Red Hat OpenShift Virtualization 4.19 migliora notevolmente le prestazioni e la velocità dei carichi di lavoro di I/O intensivi, come i database. Multiple IOThreads for Red Hat OpenShift Virtualization è una nuova funzionalità che consente di distribuire l'I/O su disco delle macchine virtuali (VM) tra più thread di lavoro sull'host, che a loro volta vengono mappati nelle code dei dischi all'interno della VM. Ciò consente alle VM di utilizzare in modo efficiente sia la vCPU che la CPU dell'host per l'I/O multistream, migliorando le prestazioni.
Questo articolo completa la presentazione della funzionalità della mia collega Jenifer Abrams. In aggiunta, fornisco i risultati delle prestazioni per aiutarti a ottimizzare la tua VM e ottenere un throughput di I/O migliore.
Per i test, ho utilizzato fio con le VM Linux come carico di lavoro di I/O sintetico. Sono in corso altre attività di test con le applicazioni e anche su Microsoft Windows.
Per ulteriori informazioni sull'implementazione di questa funzionalità in KVM, consulta l'articolo sul mapping di Virtqueue di IOThread e questo articolo complementare che illustra i miglioramenti delle prestazioni per i carichi di lavoro del database nelle VM eseguite in un ambiente Red Hat Enterprise Linux (RHEL).
Descrizione del test
Ho testato il throughput di I/O su due configurazioni:
- un cluster con storage locale che utilizza Logical Volume Manager fornito dal Local Storage Operator (LSO);
- un cluster separato che utilizza OpenShift Data Foundation (ODF).
Le configurazioni sono molto diverse e non è possibile metterle a confronto.
I test sono stati eseguiti su pod (come baseline) e VM. Alle VM sono stati assegnati 16 core e 8 GB di RAM. Per i test ho utilizzato file da 512 GB con 1 VM e da 256 GB con 2 VM. In tutti i test ho utilizzato l'I/O diretto. Ho utilizzato le attestazioni di volume persistenti (PVC), in modalità a blocchi e formattate come ext4, per le VM, e le PVC in modalità filesystem, anch'esse formattate come ext4 per i pod. Tutti i test sono stati eseguiti con il motore di I/O di libaio.
I test sono stati eseguiti con i dati della tabella seguente:
Parametro | Impostazioni |
Tipo di volume di storage | Locale (LSO), ODF |
Numero di pod/VM | 1, 2 |
Numero di thread di I/O (solo VM) | Nessuno (baseline), 1, 2, 3, 4, 6, 8, 12, 16 |
Operazioni di I/O | Letture e scritture sequenziali e casuali |
Dimensioni dei blocchi di I/O (byte) | 2 K, 4 K, 32 K, 1 M |
Processi simultanei | 1, 4, 16 |
I/O iodepth (iodepth) | 1, 4, 16 |
Ho utilizzato ClusterBuster per orchestrare i test. Le VM utilizzano CentOS Stream 9 e anche i pod utilizzano CentOS Stream come base di immagini dei container.
Storage locale
Il cluster di storage locale è un cluster a 5 nodi (3 nodi master + 2 nodi di lavoro) costituito da nodi Dell R740xd contenenti 2 CPU Intel Xeon Gold 6130, ciascuna con 16 core e 2 thread (32 CPU) per un totale di 32 core e 64 CPU. Ogni nodo contiene 192 GB di RAM. Il sottosistema di I/O è costituito da quattro unità Kioxia CM6 MU 1,6 TB NVMe a marchio Dell configurate come configurazione di più dispositivi (MD) con striping RAID0 con impostazioni predefinite. Le richieste di volumi persistenti sono state estratte da questa MD utilizzando l'operatore lvmcluster. Questa modesta configurazione era l'unica che avevo a disposizione ed è molto probabile che un sistema di I/O più veloce avrebbe prodotto ulteriori miglioramenti da più thread di I/O.
