The promise of large language models (LLMs) is clear. From code generation to customer support, from document analysis to creative workflows, organizations everywhere are racing to integrate LLMs into their products and operations. The enterprise LLM market is projected to grow from $6 billion in 2025 to over $50 billion by 2035. But behind the excitement lies a practical challenge—serving LLMs in production can be expensive, inefficient, and operationally complex.
The production scale challenges
Inference cost is the real bill
There's a common misconception that training is where most of the money goes. In many production deployments we see, however, inference costs dominate infrastructure budgets. Training happens once (or occasionally); inference happens millions of times a day. Every inefficiency in the serving stack—idle GPU cycle, cold-start delay, over-provisioned instance—can compound into real dollars.
The hardware math can be challenging
A single enterprise-grade GPU can be astonishingly expensive. A more modest setup with consumer GPUs can also represent a significant investment. And most organizations don’t rely on just one model. They often need several: a coding assistant, a summarization model, a domain-specific fine-tune, perhaps a smaller model for simple classification tasks.
Under the traditional one-model-per-GPU paradigm, common in containerized or Kubernetes environments, each model typically receives a dedicated GPU. In practice, many of those GPUs remain underutilized much of the time.
An 8B parameter model might consume 20 GB of VRAM on a 80 GB GPU, leaving a substantial portion unused. Multiply that across teams experimenting with multiple models, and the unused capacity quickly becomes meaningful. For research teams, government agencies, and mid-sized enterprises in particular, this inefficiency can become a real constraint.
Static partitioning might not fit every use case
The industry has tried to address this. NVIDIA's Multi-Instance GPU (MIG) can carve a GPU into isolated slices. Fractional GPU approaches use time-slicing to share compute resources. Multi-Process Service (MPS) spatially partitions streaming multiprocessors.
While these are excellent solutions, they often share a common trait: they tend to be static (although some automation mechanisms allow modifying them). Adapting them to workloads that shift throughout the day isn’t always straightforward. When your coding assistant is busy during work hours but idle at night, and your batch-processing model needs resources in the opposite pattern, static partitions may leave performance on the table.
Exploring a different approach
If this sounds familiar, it’s because we’ve seen a similar evolution in CPU computing. For years, each application ran on its own dedicated server. Then virtualization emerged, followed by containers and orchestration, enabling more flexible and efficient resource sharing.
We believe GPU-based AI workloads may benefit from a comparable shift: moving from largely static, single-tenant GPU allocation toward more dynamic, multi-model sharing, backed by the operational tooling to make it manageable.
What if you could pack multiple models onto a single GPU or sets of GPUs, and dynamically share the available memory between them? Load and unload models without disrupting the ones already running? Route all inference requests through a single, unified endpoint? And do it all through a dashboard that gives you real-time visibility into what's happening on your hardware?
It may not fit every scenario. But in some contexts, this approach could make a meaningful difference.
Curious? Let’s take a closer look.
Another approach
Meeting kvcached…
That's the idea behind kvcached (pronounced “K-V cache D”), short for KV cache daemon, an open source library that brings a classic operating-system concept—virtual memory—to the world of LLM serving on GPUs.
During inference, each request dynamically grows its KV cache as tokens are generated and releases memory when the request finishes (assuming no prefix caching). As request arrival rates fluctuate over time, the total KV memory demand on the GPU continuously expands and contracts. However, today's serving engines (like vLLM or SGLang) typically reserve a large, fixed block of GPU memory at startup for KV cache storage. This static allocation ignores the dynamic nature of workloads: when traffic is low, large portions of GPU memory remain unused, while during bursts the system may run out of memory even though other models or idle capacity could have shared it.
kvcached addresses this problem by decoupling virtual memory allocation from GPU physical memory. Each model reserves a large virtual address range for its KV cache, but GPU physical memory pages are only allocated and mapped when the cache is actually written to. As requests complete or models become idle, those pages are returned to a shared memory pool that other models can use.
