
Sembra che ogni modello linguistico di grandi dimensioni (LLM) diventi sempre più grande ad ogni rilascio. Ciò richiede un numero elevato di GPU per l'addestramento del modello e una maggiore quantità di risorse durante l'intero ciclo di vita dei modelli per il fine tuning, l'inferenza e così via. A questi LLM si applica una nuova legge di Moore: la dimensione del modello (misurata dal numero di parametri) raddoppia ogni quattro mesi.
Gli LLM sono costosi
L'addestramento e l'uso di un LLM sono costosi in termini di risorse, tempo e denaro. I requisiti relativi alle risorse hanno un impatto diretto sulle aziende che distribuiscono un LLM, indipendentemente dal fatto che si tratti della propria infrastruttura o dell'utilizzo di un hyperscaler. E gli LLM sono sempre più grandi.
Inoltre, l'utilizzo di un LLM richiede molte risorse. L'LLM Llama 3.1 ha 405 miliardi di parametri e richiede 810 GB di memoria (FP16) per la sola inferenza. La famiglia di modelli Llama 3.1 è stata addestrata su 15 mila miliardi di token su un cluster di GPU con 39 milioni di ore di utilizzo della GPU. Con l'aumento esponenziale delle dimensioni degli LLM, aumentano anche i requisiti di elaborazione e memoria per l'addestramento e il funzionamento. Il fine tuning di Llama 3.1 richiede 3,25 TB di memoria.
L'anno scorso si è verificata una grave carenza di GPU e, proprio mentre il divario tra domanda e offerta sta migliorando, si prevede che il prossimo ostacolo sia l'alimentazione. Con l'aumento dei data center online e il consumo di elettricità per ogni data center che raddoppia fino a raggiungere quasi 150 MW, è facile capire perché ciò diventerebbe un problema per il settore dell'IA.
Come ridurre i costi degli LLM
Prima di parlare di come ridurre i costi degli LLM, prendiamo in considerazione un esempio noto. Le fotocamere sono in costante miglioramento, e i nuovi modelli acquisiscono immagini con una risoluzione più elevata che mai. Tuttavia, i file raw delle immagini possono avere dimensioni pari o superiori a 40 MB ciascuno. Ad esclusione dei professionisti dei media che hanno bisogno di elaborare queste immagini, per la maggior parte degli usi è sufficiente una versione JPEG, che riduce le dimensioni del file dell'80%. Certo, la compressione del formato JPEG riduce la qualità dell'immagine rispetto all'originale raw, ma per la maggior parte degli utilizzi, il formato JPEG è adeguato. Inoltre, in genere sono necessarie applicazioni speciali per elaborare e visualizzare le immagini raw. Pertanto, la gestione delle immagini raw ha un costo di elaborazione più elevato rispetto a un'immagine JPEG.
Ora torniamo agli LLM. La dimensione del modello dipende dal numero di parametri, quindi un possibile approccio consiste nell'utilizzare un modello con un numero di parametri inferiore. Tutti i modelli open source più diffusi sono dotati di una serie di parametri diversi, perciò è possibile scegliere quelli più adatti a un'applicazione specifica.

