A SAAS solution to monitor your Ceph storage infrastructure
By Ilan Rabinovitch (Datadog) and Federico Lucifredi (Red Hat)
Monitoring a distributed system
Red Hat Ceph Storage is a highly scalable, fault-tolerant platform for object, block, and file storage that delivers excellent data resiliency (we default to keeping three copies of a customer’s data at all times), with service availability capable of enduring the loss of a single drive, of a cluster node, or even of an entire rack of storage without users experiencing any interruption. Like its resiliency, Ceph’s ability to scale is another outcome of its distributed architecture.
Distributed systems' architectures break with the common assumptions made by most traditional monitoring tools in defining the health of an individual device or service. In a somewhat obvious example, Nagios’ Red/Green host (or drive) health status tracking becomes inadequate, as the loss of a drive either generates unnecessary alerts or fails to highlight enough what is likely to be a more urgent condition, like the loss of a MON container. The system can withstand the loss of multiple drives or storage nodes without needing immediate action from an operator, as long as free storage capacity remains available on other nodes. More urgent events, like the loss of a MON bringing the cluster from HA+1 to HA status, would, however, be mixed in with all the other “red” false alarms and lost in all the noise.
Distributed systems need monitoring tools that are aware of their distributed nature to ensure that pagers go off only for alerts truly critical in nature. Most hardware failure reports naturally found in a large enough system are managed weekly or monthly as part of recurring maintenance activity. An under-marketed advantage of distributed systems is that the swapping of failed drives or the replacement of PSUs becomes a scheduled activity, not an emergency one.
Red Hat Ceph Storage’s built-in monitoring tools are designed to help you keep tabs on your clusters' health, performance, and resource usage, while avoiding distributed-systems awareness shortcomings. Red Hat has a long history of customer choice, and for that reason we include with Red Hat Ceph Storage documentation information on how to use external monitoring tools. Nagios may be sub-optimal for the details, but it is still the closest thing we have to a standard in the open source community’s fragmented monitoring space.
Datadog is much more interesting.
Monitoring is a service
Unlike traditional monitoring solutions, Datadog's Software-as-a-Service (SaaS) platform was built specifically for dynamic distributed systems like Red Hat Ceph Storage. Datadog automatically aggregates data from ephemeral infrastructure components, so you can maintain constant visibility even as your infrastructure scales up or down. And because Datadog is fully hosted, it self-updates with features so you only get alerted when it matters most. Field-tested machine learning algorithms distinguish between normal and abnormal trends, and you can configure alerts to trigger only on truly urgent occurrences (e.g., the loss of a Ceph monitor rather than the loss of a single storage node). To enable data-driven collaboration and troubleshooting, Datadog automatically retains your monitoring data for more than a year and makes that data easily accessible from one central platform.
Datadog provides an out-of-the-box integration with Red Hat Ceph Storage to help you get more real-time visibility into the health and performance of your clusters with near-zero setup delay. Datadog also delivers template integrations with more than 250 other technologies, including services that are commonly used with Ceph storage, like OpenStack and Amazon S3, so you can get more comprehensive insights into every layer of your stack in one place.
We will explore a few ways in which you can use Datadog to monitor Red Hat Ceph Storage in full context with the rest of your stack. Then we'll explain how to set up Datadog to start getting clearer insights into your Ceph deployment in three easy steps.
Key Ceph metrics at a glance
Datadog automatically collects metrics from your Red Hat Ceph Storage clusters and makes it easy to explore, visualize, and alert on this data at the cluster, pool, and node levels. The integration includes a template Ceph dashboard that displays an overview of health and performance data from your monitor and storage nodes. You can use the template variables at the top of the dashboard to filter metrics by individual clusters, pools, and Object Storage Daemons (OSDs) to get more granular insights.

