Osserviamo una tendenza significativa: sempre più organizzazioni utilizzano l'infrastruttura dei modelli linguistici di grandi dimensioni (LLM) internamente. Che la scelta sia motivata da esigenze di latenza, conformità o privacy dei dati, l'hosting autonomo con modelli open source sul tuo hardware ti consente di avere il pieno controllo del percorso verso l'IA. Tuttavia, trasformare gli LLM da elementi di sperimentazione a servizi in produzione comporta notevoli costi e complessità.
Un nuovo framework open source, llm-d, supportato da numerosi contributori tra cui Red Hat, IBM e Google, è stato progettato per affrontare queste sfide. Si concentra sul cuore del problema: l'inferenza IA, il processo con cui il modello genera risultati per prompt, agenti, retrieval augmented generation (RAG) e altro ancora.
Grazie a decisioni di pianificazione intelligenti (disaggregazione) e modelli di routing specifici per l'IA, llm-d consente una distribuzione dinamica e intelligente dei carichi di lavoro per gli LLM. Perché è così importante? Scopri come funziona llm-d e come può aiutare a risparmiare sui costi dell'IA, migliorando al contempo le prestazioni.
La sfida della scalabilità dell'inferenza degli LLM
La scalabilità dei servizi web tradizionali su piattaforme come Kubernetes segue schemi consolidati. Le richieste HTTP standard sono in genere veloci, uniformi e stateless. La scalabilità dell'inferenza degli LLM, tuttavia, è un problema fondamentalmente diverso.
Uno dei motivi principali è l'elevata varianza delle caratteristiche delle richieste. Un modello RAG, ad esempio, potrebbe utilizzare come input un prompt lungo e ricco di contesto proveniente da un database vettoriale, per generare una risposta breve e condensata in una frase. Al contrario, un'attività di ragionamento può iniziare con un prompt breve e produrre una risposta lunga e composta da più passaggi. Questa varianza crea squilibri di carico che possono ridurre le prestazioni e aumentare la latenza di coda. Per archiviare i risultati intermedi, l'inferenza degli LLM si affida anche alla cache key value (KV), la memoria a breve termine di un LLM. Il bilanciamento del carico tradizionale ignora lo stato della cache, causando un routing delle richieste inefficiente e il sottoutilizzo delle risorse di elaborazione.

Con Kubernetes, l'approccio attuale prevede il deployment degli LLM come container monolitici, simili a grandi scatole nere prive di visibilità o controllo. L'approccio, oltre a ignorare la struttura dei prompt, il numero di token, gli obiettivi di latenza della risposta (Obiettivi del livello di servizio o SLO), la disponibilità della cache e molti altri fattori, incide sull'efficacia della scalabilità.
In breve, i nostri sistemi di inferenza attuali sono inefficienti e utilizzano più risorse di elaborazione del necessario.
llm-d rende l'inferenza più efficiente e conveniente
Se vLLM offre supporto per i modelli su un'ampia gamma di hardware, llm-d compie un ulteriore passo avanti. Basandosi sulle infrastrutture IT aziendali in uso, llm-d offre funzionalità di inferenza distribuita e avanzata che permettono di risparmiare sulle risorse e migliorare le prestazioni, ad esempio migliorando fino a tre volte il tempo di rilascio del primo token e raddoppiando lo SLO relativo ai vincoli di throughput in condizioni di latenza. Sebbene offra una serie di importanti innovazioni, llm-d si concentra principalmente su due nuovi concetti che aiutano a migliorare l'inferenza.
- La disaggregazione del processo: consente di utilizzare in modo più efficiente gli acceleratori hardware durante l'inferenza. Consiste nel separare l'elaborazione dei prompt (fase di precompilazione) dalla generazione dei token (fase di decodifica) in singoli carichi di lavoro, chiamati pod. Questa separazione favorisce la scalabilità e l'ottimizzazione indipendenti di ogni fase, poiché hanno esigenze di elaborazione diverse.
- Il secondo concetto è il livello di pianificazione intelligente. Estende l'API Gateway di Kubernetes, consentendo decisioni di routing più specifiche per le richieste in entrata. Sfrutta dati in tempo reale, come l'utilizzo della cache KV e il carico dei pod, per indirizzare le richieste all'istanza ottimale, massimizzando gli accessi alla cache e bilanciando il carico di lavoro nel cluster.