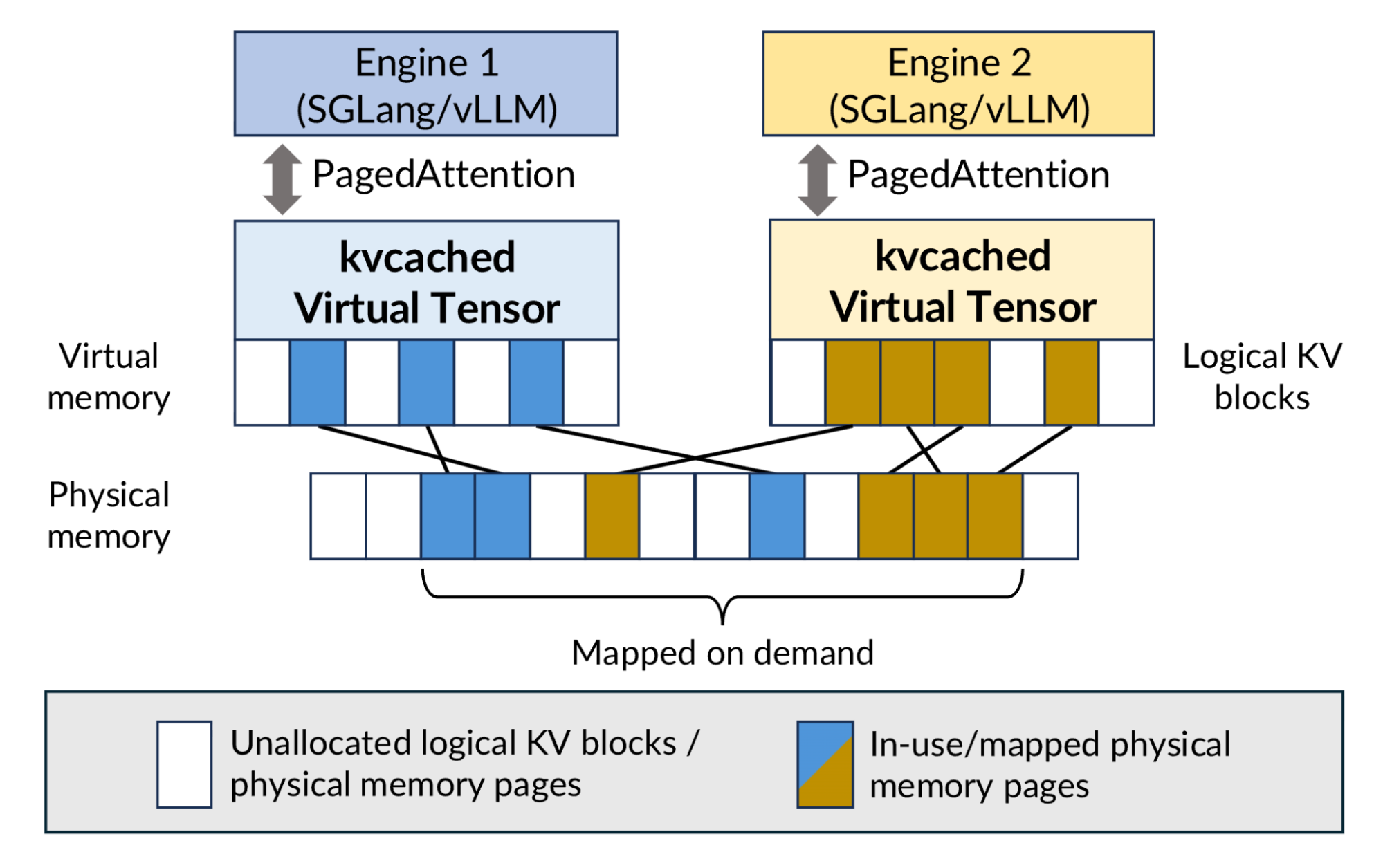
Figure 1: kvcached adopts an OS-style virtual memory design, enabling multiple serving engines to flexibly share GPU physical memory.
