Questo articolo illustra in dettaglio le iniziative di progettazione di Red Hat per supportare l'esecuzione di Oracle Database 19c a istanza singola su Red Hat OpenShift Virtualization. Fornisce un'architettura di riferimento completa, i risultati della convalida relativi a funzionalità, prestazioni, scalabilità e migrazione in tempo reale, oltre a collegamenti agli artefatti di test disponibili su GitHub.
Nell'articolo si dimostra come OpenShift Virtualization offra prestazioni solide per carichi di lavoro di produzione impegnativi (come i database Oracle), fornendo una valida alternativa alla virtualizzazione senza compromettere le prestazioni. L'articolo è destinato, in particolare, a leader tecnologici, architetti, team di ingegneria e responsabili di progetto coinvolti nella valutazione e nell'adozione di Oracle Database a istanza singola su OpenShift Virtualization.
I principi di progettazione dell'architettura si concentrano sull'allocazione delle risorse, sul partizionamento e sull'ottimizzazione dei livelli di astrazione per l'elaborazione, la rete e lo storage. I test delle prestazioni eseguiti utilizzando HammerDB con il benchmark TPC-C dimostrano che Oracle Database può essere eseguito correttamente su OpenShift Virtualization con storage NVMe locale, con prestazioni migliori rispetto a Red Hat OpenShift Data Foundation. Questo articolo evidenzia anche le funzionalità di osservabilità e monitoraggio, utilizzando Prometheus e Grafana per ottenere informazioni specifiche sull'infrastruttura e su Oracle.
Contesto
Molti clienti sono alla ricerca di alternative alla virtualizzazione che non compromettano le prestazioni. OpenShift Virtualization offre prestazioni affidabili per i carichi di lavoro di produzione più impegnativi, inclusi i database aziendali.
Uno dei componenti più comuni nelle architetture software tradizionali è Oracle Database. Per supportare i clienti interessati alla valutazione e all'adozione di Oracle Database on OpenShift Virtualization, Red Hat mette a disposizione risorse di ingegneria dedicate per offrire un'esperienza ottimizzata per l'utilizzo di Oracle Database on OpenShift Virtualization.
Questo articolo presuppone che i lettori abbiano familiarità con Red Hat OpenShift Container Platform. Non intendiamo parlare dell'architettura generica di Oracle Database, né dell'ottimizzazione delle prestazioni. Illustreremo invece le opzioni architetturali per l'impostazione e la configurazione di OpenShift Virtualization per consentire a Oracle Database di ottenere le prestazioni migliori.
Questo articolo è destinato ai seguenti professionisti coinvolti nelle attività di valutazione, convalida e decisione sull'adozione di Oracle Database a istanza singola su OpenShift Virtualization:
- Leader tecnologici (ad esempio, VP e CTO): stakeholder responsabili dell'ottimizzazione del ritorno sugli investimenti (ROI) e del costo totale di proprietà (TCO) delle operazioni quotidiane legate all'esecuzione dei carichi di lavoro di Oracle Database in ambienti di cloud ibrido o on premise.
- Architetti: gli architetti del cliente possono esaminare l'architettura di riferimento e i risultati dei test per valutare se OpenShift Virtualization è la piattaforma adatta per l'hosting dei carichi di lavoro di Oracle Database per la propria organizzazione. Questo articolo illustra i requisiti architetturali e consente agli architetti di eseguire convalide indipendenti.
- Team di ingegneria: i team di ingegneria possono sfruttare i test delle prestazioni utilizzati da Red Hat durante questa valutazione, insieme agli artefatti riutilizzabili disponibili su GitHub, per accelerare la configurazione e l'automazione dei test, semplificando il processo di convalida.
- Responsabili di progetto: i responsabili di progetto possono utilizzare le architetture di riferimento per identificare i componenti interessati e i team responsabili. Possono anche utilizzare i test standardizzati.