OpenShift Data Foundation
Il cluster OpenShift Data Foundation (ODF) è un cluster a 6 nodi (3 nodi master + 3 nodi di lavoro) costituito da nodi Dell PowerEdge R7625 contenenti 2 CPU AMD EPYC 9534, ciascuna con 64 core e 2 thread (128 CPU), per un totale di 128 core e 256 CPU. Ogni nodo contiene 512 GB di RAM. Il sottosistema di I/O è costituito da due unità NVMe da 5,8 TB per nodo, con replica a 3 vie su una rete di pod predefinita da 25 GbE. Non avevo accesso a una rete più veloce per questo test, ma un hardware di rete più recente avrebbe probabilmente garantito un miglioramento più netto.
Riepilogo dei risultati
Questo test valuta più thread di I/O con back end di I/O specifici che potrebbero non rappresentare il tuo scenario di utilizzo. Le differenze nelle caratteristiche dello storage possono incidere notevolmente sulla scelta del numero di thread di I/O.
Ecco cosa hanno rivelato i miei test.
- Throughput di I/O massimo: per lo storage locale, il throughput massimo è stato di circa 7,3 GB/sec in lettura e 6,7 GB/sec in scrittura, sia per i pod che per le VM, indipendentemente dall'iodepth o dal numero di processi nello storage locale. Questo dato è sostanzialmente inferiore a quanto ci si aspetterebbe dall'hardware. I dispositivi (4 PCIe gen4) hanno una velocità nominale di 6,9 GB/sec in lettura e 4,2 MB/sec in scrittura. Non ho ancora esaminato le cause, ma ho utilizzato un hardware obsoleto. Le prestazioni superiori sono chiaramente migliori rispetto alle prestazioni dell'unità singola, il che indica che lo striping ha avuto effetto. Per ODF, la prestazione massima ottenuta è di circa 5 GB/sec in lettura e 2 GB/sec in scrittura.
- L'I/O a blocchi di grandi dimensioni (1 MB) ha mostrato un miglioramento minimo o nullo, perché le prestazioni erano già limitate dal sistema.
- La scelta ottimale per il numero di thread di I/O varia in base al carico di lavoro e alle caratteristiche dello storage. Come previsto, i carichi di lavoro con un numero non significativo di I/O simultanei hanno offerto scarsi vantaggi.
- Storage locale: per le VM con un numero significativo di I/O simultanei, 4-8, è in genere un buon punto di partenza. Soprattutto per i carichi di lavoro che utilizzano dimensioni di I/O ridotte e simultaneità elevata, più thread possono risultare vantaggiosi.
- ODF: in rari casi la presenza di più di un thread di I/O simultanei ha prodotto vantaggi significativi e in molti casi non è stato necessario aggiungerne. Ciò è forse dovuto alla rete di pod relativamente lenta; è probabile che una rete più rapida produca risultati diversi.
- Almeno con questo test, più thread di I/O si sono dimostrati più efficaci nell'offrire miglioramenti con più processi simultanei rispetto all'I/O asincrono su più livelli.
