

Introduzione
Per mantenere la continuità operativa in caso di interruzioni non pianificate, è indispensabile disporre di strategie di ripristino di emergenza per le macchine virtuali (VM) su Red Hat OpenShift. Man mano che le organizzazioni eseguono la migrazione dei carichi di lavoro critici sulle piattaforme Kubernetes, la capacità di ripristinare tali carichi in modo rapido e affidabile diventa un requisito operativo fondamentale.
Sebbene le VM temporanee e stateless siano ormai comuni negli ambienti cloud native, la maggior parte dei carichi di lavoro delle VM aziendali è ancora stateful. Queste VM devono disporre di uno storage a blocchi permanente che possa essere nuovamente collegato durante i riavvii o le migrazioni. Per questa ragione, il ripristino di emergenza delle VM stateful presenta sfide molto diverse da quelle riscontrate nei modelli di ripristino di emergenza Kubernetes precedenti (Spazzoli, 2024), in genere pensati per le applicazioni containerizzate stateless.
Questo articolo del blog esamina i diversi requisiti delle VM stateful, partendo dalla selezione dei cluster e dell'architettura di storage e dal loro impatto sulla fattibilità del failover, sul comportamento di replica e sugli obiettivi RPO/RTO. Viene quindi considerato il livello dell'orchestrazione, mostrando in che modo gli strumenti Kubernetes native, come Red Hat Advanced Cluster Management, Helm, Kustomize e le pipeline GitOps gestiscono il posizionamento e il ripristino dei carichi di lavoro. Infine, l'articolo del blog esamina come le piattaforme di storage avanzate che replicano sia lo storage a blocchi che i manifest Kubernetes possono semplificare il processo di ripristino e connettere l'infrastruttura e l'automazione a livello di applicazioni.
Definizioni terminologiche
Prima di procedere, è bene definire alcuni termini importanti:
Evento di emergenza
Nel contesto di questo articolo, il termine "emergenza" si riferisce alla "perdita di un sito".Quando parliamo di ripristino di emergenza, intendiamo sempre le azioni intraprese per ridurre al minimo l'interruzione operativa di un servizio aziendale. Quando si perde un sito, è necessario attivare i piani utili per ripristinare il servizio nel sito alternativo nel modo più rapido ed efficiente possibile.
Nota: un piano di ripristino di emergenza non viene eseguito solo in caso di perdita di un sito. È prassi comune attivare piani di ripristino di emergenza per i singoli servizi aziendali quando si verifica un guasto di un componente principale che richiede il trasferimento dei singoli servizi al sito alternativo mentre il componente guasto viene ripristinato.
Errore di un componente
È l'errore di uno o più sottosistemi che ha impatto su un sottoinsieme di applicazioni aziendali dell'organizzazione. Questa modalità di errore richiede il failover dei processi su un sistema alternativo nel sito principale oppure l'adozione di singoli piani di ripristino di emergenza per trasferire i processi dell'applicazione aziendale su un sito secondario.
Recovery Point Objective (RPO)
Per obiettivo RPO si intende la quantità massima di dati (misurata in base al tempo) che può andare persa dopo un ripristino da un'emergenza o da un errore e prima che tale perdita superi il valore accettabile per un'organizzazione.
Recovery Time Objective (RTO)
Per obiettivo RTO si intende il periodo di tempo massimo di indisponibilità di un servizio tollerabile da un'organizzazione. Le diverse scelte architetturali possono incidere sugli obiettivi RTO, ma queste considerazioni esulano dall'ambito di questo articolo del blog.
Ripristino di emergenza Metro e Regional
Sono disponibili due tipi di ripristino di emergenza: Metro e Regional.
- Il ripristino di emergenza Metro è indicato per le situazioni in cui i datacenter sono sufficientemente vicini e le prestazioni della rete consentono la replica dei dati sincrona, che offre il vantaggio di garantire obiettivi RPO pari a zero.
- Il ripristino di emergenza Regional è indicato per le situazioni in cui è necessario utilizzare la replica asincrona perché i datacenter sono troppo distanti per supportare la replica sincrona. Quasi sicuramente la replica asincrona comporta una perdita di dati; la quantità di dati persi non è rilevante ai fini di questo articolo del blog.