Red Hat Ceph Storage includes robust features for high availability and performance and, by monitoring its built-in health checks, you can help you ensure everything is running smoothly.
Datadog automatically queries Ceph for the status of these health checks, along with other key information about your nodes, including:
- Object Storage Daemon (OSD) status: Quickly find out if an OSD is down, so you can try restarting the node or troubleshooting potential issues (e.g., networking, disk capacity).
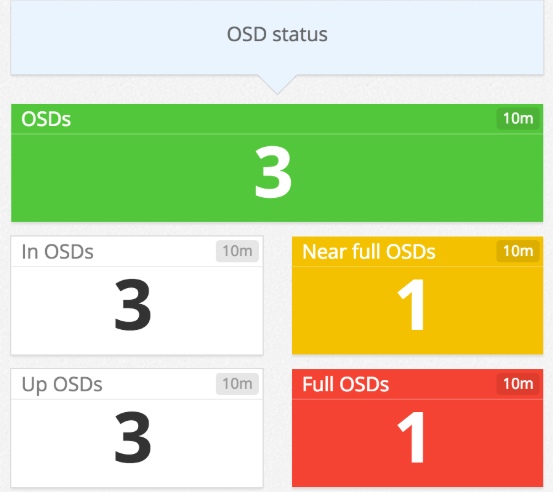
- Monitor status: If you're running more than one monitor in your cluster (as recommended for high availability), Ceph requires a quorum of monitor nodes to reach a consensus about the latest version of the cluster map. Monitor nodes fall out of the quorum when they become unavailable, or when they fall behind and cannot access the latest version of the map. If your cluster cannot maintain a quorum, clients will be unable to read or write data from the cluster. With Datadog, you can track the number of available monitor nodes in your cluster, as well as the real-time quorum status (the number of monitors in the quorum). You can also set up an alert that notifies you when the number of monitors in the quorum decreases, so you can have enough time to troubleshoot the issue or deploy more nodes if needed.
- Storage capacity: Datadog's Red Hat Ceph Storage integration reports OSD storage capacity metrics so you can take action before any OSD runs out of disk space (at which point Ceph will stop writing data to the OSD to guard against data loss). You can set up an alert to detect when any OSD reaches a "NEARFULL" state (85 percent capacity, by default), which gives you enough time to add more OSDs, as recommended in the documentation. You can also use Datadog's forecasting algorithms to get notified a certain amount of time before any OSD, pool, or cluster is predicted to run out of disk space.

Increased visibility across Ceph metrics
Datadog's integration also reports other metrics from Ceph, including the rate of I/O operations and commit latency. See the full list of metrics collected as part of this integration in our documentation.
Although it's important to monitor these metrics, they provide only part of the picture. In the next section, we'll explore a few of the other ways you can use Datadog to monitor Red Hat Ceph Storage alongside all the other services in your environment.
Monitoring Ceph in context
Your infrastructure depends on Ceph for storage, but it also relies on a range of other systems, services, and applications. To help you monitor Red Hat Ceph Storage in context with other components of your stack, Datadog also integrates with more than 250 technologies, including Amazon S3 and OpenStack Nova.
Monitoring OpenStack + Ceph
If you've deployed Ceph on OpenStack, Datadog can help you get clearer insights into your infrastructure across multiple dimensions. Datadog's OpenStack integration includes a default dashboard that provides a high-level overview of metrics from the hypervisors, Nova servers, tenants, and other components of your OpenStack Compute cluster.

