
As Red Hat OpenShift clusters scale to support hundreds of microservices, the sheer volume of telemetry data can become overwhelming. Platform architects often face a difficult paradox: Maintain visibility required for security and compliance while also managing rising storage costs and "noise" associated with high-volume infrastructure logs. In this article, I explore how to leverage the ClusterLogForwarder (CLF) API and Loki filters in Red Hat OpenShift to move from a "collect everything" model to a route-by-value strategy.
Infrastructure metadata and application insight
In a standard OpenShift deployment, the ingress controller (HAProxy) and various system operators generate a continuous stream of metadata. While these logs are essential for a security operations center (SOC), they are often noise to an application developer attempting to trace a logic error.
The diagram below illustrates the common "collect all" problem, where all logs are funneled into a single storage backend, leading to increased costs and performance issues.
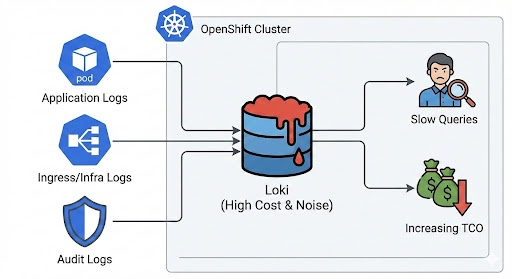
Storing high-volume, low-entropy logs (like 200 OK health checks) in high-performance storage leads to:
- Index bloat: Slower query response times due to massive cardinality
- Storage pressure: Reduced retention periods for critical application data
- Compliance risk: Difficulty in isolating sensitive audit trails
The logic of the ClusterLogForwarder
The CLF acts as a high-level abstraction over the underlying collector (Vector). It uses a declarative approach to define inputs, filters, outputs, and pipelines. The diagram below illustrates how the ClusterLogForwarder can fork a single log stream into multiple pipelines using selective filters, ensuring data reaches the correct destination without duplication.
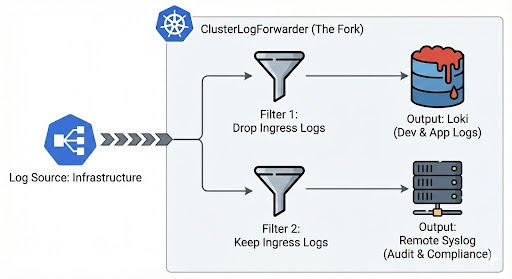
Strategic policy selection: Drop vs. keep
Before configuring your pipelines, it is crucial to understand the two primary logic gates provided by the ClusterLogForwarder API. Choosing between a drop or keep strategy depends on whether you are practicing exclusionary or inclusionary data governance.
The drop strategy (exclusionary)
The drop filter acts as a ban list. It allows all logs to pass through by default unless they match the specific criteria you define.
- "I want to see everything except the noise."
- Best for: Developer-facing pipelines (Loki). It helps ensure that as new applications are deployed to the cluster, their logs are collected automatically without manual configuration updates.
- Risk profile: Low. You are unlikely to miss important data, but you risk storage growth if a new, noisy application is deployed.
The keep strategy (inclusionary)
The keep filter acts as an allow list. It immediately discards all incoming logs unless they match your specific criteria.
- "Discard everything except the gold."
- Best for: Compliance and security pipelines (SIEM/audit). It helps to ensure that only strictly regulated data reaches sensitive backends, preventing log leakage of personally identifiable information (PII) from other namespaces.
- Risk profile: High. If a new audit source is added to the cluster, it's dropped by default until you explicitly update the filter.
Defining advanced selective filters
To take advantage of these methods, you must have:
- Red Hat OpenShift 4.16+ for advanced CLF filter support
- Red Hat OpenShift logging operator installed in the
openshift-loggingnamespace - A functional LokiStack or external Syslog/S3 destination
Filters are applied during the processing phase of the collector. We use the test array to match metadata fields. For Ingress logs, we specifically target the openshift-ingress namespace.
spec:
filters:
- name: exclude-ingress-from-loki
type: drop
drop:
- test:
- field: .kubernetes.namespace_name
matches: openshift-ingress
- name: isolate-audit-traffic
type: keep
keep:
- test:
- field: .log_type
matches: auditMulti-backend pipeline orchestration