Nota: se l'infrastruttura di storage non supporta la replica sincrona, per il ripristino di emergenza Metro viene utilizzata un'architettura di ripristino Regional.
Riavvio storm
Si ha un riavvio storm quando il numero di VM che si tenta di riavviare contemporaneamente è così elevato che l'hypervisor e l'infrastruttura di supporto non riescono a sostenerlo: nessuna VM riesce ad avviarsi o la VM che si riavvia accetta un numero di comandi troppo alto rispetto a quanti ne possa sostenere. L'evento può anche essere descritto come un attacco denial of service non dannoso.
Approcci architetturali alla continuità operativa
Sono diversi gli approcci in grado di assicurare la continuità operativa e il ripristino di emergenza. Per una trattazione generale dell'argomento, leggi il white paper Cloud Native Disaster Recovery for Stateful Workloads (Spazzoli, 2024) della Cloud Native Computing Foundation (CNCF). Il diagramma seguente presenta per grandi linee i quattro approcci tipici al ripristino di emergenza (nel white paper è inclusa una spiegazione approfondita di ciascuno di questi approcci):
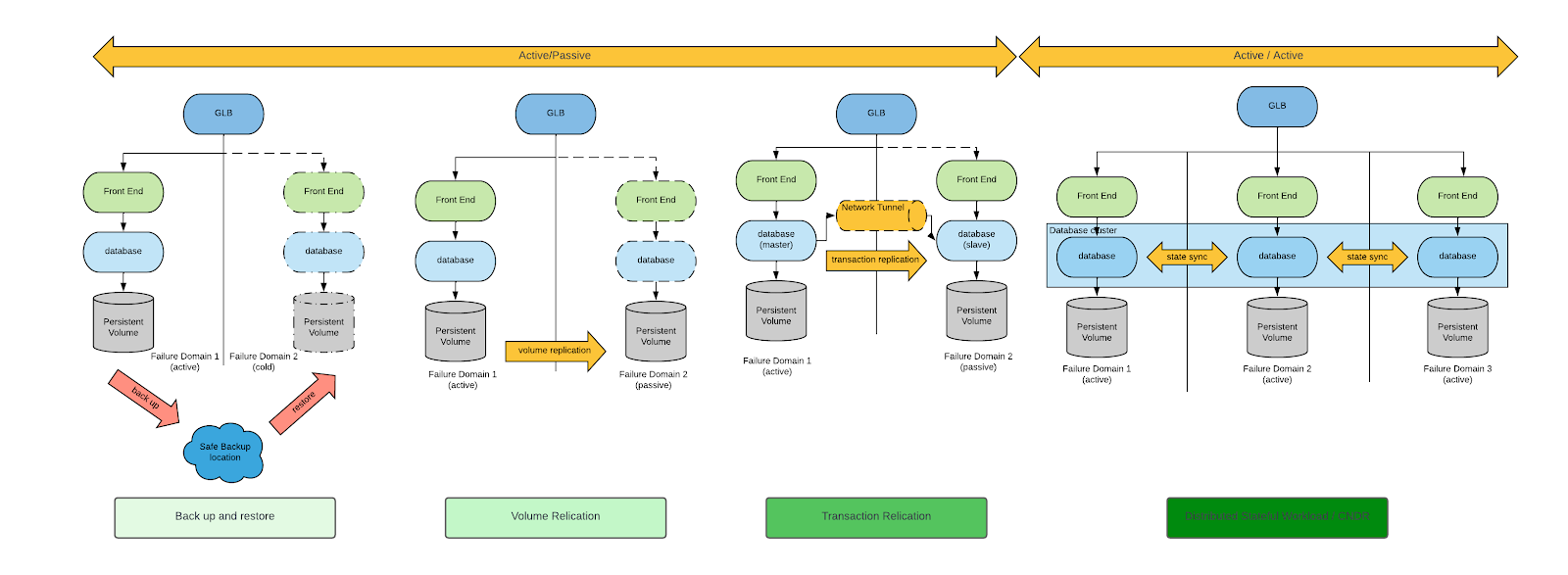
Considerando i requisiti di ripristino di emergenza per le VM, backup, ripristino e replica dei volumi risultano essere gli unici schemi di ripristino adeguati.