Panoramica dell'architettura di OpenShift Virtualization
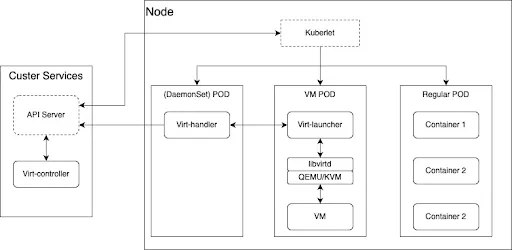
OpenShift Virtualization è l'implementazione Red Hat del progetto open source KubeVirt, ed è basata sulla piattaforma OpenShift standard. Una macchina virtuale (VM) viene eseguita all'interno di un pod containerizzato; OpenShift Container Platform gestisce le VM come gestisce qualsiasi pod, ovvero un'istanza di VM accede agli stessi servizi della piattaforma, inclusi sicurezza, rete e storage, come una normale applicazione containerizzata. L'unica differenza è che la VM viene gestita direttamente a livello di pod, a differenza delle normali applicazioni per carichi di lavoro eseguite all'interno dei container.
Componenti dell'architettura:
- Kernel-based Virtual Machine (KVM): l'hypervisor della VM su OpenShift fa parte del kernel Linux.
- Istanza di macchina virtuale (VMI): ogni VM rappresentata da una VMI viene creata da QEMU utilizzando KVM per emulare l'hardware; QEMU crea l'isolamento a livello di spazio utente.
- KubeVirt: componente aggiuntivo di Kubernetes per gestire le VM come risorse Kubernetes, rendendole simili a un pod.
virt-operator:gestisce l'installazione e gli aggiornamenti dei componenti KubeVirt.virt-controller:si occupa della gestione del ciclo di vita delle VM (ad esempio, riavvio in caso di errore, scalabilità).virt-handler:un daemon su un nodo abilitato KubeVirt per gestire le VM sugli host utilizzando KVM/QEMU.virt-launcher:uno per ogni pod VM, funge da agente di orchestrazione che gestisce il processo della macchina virtuale QEMU/KVM all'interno del pod.- Risorse personalizzate (Custom Resources, CM): rappresenta la definizione di una VM, l'esecuzione di un'istanza di VM e la pianificazione/le policy.
- Wrapper del pod funge da wrapper per il processo QEMU. La VMI viene eseguita all'interno del pod come sistema operativo guest virtualizzato.
- Storage: OpenShift Virtualization supporta un'ampia gamma di soluzioni di storage, tra cui numerose opzioni Kubernetes native come OpenShift Data Foundation, Portworx e soluzioni enterprise più tradizionali come iSCSI, storage Fibre Channel (FC) SAN e altre. OpenShift Data Foundation è la soluzione di storage Kubernetes native basata sul progetto open source Ceph; offre uno storage scalabile e ridondante con un livello di astrazione ottimizzato per gli ambienti Kubernetes. OpenShift Data Foundation supporta anche il provisioning dinamico dei volumi permanenti (PV) e delle richieste di volumi permanenti (PVC), semplificando la gestione dello storage.
Per questo progetto di convalida di Oracle Database, prenderemo in considerazione diverse alternative di storage. Tuttavia, questo documento si incentra su OpenShift Data Foundation, grazie alla sua perfetta integrazione con Kubernetes. Quando si distribuiscono i carichi di lavoro di Oracle Database, è importante valutare e selezionare la soluzione di storage che meglio soddisfa i requisiti prestazionali e operativi.
Rete: le VM accedono alla rete tramite Multus (meta plugin CNI) o Single Root I/O Virtualization (SR-IOV), dove Multus è definito a livello di pod.

Principi di progettazione di Oracle Database
Quando un database Oracle viene eseguito su un sistema operativo virtuale, la VM ha il compito di garantire che il database riceva risorse di sistema adeguate per funzionare in modo efficiente e rimanere resiliente. Poiché le risorse dell'infrastruttura reale sono limitate, l'architettura dell'infrastruttura deve essere progettata con attenzione per bilanciare l'allocazione delle risorse e soddisfare le esigenze variabili dei diversi carichi di lavoro.
Un approccio architetturale comune per migliorare le prestazioni di Oracle Database a livello di infrastruttura tiene conto dei seguenti principi:
- Posizione delle risorse: alloca risorse sufficienti in termini di elaborazione, storage e rete per eliminare gli ostacoli.