- Ho rilevato poca differenza nel comportamento tra 1 e 2 VM simultanee fino a quando non è stato raggiunto il throughput massimo aggregato di I/O alla base (indicato sopra).
- I thread di I/O simultanei non hanno colmato completamente il divario con i pod, con un numero di processi inferiore o con iodepth I/O. Con un iodepth I/O più elevato e operazioni di piccole dimensioni, le VM hanno effettivamente superato i pod, con margini significativi nelle operazioni di scrittura.
Vantaggi in cifre
Di seguito è riportato il throughput di I/O complessivo che si ottiene utilizzando più thread di I/O sul mio sistema basato su storage locale. Come si può vedere, i carichi di lavoro con dimensioni di I/O più piccole e un grado di parallelismo elevato rispetto a un sistema di I/O veloce possono offrire grandi vantaggi. Di seguito riporto altri risultati ottenuti con diversi valori relativi ai thread di I/O. Ho riscontrato solo un lieve miglioramento con una dimensione del blocco di 1 MB, perché le prestazioni erano già molto vicine al limite del sistema alla base. Con un hardware più veloce, è possibile che thread di I/O aggiuntivi producano miglioramenti anche con blocchi di grandi dimensioni.
Miglioramento ottimale rispetto alla baseline delle VM con thread di I/O aggiuntivi | ||||||||||
(Storage locale) | processi | iodepth | ||||||||
1 | 4 | 16 | ||||||||
dimensione | operazione | 1 | 4 | 16 | 1 | 4 | 16 | 1 | 4 | 16 |
2048 | randread | 18% | 31% | 30% | 30% | 103% | 192% | 151% | 432% | 494% |
randwrite | 81% | 59% | 24% | 153% | 199% | 187% | 458% | 433% | 353% | |
read | 67% | 58% | 25% | 64% | 71% | 103% | 252% | 241% | 287% | |
write | 103% | 64% | 0% | 143% | 99% | 84% | 410% | 250% | 203% | |
Totale 2048 | 67% | 53% | 20% | 97% | 118% | 141% | 318% | 339% | 334% | |
4096 | randread | 18% | 34% | 28% | 33% | 101% | 208% | 156% | 432% | 492% |
randwrite | 95% | 69% | 20% | 149% | 200% | 187% | 471% | 543% | 481% | |
read | 26% | 53% | 27% | 24% | 46% | 66% | 142% | 155% | 165% | |
write | 103% | 69% | 0% | 144% | 86% | 48% | 438% | 256% | 161% | |
Totale 4096 | 60% | 56% | 19% | 87% | 108% | 127% | 302% | 346% | 325% | |
32768 | randread | 16% | 23% | 26% | 23% | 71% | 124% | 99% | 160% | 129% |
randwrite | 75% | 71% | 28% | 108% | 132% | 116% | 203% | 123% | 115% | |
read | 21% | 57% | 25% | 21% | 42% | 32% | 77% | 54% | 32% | |
write | 79% | 64% | 26% | 104% | 59% | 24% | 195% | 45% | 27% | |
Totale 32768 | 48% | 53% | 26% | 64% | 76% | 74% | 143% | 96% | 76% | |
1048576 | randread | 5% | 2% | 0% | 9% | 0% | 0% | 17% | 0% | 0% |
randwrite | 10% | 0% | 1% | 6% | 0% | 2% | 9% | 0% | 2% | |
read | 12% | 18% | 0% | 9% | 0% | 0% | 16% | 0% | 0% | |
write | 19% | 0% | 0% | 7% | 0% | 0% | 9% | 0% | 0% | |
Totale 1048576 | 11% | 5% | 0% | 8% | 0% | 1% | 13% | 0% | 0% | |
