-
Prodotti e documentazione Red Hat AI
Una piattaforma di prodotti e servizi per lo sviluppo e il deployment dell'IA nel cloud ibrido.
Red Hat AI Enterprise
Crea, sviluppa e distribuisci applicazioni basate sull'IA nel cloud ibrido.
Red Hat AI Inference Server
Ottimizza le prestazioni dei modelli con vLLM per un'inferenza rapida e conveniente in modo scalabile.
Red Hat Enterprise Linux AI
Sviluppa, testa ed esegui modelli di IA generativa con funzionalità di inferenza ottimizzate.
Red Hat OpenShift AI
Crea e distribuisci applicazioni e modelli basati sull'IA in modo scalabile negli ambienti ibridi.
-
Formazione Concetti di base
-
Partner per l'IA
L’importanza dell'inferenza IA
Senza l’inferenza, l’IA non esisterebbe.
L'inferenza è una funzionalità indispensabile per l'IA generativa. Tuttavia, la crescente complessità dei modelli può ripercuotersi negativamente sulla sua efficacia.
Occorre pertanto analizzare le sfide legate all'inferenza IA, dall'ottimizzazione del modello con vLLM ai più recenti framework distribuiti open source come llm-d, per poterne sfruttare appieno le opportunità.

Perché l'inferenza è essenziale?
L’inferenza è la fase finale di un processo di machine learning lungo e complesso, in cui il modello genera l’output previsto.
Nella fattispecie, si tratta di una funzione necessaria affinché l'IA funzioni correttamente.
Ecco perché l'hardware e il software che supportano le funzionalità di inferenza possono determinare il successo o il fallimento della tua strategia di IA.

Quali sono le difficoltà legate alla scalabilità?
L'inferenza è sottoposta a una forte pressione da parte di modelli che continuano a crescere. Man mano che i modelli aumentano di complessità, l'inferenza tende a rallentare.
Affinché l'inferenza possa garantire piena efficacia, i modelli di IA devono eseguire una grande quantità di calcoli in un breve lasso di tempo. Fattori come le dimensioni del modello, il volume elevato degli utenti e la latenza possono limitare le prestazioni.
Quando i modelli necessitano di più dati e di più memoria, hardware e acceleratori faticano a tenere il passo.
66%
Le risorse di calcolo dell'IA che si prevede saranno assorbite dall'inferenza nel 2026, rispetto al 33% del 2023 e al 50% del 2025.1
Come si può migliorare l'inferenza?
Ottimizzando l'inferenza, i modelli di IA riescono a lavorare in modo più veloce e intelligente.
Tra i metodi di ottimizzazione troviamo un'elaborazione più efficiente dei processi di GPU, la decodifica speculativa, la sparsità, la compressione dei modelli con tecniche di quantizzazione e l'inferenza distribuita.
Strumenti come LLM Compressor utilizzano le ricerche più recenti sulla compressione dei modelli per rendere gli LLM più piccoli, più efficienti dal punto di vista energetico e più veloci. Ciò riduce i requisiti hardware migliorando l'efficienza, senza rinunciare all'accuratezza.
Ottimizzazioni come queste aiutano a contenere i costi legati all’inferenza IA, in modo da adattarla con scalabilità in base all’evoluzione dei tuoi team e delle loro esigenze.
> 99%
Mantenimento dell'accuratezza durante le ottimizzazioni con LLM Compressor.2

2 x
Più throughput per l'elaborazione utilizzando modelli compressi senza compromettere l'accuratezza.3
50%
Risparmio sui costi preservando le prestazioni con l'ottimizzazione dei modelli tramite LLM Compressor.4

In che modo vLLM ottimizza l'inferenza?
L'ottimizzazione dei modelli è solo metà dell'opera. Occorre anche un motore di inferenza ad alte prestazioni, ed è questo è il contesto in cui subentra vLLM.
I sistemi di gestione della memoria LLM tradizionali non gestiscono la memoria nel modo più efficiente, il che ne rallenta l'attività. vLLM utilizza PagedAttention, una tecnica di gestione della memoria che identifica i valori chiave ripetitivi per ridurre il sovraccarico per gli LLM.
Ciò consente a vLLM di utilizzare al meglio la memoria GPU e velocizzare l'inferenza IA generativa. Questa strategia massimizza il throughput (token elaborati al secondo) per distribuire le soluzioni a più utenti contemporaneamente.
L'utilizzo degli acceleratori in modo più efficiente consente ai modelli di svolgere più calcoli matematici in un minore intervallo di tempo, permettendo ai team di soddisfare più utenti e agenti più velocemente.
50%
Riduzione dei parametri con l'utilizzo della struttura di sparsità5