- Partizionamento delle risorse: quando le risorse sono limitate, è possibile suddividere i rispettivi requisiti e implementare soluzioni su misura per soddisfare esigenze specifiche.
- Ottimizzazione dei livelli di astrazione:evita i livelli di astrazione non necessari o di basso valore, in cambio della flessibilità e del miglioramento delle prestazioni.
Oracle Database si basa principalmente su tre tipi di risorse di sistema:
- Elaborazione: include vCPU, IOThread, memoria e la scalabilità tra i nodi.
- Rete: Oracle Database è altamente sensibile alle prestazioni di I/O. L'accesso al client e allo storage hanno requisiti di throughput e latenza distinti. Di conseguenza, le architetture di Oracle Database utilizzano spesso reti separate per i diversi tipi di traffico.
- Storage: redolog, tabelle dei database e backup hanno esigenze di lettura/scrittura diverse. Quando possibile, è consigliabile collocarli in uno storage fisico separato per garantire prestazioni di I/O ottimali.
OpenShift Virtualization offre le funzionalità e la flessibilità necessarie per supportare vari approcci all'allocazione delle risorse in base alle esigenze di partizionamento delle risorse di sistema.
Architettura di riferimento
Questo paragrafo esamina l'architettura in relazione alle possibili soluzioni per la progettazione di Oracle Database on OpenShift Virtualization.
Elaborazione
Assicurati che Oracle Database disponga di risorse di elaborazione sufficienti e che siano controllabili direttamente dalla piattaforma OpenShift Virtualization:
- Configurazione dell'allocazione di vCPU e RAM per la scalabilità verticale delle risorse.
- Estendibilità del cluster OpenShift Virtualization per la scalabilità orizzontale.
- Controllo dell'allocazione del numero di thread di I/O delle VM per eliminare gli ostacoli di I/O a livello di pod.
- Evitare il sovraccarico delle risorse per le macchine virtuali che ospitano i carichi di lavoro di Oracle Database allocando più CPU o memoria virtualizzate rispetto alle risorse fisiche presenti nel sistema.
Rete
Il traffico di Oracle Database ha requisiti prestazionali diversi in termini di latenza di rete, throughput e affidabilità. Il pod Multus di OpenShift Container Platform è una funzionalità per la partizione del traffico di rete e la mediazione tra più protocolli di rete. Considera quanto segue:
- L'implementazione di percorsi di rete diversi per SDN OpenShift, storage e macchine virtuali.
- Per le installazioni di Oracle RAC Database, è necessario isolare ulteriormente il traffico di rete per la comunicazione di interconnessione da istanza a istanza RAC e la comunicazione sulla rete "pubblica".
- Per i carichi di lavoro di importanza critica sensibili alla latenza e al throughput, valuta la possibilità di sfruttare SR-IOV per le interfacce di rete virtuali, creando un percorso diretto dalla VM alle risorse fisiche sottostanti.
Storage
Come accennato in precedenza, OpenShift Virtualization supporta un'ampia gamma di soluzioni di storage, dalle opzioni Kubernetes native come OpenShift Data Foundation e Portworx ai sistemi aziendali tradizionali come iSCSI e Fibre Channel (FC) SAN. Questa flessibilità consente agli utenti di scegliere lo storage più adatto alle proprie esigenze prestazionali e operative.
Sebbene non esistano regole universali per la selezione dell'opzione di storage appropriata, i seguenti principi possono essere utilizzati come linee guida:
- Equilibrio tra esigenze di flessibilità operativa (facilità di provisioning, integrazione con la piattaforma) e i requisiti prestazionali (latenza di I/O, throughput).
- Supporto per l'opzione di scrittura multipla (volume condiviso tra due o più VM) potenzialmente necessaria per Oracle RAC Database.
Configurazione hardware
La progettazione dei test delle prestazioni iniziali è stata applicata a un insieme di risorse hardware attualmente disponibili.