Di seguito è indicato il numero di thread di I/O necessari per ottenere il 90% del miglior risultato ottenibile con un massimo di 16 thread di I/O. Ad esempio, se il miglior risultato ottenuto nel mio test con una specifica combinazione di operazioni, dimensioni dei blocchi, processi e iodepth è stato di 1 GB/sec, la metrica in questo caso equivale al numero minimo di thread necessari per raggiungere 900 MB/sec. In questo modo è possibile impostare un numero ridotto di thread pur ottenendo prestazioni ottimali.
Numero minimo di iothread per ottenere il 90% di prestazioni migliori | ||||||||||
(Storage locale) | processi | iodepth | ||||||||
1 | 4 | 16 | ||||||||
dimensione | operazione | 1 | 4 | 16 | 1 | 4 | 16 | 1 | 4 | 16 |
2048 | randread | 1 | 1 | 1 | 1 | 4 | 8 | 3 | 12 | 12 |
randwrite | 1 | 1 | 1 | 3 | 16 | 12 | 8 | 12 | 12 | |
read | 1 | 1 | 1 | 1 | 4 | 4 | 4 | 6 | 8 | |
write | 1 | 1 | 0 | 2 | 12 | 6 | 8 | 6 | 6 | |
Totale 2048 | 1 | 1 | 1 | 2 | 9 | 8 | 6 | 9 | 10 | |
4096 | randread | 1 | 1 | 1 | 1 | 4 | 8 | 3 | 12 | 12 |
randwrite | 1 | 1 | 1 | 3 | 16 | 12 | 8 | 12 | 12 | |
read | 1 | 1 | 1 | 1 | 2 | 3 | 3 | 6 | 8 | |
write | 1 | 1 | 0 | 3 | 12 | 4 | 8 | 6 | 4 | |
Totale 4096 | 1 | 1 | 1 | 2 | 9 | 7 | 6 | 9 | 9 | |
32768 | randread | 1 | 1 | 1 | 1 | 3 | 6 | 2 | 4 | 3 |
randwrite | 1 | 1 | 1 | 2 | 12 | 6 | 4 | 3 | 3 | |
read | 1 | 1 | 1 | 1 | 2 | 2 | 2 | 2 | 2 | |
write | 1 | 1 | 1 | 2 | 6 | 2 | 4 | 2 | 1 | |
Totale 32768 | 1 | 1 | 1 | 2 | 6 | 4 | 3 | 3 | 2 | |
1048576 | randread | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 |
randwrite | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | |
read | 1 | 1 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | |
write | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | |
Totale 1048576 | 1 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | |
Risultati dettagliati
Per ogni scenario di test misurato, ho calcolato le seguenti cifre di merito:
- Misurazione del throughput di I/O
- Migliori prestazioni delle VM (non segnalate direttamente)
- Numero minimo di iothread per ottenere il 90% di prestazioni migliori delle VM
- Rapporto tra le migliori prestazioni delle VM e quelle dei pod
- Miglioramento delle migliori prestazioni delle VM rispetto alla prestazione della VM di base
NON sto segnalando il numero di thread per la prestazione migliore, perché in molti casi le differenze sono molto piccole, inferiori alla normale varianza delle prestazioni di I/O segnalate.
Fornisco riepiloghi separati per i risultati relativi allo storage locale e a ODF, perché hanno caratteristiche molto diverse.
Tutti i grafici delle prestazioni seguenti mostrano i risultati per i pod (pod), una VM di base senza thread di I/O (0) e il numero specificato di thread di I/O sull'asse X.
Storage locale
Se osserviamo le prestazioni non elaborate, notiamo che, almeno in alcuni casi, l'utilizzo di più thread di I/O offre vantaggi sostanziali. Ad esempio, con 16 processi, I/O asincrono con iodepth 1 sullo storage locale, l'utilizzo di thread di I/O aggiuntivi può, nella maggior parte dei casi, produrre vantaggi consistenti:
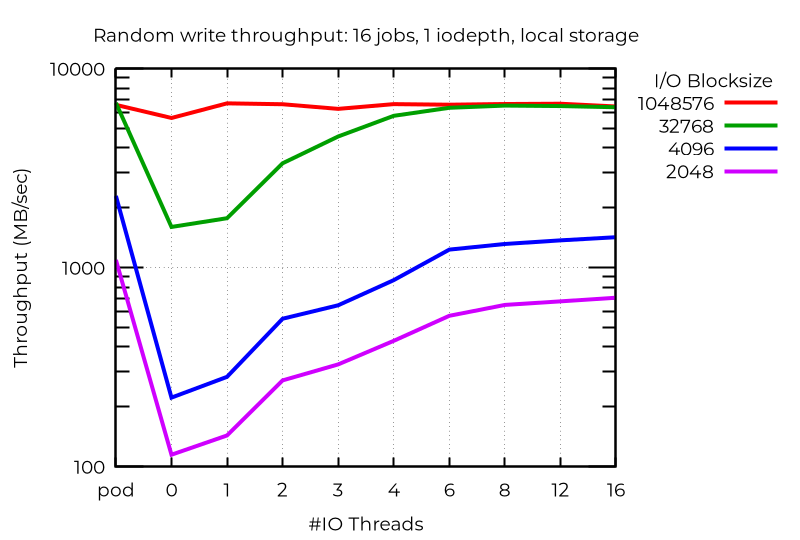
Anche con un singolo flusso di I/O, l'utilizzo di un thread I/O in più può offrire vantaggi. Non sempre l'aggiunta di thread è d'aiuto:

