrastructure de stockage ne prend pas en charge la réplication synchrone, vous devrez utiliser une architecture de récupération après sinistre régionale, même si vos datacenters sont suffisamment proches pour une récupération sur site.
Restart storm :
Une « restart storm » (littéralement « tempête de redémarrages »), est un événement qui se produit lorsque le nombre de machines virtuelles que vous essayez de redémarrer simultanément est trop élevé pour l'hyperviseur et l'infrastructure sous-jacente. Résultat : aucune machine virtuelle ne peut redémarrer ou le redémarrage prend trop de temps. Ce phénomène ressemble à une attaque par déni de service.
Approches architecturales pour la continuité des activités
Il existe plusieurs approches permettant d'assurer la continuité des activités et la récupération après sinistre. Si vous cherchez une présentation générale du sujet, consultez le livre blanc Cloud Native Disaster Recovery for Stateful Workloads (Spazzoli, 2024) de la Cloud Native Computing Foundation (CNCF). Le schéma suivant illustre dans les grandes lignes quatre approches de la récupération après sinistre (une explication détaillée de chacune d'entre elles est disponible dans le livre blanc) :
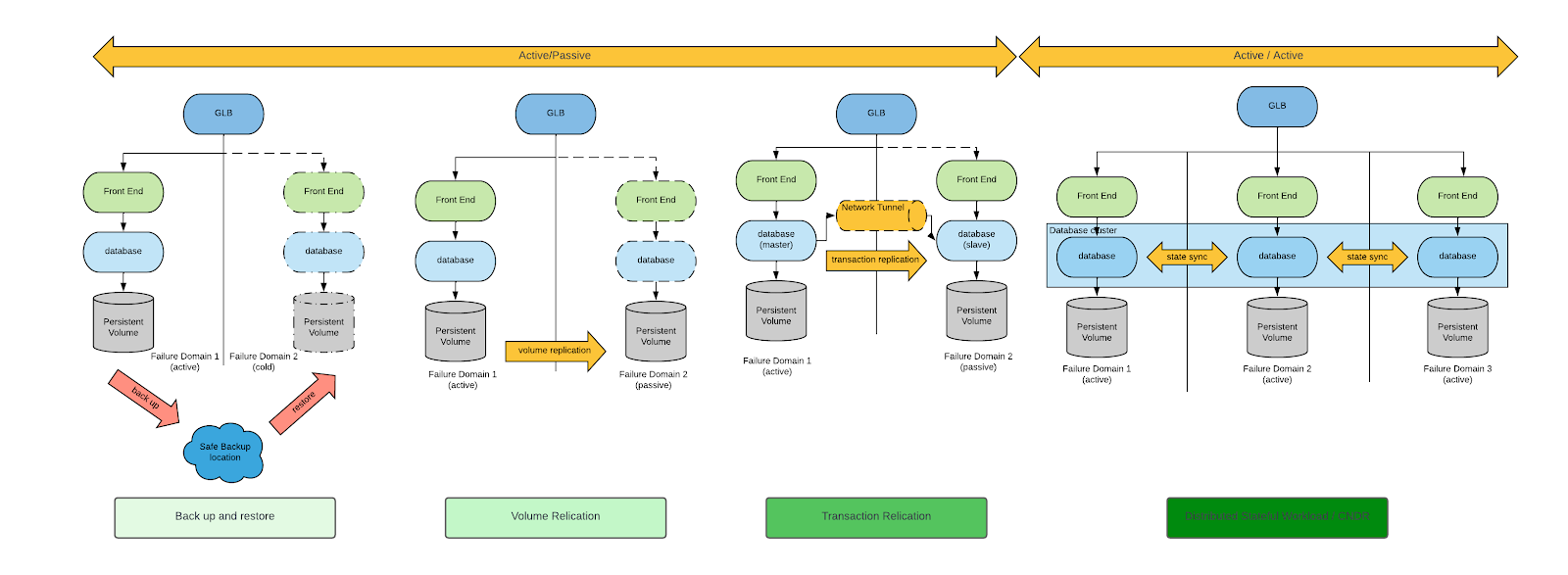
En tenant compte des exigences des machines virtuelles, les seuls modèles de récupération après sinistre envisageables sont la sauvegarde et la restauration, ainsi que la réplication de volume.