The pipeline is where the routing occurs. By referencing different filterRefs, we can ensure that a single log source (like infrastructure) is processed differently depending on its destination.
pipelines:
- name: developer-loki-stream
inputRefs:
- application
- infrastructure
outputRefs:
- default-loki
filterRefs:
- exclude-ingress-from-loki
- name: security-compliance-stream
inputRefs:
- audit
- infrastructure
outputRefs:
- remote-syslog
filterRefs:
- isolate-audit-trafficUse case 1: Compliance-driven audit isolation
Problem: Audit logs (API server, OAuth, and so on) must be kept for 3 years, but application logs only for 7 days.
Solution: Split the stream. Audit logs are forked into low-cost S3 buckets.
Use case 2: Silencing system noise
Problem: Namespaces likeopenshift-monitoring generate logs that developers don't need.
Solution: Use the regex-based drop filter matches:openshift-monitoring|openshift-operators
Use case 3: Incident response "debug" throttling
Problem: A DEBUGlog storm during an incident can crash the logging backend.
Solution: Filter by severity:
name: filter-debug
type: drop
drop:
- test:
- field: .level
matches: debug|DEBUGValidation: Monitoring the data flow
After applying your configuration, verify the health of your pipelines. A Valid status indicates that the collector has successfully re-generated its internal Vector configuration.
oc get clusterlogforwarder instance -n openshift-logging -o yaml
To see the fork in action, compare the ingestion rates in Loki to the received logs in your Syslog server. You should see a marked decrease in Loki cardinality.
Strategic business outcomes
There are several potential benefits to this methodology.
- Cost control: Tiered storage reduces the cost per GB by offloading infra logs to cheaper sinks
- Risk mitigation: Ensures PII or sensitive audit data is isolated and encrypted
- Developer velocity: Faster queries (less data to scan) allow SREs to identify root causes faster
Data sovereignty in the hybrid cloud
Implementing a selective log routing strategy enables a tiered logging architecture that is both cost-effective and compliant. This final diagram illustrates the strategic "After" state, where different log types are routed to the most appropriate storage tier across a hybrid cloud environment.
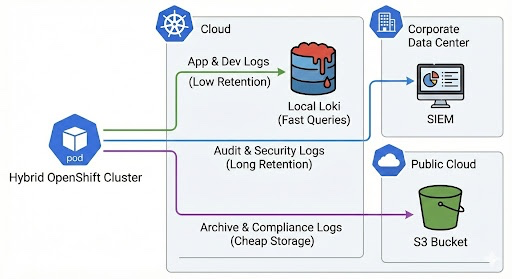
Architecture is the art of making intentional choices. By choosing where your logs land, you are managing the resilience and economics of your entire platform. Selective forwarding ensures that your logging infrastructure remains a tool for insight, rather than a burden of noise.
Prova prodotto
Red Hat OpenShift Container Platform | Versione di prova del prodotto
Sull'autore
Viral Gohel is a Senior Technical Account Manager at Red Hat. Specializing in Red Hat OpenShift, middleware, and application performance, he focuses on OpenShift optimization. With over 14 years at Red Hat, Viral has extensive experience in enhancing application performance and ensuring optimal OpenShift functionality.
Altri risultati simili a questo
Red Hat OpenShift 4.21: scalabilità più intelligente, migrazione più rapida ed efficienza basata sull'IA
Sfrutta al meglio Red Hat Enterprise Linux for AWS
Ricerca per canale

Automazione
Novità sull'automazione IT di tecnologie, team e ambienti

Intelligenza artificiale
Aggiornamenti sulle piattaforme che consentono alle aziende di eseguire carichi di lavoro IA ovunque

Hybrid cloud open source
Scopri come affrontare il futuro in modo più agile grazie al cloud ibrido

Sicurezza
Le ultime novità sulle nostre soluzioni per ridurre i rischi nelle tecnologie e negli ambienti

Edge computing
Aggiornamenti sulle piattaforme che semplificano l'operatività edge

Infrastruttura
Le ultime novità sulla piattaforma Linux aziendale leader a livello mondiale

Applicazioni
Approfondimenti sulle nostre soluzioni alle sfide applicative più difficili
Virtualizzazione
Il futuro della virtualizzazione negli ambienti aziendali per i carichi di lavoro on premise o nel cloud