
Many organizations are now migrating virtualized workloads to Red Hat OpenShift Virtualization.
In many cases, this migration consists of a lift-and-shift (rehosting) approach, in which a virtual machine (VM) is moved from a source platform to OpenShift Virtualization while retaining the same network identity (MAC addresses, IP addresses, and so on). Essentially, the hypervisor and VM orchestrator change, but everything else remains the same. This is suitable when the objective is to replatform quickly.
But once the migration is completed, you might ask yourself whether you can optimize, or even decommission some of the VMs that you've migrated.
With Red Hat OpenShift, you have the option to containerize your workloads. In some cases, this might be an appropriate solution, but not in every case. There’s also an approach focused on rationalizing migrated VMs without requiring application code refactoring, particularly for VMs supporting networking functions such as load balancers and reverse proxies.
The traffic pattern of load balancer to reverse proxy to application server is common:
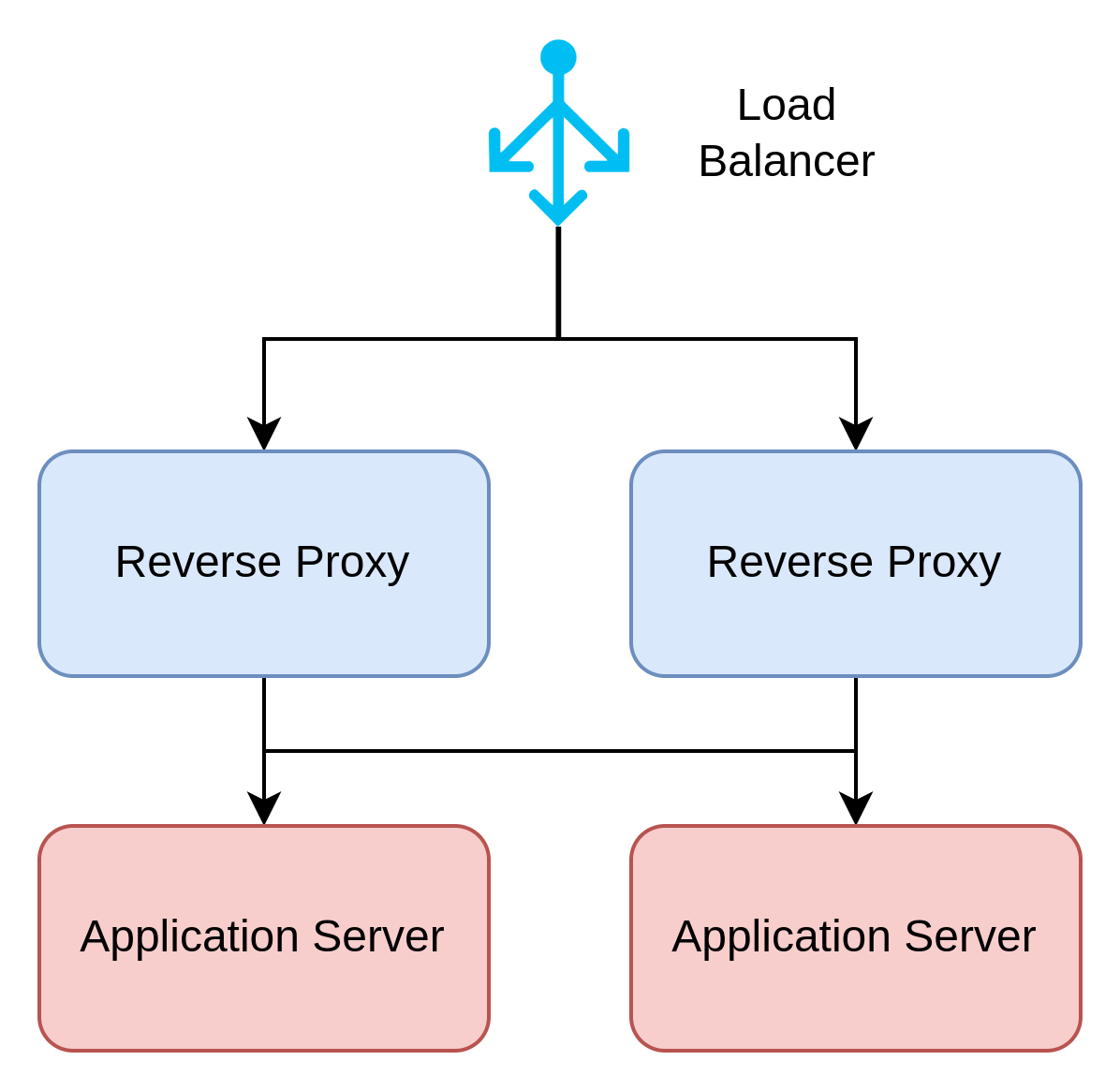
When these are VMs sitting on the same Virtual Local Area Network (VLAN), they're organized in a manner similar to the following:

Some of the VMs in the diagram above are dedicated to performing the function of load balancing and reverse proxying. These VMs are usually shared across several application workloads. In OpenShift, load balancing and reverse proxying are native capabilities (or capabilities that can be enabled by specific operators). Given that, it's worth asking whether you can replace these VMs with OpenShift capabilities.