Ces deux approches sont parfaitement viables, mais la réplication de volume réduit à la fois le RPO et le RTO. Par conséquent, nous nous concentrerons uniquement sur ce modèle de récupération.
Maintenant que nous avons réduit notre champ d'analyse, nous allons présenter deux architectures de récupération après sinistre qui se distinguent par le type de réplication de volume :
- Réplication unidirectionnelle
- Réplication symétrique ou bidirectionnelle
Réplication unidirectionnelle
Avec cette approche, la réplication des volumes entre les datacenters est à sens unique. Le sens de réplication est contrôlé via la baie de stockage et la réplication peut être synchrone ou asynchrone. Ce choix dépend de la capacité de la baie de stockage et de la latence entre les deux datacenters. La réplication asynchrone convient aux datacenters séparés par une latence élevée, situés généralement dans une même région du monde, mais pas dans la même agglomération.
Sur le plan architectural, la réplication unidirectionnelle se présente comme sur la figure suivante :
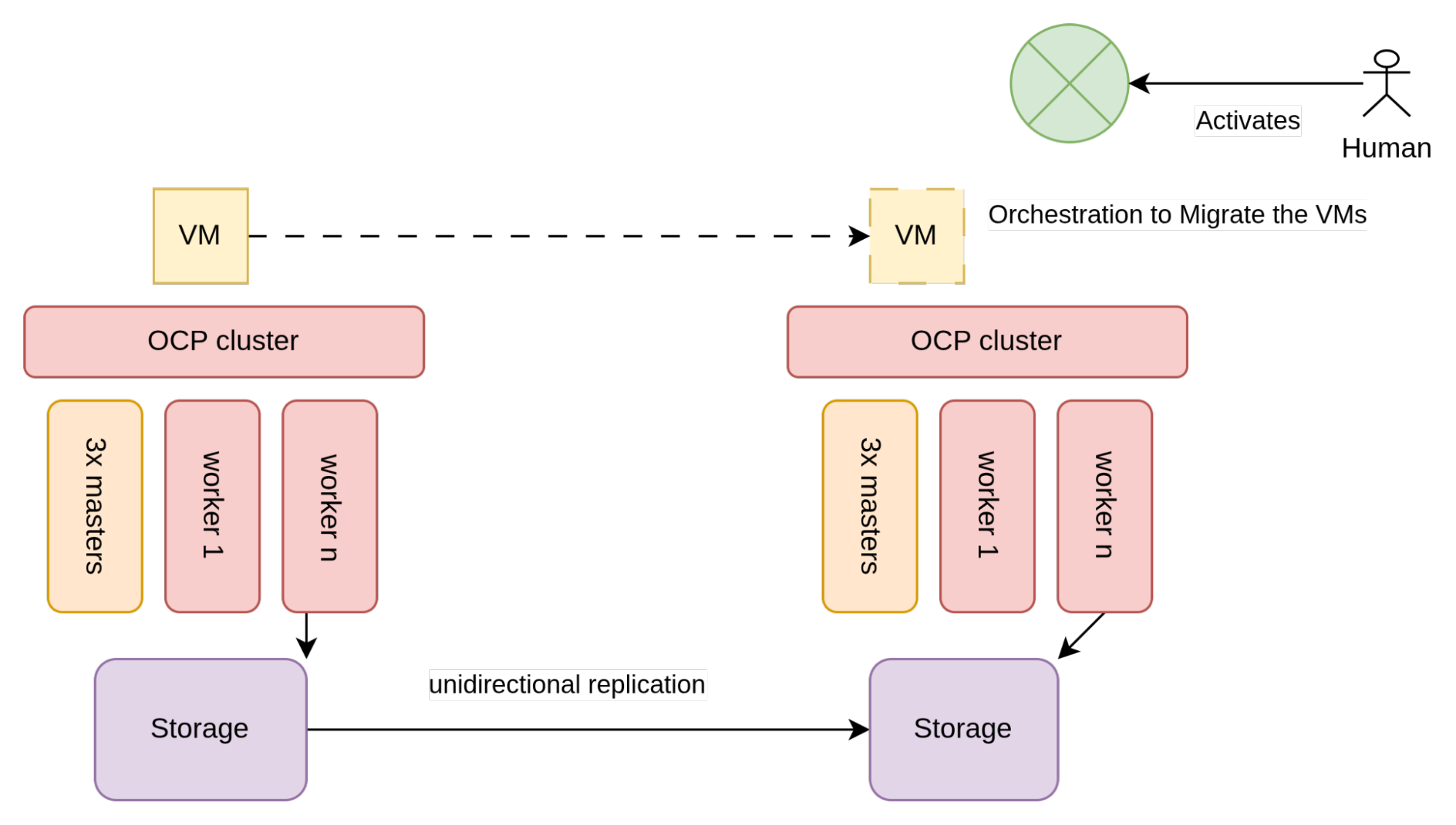
Comme illustré sur la figure 2, le stockage utilisé par les machines virtuelles (généralement des baies SAN) est configuré pour permettre la réplication unidirectionnelle.