Sebbene siano entrambi praticabili, gli approcci basati sulla replica dei volumi riducono al minimo sia gli obiettivi RPO che quelli RTO. Per questo motivo, esamineremo solo gli approcci al ripristino di emergenza basati sulla replica dei volumi.
Dopo aver ristretto il campo di analisi, esamineremo due approcci architetturali al ripristino di emergenza che si differenziano per il tipo di replica del volume:
- Replica unidirezionale;
- Replica simmetrica o replica bidirezionale.
Replica unidirezionale
Nella replica unidirezionale, i volumi vengono replicati da un datacenter all'altro, ma non viceversa. La direzione della replica è controllata tramite l'array di storage e la replica dei volumi può essere sincrona o asincrona, una scelta che dipende dalla capacità dell'array di storage e dalla latenza tra i due datacenter. La replica asincrona è adatta per i datacenter tra i quali esiste una latenza elevata e che molto probabilmente si trovano nella stessa area geografica, ma non nella stessa area metropolitana.
La struttura architetturale della replica unidirezionale è illustrata nella figura seguente:
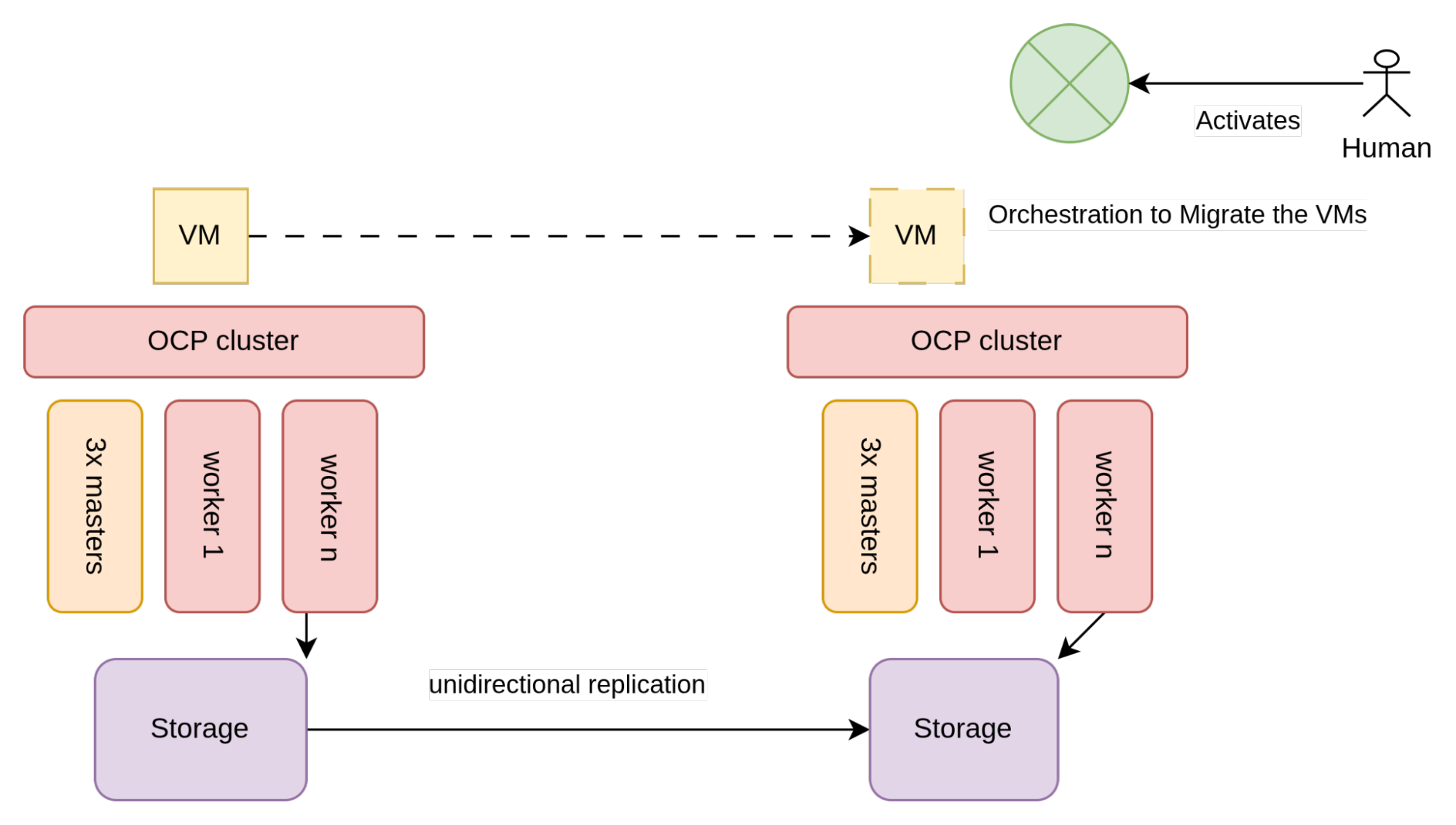
Nella Figura 2, lo storage utilizzato dalle VM, in genere un array SAN, è configurato per consentire la replica unidirezionale.