Tuttavia, per la maggior parte dei benchmark, un LLM con un numero maggiore di parametri in genere offre prestazioni migliori rispetto a un modello con un numero inferiore di parametri. Per ridurre i requisiti in termini di risorse, potrebbe essere meglio utilizzare un modello con più parametri comprimendolo in una dimensione inferiore. I test hanno dimostrato chela compressione GAN può ridurre l'elaborazione di quasi 20 volte.
Esistono decine di approcci alla compressione di un LLM, tra cui quantizzazione, pruning, distillazione delle conoscenze e riduzione dei livelli.
Quantizzazione
La quantizzazione modifica i valori numerici in un modello da un formato a virgola mobile a 32 bit a un tipo di dati con precisione inferiore: virgola mobile a 16 bit, intero a 8 bit, intero a 4 bit o anche intero a 2 bit. Riducendo la precisione del tipo di dati, il modello richiede meno bit durante le operazioni, con conseguente riduzione di memoria ed elaborazione. La quantizzazione può essere eseguita durante o dopo il processo di addestramento del modello.
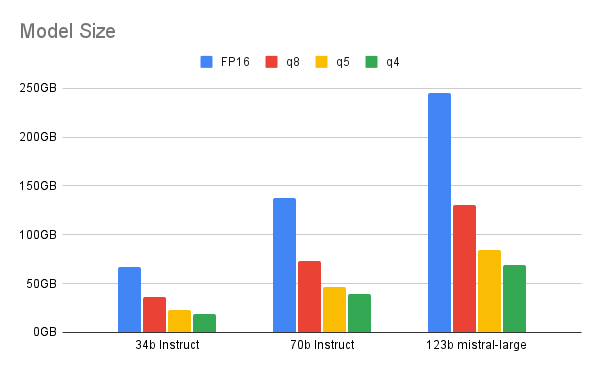
Passando ai bit più bassi, entra in gioco un compromesso tra quantizzazione e prestazioni. Questo documento evidenzia l'intervallo ideale offerto dalla quantizzazione a 4 bit per i modelli più ampi (almeno 70 miliardi di parametri). Un valore inferiore mostra una notevole discrepanza nelle prestazioni tra l'LLM e la sua controparte quantizzata. Per un modello più piccolo, la quantizzazione a 6 o 8 bit può essere una scelta più indicata.
Grazie alla quantizzazione, è possibile eseguire questa demo RAG LLM su un laptop.
Pruning
Il pruning ("sfoltimento") riduce le dimensioni dei modelli eliminando pesi o neuroni meno importanti. È necessario trovare un delicato equilibrio tra la riduzione delle dimensioni del modello e il mantenimento dell'accuratezza. Il pruning può essere eseguito prima, durante o dopo l'addestramento del modello. La riduzione dei livelli migliora ulteriormente questa idea rimuovendo interi blocchi di livelli. In questo documento, gli autori riferiscono che può essere rimosso fino al 50% dei livelli ottenendo un calo minimo delle prestazioni.
Distillazione delle conoscenze
Trasferisce le conoscenze da un modello di grandi dimensioni (l'insegnante) a un modello più piccolo (lo studente). Il modello più piccolo viene addestrato dagli output del modello più grande anziché dai dati di addestramento più grandi.
Questo documento mostra come la distillazione del modello BERT di Google in DistilBERT ha ridotto le dimensioni del modello del 40% e aumentato la velocità di inferenza del 60%, mantenendo il 97% delle sue capacità di comprensione del linguaggio.
Approccio ibrido
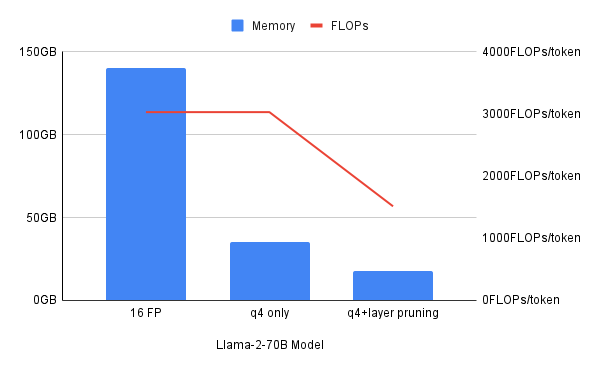
Sebbene ciascuna di queste singole tecniche di compressione sia utile, a volte un approccio ibrido che combina diverse modalità è la soluzione migliore. Questo documento evidenzia come la quantizzazione a 4 bit riduca di 4 volte il fabbisogno di memoria, ma non le risorse di elaborazione misurate in FLOPS (operazioni a virgola mobile al secondo). La quantizzazione combinata con la riduzione dei livelli aiuta a diminuire la memoria e le risorse di elaborazione.
Vantaggi di un modello più piccolo
L'uso di modelli più piccoli può ridurre notevolmente i requisiti di elaborazione, mantenendo comunque un elevato livello di prestazioni e precisione.
- Riduzione dei costi di elaborazione: i modelli più piccoli riducono i requisiti di CPU e GPU, con un notevole risparmio sui costi. Considerando che le GPU di fascia alta possono costare fino a 30.000 dollari ciascuna, qualsiasi riduzione dei costi di elaborazione è una buona notizia.