Even more interestingly, kvcached integrates transparently with existing serving engines. Install it alongside vLLM or SGLang, set a few environment variables, and GPU memory management becomes virtualized under the hood–no changes to the model or serving stack are required.
In benchmarks running three Llama-3.1-8B models on a single A100 under bursty traffic, kvcached achieved a more than 2x reduction in time-to-first-token (TTFT). This improvement directly translates into higher GPU utilization and fewer GPUs needed to meet the same performance targets.
… and its companion project, Sardeenz
Memory sharing alone doesn't give you a production-ready platform. Someone still needs to decide which models to load, when to load them, where to put them, and how to route traffic once they're running. That's the gap the project Sardeenz aims to fill.
Think of kvcached as the kernel-level primitive—it handles the low-level mechanics of GPU memory sharing between processes. Sardeenz sits above it, providing the operational layer: a control plane for dynamically managing multiple LLMs across one or more GPUs.
At its core, Sardeenz is a relatively straightforward idea:
- Load and unload models on the fly, without disrupting the ones already serving traffic.
- Route all inference requests through a single endpoint, so downstream applications don't need to know which port or process is handling their model.
- See what's happening through a web dashboard, rather than juggling terminal sessions and log files.
None of these ideas are revolutionary on their own. But putting them together in a cohesive, easy-to-deploy package turns out to be useful in ways we didn't fully anticipate when we started building it.
How it works in practice
Let's walk through a typical scenario. You have a server with one or two GPUs, and your team needs access to 3 models: a general-purpose chat model, a code assistant, and a smaller summarization model.
With Sardeenz, you can open the dashboard, point it at the model repositories (local paths or HuggingFace IDs), and load each one. The system checks available GPU memory, suggests GPU assignments, and starts spinning up vLLM instances behind the scene. You can watch the loading progress in real time–including any errors that come up–through a live log stream in the UI.
