
Having a grasp of common architectural patterns is essential to designing software architecture at scale. Using them saves not only time but also ensures a reliable implementation of your design. There’s no need to reinvent the wheel when there’s an architectural pattern available that applies to an architecture you’re developing.
The following is a brief overview of the Sharding architectural pattern.
Understanding the Sharding pattern
The Sharding pattern is when a datastore is separated from a single storage instance into multiple instances called shards. Data is then divided according to some form of sharing logic. Queries are executed against the shards. It’s up to the database technology implementing the shards to perform the queries in an optimized manner.
One type of sharding logic is when database administrators (DBAs) segment data according to values in a particular field in the database. An example of such separation is dividing data among the shards according to the first letters of the last name.
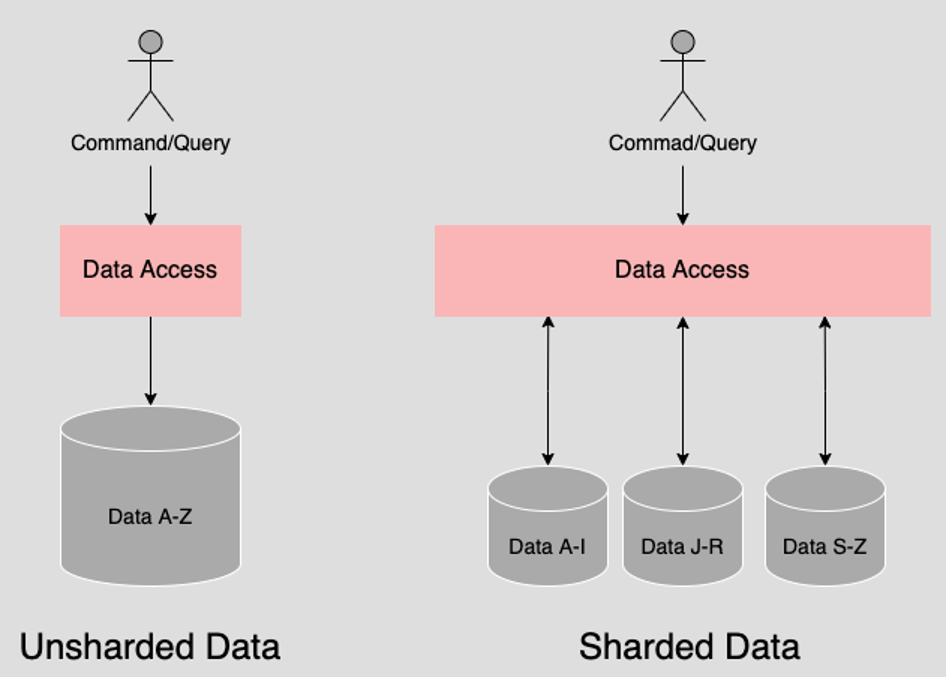
Another type of sharding separates data according to a segmentation logic that ensures that disk capacity is consumed equally among all instances.
Pros
- The sharding pattern is well suited for large, distributed enterprise applications.
- Sharding allows for the fast execution of a command or a query.
- Storage segmentation, which is a key feature of the sharding pattern, enables the physical infrastructure to scale in a controlled manner.
Cons
- The sharding pattern requires that DBAs have both specific domain expertise and experience with the best practices of the database technologies in play in order to manage the sharding segmentation effectively.
- Shards distributed over a large number of geolocations can be susceptible to performance degradation due to excessive network traffic.
- Some database technologies are better suited to the sharding pattern than others. Thus, you need to choose wisely.
- Added hardware means a higher total cost of ownership of the service.
Putting it all together
Separating data using the Sharding pattern is well suited to large distributed applications. Large enterprise applications depend on fast data access. Logically segmenting data according to a data table’s key or a database’s storage capabilities executes queries with a fine grain of precision. Searching for data according to shard is faster. Also, scaling becomes more efficient.
Sull'autore
Bob Reselman is a nationally known software developer, system architect, industry analyst, and technical writer/journalist. Over a career that spans 30 years, Bob has worked for companies such as Gateway, Cap Gemini, The Los Angeles Weekly, Edmunds.com and the Academy of Recording Arts and Sciences, to name a few. He has held roles with significant responsibility, including but not limited to, Platform Architect (Consumer) at Gateway, Principal Consultant with Cap Gemini and CTO at the international trade finance company, ItFex.
Altri risultati simili a questo
Red Hat Learning Subscription Course reinventa la formazione virtuale
Dietro le quinte di RHEL 10, parte terza
How Do We Mentor the Next Generation of IT Leaders? | Compiler
The Developer Advocate And The Exchange | Compiler: Re:Role
Ricerca per canale

Automazione
Novità sull'automazione IT di tecnologie, team e ambienti

Intelligenza artificiale
Aggiornamenti sulle piattaforme che consentono alle aziende di eseguire carichi di lavoro IA ovunque

Hybrid cloud open source
Scopri come affrontare il futuro in modo più agile grazie al cloud ibrido

Sicurezza
Le ultime novità sulle nostre soluzioni per ridurre i rischi nelle tecnologie e negli ambienti

Edge computing
Aggiornamenti sulle piattaforme che semplificano l'operatività edge

Infrastruttura
Le ultime novità sulla piattaforma Linux aziendale leader a livello mondiale

Applicazioni
Approfondimenti sulle nostre soluzioni alle sfide applicative più difficili
Virtualizzazione
Il futuro della virtualizzazione negli ambienti aziendali per i carichi di lavoro on premise o nel cloud