In ogni datacenter sono presenti due diversi cluster OpenShift, ognuno connesso all'array di storage locale. Poiché i cluster non sono a conoscenza l'uno dell'altro, gli unici vincoli all'implementazione di questa architettura sono determinati dal fornitore dello storage, nello specifico dai requisiti da soddisfare per consentire la replica unidirezionale.
Considerazioni sulla replica dei volumi unidirezionale
Poiché la replica dei volumi non è standardizzata nella specifica CSI di Kubernetes, i fornitori di storage hanno creato definizioni di risorse personalizzate (CRD) proprietarie per abilitare questa funzionalità. In linea di massima, osserviamo tre livelli di maturità dei fornitori rispetto a questa funzionalità:
- La funzionalità di replica dei volumi non è disponibile a livello di CSI, oppure è disponibile ma non consente la creazione di un'orchestrazione adeguata del ripristino di emergenza senza una chiamata diretta all'API dell'array di storage.
- La funzionalità di replica dei volumi è disponibile a livello di CSI.
- La funzionalità di replica dei volumi è disponibile e il fornitore si occupa anche del ripristino dei metadati dello spazio dei nomi (ovvero le VM e altri manifest presenti nello spazio dei nomi).
Questa frammentazione complica la scrittura di un processo di ripristino di emergenza indipendente dal fornitore per configurare il ripristino di emergenza Regional. La quantità di codice necessaria a creare un'adeguata orchestrazione del ripristino di emergenza dipende dal fornitore dello storage.
Osserviamo ora il comportamento di questa architettura con diverse modalità di errore: errore del nodo OpenShift, errore dell'array di storage (errore dei componenti) ed errore dell'intero datacenter (lo scenario di ripristino di emergenza effettivo).
Errore del nodo OpenShift
In caso di errore di un nodo (componente), lo scheduler di OpenShift Virtualization è responsabile del riavvio automatico della VM sul nodo del cluster successivo più appropriato. In questo scenario non dovrebbero essere necessarie ulteriori azioni.
Errore dell'array di storage
Un errore dell'array di storage si ripercuote su tutte le VM che dipendono dall'array. In questo scenario, è necessario attivare il processo di ripristino di emergenza. Consulta la sezione dedicata al processo di ripristino di emergenza per i passaggi necessari.
Errore del datacenter
In caso di malfunzionamento del datacenter, è necessario attivare il processo di ripristino di emergenza per riavviare tutte le VM nel datacenter non interessate dal problema. In questa situazione, l'automazione gioca un ruolo fondamentale, anche se in genere il processo viene avviato tramite l'intervento umano nell'ambito del processo di gestione degli incidenti di maggior impatto. Il paragrafo seguente fornisce una panoramica dei passaggi necessari.
Processo di ripristino di emergenza
Le procedure di ripristino di emergenza possono diventare molto complicate. In breve, un processo di ripristino di emergenza dovrebbe considerare quanto segue:
- I volumi delle VM che fanno parte della stessa applicazione devono essere replicati in modo coerente, ovvero devono far parte dello stesso gruppo di coerenza.
- Deve essere possibile verificare se replicare i volumi in un gruppo di coerenza e in quale direzione. In circostanze normali, i volumi vengono replicati dal sito attivo a quello passivo. Durante un failover, i volumi non vengono replicati. Durante la fase di preparazione al failback, i volumi vengono replicati dal sito passivo a quello attivo. Durante il failback, i volumi non vengono replicati.