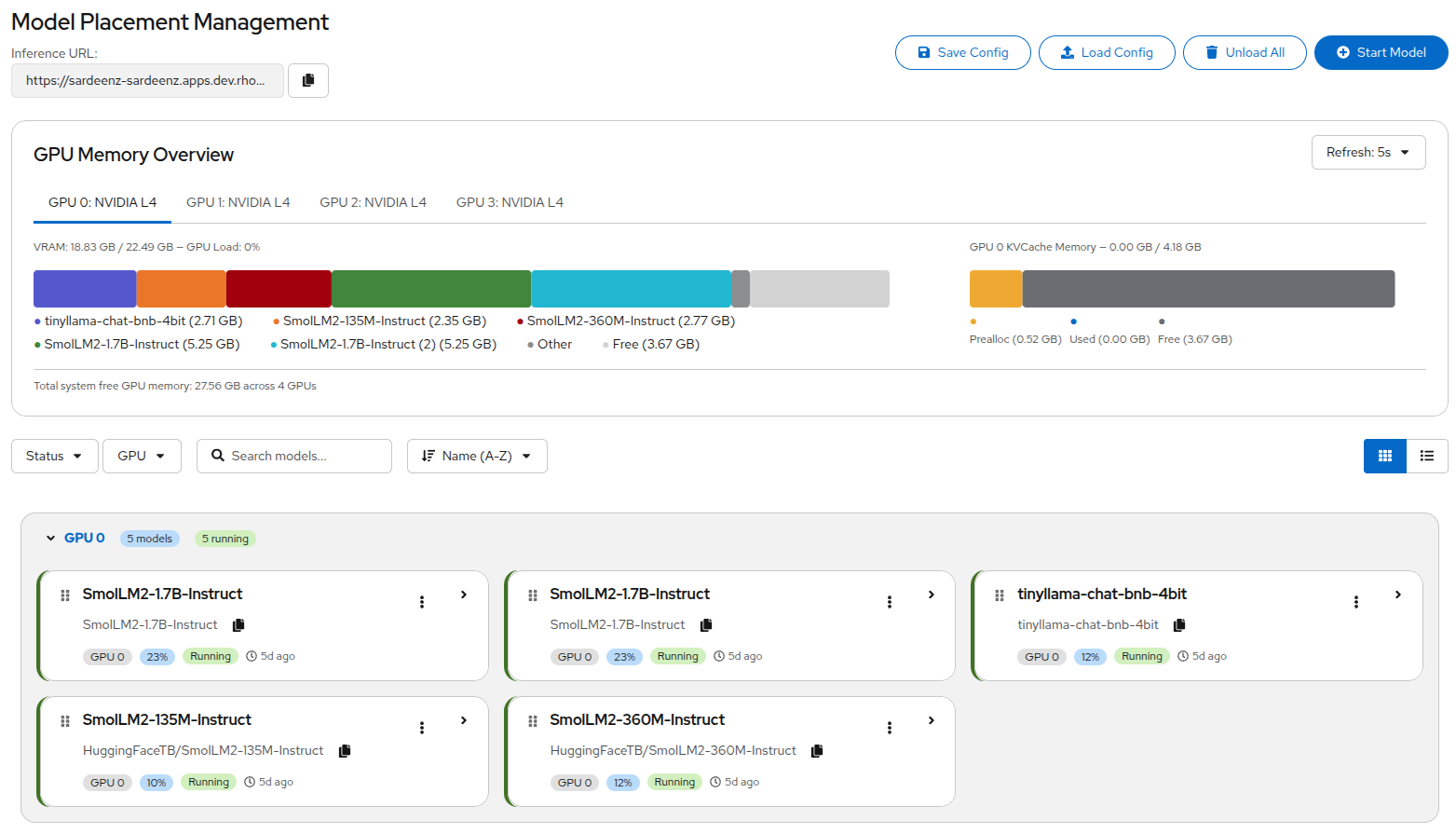
Figure 2: The main Sardeenz dashboard.
Once loaded, all 3 models are accessible through a single OpenAI-compatible API endpoint. Your applications send requests to the same URL, specifying the model name in the request body, and Sardeenz routes the traffic to the right backend process.
When the coding team goes home for the evening and the batch-processing workload picks up, you can unload the code assistant and reclaim that GPU memory for a larger model, or simply let the remaining models benefit from the freed-up KV cache space. In the morning, load it back. No restarts, no redeployments, no YAML editing.
A few things worth highlighting
Memory visibility. The dashboard provides a practical view of GPU memory usage, broken down by model, including real-time KV cache allocation. A memory profiler allows you to check if a model will fit before loading it, which is essential for maximizing usage on limited hardware.
Benchmarking built-in. Sardeenz includes a suite to measure time-to-first-token, tokens-per-second, and end-to-end latency. You can test performance in isolation or under contention, simulating shared hardware scenarios. Results are persistently stored for performance comparison over time or across configurations.
Blue-Green model migration. Safely move models between GPUs (e.g., for rebalancing or maintenance) using a blue-green deployment process. The system loads the model on the target GPU, switches routing, drains requests from the old instance, and unloads it. If the target load fails, the original instance keeps serving traffic.
Configuration presets. Save working model configurations (e.g., specific models on specific GPUs with token limits) as named presets. Restoring a configuration is a single action. The system manages load sequencing, loading models on shared GPUs sequentially and those on separate GPUs in parallel.
Sleep mode. To manage memory pressure without fully unloading models, Sardeenz utilizes vLLM's sleep mode, offloading model weights from GPU memory to system RAM. A sleeping model frees up to 90% of its GPU footprint, and waking it up is significantly faster than a cold load from disk. This feature is accessible via both API and the dashboard.