- Diminuzione dell'utilizzo della memoria: i modelli più piccoli richiedono meno memoria rispetto ai modelli più grandi. Questo è utile per i deployment dei modelli su sistemi con risorse limitate, come dispositivi IoT o telefoni cellulari.
- Inferenza più rapida: i modelli più piccoli possono essere caricati ed eseguiti rapidamente, con conseguente riduzione della latenza dell'inferenza. Un'inferenza più rapida può fare la differenza per le applicazioni in tempo reale come le autovetture autonome.
- Impronta di carbonio ridotta: la riduzione dei requisiti di elaborazione dei modelli più piccoli contribuisce a migliorare l'efficienza energetica riducendo l'impatto ambientale.
- Flessibilità di deployment: i requisiti di elaborazione inferiori aumentano la flessibilità per il deployment dei modelli in cui sono necessari. I modelli possono essere distribuiti per soddisfare le esigenze degli utenti in continua evoluzione o i vincoli di sistema, incluso l'edge della rete.
I modelli più piccoli ed economici stanno guadagnando popolarità, come dimostrano le recenti versioni di ChatGPT-4o mini (60% in meno rispetto a GPT-3.5 Turbo) e le innovazioni open source di SmolLM e Mistral NeMo.
- Hugging Face SmolLM: una famiglia di modelli di piccole dimensioni con 135 milioni, 360 milioni e 1,7 miliardi di parametri;
- Mistral NeMo: un modello di piccole dimensioni con 12 miliardi di parametri, realizzato in collaborazione con Nvidia.
Questa tendenza verso gli SLM (modelli linguistici di piccole dimensioni) è dovuta ai vantaggi illustrati in precedenza. Con i modelli più piccoli sono disponibili molte opzioni: utilizza un modello predefinito o adotta tecniche di compressione per ridurre un LLM esistente. Il tuo scenario di utilizzo deve determinare l'approccio da adottare nella scelta di un modello di piccole dimensioni, quindi valuta attentamente le opzioni disponibili.
Sull'autore
Ishu Verma is an AI Solution Architect at Red Hat dabbling in emerging technologies like AI Ops, AI safety and security. He, along with fellow open source hackers, works on building enterprise focused solutions with open source technologies. Prior to Red Hat, Ishu worked in technical marketing at Intel on IoT Gateways and building end-to-end IoT solutions with partners.
Altri risultati simili a questo
L'IA agentica richiede nuove tecnologie per l’infrastruttura: AMD e Red Hat rispondono a questa esigenza
Smetti di gestire il passato e inizia a costruire il futuro dell'IT
Technically Speaking | Defining sovereign AI with open source
Technically Speaking | Inside open source AI strategy
Ricerca per canale

Automazione
Novità sull'automazione IT di tecnologie, team e ambienti

Intelligenza artificiale
Aggiornamenti sulle piattaforme che consentono alle aziende di eseguire carichi di lavoro IA ovunque

Hybrid cloud open source
Scopri come affrontare il futuro in modo più agile grazie al cloud ibrido

Sicurezza
Le ultime novità sulle nostre soluzioni per ridurre i rischi nelle tecnologie e negli ambienti

Edge computing
Aggiornamenti sulle piattaforme che semplificano l'operatività edge

Infrastruttura
Le ultime novità sulla piattaforma Linux aziendale leader a livello mondiale

Applicazioni
Approfondimenti sulle nostre soluzioni alle sfide applicative più difficili
Virtualizzazione
Il futuro della virtualizzazione negli ambienti aziendali per i carichi di lavoro on premise o nel cloud