Doing so gives you three major advantages:
- Easily configure the capabilities declaratively, and possibly letting developers perform actions in a self-service manner, eliminating or reducing the number of ticket requests required
- Leverage the self-healing capability of the OpenShift platform
- Save on compute resources and licensing costs
Solution Design
At a high-level, a solution might look similar to this:
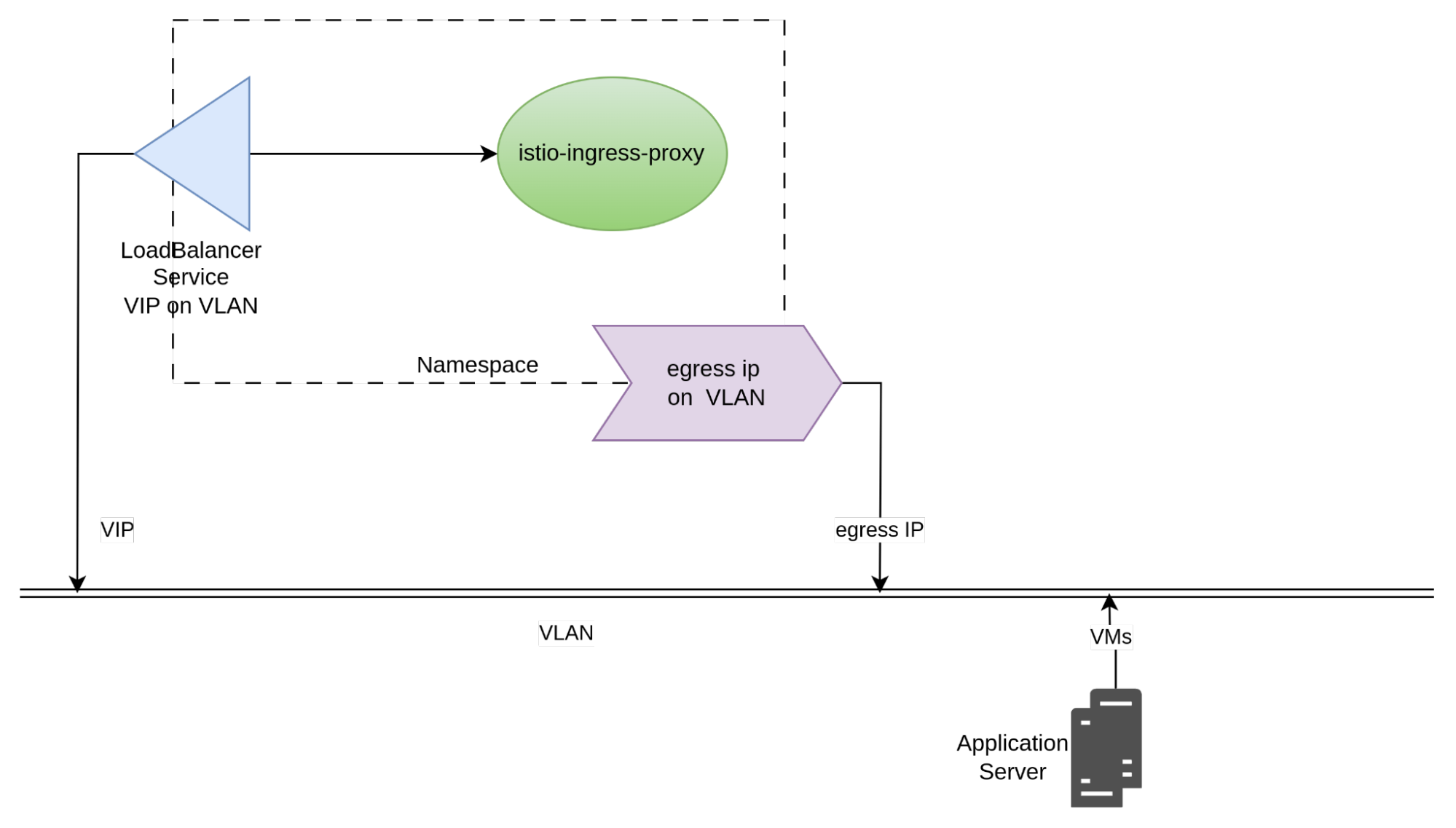
In the diagram above, you have a load balancer with its VIP on the VLAN. This load balancer sends traffic to a set of OpenShift Service Mesh ingress-gateway pods. The pods play the role of a reverse proxy.
The ingress-gateway pods then forward the request to virtual machines on the VLAN.
This occurs because the namespace in which the ingress-gateway pods reside is configured with an egress IP using an address located on the VLAN.
OpenShift networking features, such as load balancing and reverse proxying, typically only work on the pod network (although this may change in the future). With