Il existe deux clusters OpenShift différents dans chaque datacenter, qui sont connectés à la baie de stockage locale. Les clusters agissent de manière indépendante. Par conséquent, les seules contraintes pour mettre en œuvre cette architecture proviennent du fournisseur de stockage, et plus précisément des exigences à respecter pour permettre une réplication unidirectionnelle.
Spécificités de la réplication de volume unidirectionnelle
La réplication de volume n'est pas standardisée dans la spécification CSI Kubernetes. C'est pourquoi les fournisseurs de stockage ont créé des définitions de ressources personnalisées propriétaires. Cette réplication est disponible chez des fournisseurs de trois niveaux de maturité différents :
- La réplication de volume n'est pas disponible au niveau CSI, ou elle ne permet pas de créer une orchestration de récupération après sinistre correcte sans appeler directement l'API de la baie de stockage.
- La réplication de volume est disponible au niveau CSI.
- La réplication de volume est disponible et le fournisseur gère également la restauration des métadonnées de l'espace de noms (c'est-à-dire les machines virtuelles et autres manifestes présents dans l'espace de noms).
Compte tenu de cette fragmentation, il n'est pas simple de créer un processus de récupération après sinistre indépendant de tout fournisseur pour une configuration régionale. Le volume de données à écrire pour créer une orchestration de récupération après sinistre appropriée dépend du fournisseur de stockage.
Examinons le comportement de cette architecture dans différents scénarios de défaillance : défaillance d'un nœud OpenShift, défaillance d'une baie de stockage (défaillance de composant) et défaillance d'un datacenter complet (le scénario type de récupération après sinistre).
Défaillance d'un nœud OpenShift
En cas de défaillance d'un nœud (composant), le planificateur OpenShift Virtualization se charge du redémarrage automatique de la machine virtuelle sur le nœud le plus approprié du cluster. Ce scénario ne requiert en général aucune autre action.
Défaillance d'une baie de stockage
En cas de panne d'une baie de stockage, toutes les machines virtuelles qui dépendent de cette baie cessent également de fonctionner. Dans ce scénario, il faut lancer le processus de récupération après sinistre. (Pour connaître les étapes à suivre, reportez-vous à la section Processus de récupération après sinistre.)
Défaillance du datacenter
En cas de défaillance du datacenter, il faut lancer le processus de récupération après sinistre pour redémarrer toutes les machines virtuelles du datacenter qui ne sont pas affectées par la panne. L'automatisation joue ici un rôle clé. Cependant, le processus est généralement lancé par un humain dans le cadre d'une procédure de gestion des incidents majeurs. La section suivante en présente les grandes étapes.
Processus de récupération après sinistre
Les procédures de récupération après sinistre peuvent devenir très complexes, mais nous allons tenter de les expliquer de manière simple. Voici quelques éléments à prendre en compte pour tout processus de récupération après sinistre :
- Les volumes des machines virtuelles qui font partie de la même application doivent être répliqués de manière cohérente. En d'autres termes, les volumes de ces machines virtuelles font partie du même groupe de cohérence.
- L'utilisateur doit pouvoir décider si les volumes d'un groupe de cohérence doivent être répliqués et dans quel sens. En temps normal, les volumes sont répliqués du site actif vers le site passif. Durant un basculement (ou « failover »), les volumes ne sont pas répliqués. Pendant la phase de préparation au rétablissement (ou « failback »), les volumes sont répliqués du site passif vers le site actif. Au moment du rétablissement, les volumes ne sont pas répliqués.
- Il doit être possible de redémarrer les machines virtuelles dans l'autre datacenter et elles doivent pouvoir se connecter au volume de stockage répliqué.