Specifiche del cluster:
- 4 server Dell R660
- 128 thread CPU (2 socket di Intel Xeon Gold 6430)
- 256 GB di memoria
- Disco di root da 1 TB
- 4 unità NVME da 1,5 TB
- 4 NIC Broadcom da 25 Gbps
- 2 NIC Intel 810 da 25 Gbps
Configurazione di OpenShift Virtualization
Sebbene la configurazione predefinita per lo storage di OpenShift Virtualization e OpenShift Data Foundation offra prestazioni ragionevoli, sono state apportate ulteriori modifiche alla configurazione per ottimizzare la piattaforma di test per i carichi di lavoro ad alta intensità di I/O tipici dei database:
- Configurazione di OpenShift Data Foundation per l'utilizzo di un profilo delle prestazioni.
- Configurazione di OpenShift Data Foundation e OpenShift Virtualization per separare il traffico dello storage di OpenShift Data Foundation dal traffico generico della rete SDN di OpenShift Container Platform. (Capitolo 8. Requisiti di rete | Pianificazione del deployment | Red Hat OpenShift Data Foundation | 4.18)
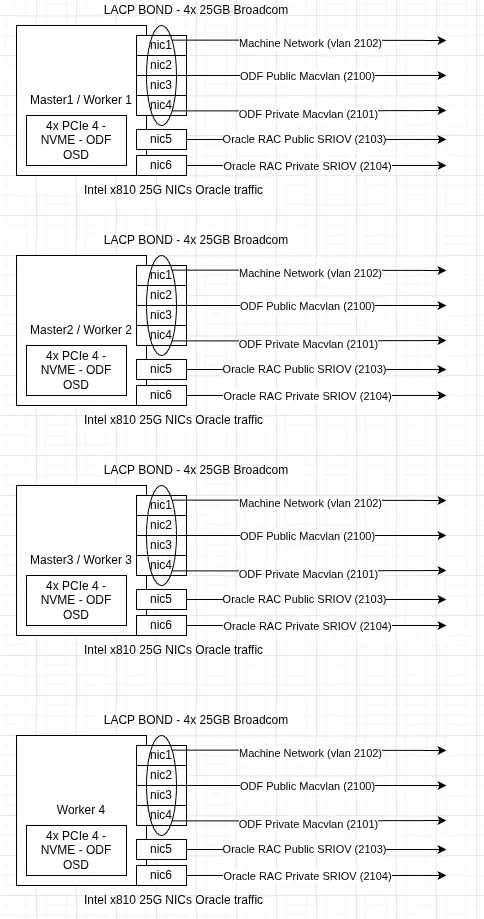
- Separazione del traffico per le macchine virtuali (Oracle Database e test harness di HammerDB) dallo storage OpenShift Data Foundation e dalla SDN di OpenShift Container Platform utilizzando interfacce di rete fisiche separate. Per ridurre la latenza e aumentare il throughput, le interfacce di rete sono state introdotte nelle macchine virtuali interessate tramite Single Root I/O Virtualization (SR-IOV) (figura 2).
Specifiche del cluster:
- Versione di OpenShift: 4.18.9
- OpenShift Virtualization: abilitato tramite OperatorHub
- Nodi:
- 3 nodi ibridi (nodi del piano di controllo / di lavoro / di storage)
- 1 nodo di lavoro
- Rete (specifica per le VM di Oracle Database):
- Collegamento LACP con 4 NIC Broadcom da 25 Gbps partizionate per separare la SDN di OpenShift, il client di storage di OpenShift Data Foundation e il traffico di replica dello storage di OpenShift Data Foundation.
- Due NIC Intel x810 da 25 GB per il traffico delle macchine virtuali con due diverse sottoreti (pubblica e privata) configurate per essere presentate alle macchine virtuali tramite SR-IOV.
- Storage (specifico per le VM Oracle Database): storage OpenShift Data Foundation (supportato da 4 unità NVMe da 1,5 TB) configurato con un profilo delle prestazioni e che utilizza una rete di storage separata.

Configurazione di Oracle Database
La macchina virtuale che ospita Oracle Database ha dimensioni contenute per evitare un impegno eccessivo delle risorse e per confrontare i risultati dei test su diverse opzioni hardware. Oracle Database non è specificamente ottimizzato per il test Transaction Processing Performance Council Benchmark C (TPC-C) e utilizza in gran parte una configurazione predefinita, ad eccezione delle poche modifiche di ottimizzazione comuni basate sulle procedure consigliate.