this solution, you deviate traffic from the VLAN to the pod network to take advantage of the native capabilities of OpenShift, but all of the traffic appears to occur on the VLAN itself as before.
There are a few possible variations that could be implemented, including:
- The load balancer VIP could be published on a different VLAN. This is useful when a VIP must be public, but other endpoints must be private, and therefore VIPs exist in different VLANs than normal serviced endpoints
- In some instances, reverse proxies also perform authentication (especially when they reside within a DMZ). You can use OpenShift Service Mesh capabilities to enable this type of use case. In such a scenario, the architecture might look similar to the following:
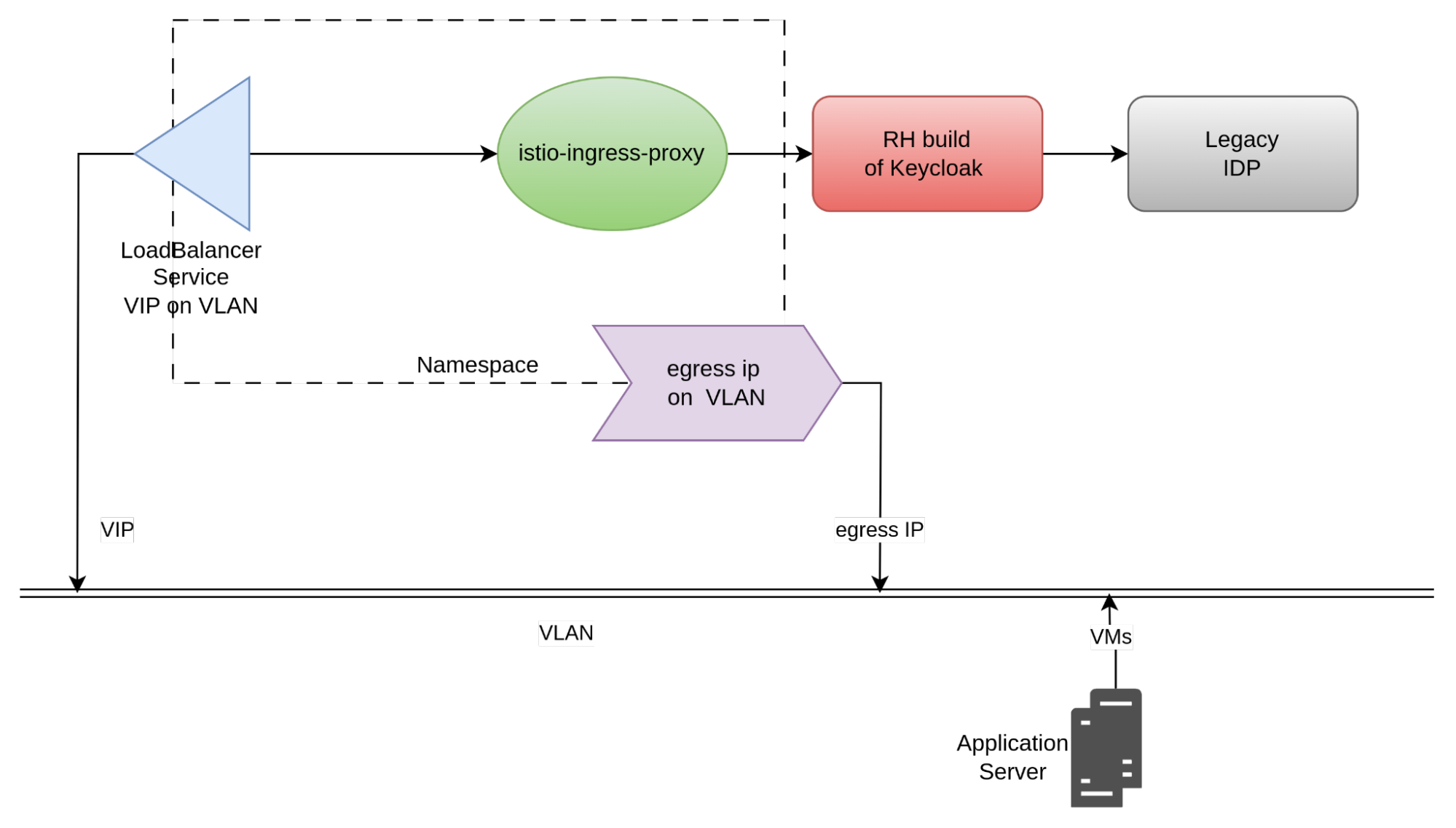
In this example, the Red Hat build of KeyCloak acts as an Istio external authorization provider. KeyCloak can then interface with the enterprise identity provider (IDP).
Below, let’s look at how to configure this type of solution in which the reverse proxy is routing and balancing requests. Let’s start with configuring the node network.