2,1 x
Riduzione del tempo di latenza dell'inferenza grazie a tecniche di decodifica speculativa.6
24 x
Aumento del throughput con vLLM rispetto alla concorrenza.7
Perché vLLM è così diffuso?
vLLM ha contribuito a gestire le sfide principali riguardanti un utilizzo efficiente delle GPU. Ciò ha permesso di ridurre il costo per token, ottenendo una latenza stabile in maniera scalabile, grazie a un approccio di implementazione aperto e in grado di garantire portabilità.
La community vLLM è costituita da un’ampia base di utenti di gruppi esperti e appassionati come Hugging Face, UC Berkeley, NVIDIA, Red Hat e molti altri. La community contribuisce in maniera dinamica a migliorare costantemente il software nel progetto open source.
Con un supporto dalla fase 0 per tutti i modelli e gli acceleratori principali, offre un'accessibilità interessante sia per l'industria che per il mondo accademico.
Più di 10.000
vLLM GitHub commit*—un aumento superiore al 200%—nel 2025.
La community di vLLM oggi
Più di 500.000
GPU distribuitie 24 ore su 24, 7 giorni su 78
Più di 200
Acceleratori di vario tipo9
Più di 500
Architetture dei modelli supportate9
Più di 2.200
Dove si inserisce l'inferenza distribuita?
Con l'inferenza distribuita i modelli di IA suddividono le attività di inferenza su un gruppo di dispositivi interconnessi.
Quando un modello è in grado di soddisfare diverse richieste tutte allo stesso tempo, riduce significativamente l'hardware necessario e aumenta l'efficienza dell'inferenza.
L'inferenza distribuita utilizza tecniche come il parallelismo tensoriale, la programmazione intelligente dell'inferenza e la disaggregazione. Quando integrata con vLLM, l'inferenza diventa uno strumento polivalente molto efficiente.
Ciò permette di mantenere l'inferenza monitorabile, scalabile e coerente.
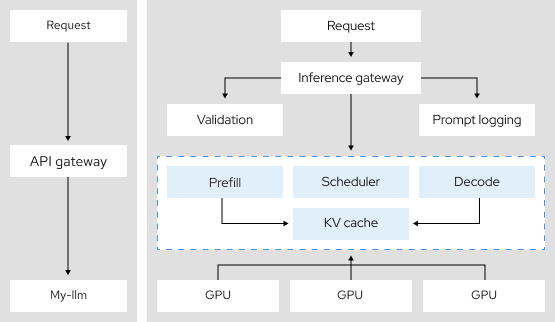
3,9 x
Aumento del throughput per token utilizzando il parallelismo tensoriale, un'architettura di inferenza distribuita.10
Esiste una community open source dedicata all’inferenza distribuita?
Sì, si chiama llm-d.
llm-d è un framework open source che offre agli sviluppatori un modello per realizzare un'inferenza distribuita in modo scalabile.
La sua architettura modulare supporta le complesse necessità di risorse degli LLM avanzati e sostituisce i processi manuali e frammentati con percorsi integrati e ben definiti, accelerando i tempi dal progetto pilota alla produzione.
llm-d introduce l'inferenza in Kubernetes, fornendo un kit di strumenti standardizzato che aiuta ad applicare l'inferenza distribuita agli scenari di utilizzo aziendali specifici.
2 x
Aumento della baseline di query al secondo (QPS, Queries Per Second) supportata da llm-d.11
Ulteriori risorse di IA
Red Hat AI Inference Server
Trasferisci più rapidamente i tuoi LLM dalla fase di codice al passaggio in produzione.
Realizzato a partire da vLLM, il nostro motore di inferenza pensato per le aziende consente un'inferenza più rapida senza ripercuotersi sulle prestazioni.
Ottieni la scalabilità nel cloud ibrido con il tuo modello di IA gen preferito e ottimizzato su qualsiasi acceleratore di IA e in qualsiasi ambiente cloud.

Fonti citate
[1] "Why AI’s Next Phase Will Likely Demand More Computing Power—Not Less ."The Wall Street Journal, 22 gen. 2026.
[2] Kurtić, Eldar, et al. "We ran over half a million evaluations on quantized LLMs—here's what we found." Blog di Red Hat Developer, 17 ott. 2024.
[3] Condado, Carlos. "A strategic approach to AI inference performance." Blog Red Hat, 15 set. 2025.
[4] Zelenović, Saša. "Unleash the full potential of LLMs: Optimize for performance with vLLM." Blog di Red Hat, 27 feb. 2025.
[5] Kurtić, Eldar, et al. "2:4 Sparse Llama: Smaller models for efficient GPU inference." Blog di Red Hat Developer, 28 feb 2025.
[6] Marques, Alexandre, et al. "Fly Eagle(3) fly: Faster inference with vLLM & speculative decoding." Blog di Red Hat Developer, 1° lug. 2025.
[7] Kwon, Woosuk, et al. "vLLM: Easy, Fast, and Cheap LLM Serving with PagedAttention." Blog vLLM, 20 giu. 2023.
[8] Goin, Michael. "[vLLM Office Hours #38] vLLM 2025 Retrospective & 2026 Roadmap - December 18, 2025." YouTube, 8 dic. 2025.
[9] Kwon, Woosuk. "Today, vLLM supports 500+ model architectures, runs on 200+ accelerator types, and powers inference at global scale." X, 26 gen. 2026.
[10] Goin, Michael. "Distributed inference with vLLM.” Red Hat Developer, 6 feb. 2025.
[11] Shaw, Robert. "llm-d: Kubernetes-native distributed inferencing." Red Hat Developers, 20 mag. 2025.