Abbiamo selezionato i parametri di ottimizzazione in base alle dimensioni della macchina virtuale, alle specifiche del carico di lavoro di test del benchmark e alle informazioni di monitoraggio. Abbiamo valutato l'efficacia di ogni modifica confrontando i risultati dei test con i valori di riferimento. La configurazione di Oracle Database può essere ulteriormente ottimizzata seguendo la guida all'ottimizzazione delle prestazioni del database.
La figura 3 mostra che Oracle Database e l'accesso al client HammerDB si trovano sulla stessa rete. I volumi di dati per le macchine virtuali sono configurati in modo da allocare preventivamente lo spazio su disco per migliorare le operazioni di scrittura.
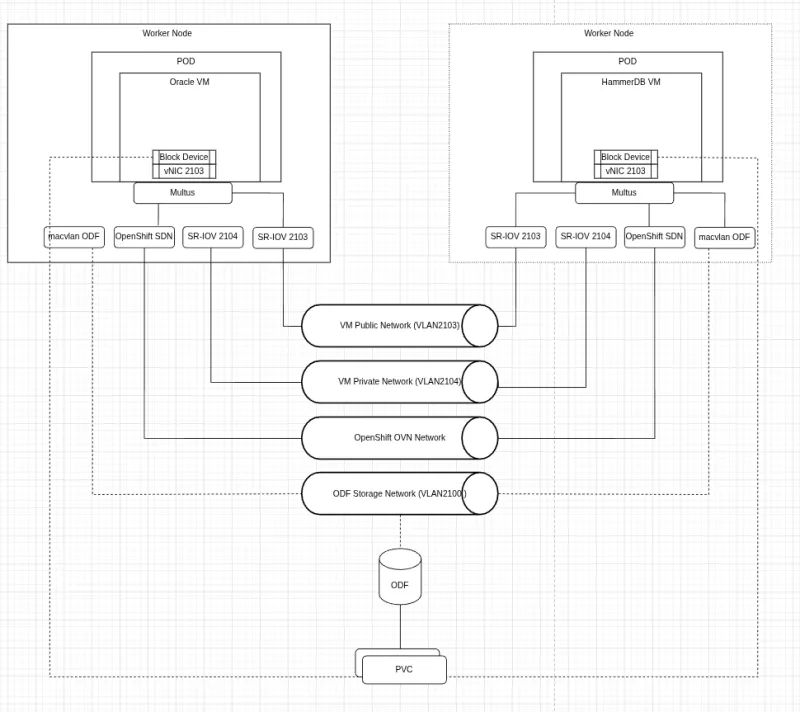
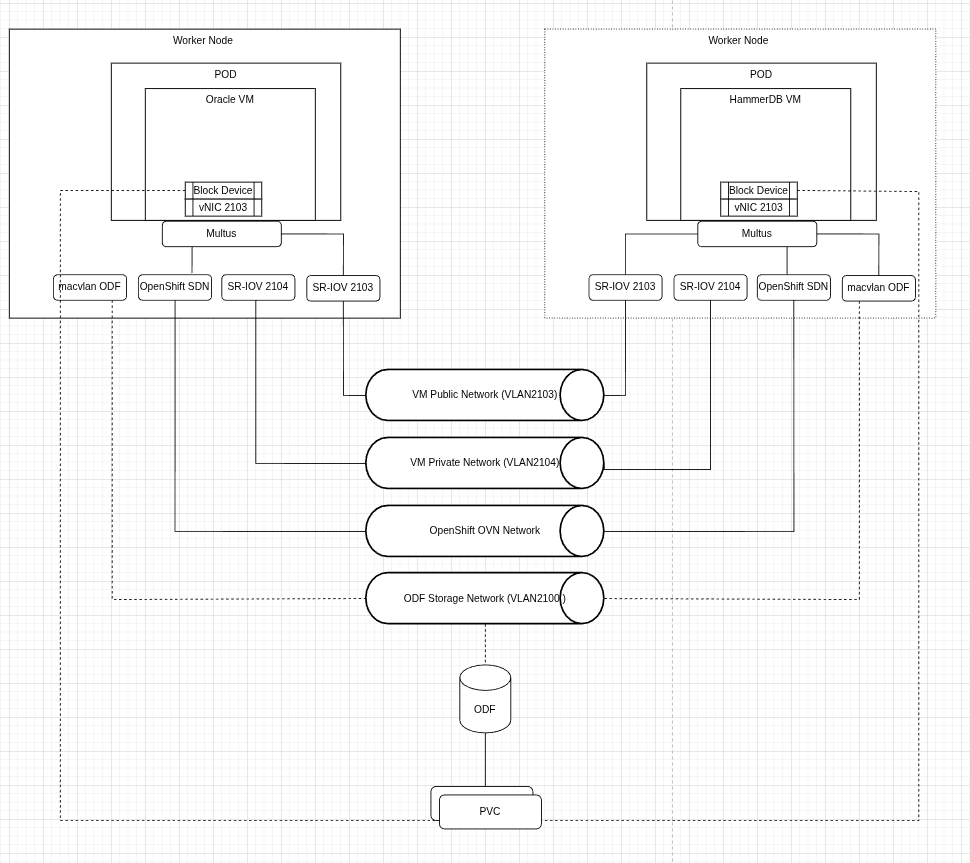
Abbiamo eseguito test ad hoc separati per valutare l'impatto dello storage sulle prestazioni del database aggiungendo lo storage NVMe tramite un operatore di storage locale.
Specifiche della macchina virtuale:
- SISTEMA OPERATIVO: RHEL 8.10
- Numero di VM: 1
- vCPU: 16
- Memoria: 48 GB
- Storage: 250 GB (dati root e database che risiedono sullo stesso volume) come dispositivo a blocchi da RH ODF
- DataVolume: creato utilizzando "preallocation: true" (thick provisioning).
- Rete: connessione a una sottorete pubblica tramite SR-IOV.
Configurazione di una istanza singola di Oracle Database:
Versione di Oracle Database: 19c Enterprise Edition con Release Update 26 (versione 19.26)