- Le nombre de redémarrages peut être limité pour éviter une « restart storm ». De plus, il est souvent préférable de hiérarchiser la séquence de redémarrage des machines virtuelles afin que les applications les plus critiques démarrent en premier ou pour s'assurer que les composants indispensables, tels que les bases de données, puissent démarrer avant les services qui en dépendent.
Remarques au sujet des coûts
Selon la configuration du cluster OpenShift, il peut être considéré comme un site de récupération après sinistre intermédiaire ou à chaud. Les sites à chaud doivent être couverts par une souscription complète, contrairement aux sites intermédiaires, qui coûtent donc potentiellement moins cher.
En général, un site de récupération après sinistre est considéré comme intermédiaire si aucune charge de travail n'y est exécutée. Dans les faits, il est possible de configurer des volumes persistants, des revendications de volume persistant et même des machines virtuelles inactives, prêtes à être démarrées en cas de sinistre, sans que le site ne passe au statut à chaud.
Configuration active/passive symétrique
Rares sont les entreprises qui placent l'intégralité de leurs charges de travail sur le site actif. Elles optent plutôt pour une répartition à 50/50 entre les datacenters principal et secondaire. Cette approche pratique garantit qu'un sinistre n'entraînera jamais la défaillance de tous les services en même temps. De plus, l'effort global de récupération est réduit en conséquence.
Lors de la distribution de machines virtuelles actives entre les datacenters, chaque moitié est configurée de manière à pouvoir basculer vers l'autre. Cette configuration est parfois appelée active/passive symétrique.
Cette approche fonctionne avec OpenShift Virtualization et l'architecture que nous avons examinée ci-dessus. N'oubliez pas qu'avec une configuration active/passive symétrique, les deux datacenters sont considérés comme actifs, ce qui implique de couvrir tous les nœuds OpenShift par une souscription.
Réplication symétrique
Avec la réplication symétrique, les volumes sont répliqués de manière synchrone et dans les deux sens. Par conséquent, les deux datacenters peuvent disposer de volumes actifs et autoriser l'accès en écriture. Pour utiliser ce type de configuration, l'entreprise doit posséder deux datacenters séparés par une latence très faible (< 5 ms). Cette architecture, aussi appelée récupération après sinistre sur site, implique en règle générale que les deux datacenters se trouvent dans la même ville. En voici un schéma :

Dans cette architecture, le stockage utilisé par les machines virtuelles (généralement une baie SAN) est configuré pour effectuer une réplication symétrique entre les deux datacenters.
Une baie de stockage logique étendue sur les deux datacenters est ainsi créée. Pour permettre une réplication symétrique, il est nécessaire de disposer d'un « site témoin » qui agit comme un régulateur indépendant afin d'éviter les scénarios de type « split-brain » (littéralement, « cerveau scindé ») en cas de défaillance d'un réseau ou d'un site.
Le site témoin n'a pas besoin d'être aussi proche (en termes de latence) que les deux datacenters principaux, car il est utilisé pour créer un seuil minimal et résoudre les situations de « split-brain ». Le site témoin doit être une zone de disponibilité indépendante, qui n'accepte aucune charge de travail d'applications et n'a pas besoin d'une capacité importante, mais il doit offrir la même qualité de service que l'autre datacenter au niveau de l'exploitation (p. ex. sécurité informatique, gestion de l'énergie et refroidissement).
Puisque le stockage est étendu sur plusieurs datacenters, OpenShift est déployé par-dessus cette infrastructure distribuée. Pour garantir une haute disponibilité avec cette configuration, trois zones de disponibilité (ou sites) sont nécessaires pour héberger les nœuds du plan de contrôle d'OpenShift. Cette contrainte s'explique par le fait que la base de données etcd de Kubernetes exige au moins trois domaines de défaillance distincts pour pouvoir maintenir un seuil minimal fiable. Aussi, cette configuration repose souvent sur l'utilisation du site témoin de stockage pour héberger l'un des nœuds du plan de contrôle.