To learn more about integrating Datadog with OpenStack, consult the documentation.
Monitoring Amazon S3 + Ceph
If you're using Amazon S3 alongside Red Hat Ceph Storage, it's important to track your S3 activity in real time. Datadog's AWS S3 integration automatically collects metrics related to request throughput, HTTP errors, and latency. Upon setting up the AWS S3 integration, you'll see all these key metrics displayed in an out-of-the-box dashboard.
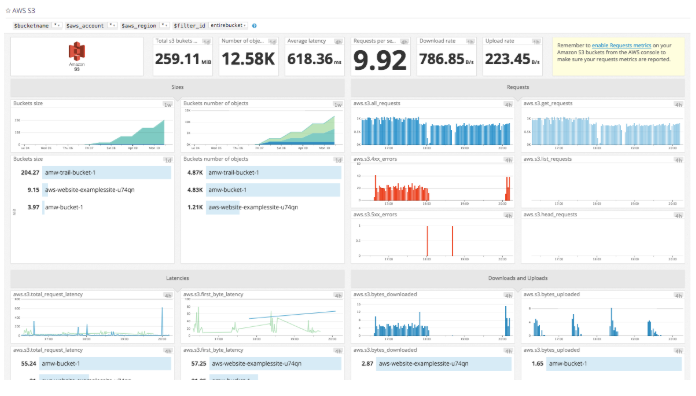
To learn more about integrating Datadog with AWS S3, consult the documentation.
More visibility with APM and logs
Datadog's distributed tracing and APM can help you monitor the performance of applications and services that use Ceph. Datadog APM is fully integrated with the rest of Datadog, so you can easily navigate from inspecting a distributed request trace to viewing system-level metrics from the specific host that executed that unit of work.
You can also use log processing and analytics to collect and monitor Ceph logs in the same place as your metrics and distributed request traces. Simply follow the configuration steps described here.
Setup guide
It only takes a few minutes to set up Datadog's Ceph integration. The open source Datadog Agent collects data (including system-level metrics like CPU and memory usage) from all your nodes, as well as the services running on those nodes, so that you can view, correlate, and alert on this data in real time.
Installing the Agent on a node usually only takes a single command—see the instructions for your platform here. You can also deploy the Agent across your entire Ceph cluster with configuration management tools like Chef and Ansible, if desired.
Configure metric collection
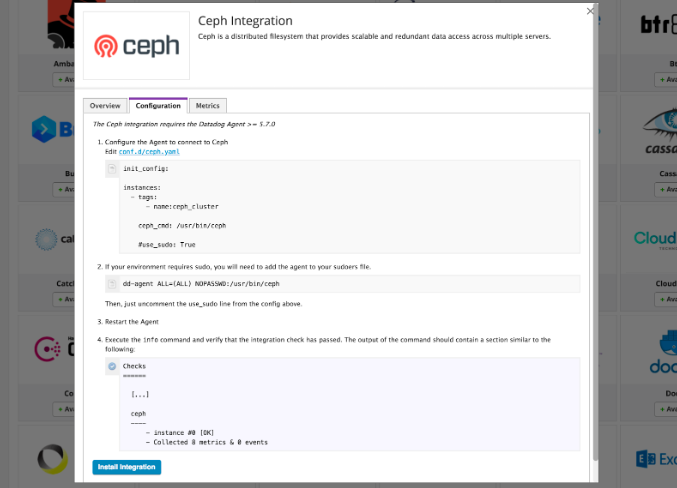
To configure the Datadog Agent to collect Ceph metrics, you'll need to create a configuration file for the integration on your Ceph nodes. The Agent comes with an example config that you can use as a template. Navigate to the "ceph.d" directory within your Agent's configuration directory, and locate the example configuration file: **conf.yaml.example**.
Copy the example to a new **conf.yaml** file, and edit the new file to include the correct path to your Ceph executable. The Agent check expects the executable to be located at "/usr/bin/ceph", but you can specify a different path if needed:
init_config: instances: - ceph_cmd: /path/to/your/ceph # default is /usr/bin/ceph use_sudo: true # only if the ceph binary needs sudo on your nodes
As the preceding example shows, you can also enable "sudo" access if it's required to execute "ceph" commands on your nodes. If you enable the "use_sudo" option, you must also add the Datadog Agent to your sudoers file, as described in the documentation. For example:
dd-agent ALL=(ALL) NOPASSWD:/usr/bin/ceph
Restart the Agent
Save and exit the configuration file. Restart the Agent using the command for your platform (as specified here) to pick up the Agent configuration change. Then run the Agent status command to ensure that the Agent can successfully connect to Ceph and retrieve data from your cluster. When the integration is working properly, you should see a "ceph" section in the terminal output, similar to the following snippet:
Running Checks ============== ceph (unversioned) ------------------ Total Runs: 124 Metric Samples: 27, Total: 3348 Events: 0, Total: 0 Service Checks: 19, Total: 2356 Average Execution Time : 2025ms
In the Datadog platform, navigate to the Ceph integration tile of your Datadog account and click the "Install Integration" button.
Now that the Datadog Agent is collecting metrics from Ceph, you should start to see data flowing into the built-in Ceph dashboard in your Datadog account.
After you deploy Datadog, your Ceph data is available for visualization, alerting, and correlation with monitoring data from the rest of your infrastructure and applications. The template Ceph dashboard provides a high-level overview of your cluster at a glance, but you can easily customize it to highlight the information that matters most. And dashboards are just the tip of the iceberg—You can use features like the Host Map to visualize how resources are distributed across availability zones. Visit Datadog's web site to learn more about how these and other features can help you ensure the availability and performance of Ceph and the rest of your systems.
For more detailed setup instructions and a full list of metrics collected as part of the Red Hat Ceph Storage integration, consult Datadog’s documentation.
For more information on Red Hat Ceph Storage, please visit this product page.
Sull'autore

Altri risultati simili a questo
Smetti di gestire il passato e inizia a costruire il futuro dell'IT
Potenziata, pronta e a costo zero: l’evoluzione della sicurezza dei container
Collaboration In Product Security | Compiler
Keeping Track Of Vulnerabilities With CVEs | Compiler
Ricerca per canale

Automazione
Novità sull'automazione IT di tecnologie, team e ambienti

Intelligenza artificiale
Aggiornamenti sulle piattaforme che consentono alle aziende di eseguire carichi di lavoro IA ovunque

Hybrid cloud open source
Scopri come affrontare il futuro in modo più agile grazie al cloud ibrido

Sicurezza
Le ultime novità sulle nostre soluzioni per ridurre i rischi nelle tecnologie e negli ambienti

Edge computing
Aggiornamenti sulle piattaforme che semplificano l'operatività edge

Infrastruttura
Le ultime novità sulla piattaforma Linux aziendale leader a livello mondiale

Applicazioni
Approfondimenti sulle nostre soluzioni alle sfide applicative più difficili
Virtualizzazione
Il futuro della virtualizzazione negli ambienti aziendali per i carichi di lavoro on premise o nel cloud