Node network configuration
The node network configuration looks something like this:
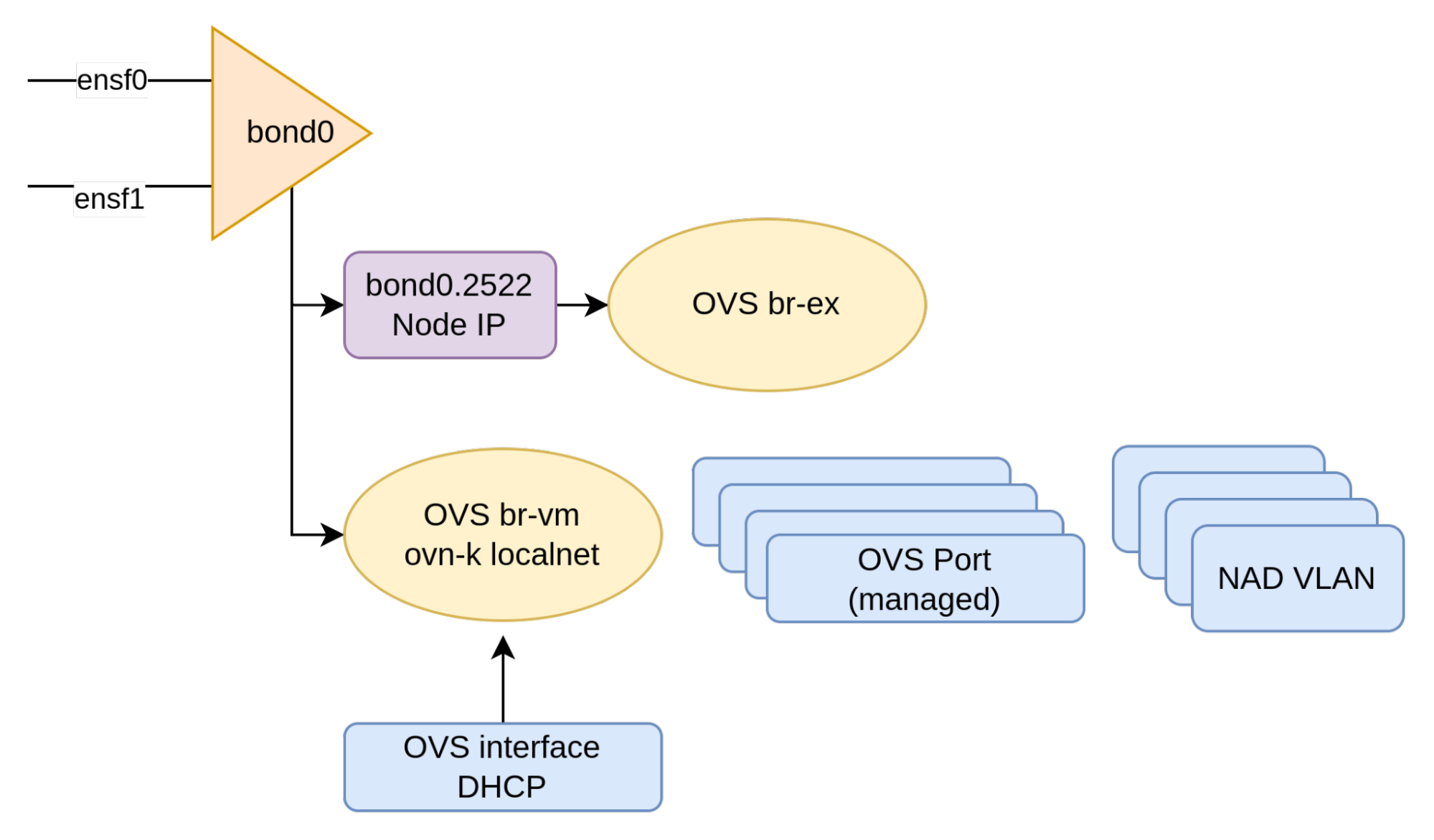
In the diagram above, each node has two bonded NICs. Out of the bond, create a VLAN interface for the node network (in this case, the node network is on a specific VLAN) and let the OpenShift installer build the br-ex bridge on that interface.
Then create an OVS bridge (br-vm) dedicated to the virtual machines, which allows you to support multiple VLANs for the virtual machines hosted on this node.
Also create an OVS interface on br-vm bridge. This connects the host to the bridge, allowing it to see traffic on one specific VLAN (this filtering is part of the configuration).
It's important to note that in this example, we have dedicated a separate bridge for the VM VLANs along with an OVS interface that's configured to see one of these VLANs. In this case, VLAN 1512 is for use by the virtual machines.
This configuration can be created with a NodeNetworkConfigurationPolicy (NNCP):
apiVersion: nmstate.io/v1
kind: NodeNetworkConfigurationPolicy
metadata:
name: ovs-br1-multiple-networks
spec:
nodeSelector:
node-role.kubernetes.io/worker: ''
desiredState:
interfaces:
- name: ovs-br1-host
type: ovs-interface
state: up
ipv4:
enabled: true
dhcp: true
ipv6:
enabled: false
- name: ovs-br1
description: |-
A dedicated OVS bridge with ens1f0 and ovs-vr1-host as ports
ovs-vr1-host only receives VLAN 1512
type: ovs-bridge
state: up
ipv4:
enabled: false
ipv6:
enabled: false
bridge:
allow-extra-patch-ports: true
options:
stp:
enabled: false
port:
- name: bond0
- name: ovs-br1-host
vlan:
mode: access
tag: 1512
ovn:
bridge-mappings:
- localnet: vlan-1512
bridge: ovs-br1
state: presentThe node is now connected to one of the VM VLANs. Should you need to connect the node to additional VM VLANs, you can create more OVS interfaces. In general, hypervisors are not connected to the VM network, and it's important to verify with any applicable security team about whether a configuration is deemed a risk.