La plupart des fournisseurs de réseaux SAN prennent en charge la réplication symétrique de leurs baies de stockage. Cependant, tous les fournisseurs ne proposent pas cette fonctionnalité au niveau de l'interface CSI. En supposant qu'un fournisseur de stockage prenne en charge la réplication symétrique au niveau de son plugin CSI, et en supposant que les conditions préalables et les configurations nécessaires soient respectées, un LUN multipath (c'est-à-dire, à plusieurs chemins) est provisionné à la création d'une revendication de volume persistant. Ce LUN inclut des chemins vers les deux datacenters, de sorte que tous les nœuds OpenShift doivent être configurés pour permettre la connectivité aux deux baies de stockage. Le périphérique multipath est généralement créé soit avec une configuration ALUA (Asymmetric Logical Unit Access) (Pearson IT Certification, 2024), par exemple une configuration active/passive dans laquelle le chemin actif est celui du réseau le plus proche, soit avec une voie active/active présentant des pondérations différentes, dans laquelle la baie la plus proche a plus de poids.
Certains fournisseurs autorisent même l'utilisation de cette architecture lorsque les connexions Fibre Channel ne sont pas « uniformisées », ce qui signifie que les nœuds d'un site ne peuvent se connecter qu'à la baie de stockage locale. Dans ce cas, la configuration ALUA n'est évidemment pas créée.
Cette topologie de cluster contribue à assurer la protection contre les défaillances de composants et les sinistres. Examinons maintenant le comportement de cette architecture dans différents scénarios de défaillance.
Défaillance d'un nœud OpenShift
En cas de défaillance d'un nœud (composant), le planificateur OpenShift Virtualization se charge du redémarrage automatique de la machine virtuelle sur le nœud le plus approprié du cluster. Ce scénario ne requiert en général aucune autre action.
Défaillance d'une baie de stockage
Les LUN multipath contribuent à assurer la continuité du service si l'une des deux baies de stockage tombe en panne ou est mise hors ligne à des fins de maintenance. Dans un scénario de connectivité uniforme, la voie passive ou moins pondérée des LUN multipath est utilisée pour connecter la machine virtuelle aux autres baies. Cette défaillance est totalement transparente pour les machines virtuelles, ce qui peut entraîner une légère augmentation de la latence d'E/S du disque. Dans un scénario de connectivité non uniforme, la machine virtuelle doit être migrée vers un nœud connecté.
Défaillance du datacenter
L'indisponibilité d'un datacenter entier est perçue par OpenShift comme une panne simultanée de plusieurs nœuds. OpenShift commence à planifier les machines virtuelles vers des nœuds dans l'autre datacenter, comme décrit dans la section sur la défaillance de nœuds OpenShift.
En supposant qu'il y ait suffisamment de capacité de réserve pour que les charges de travail puissent y migrer, toutes les machines finiront par redémarrer dans l'autre datacenter. Les machines virtuelles qui ont redémarré présentent un RPO de zéro et un RTO correspondant à la somme des durées suivantes :
- Durée nécessaire à OpenShift pour détecter que les nœuds ne sont pas prêts
- Durée nécessaire pour isoler les nœuds
- Durée nécessaire pour redémarrer les machines virtuelles
- Durée nécessaire pour terminer le processus de démarrage de la machine virtuelle
Ce mécanisme de récupération après sinistre est entièrement autonome et ne nécessite aucune intervention humaine, ce qui n'est pas toujours souhaitable. Pour éviter une « restart storm », il est préférable de pouvoir choisir les machines virtuelles qui seront redémarrées et à quel moment.
Remarques sur la récupération après sinistre sur site
Voici quelques éléments à prendre en compte concernant cette approche :
- Étant donné que les machines virtuelles sont généralement connectées à des VLAN, il est nécessaire que ces VLAN soient également étendus entre les deux datacenters sur site pour qu'elles puissent naviguer entre les deux. Dans certains cas, cette contrainte n'est pas souhaitable.
- Il arrive souvent que le réseau de gestion du site témoin (réseau de nœuds OpenShift) ne se trouve pas dans le même sous-réseau L2 que le réseau de gestion des datacenters sur site.
- Certains spécialistes ne considèrent pas cette solution comme complète, car le plan de contrôle OpenShift et le plan de contrôle de la baie de stockage représentent deux points de défaillance unique. Ce point de défaillance unique ne l'est que d'un point de vue logique, car il existe bel et bien une redondance matérielle. Cependant, il est vrai qu'une seule commande erronée au niveau d'OpenShift ou de la baie de stockage peut, en théorie, effacer l'ensemble de l'environnement. C'est pourquoi cette architecture est parfois reliée à une architecture de récupération après sinistre régionale plus traditionnelle pour les charges de travail les plus critiques.