In alcuni casi anomali, l'aggiunta di thread di I/O compromette le prestazioni. In questo caso, utilizzando un I/O asincrono su più livelli con blocchi di piccole dimensioni, le prestazioni migliori (anche rispetto ai pod) si ottengono con le VM che non utilizzano thread di I/O dedicati. Non ho ancora stabilito il motivo per cui ciò accade.
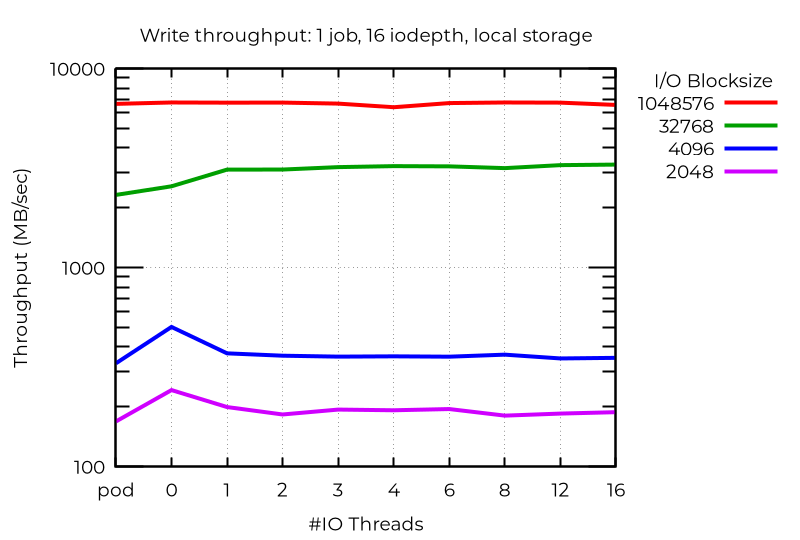
Questo lavoro dimostra che per ottenere le migliori prestazioni da più thread di I/O, è necessario effettuare le dovute sperimentazioni con il proprio carico di lavoro specifico.
Risultati del cluster ODF
A differenza dello storage locale, in cui la scrittura casuale di piccoli blocchi ha mostrato notevoli miglioramenti con l'utilizzo di più thread di I/O, con ODF ho osservato un miglioramento minimo, anche con un numero elevato di processi. È probabile che una rete più veloce o una latenza inferiore offrano maggiori vantaggi. Le operazioni di lettura, in particolare la lettura casuale, hanno ottenuto vantaggi modesti, mentre le operazioni di scrittura e un numero di processi inferiore hanno fatto registrare vantaggi scarsi, se non nulli.
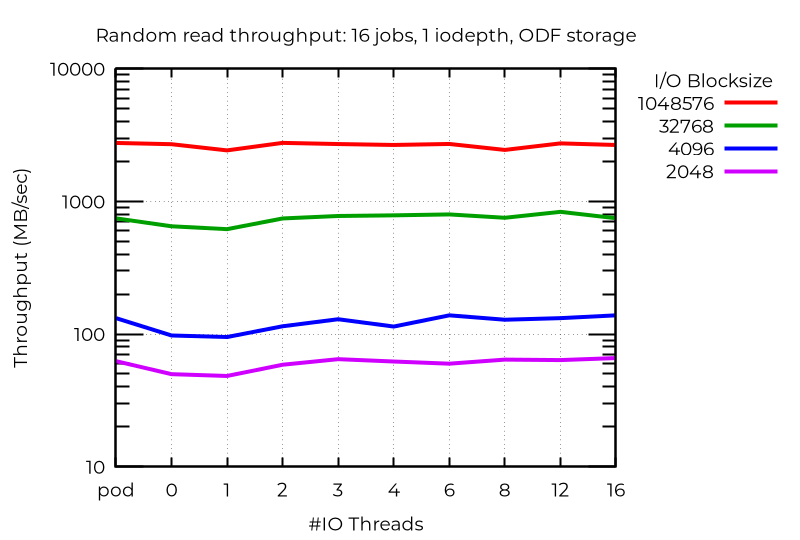
Conclusioni
Multiple I/OThreads for OpenShift Virtualization è una nuova interessante funzionalità di OpenShift 4.19 in grado di offrire miglioramenti sostanziali delle prestazioni di I/O per i carichi di lavoro con I/O simultanei, in particolare con i sistemi di I/O veloci come lo storage NVMe locale utilizzato nei miei test. I sottosistemi di I/O più veloci possono ottenere vantaggi elevati dall'utilizzo di più thread di I/O, perché sono necessarie più CPU per gestire l'I/O bare metal alla base. Come sempre per l'I/O, le differenze nei sistemi di I/O e nei carichi di lavoro complessivi possono influire notevolmente sulle prestazioni, quindi ti consiglio di testare i tuoi carichi di lavoro per sfruttare al meglio questa nuova funzionalità. Spero che i risultati dei miei test ti aiuteranno a scegliere consapevolmente i tuoi thread di I/O.
Prova prodotto
Red Hat OpenShift Virtualization Engine | Versione di prova del prodotto
Sull'autore

Altri risultati simili a questo
Modernize virtual machines on Google Cloud with Red Hat OpenShift Virtualization
Migrate your VMs faster with the migration toolkit for virtualization 2.11
Ricerca per canale

Automazione
Novità sull'automazione IT di tecnologie, team e ambienti

Intelligenza artificiale
Aggiornamenti sulle piattaforme che consentono alle aziende di eseguire carichi di lavoro IA ovunque

Hybrid cloud open source
Scopri come affrontare il futuro in modo più agile grazie al cloud ibrido

Sicurezza
Le ultime novità sulle nostre soluzioni per ridurre i rischi nelle tecnologie e negli ambienti

Edge computing
Aggiornamenti sulle piattaforme che semplificano l'operatività edge

Infrastruttura
Le ultime novità sulla piattaforma Linux aziendale leader a livello mondiale

Applicazioni
Approfondimenti sulle nostre soluzioni alle sfide applicative più difficili
Virtualizzazione
Il futuro della virtualizzazione negli ambienti aziendali per i carichi di lavoro on premise o nel cloud