- Le VM nell'altro datacenter devono poter essere riavviate e devono potersi connettere al volume di storage replicato.
- Può essere necessario limitare il riavvio delle VM per evitare un riavvio storm. Inoltre, è consigliabile definire la priorità della sequenza di riavvio delle VM per garantire che le applicazioni critiche vengano avviate per prime o che i componenti con dipendenze, come i database, vengano avviati prima dei servizi che da questi dipendono.
Considerazioni sui costi
In base alla sua configurazione, il cluster OpenShift può essere considerato come sito di ripristino di emergenza "warm" o "hot". Per i siti "hot" è necessaria una sottoscrizione completa, che non serve invece per i siti "warm", che quindi consentono un risparmio sui costi.
In linea generale, un sito di ripristino di emergenza può essere considerato "warm" se non presenta carichi di lavoro attivi in esecuzione. In particolare, è possibile configurare volumi persistenti (PV), richieste di volumi persistenti (PVC) e anche VM non in esecuzione e pronte per essere avviate in caso di emergenza, e mantenere la designazione di sito "warm".
Modalità simmetrica attiva/passiva
La presenza del 100% dei carichi di lavoro nel sito attivo non è comune. Al contrario, le organizzazioni suddividono in genere al 50% i carichi di lavoro tra i datacenter primari e secondari. Si tratta di un approccio pratico che permette di evitare che tutti i servizi siano eliminati in una volta sola in caso di emergenza, e di ridurre di conseguenza le attività di ripristino complessive.
Durante la distribuzione delle VM attive in ogni datacenter, ogni lato viene configurato in modo da poter eseguire il failover sull'altro. Questa configurazione, nota anche come modalità simmetrica attiva/passiva, funziona con OpenShift Virtualization e l'architettura esaminata in precedenza. Nella modalità simmetrica attiva/passiva, entrambi i datacenter sono considerati attivi e pertanto è necessaria la sottoscrizione di tutti i nodi OpenShift.
Replica simmetrica
Con la replica simmetrica, i volumi vengono replicati in modo sincrono e in entrambe le direzioni. Di conseguenza, entrambi i datacenter possono disporre di volumi attivi ed eseguire operazioni di scrittura su tali volumi. Affinché ciò sia possibile, un'organizzazione deve disporre di due datacenter con latenza di rete molto bassa (ad esempio, ~<5 ms). In genere, questo è possibile se i due datacenter si trovano nella stessa area metropolitana, ed è per questo che l'architettura è anche nota come Ripristino di emergenza Metro. In questo scenario, è possibile utilizzare l'architettura seguente:

In questa architettura, lo storage utilizzato dalle VM, in genere un array SAN, è configurato per eseguire la replica simmetrica tra i due datacenter.
Si ottiene così un array di storage logico esteso ai due datacenter. Per consentire la replica simmetrica, è necessario disporre di un "sito di controllo" che agisca come arbitro indipendente per evitare la suddivisione delle funzioni principali in caso di guasto di una rete o di un sito.
In termini di latenza, il sito di controllo non deve essere necessariamente vicino come accade con i due datacenter principali, poiché viene utilizzato per creare il quorum e per mantenere connesse le funzioni principali. Il sito di controllo deve essere una zona di disponibilità indipendente e non prevedere carichi di lavoro applicativi; inoltre, non è necessario che abbia grandi capacità, ma deve offrire servizi di qualità pari a quella degli altri datacenter in termini di operazioni del datacenter (ad es. sicurezza fisica/logica, gestione dell'alimentazione, raffreddamento).
Lo storage è esteso a tutti i datacenter, e OpenShift si estende al di sopra dello storage. Per ottenere questo risultato con un'architettura ad alta disponibilità, il piano di controllo di OpenShift richiede tre zone di disponibilità (siti). Ciò è dovuto al fatto che, per mantenere un quorum affidabile, il database etcd interno di Kubernetes richiede almeno tre domini di errore. In genere, questo approccio viene implementato sfruttando il sito di storage di controllo per uno dei nodi del piano di controllo.