Oltre a funzionalità come la memorizzazione nella cache delle coppie KV tra le richieste per impedire il ricalcolo, llm-d suddivide l'inferenza degli LLM in servizi modulari e intelligenti per ottenere prestazioni scalabili (si basa sul supporto esteso fornito da vLLM). Approfondiamo queste tecnologie per scoprire come vengono utilizzate da llm-d, con alcuni esempi pratici.
Come la disaggregazione aumenta il throughput a una latenza inferiore
La differenza fondamentale tra la fase di precompilazione e quella di decodifica dell'inferenza degli LLM crea alcune difficoltà per l'allocazione uniforme delle risorse. La fase di precompilazione, in cui viene elaborato il prompt di input, è vincolata all'elaborazione e richiede un'elevata potenza di calcolo per creare le voci KV iniziali della cache. La fase di decodifica invece, in cui i token vengono generati uno a uno, è spesso legata alla larghezza di banda della memoria, poiché prevede principalmente la lettura e la scrittura nella cache KV con esigenze di calcolo relativamente inferiori.
Implementando la disaggregazione, llm-d consente a questi due profili di elaborazione distinti di essere serviti da pod Kubernetes separati. Ciò significa che è possibile eseguire il provisioning dei pod di precompilazione con risorse ottimizzate per le attività di elaborazione più impegnative e di decodificare i pod con configurazioni personalizzate per ottimizzare la larghezza di banda della memoria.
Come funziona il gateway di inferenza compatibile con LLM
Il fulcro delle prestazioni di llm-d è il router di pianificazione intelligente, che orchestra dove e come vengono elaborate le richieste di inferenza. Quando una richiesta di inferenza arriva al gateway llm-d (basato su kgateway), non viene semplicemente inoltrata al successivo pod disponibile. Per determinare la destinazione ottimale, l'endpoint picker (EPP), un componente principale dello scheduler di llm-d, valuta i seguenti fattori in tempo reale.
- Compatibilità con la cache KV: lo scheduler mantiene un indice dello stato della cache KV per tutte le repliche di vLLM in esecuzione. Se una nuova richiesta condivide un prefisso comune con una sessione già memorizzata nella cache su un pod specifico, lo scheduler assegna la priorità al routing verso tale pod. Ciò aumenta notevolmente la frequenza di accesso alla cache, evitando calcoli di precompilazione ridondanti e riducendo direttamente la latenza.
- Compatibilità del carico: oltre al semplice conteggio delle richieste, lo scheduler valuta il carico effettivo su ciascun pod vLLM, considerando l'utilizzo della memoria GPU e le code di elaborazione per evitare sovraccarichi.
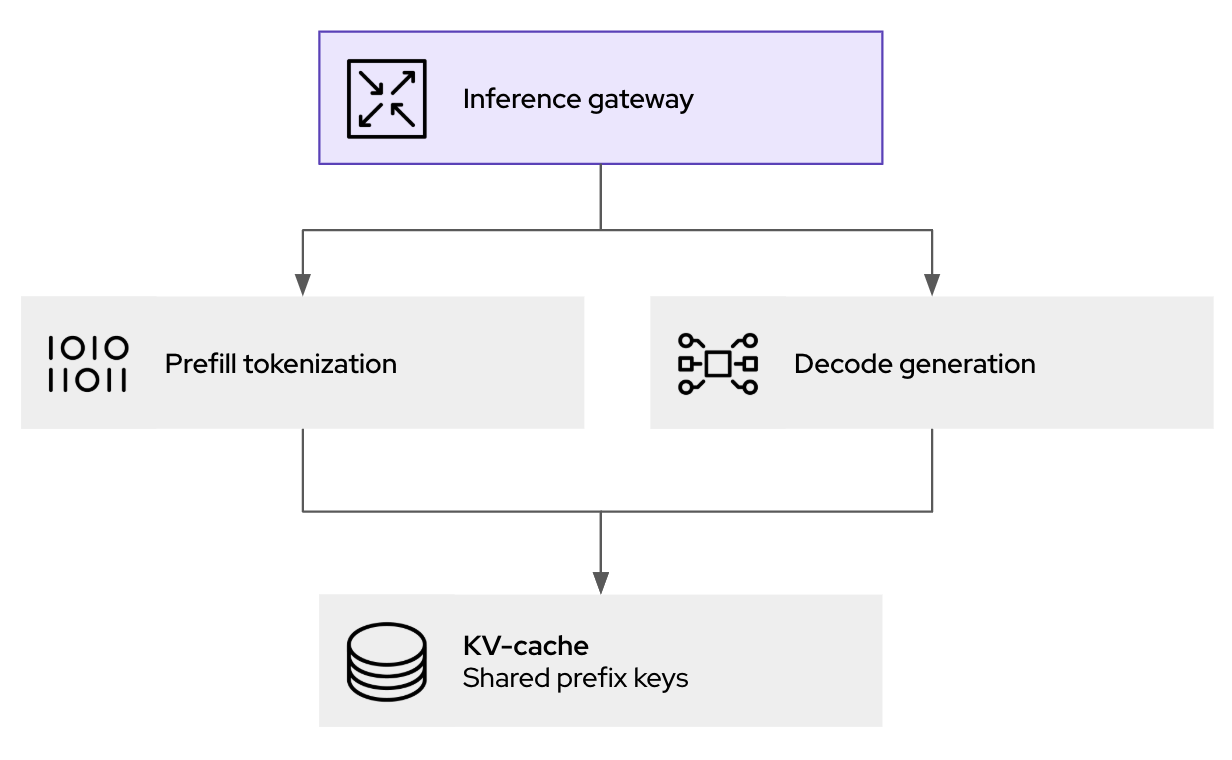
Questo approccio Kubernetes native fornisce il livello di policy, sicurezza e osservabilità per l'inferenza dell'IA generativa. Non solo aiuta a gestire il traffico, ma consente anche la registrazione e l'audit dei prompt (per le esigenze di governance e conformità), e le necessarie protezioni prima dell'inoltro all'inferenza.
Inizia a utilizzare llm-d
Il progetto llm-d è il frutto di un'energia entusiasmante. Mentre vLLM è l'ideale per le configurazioni a server singolo, llm-d è progettato per l'operatore che gestisce un cluster, con l'obiettivo di ottenere un'inferenza IA efficiente ed economica. Vuoi scoprirlo in autonomia? Dai un'occhiata al repository llm-d su GitHub e partecipa alla discussione su Slack. È il luogo ideale per porre domande e interagire.
Il futuro dell'IA si basa sui principi dell'open source e della collaborazione. Contribuendo a community come vLLM e a progetti come llm-d, Red Hat punta a rendere l'IA più accessibile, conveniente ed efficiente per gli sviluppatori di tutto il mondo.
Risorsa
Definizione della strategia aziendale per l'IA: una guida introduttiva
Sugli autori