- Sans intervention humaine, pendant une récupération après sinistre, OpenShift replanifie automatiquement le redémarrage de toutes les machines virtuelles du datacenter affecté sur le datacenter sain. Cette opération peut provoquer un phénomène appelé « restart storm » (littérallement « tempête de redémarrage »). Certaines fonctions Kubernetes contribuent à réduire ce risque en permettant de décider quelles applications basculent et à quel moment.
Remarques au sujet des coûts
Avec la réplication symétrique, les deux sites doivent être entièrement couverts par une souscription, car ils appartiennent à un seul cluster OpenShift actif. Comme pour la réplication unidirectionnelle, chaque site doit être intégralement surprovisionné, ce qui permet un basculement à 100 % de l'autre site.
Conclusion
Le choix de l'architecture de réplication, unidirectionnelle ou symétrique, conditionne toute la stratégie de récupération après sinistre sur OpenShift Virtualization. Chaque modèle implique des compromis entre la complexité de l'exploitation, le coût de l'infrastructure, les garanties RPO/RTO et le potentiel d'automatisation. Que vous optiez pour une configuration à deux clusters ou à clusters étendus, l'architecture de base doit s'adapter aux attentes en matière de continuité des activités et aux contraintes liées à l'infrastructure. Maintenant que nous avons posé les bases, nous aborderons dans la partie 2 la question de l'orchestration. Nous irons au-delà du stockage pour examiner comment les machines virtuelles sont placées, redémarrées et contrôlées en cas de sinistre.
Essai de produit
Red Hat OpenShift Virtualization Engine | Essai de produit
À propos des auteurs
Bryon is a skilled infrastructure and software engineering specialist with deep expertise in AI/ML, Kubernetes, OpenShift, cloud-native architecture, and enterprise networking. With a strong background in storage technologies, infrastructure, and virtualisation, Bryon works across domains including system administration, AI model deployment, and platform engineering. He is proficient in C#, Golang and Python, experienced in container orchestration, and actively contributes to Red Hat-based solutions. Passionate about education and enablement, Bryon frequently develops technical workshops and training programs, particularly in AI/ML and DevOps. He is also a practising musician, blending his technical acumen with creative expression.
Raffaele is a full-stack enterprise architect with 20+ years of experience. Raffaele started his career in Italy as a Java Architect then gradually moved to Integration Architect and then Enterprise Architect. Later he moved to the United States to eventually become an OpenShift Architect for Red Hat consulting services, acquiring, in the process, knowledge of the infrastructure side of IT.
Currently Raffaele covers a consulting position of cross-portfolio application architect with a focus on OpenShift. Most of his career Raffaele worked with large financial institutions allowing him to acquire an understanding of enterprise processes and security and compliance requirements of large enterprise customers.
Raffaele has become part of the CNCF TAG Storage and contributed to the Cloud Native Disaster Recovery whitepaper.
Recently Raffaele has been focusing on how to improve the developer experience by implementing internal development platforms (IDP).
Plus de résultats similaires
Les menaces liées à l'IA évoluent. Vos défenses doivent en faire autant.
Au-delà de l'automatisation : pourquoi la montée des vulnérabilités de sécurité liées à l'IA exige une expertise technique humaine
Untangling Networks | Compiler
Technically Speaking | Defining sovereign AI with open source
Parcourir par canal

Automatisation
Les dernières nouveautés en matière d'automatisation informatique pour les technologies, les équipes et les environnements

Intelligence artificielle
Actualité sur les plateformes qui permettent aux clients d'exécuter des charges de travail d'IA sur tout type d'environnement

Cloud hybride ouvert
Découvrez comment créer un avenir flexible grâce au cloud hybride

Sécurité
Les dernières actualités sur la façon dont nous réduisons les risques dans tous les environnements et technologies

Edge computing
Actualité sur les plateformes qui simplifient les opérations en périphérie

Infrastructure
Les dernières nouveautés sur la plateforme Linux d'entreprise leader au monde

Applications
À l’intérieur de nos solutions aux défis d’application les plus difficiles
Virtualisation
L'avenir de la virtualisation d'entreprise pour vos charges de travail sur site ou sur le cloud