In this example, we configure the node IP on the VLAN using DHCP. Doing so is convenient because it allows you to use a single NNCP for all nodes. If DHCP is not an option, you can set IPs statically. But in that case, you would need to create an NNCP for each node.
You also need a NetworkAttachmentDefinition (NAD) to allow virtual machines to attach to the VLAN:
apiVersion: k8s.cni.cncf.io/v1
kind: NetworkAttachmentDefinition
metadata:
annotations:
description: Network 1512 via OVS Bridge
name: vlan-1512
namespace: default
spec:
config: |-
{
"cniVersion": "0.3.1",
"name": "vlan-1512",
"type": "ovn-k8s-cni-overlay",
"topology": "localnet",
"netAttachDefName": "default/vlan-1512",
"vlanID": 1512,
"mtu": 1500,
"ipam": {}
}Virtual machine configuration
You can, at this point, create a couple of virtual machines to simulate our migrated workload. VirtualMachine manifests are quite large, so we will only show the relevant sections. The following snippet is the network configuration for the virtual machine:
interfaces:
- bridge: {}
macAddress: '02:a5:cf:00:00:07'
model: virtio
name: nic-sapphire-roadrunner-92
…
networks:
- multus:
networkName: default/vlan-1512
name: nic-sapphire-roadrunner-92The virtual machine is attached to the vlan-1512 NAD. DHCP is available on this VLAN and it is configured to assign IPs based on MAC addresses with an infinite lease duration. This way, you can ensure that virtual machines always receive the same IP address. A common scenario in many organizations is that each virtual machine has its IP addresses statically assigned. Either option is acceptable, as long as the IP addresses are known. In this example, the IP addresses are 10.10.1.2 and 10.10.1.3.
The Apache HTTP daemon (httpd) is installed and enabled on these virtual machines.
Load-balancer configuration
On bare metal deployments, it's common practice to use MetalLB to create a load balancer. Fortunately for us, MetalLB provides the capabilities to specify which interface the VIPs should be created for:
apiVersion: metallb.io/v1beta1
kind: IPAddressPool
metadata:
name: vlan-1512-pool
namespace: metallb-system
spec:
addresses:
- 10.10.1.128/25
---
apiVersion: metallb.io/v1beta1
kind: L2Advertisement
metadata:
name: vlan-1512-ad
namespace: metallb-system
spec:
ipAddressPools:
- vlan-1512-pool
interfaces:
- ovs-br1-hostTwo manifests are included above. The first manifest defines a pool of addresses that can be used by the VIPs. These manifests dedicate a portion of the VLAN CIDR for this purpose. The second manifest specifies that these addresses should be associated with the ovs-br1-host interface (the specified interface is associated with the ovs-interface attached to the VM-dedicated bridge).
Istio ingress gateway configuration
You can create a dedicated Istio IngressGateway using one of the documented installation approaches. While several approaches are described, I personally prefer the helm chart approach.
Once the ingress gateway has been deployed, you can create a LoadBalancer service in front of it:
kind: Service
apiVersion: v1
metadata:
name: vlan-1512-ingress-gateway
annotations:
metallb.universe.tf/address-pool: vlan-1512-pool
spec:
ports:
- name: http2
protocol: TCP
port: 80
targetPort: 80
- name: https
protocol: TCP
port: 443
targetPort: 443
internalTrafficPolicy: Cluster
clusterIPs:
- 172.31.34.184
type: LoadBalancer
selector:
app: vlan-1512-ingress-gateway
istio: vlan-1512-ingress-gatewayNotice the presence of the metallb.universe.tf/address-pool annotation requesting the use of the vlan-1512-pool IPAddressPool from MetalLB.