Deployment: one container, one port
We've tried to keep the deployment story simple. Sardeenz ships as a single container image. The Fastify backend serves the API, the inference proxy, and the frontend dashboard–all on a single port. There's no separate NGINX, no sidecar containers, no multiservice orchestration to set up.
For Kubernetes and Red Hat OpenShift environments, it supports standard health probes, Prometheus metrics, and persistent storage for its SQLite database. Authentication is flexible: you can run with no auth for development, simple username/password for smaller deployments, or full OAuth with Kubernetes role-based access control (RBAC) integration for more advanced environments. Inference endpoints can be independently secured with API keys, keeping the admin and inference authentication concerns separate.
The goal was to make it something a platform engineer could deploy in an afternoon.
What it isn't
It's worth being clear about what Sardeenz is not trying to be:
- It's not a replacement for large-scale inference platforms. If you're serving thousands of concurrent users across dozens of GPUs, you likely need purpose-built infrastructure with more sophisticated scheduling, autoscaling, and multinode orchestration.
- It's not doing anything magical with the GPU itself. The multimodel memory sharing is handled by kvcached at the system level. Sardeenz orchestrates and manages the models on top of that.
- It's currently single-node. It manages the GPUs on one server. Multinode federation is something we're thinking about, but it's not there today.
We think there's a meaningful niche for teams that have a handful of GPUs and a handful of models, and want to use both more efficiently without building a custom platform from scratch.
Whether that describes your situation is something only you can judge—but if it does, Sardeenz might be worth a look.
Where this fits and where to go from here
We've covered a lot of ground. The cost and complexity of serving multiple LLMs in production, how kvcached enables GPU memory sharing at the system level, and how Sardeenz provides the operational layer to manage it all. Let's bring it together with some concrete scenarios where this approach might be a good fit—and a few where you should probably look for other solutions.
Scenarios we had in mind
The research lab with one or two GPUs. A university team or a small R&D group has a couple of NVIDIA GPUs and needs to experiment with several models—comparing a fine-tuned domain model against a general-purpose one, testing different model sizes, iterating on prompts. Under the traditional approach, they'd either swap models manually (slow, disruptive) or limit themselves to whatever fits on one GPU at a time. With kvcached and Sardeenz, they could keep 2 or 3 models loaded simultaneously, benchmark them side by side, and swap configurations as experiments evolve. Not a game-changer for everyone, but for a resource-constrained team, it can meaningfully reduce friction.
The internal AI platform serving multiple teams. A mid-sized company wants to offer LLM capabilities to several internal teams: engineering gets a code assistant, customer support gets a conversational model, the legal team gets a document analysis model. Provisioning a dedicated GPU for each is expensive and, in practice, most of these models sit idle much of the time. Running them on shared hardware with a unified API endpoint simplifies both the infrastructure and the developer experience. Each team hits the same URL, specifies their model, and doesn't need to care about what's running underneath. When usage patterns shift—the code assistant is quiet over the weekend, the batch-processing model ramps up—the platform engineer can adjust without redeploying anything.
Edge and on-premise deployments. Government agencies, healthcare organizations, financial institutions—environments where data can't leave the premises and cloud APIs aren't an option. These deployments often have a fixed hardware budget that needs to stretch across multiple use cases. Being able to run several models on limited local hardware, with a simple deployment footprint (1 container, 1 port), can make the difference between a viable project and one that stalls at the procurement stage.
Development and staging environments. Even teams that run large-scale inference infrastructure in production often need lighter-weight environments for development and testing. Rather than replicating the full production stack, a single Sardeenz instance can host the models developers need for integration testing, prompt engineering, or demo environments—at a fraction of the cost.
When to look elsewhere
This approach works best for small-to-medium scale deployments where you're managing a handful of models across a handful of GPUs. If your needs look more like:
- High-throughput, single-model serving at scale: you're probably better served by dedicated inference infrastructure optimized for that workload.