Cedric Clyburn (@cedricclyburn), Senior Developer Advocate at Red Hat, is an enthusiastic software technologist with a background in Kubernetes, DevOps, and container tools. He has experience speaking and organizing conferences including DevNexus, WeAreDevelopers, The Linux Foundation, KCD NYC, and more. Cedric loves all things open-source, and works to make developer's lives easier! Based out of New York.

Christopher Nuland is a Principal Technical Marketing Manager for AI at Red Hat and has been with the company for over six years. Before Red Hat, he focused on machine learning and big data analytics for companies in the finance and agriculture sectors. Once coming to Red Hat, he specialized in cloud native migrations, metrics-driven transformations, and the deployment and management of modern AI platforms as a Senior Architect for Red Hat’s consulting services, working almost exclusively with Fortune 50 companies until recently moving into his current role. Christopher has spoken worldwide on AI at conferences like IBM Think, KubeCon EU/US, and Red Hat’s Summit events.
Altri risultati simili a questo
AI in telco – the catalyst for scaling digital business
The nervous system gets a soul: why sovereign cloud is telco’s real second act
Technically Speaking | Build a production-ready AI toolbox
Technically Speaking | Platform engineering for AI agents
Ricerca per canale

Automazione
Novità sull'automazione IT di tecnologie, team e ambienti

Intelligenza artificiale
Aggiornamenti sulle piattaforme che consentono alle aziende di eseguire carichi di lavoro IA ovunque

Hybrid cloud open source
Scopri come affrontare il futuro in modo più agile grazie al cloud ibrido

Sicurezza
Le ultime novità sulle nostre soluzioni per ridurre i rischi nelle tecnologie e negli ambienti

Edge computing
Aggiornamenti sulle piattaforme che semplificano l'operatività edge

Infrastruttura
Le ultime novità sulla piattaforma Linux aziendale leader a livello mondiale

Applicazioni
Approfondimenti sulle nostre soluzioni alle sfide applicative più difficili
Virtualizzazione
Il futuro della virtualizzazione negli ambienti aziendali per i carichi di lavoro on premise o nel cloud