- Il database configurato con un file system come destinazione per i file di dati (volume root con storage supportato da OpenShift Data Foundation) tramite OMF (Oracle Managed Files).
- Per garantire la compatibilità del test con le versioni future di Oracle Database, il database è stato creato utilizzando l'architettura Container Database (CDB).
- L'allocazione della memoria ha utilizzato una memoria totale di 32 GB come input per la creazione guidata del database (consentendo all'installazione di Oracle Database di valutare automaticamente la suddivisione SGA/PGA).
- Parametri di ottimizzazione aggiuntivi:
- 4 file di dati estesi manualmente a 32 GB
- Dimensioni del redolog regolate a 4 GB
- 4 gruppi di dischi del redolog
- FILESYSTEMIO_OPTIONS: SETALL (che consente I/O asincrono e I/O diretto)
- USE_LARGE_PAGES: AUTO (per ottimizzare l'utilizzo della CPU in caso di SGA di grandi dimensioni)
Nota: per i test delle prestazioni con lo storage supportato da NVME, è stato montato un file system separato utilizzando il dispositivo NVME, assegnato come destinazione per i file di dati.
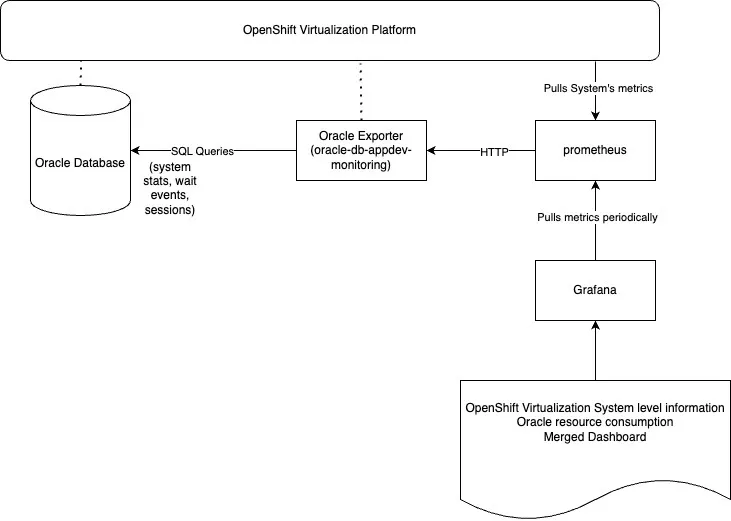
Osservabilità e monitoraggio
OpenShift offre una piattaforma di osservabilità efficiente e integrata che consolida il monitoraggio a livello di infrastruttura e applicazione. Supporta in modo nativo la raccolta di metriche, la registrazione e gli avvisi e può essere esteso per acquisire i dati di osservabilità da applicazioni esterne come i database Oracle. Questo approccio unificato riduce la complessità operativa e garantisce la visibilità end to end.