La maggior parte dei fornitori di reti SAN (Storage Area Network) supporta la replica simmetrica per i propri array di storage. Tuttavia, non tutti i fornitori offrono questa capacità a livello di CSI. Supponendo che un fornitore di storage supporti la replica simmetrica a livello di CSI e che siano soddisfatti i prerequisiti e le configurazioni necessari, al momento della creazione di una PVC viene fornito un numero di unità logica (LUN) multipath. Poiché tale LUN include i percorsi diretti a entrambi i datacenter, tutti i nodi OpenShift devono essere configurati in modo da consentire la connessione a entrambi gli array di storage. Generalmente, il dispositivo multipath viene creato con una configurazione di accesso asimmetrico all'unità logica (ALUA) (Pearson IT Certification, 2024), un approccio attivo/passivo in cui il percorso attivo è quello dell'array più vicino, o con un percorso attivo/attivo con pesi diversi, in cui l'array più vicino ha pesi elevati.
Alcuni fornitori accettano questa architettura anche quando le connessioni Fibre Channel non sono "uniformi", ovvero quando i nodi di un sito possono connettersi solo all'array di storage locale. Ovviamente, in questo caso la configurazione ALUA non viene creata.
Questa topologia di cluster facilita la protezione tanto dagli errori dei componenti quando dagli eventi di emergenza. Osserviamo ora il comportamento di questa architettura nelle diverse modalità di errore.
Errore del nodo OpenShift
In caso di errore di un nodo (componente), lo scheduler di OpenShift Virtualization è responsabile del riavvio automatico della VM sul nodo successivo più appropriato del cluster. In questo scenario non dovrebbero essere necessarie ulteriori azioni.
Errore dell'array di storage
I LUN multipath garantiscono la continuità del servizio nel caso in cui in uno dei due array di storage si verifichi un errore o venga disconnesso per manutenzione. In uno scenario di connettività uniforme, il percorso passivo o con meno peso del LUN multipath viene utilizzato per connettere la VM agli altri array. Questo errore è completamente visibile alle VM e può causare un lieve aumento della latenza di I/O del disco. In uno scenario di connettività non uniforme, è necessario eseguire la migrazione della VM su un nodo con connettività.
Errore del datacenter
L'indisponibilità di un intero datacenter viene considerata dal cluster OpenShift esteso come un errore contemporaneo di più nodi. OpenShift avvia la pianificazione delle VM sui nodi all'interno dell'altro datacenter, come descritto nel paragrafo sugli errori del nodo OpenShift.
Supponendo che sia disponibile una capacità di riserva sufficiente per la migrazione dei carichi di lavoro, tutte le macchine verranno riavviate nell'altro datacenter. Le VM riavviate hanno obiettivi RPO e RTO pari a zero, dati dalla somma delle tempistiche seguenti:
- Il tempo impiegato da OpenShift per capire che i nodi non sono pronti
- Il tempo necessario per il fencing dei nodi
- Il tempo necessario per il riavvio delle VM
- Il tempo necessario per completare il processo di avvio della VM
Questo meccanismo di ripristino di emergenza è completamente autonomo e non richiede l'intervento umano, ma ciò non è sempre auspicabile. Per evitare un riavvio storm, è spesso consigliabile controllare quali VM vengono riavviate e quando viene avviato il processo.
Considerazioni sul ripristino di emergenza Metro
Di seguito alcune considerazioni su questo approccio:
- Poiché le VM sono in genere connesse a reti VLAN per garantirne la mobilità tra i datacenter, è necessario che le VLAN siano estese anche ai datacenter dell'area metropolitana, ma non sempre questa configurazione è desiderabile.
- Spesso la rete di gestione del sito di controllo (rete del nodo OpenShift) non si trova nella stessa sottorete L2 della rete di gestione dei datacenter dell'area metropolitana.
- Alcune scuole di pensiero non considerano completa questa soluzione di ripristino di emergenza, poiché il piano di controllo di OpenShift e il piano di controllo dell'array di storage rappresentano due singoli punti di errore (SPOF). Si tratta di SPOF in senso logico, poiché dal punto di vista fisico esiste ovviamente la ridondanza. Tuttavia, è vero che un singolo comando errato inviato a OpenShift o all'array di storage può, in teoria, cancellare l'intero ambiente. Per questo motivo, questa architettura è a volte collegata con un approccio daisy-chained a un'architettura di ripristino di emergenza regionale più tradizionale, soprattutto per i carichi di lavoro critici.