If you have the external-dns operator, you can also request the creation of a DNS record for the VIP that MetaLB returns. With the correct configuration in external-dns, this can be achieved by adding the following annotation to the Service: external-dns.alpha.kubernetes.io/hostname: vms.vlan-1512.org.
At this point, you can configure a Gateway object to ensure that the ingress-gateway opens some ports to listen for incoming connections:
apiVersion: networking.istio.io/v1beta1
kind: Gateway
metadata:
name: vlan-1512-ingress-gateway
namespace: istio-system
spec:
selector:
istio: vlan-1512-ingress-gateway
servers:
- port:
number: 8080
name: http
protocol: HTTP
hosts:
- "*"
- port:
number: 8443
name: https
protocol: HTTPS
tls:
mode: SIMPLE
credentialName: vlan-1512-ingress-gateway-tls
hosts:
- "*"Notice that we select the ingress-gateway pod with the istio: vlan-1512-ingress-gateway selector. Our gateway pod must have that label to satisfy the match. We listen on the standard set of non-privileged httpand httpsports. For the https port, a certificate is included by referencing a previously created secret. If you have the cert-manager operator on this cluster, then you can configure it to provision certificates from an enterprise public key infrastructure (PKI).
With OpenShift Service Mesh, namespaces in the mesh are locked down, in terms of being able to receive traffic from outside the mesh. This requires a NetworkPolicy resource to allow incoming traffic from the VIP:
kind: NetworkPolicy
apiVersion: networking.k8s.io/v1
metadata:
name: allow-vlan-1512-ingress-gateway-lb
namespace: istio-system
spec:
podSelector:
matchLabels:
istio: vlan-1512-ingress-gateway
ingress:
- ports:
- protocol: TCP
port: 8443
- protocol: TCP
port: 8080
from:
- ipBlock:
cidr: 0.0.0.0/0
policyTypes:
- IngressThe pod selector that in this case is used to apply this NetworkPolicy to the ingress-gateway pod.
You can now define a ServiceEntry to inform Istio that endpoints exist outside the mesh:
apiVersion: networking.istio.io/v1beta1
kind: ServiceEntry
metadata:
name: vms
spec:
hosts:
- vms.vlan-1512.org
ports:
- number: 443
name: https
protocol: HTTPS
- number: 80
name: http
protocol: HTTP
resolution: STATIC
location: MESH_EXTERNAL
endpoints:
- address: "10.10.1.2"
- address: "10.10.1.3"The ServiceEntry is tied to the vms.vlan-1512.org dns name, which matches the VIP created previously. Notice also that we explicitly list the virtual machine IPs as the endpoints of this ServiceEntry, making the resolution of this service static.
Finally, you can create a VirtualService to specify how Istio routes traffic entering the ingress-gateway pod. In this case, you just need to route this traffic to the ServiceEntry.
apiVersion: networking.istio.io/v1beta1
kind: VirtualService
metadata:
name: vms
namespace: istio-system
spec:
gateways:
- vlan-1512-ingress-gateway
hosts:
- "vms.vlan-1512.org"
http:
- route:
- destination:
host: vms.vlan-1512.org
port:
number: 80For the sake of simplicity, only httptraffic has been defined.
This concludes the configurations necessary to enable reverse proxy capabilities using OpenShift Service Mesh (Istio). Other options could also be used and include OpenShift Ingress or the Gateway API.
EgressIP configuration
To ensure that the traffic forwarded by the ingress-gateway is routed into the VLAN, an EgressIP also needs to be configured:
apiVersion: k8s.ovn.org/v1
kind: EgressIP
metadata:
name: vlan-1512-ingress-gateway
spec:
egressIPs:
- "10.10.1.125"
namespaceSelector:
matchLabels:
kubernetes.io/metadata.name: …
podSelector:
matchLabels:
istio: vlan-1512-ingress-gatewayAs described in the manifest above, we assign an EgressIP from the VM VLAN CIDR to the egress traffic originating from the ingress-gateway pod. Egress traffic is enabled with NAT and EgressIP. With the EgressIP feature, OpenShift tries to find an interface on the node with a CIDR containing the EgressIP. If a match is found, then the EgressIP is added as a secondary IP on that interface, and traffic can egress from that interface.