Observability for OpenShift Virtualization è perfettamente integrato nella stessa piattaforma e consente di monitorare le macchine virtuali, le risorse di sistema e i carichi di lavoro (ad esempio i database Oracle all'interno di un unico stack di monitoraggio coerente).
Oracle Database Observability Exporter, distribuito con OpenShift, raccoglie le metriche e i metadati delle prestazioni di Oracle Database, che sono esposti a Prometheus. Grafana visualizza queste metriche e fornisce dashboard in tempo reale per rilevare schemi anomali, risorse sotto pressione e problemi di prestazioni a livello di Oracle Database e VM.
Per migliorare l'analisi a livello del database, puoi utilizzare HammerDB durante i test delle prestazioni per acquisire snapshot e generare report AWR (Automatic Workload Repository). Combinati con le metriche di Prometheus e Grafana, questi report permettono di comprendere in modo più approfondito e multidimensionale il comportamento dei carichi di lavoro e dei potenziali ostacoli.
Oracle Database Enterprise Manager è uno strumento complementare che offre funzionalità di diagnostica dettagliate e monitoraggio specializzato per i database Oracle. Utilizzato insieme alla piattaforma di osservabilità unificata di OpenShift, garantisce una copertura completa per ottenere informazioni operative specifiche sull'infrastruttura e su Oracle Database.

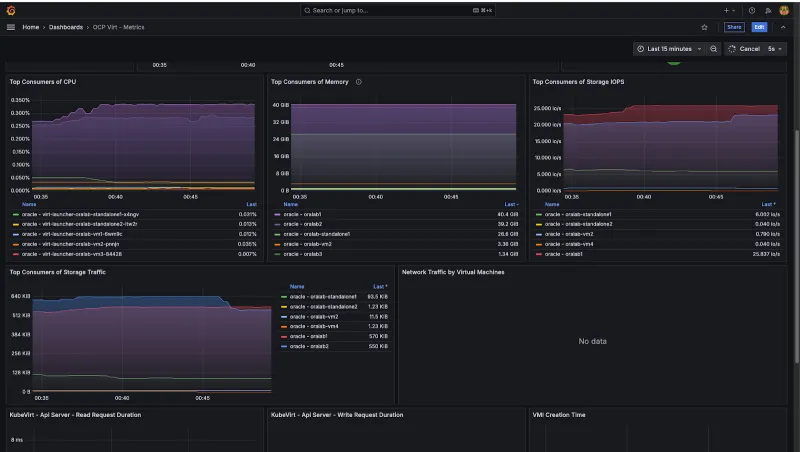
La figura 5 mostra un esempio di dashboard Grafana distribuita come parte della configurazione dell'osservabilità e del monitoraggio per la piattaforma OpenShift Virtualization.