- Durante una situazione di ripristino di emergenza, OpenShift riprogramma in modo automatico e contemporaneo tutte le VM nel datacenter interessate dall'emergenza verso il datacenter integro, potenzialmente causando un fenomeno noto come "riavvio storm". Esistono numerose funzionalità di Kubernetes che possono contenere questo rischio controllando quali applicazioni eseguono il failover e quando.
Considerazioni sui costi
Nella replica simmetrica, entrambi i siti devono disporre di una sottoscrizione completa, in quanto appartengono a un singolo cluster OpenShift attivo. Come con la replica unidirezionale, l'overprovisioning di ogni sito deve essere eseguito al 100% per consentire il failover completo dell'altro sito.
Conclusioni
La scelta tra architetture di replica unidirezionali e simmetriche pone le basi per l'intera strategia di ripristino di emergenza su OpenShift Virtualization. Ogni modello prevede alcuni compromessi tra complessità operativa, costo dell'infrastruttura, RPO/RTO garantiti e potenziale di automazione. Che si scelga un modello a doppio cluster o a cluster esteso, l'architettura di base deve essere in linea con le aspettative di continuità operativa e i vincoli dell'infrastruttura. Definiti questi concetti di base, nella seconda parte sposteremo l'attenzione dall'infrastruttura all'orchestrazione, andando oltre lo storage per approfondire il posizionamento, il riavvio e il controllo delle VM in situazioni di emergenza.
Prova prodotto
Red Hat OpenShift Virtualization Engine | Versione di prova del prodotto
Sugli autori
Bryon is a skilled infrastructure and software engineering specialist with deep expertise in AI/ML, Kubernetes, OpenShift, cloud-native architecture, and enterprise networking. With a strong background in storage technologies, infrastructure, and virtualisation, Bryon works across domains including system administration, AI model deployment, and platform engineering. He is proficient in C#, Golang and Python, experienced in container orchestration, and actively contributes to Red Hat-based solutions. Passionate about education and enablement, Bryon frequently develops technical workshops and training programs, particularly in AI/ML and DevOps. He is also a practising musician, blending his technical acumen with creative expression.
Raffaele is a full-stack enterprise architect with 20+ years of experience. Raffaele started his career in Italy as a Java Architect then gradually moved to Integration Architect and then Enterprise Architect. Later he moved to the United States to eventually become an OpenShift Architect for Red Hat consulting services, acquiring, in the process, knowledge of the infrastructure side of IT.
Currently Raffaele covers a consulting position of cross-portfolio application architect with a focus on OpenShift. Most of his career Raffaele worked with large financial institutions allowing him to acquire an understanding of enterprise processes and security and compliance requirements of large enterprise customers.
Raffaele has become part of the CNCF TAG Storage and contributed to the Cloud Native Disaster Recovery whitepaper.
Recently Raffaele has been focusing on how to improve the developer experience by implementing internal development platforms (IDP).
Altri risultati simili a questo
Oltre l'Automazione: perché l'aumento delle vulnerabilità di sicurezza basate sull'IA richiede un supporto tecnico umano
Funzionalità post-quantistiche di SSH migliorate in Red Hat Enterprise Linux
Untangling Networks | Compiler
Technically Speaking | Defining sovereign AI with open source
Ricerca per canale

Automazione
Novità sull'automazione IT di tecnologie, team e ambienti

Intelligenza artificiale
Aggiornamenti sulle piattaforme che consentono alle aziende di eseguire carichi di lavoro IA ovunque

Hybrid cloud open source
Scopri come affrontare il futuro in modo più agile grazie al cloud ibrido

Sicurezza
Le ultime novità sulle nostre soluzioni per ridurre i rischi nelle tecnologie e negli ambienti

Edge computing
Aggiornamenti sulle piattaforme che semplificano l'operatività edge

Infrastruttura
Le ultime novità sulla piattaforma Linux aziendale leader a livello mondiale

Applicazioni
Approfondimenti sulle nostre soluzioni alle sfide applicative più difficili
Virtualizzazione
Il futuro della virtualizzazione negli ambienti aziendali per i carichi di lavoro on premise o nel cloud