In this example, the interface in question is again ovs-br1-host. Once applied, the configuration appears from the perspective of an OpenShift node:
ip a | grep ovs-br1-host
21030: ovs-br1-host: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UNKNOWN group default qlen 1000
inet 10.10.1.50/24 brd 10.10.1.255 scope global dynamic noprefixroute ovs-br1-host
inet 10.10.1.125/32 scope global ovs-br1-hostWhen using EgressIPs that aren't hosted on the main interface, you must enable global routing at the network Operator level with the following configuration:
defaultNetwork:
ovnKubernetesConfig:
gatewayConfig:
ipForwarding: GlobalAdditional information can also be found in OpenShift documentation. Again, check in with your security team to assess whether this might be considered a security issue.
Testing
With this configuration in place, let’s test and verify the functionality by creating a pod in the VLAN and executing the curlcommand from within the pod:
curl http://vms.vlan-1512.org:80 -v
Added vms.vlan-1512.org:80:10.10.1.128 to DNS cache
* Hostname vms.vlan-1512.org was found in DNS cache
* Trying 10.10.1.128:80...
* Connected to vms.vlan-1512.org (10.10.1.128) port 80
> GET / HTTP/1.1
> Host: vms.vlan-1512.org
> User-Agent: curl/8.6.0
> Accept: */*
>
…
<!doctype html>
<html>
<head>
<meta charset='utf-8'>
<meta name='viewport' content='width=device-width, initial-scale=1'>
<title>Test Page for the HTTP Server on Fedora</title>
…If the connection was successful, the default response from the Apache HTTPD server is provided.
Conclusions
Eliminating the need for VMs dedicated to load balancing and reverse proxy functions can be achieved by leveraging OpenShift's native capabilities. This approach enhances the user experience through self-service options while lowering costs by reducing the number of VMs and associated compute resources, including potential licensing fees. Such rationalizations are valuable following a lift-and-shift replatforming of VMs.
Sobre o autor
Raffaele is a full-stack enterprise architect with 20+ years of experience. Raffaele started his career in Italy as a Java Architect then gradually moved to Integration Architect and then Enterprise Architect. Later he moved to the United States to eventually become an OpenShift Architect for Red Hat consulting services, acquiring, in the process, knowledge of the infrastructure side of IT.
Currently Raffaele covers a consulting position of cross-portfolio application architect with a focus on OpenShift. Most of his career Raffaele worked with large financial institutions allowing him to acquire an understanding of enterprise processes and security and compliance requirements of large enterprise customers.
Raffaele has become part of the CNCF TAG Storage and contributed to the Cloud Native Disaster Recovery whitepaper.
Recently Raffaele has been focusing on how to improve the developer experience by implementing internal development platforms (IDP).
Mais como este
O paradoxo agêntico e o argumento a favor da IA híbrida
Pare de gerenciar o passado e comece a construir o futuro da TI
Untangling Networks | Compiler
Operating System Management | Compiler
Navegue por canal

Automação
Últimas novidades em automação de TI para empresas de tecnologia, equipes e ambientes

Inteligência artificial
Descubra as atualizações nas plataformas que proporcionam aos clientes executar suas cargas de trabalho de IA em qualquer ambiente

Nuvem híbrida aberta
Veja como construímos um futuro mais flexível com a nuvem híbrida

Segurança
Veja as últimas novidades sobre como reduzimos riscos em ambientes e tecnologias

Edge computing
Saiba quais são as atualizações nas plataformas que simplificam as operações na borda

Infraestrutura
Saiba o que há de mais recente na plataforma Linux empresarial líder mundial

Aplicações
Conheça nossas soluções desenvolvidas para ajudar você a superar os desafios mais complexos de aplicações
Virtualização
O futuro da virtualização empresarial para suas cargas de trabalho on-premise ou na nuvem