- Multinode GPU clusters with dozens of machines: orchestration at that scale calls for different tooling.
- Latency-critical applications where even the overhead of a routing proxy is a concern: direct model access will always be faster.
We're not suggesting kvcached with Sardeenz replaces those solutions. It occupies a different spot in the landscape.
Getting started
Both projects are open source and available today:
- kvcached enables the GPU memory sharing that makes multimodel hosting practical. If you're already running vLLM and want to experiment with packing more models onto your existing hardware, kvcached is the place to start. https://github.com/ovg-project/kvcached
- Sardeenz adds the management layer on top: dynamic model loading, unified proxy, dashboard, benchmarking, and deployment tooling. If you want the full operational experience, the container image is the quickest path. https://github.com/rh-aiservices-bu/sardeenz
You don't need both—kvcached works independently if you prefer to manage vLLM instances yourself, and Sardeenz can run without kvcached if memory sharing isn't a requirement for your setup (though you'll be more limited in how many models you can pack onto a single GPU). But together, they're designed to complement each other.
What's next
Both kvcached and Sardeenz are evolving projects. There are rough edges, features we haven't built yet, and assumptions that may not hold for every use case. Some of the things on our radar:
- Autoscaling: Dynamically loading and unloading models based on request patterns, rather than manual intervention.
- LoRA adapter support: Hot-swapping fine-tuned adapters without reloading the base model.
- Request queueing and prioritization: Smarter handling of traffic when GPU resources are contended.
- Multi-node awareness: Extending beyond single-server deployments.
We're building this in the open because we think the problem is real and the community's input makes the solution better. If any of the scenarios above sound like yours, we'd welcome you to try it out, tell us what works, and, perhaps more importantly, tell us what doesn't.
As a final word, here is an interactive experience of Sardeenz.
Sugli autori

Guillaume Moutier is a Senior Principal Consultant at Red Hat, specializing in AI/ML platforms, data services, and complex infrastructure solutions. With over 25 years of experience across IT architecture, software engineering, and large-scale systems design, he combines deep technical expertise with a pragmatic, business-aligned approach.
Guillaume’s career spans roles as Project Manager, Director of Architecture, and CTO for major institutions, where he led cross-functional teams and managed enterprise-grade infrastructure, DevOps pipelines, and AI platforms. His background gives him a strategic perspective on how to align technology with organizational goals.
He is a recognized speaker at industry events including Red Hat Summit, KubeCon, Cephalocon, and ODSC, and is the creator of multiple widely adopted AI demos and learning resources. Outside of tech, Guillaume is a multi-instrumentalist musician, gamer, and avid reader.

Altri risultati simili a questo
The zero touch future: Enabling Telstra’s path to a fully autonomous, self-healing network
From RAG to agentic AI: When models stop answering and start acting
Technically Speaking | Build a production-ready AI toolbox
Technically Speaking | Platform engineering for AI agents
Ricerca per canale

Automazione
Novità sull'automazione IT di tecnologie, team e ambienti

Intelligenza artificiale
Aggiornamenti sulle piattaforme che consentono alle aziende di eseguire carichi di lavoro IA ovunque

Hybrid cloud open source
Scopri come affrontare il futuro in modo più agile grazie al cloud ibrido

Sicurezza
Le ultime novità sulle nostre soluzioni per ridurre i rischi nelle tecnologie e negli ambienti

Edge computing
Aggiornamenti sulle piattaforme che semplificano l'operatività edge

Infrastruttura
Le ultime novità sulla piattaforma Linux aziendale leader a livello mondiale

Applicazioni
Approfondimenti sulle nostre soluzioni alle sfide applicative più difficili
Virtualizzazione
Il futuro della virtualizzazione negli ambienti aziendali per i carichi di lavoro on premise o nel cloud