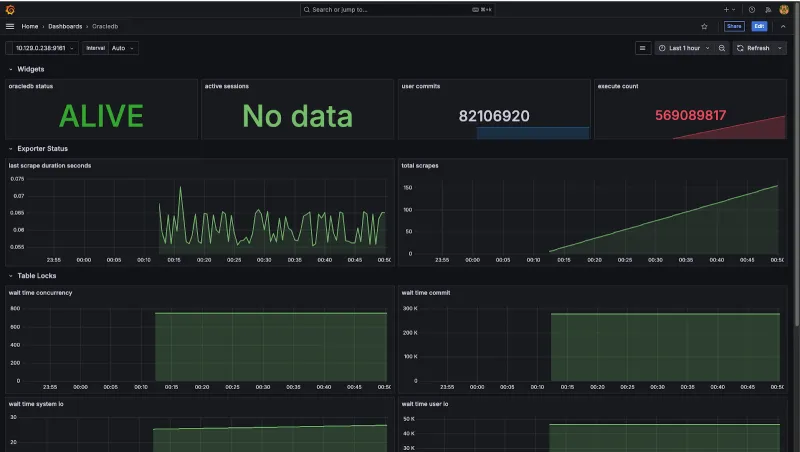
La figura 6 mostra un esempio di dashboard di Oracle Database Grafana distribuita sulla piattaforma OpenShift Virtualization.

Valutazione delle prestazioni del sistema
Il test delle prestazioni è stato progettato per misurare il throughput delle transazioni del database e la latenza delle query per i carichi di lavoro OLTP (Online Transaction Processing). Abbiamo utilizzato HammerDB, un software open source per il test delle prestazioni dei database per simulare i carichi di lavoro OLTP utilizzando il benchmark TPC-C a fronte di Oracle Database a istanza singola con i dettagli di sistema menzionati in precedenza. Il test TPC-C simula un sistema di gestione degli ordini reale, con un mix di operazioni per l'80% di scrittura e per il 20% di lettura, inclusi ordini dei clienti ad alta frequenza, pagamenti, controlli dell'inventario e consegne in batch. L'esecuzione del test prevede che HammerDB generi carichi di lavoro TPC-C su Oracle Database all'interno di OpenShift Virtualization.


Riepilogo del test
Con il test harness di HammerDB, il profilo di scalabilità dell'esecuzione è stato configurato per simulare carichi di lavoro significativi con un numero di utenti virtuali a partire da 20 e scalabile fino a 100, utilizzando 500 warehouse per ogni ciclo di test per 20 minuti. Abbiamo progettato questa configurazione per riflettere scenari di produzione realistici e per valutare le prestazioni del sistema con carichi transazionali scalabili.
In base alla configurazione dell'architettura di riferimento, i risultati del test hanno mostrato metriche solide New Orders Per Minute (NOPM) e Transactions Per Minute (TPM) per la singola istanza di Oracle Database con lo storage OpenShift Data Foundation. Tuttavia, Oracle Database a singola istanza con storage NVMe locale ha fornito prestazioni migliori rispetto alla configurazione di OpenShift Data Foundation. Sebbene la latenza media sia rimasta relativamente stabile, abbiamo osservato picchi occasionali.
Considerazioni finali
OpenShift Virtualization è una piattaforma idonea per il deployment dei carichi di lavoro Oracle Database 19c. La facilità di configurazione di OpenShift Virtualization offre un solido supporto per la creazione di macchine virtuali. Considerando questi fattori, OpenShift Virtualization si pone come valida alternativa alle tecnologie di virtualizzazione concorrenti. L'attuale convalida delle prestazioni di Oracle Database 19c dimostra prestazioni di livello enterprise sulla piattaforma OpenShift Virtualization.
Attraverso test ad hoc dello storage NVMe locale, abbiamo valutato l'impatto delle opzioni di storage ad alte prestazioni e abbiamo riscontrato che l'upgrade a soluzioni di storage ad alte prestazioni come FC SAN può migliorare significativamente le prestazioni complessive.
Per i carichi di lavoro ad alte prestazioni, è bene considerare:
- Opzioni di storage ad alte prestazioni come FC SAN per i file di dati di Oracle Database e i redolog per ottimizzare le prestazioni.
- Segmentazione della rete per le macchine virtuali, SDN di OpenShift e rete di storage, utilizzando preferibilmente dispositivi fisici separati sui nodi di OpenShift Virtualization.
- SR-IOV (Single Root I/O Virtualization), se supportato dall'hardware, per ottimizzare le prestazioni delle interfacce di rete virtuali delle macchine virtuali che ospitano il carico di lavoro di Oracle Database.
- HugePages con l'impostazione Oracle Database
USE_LARGE_PAGESin base ai requisiti del carico di lavoro: questa configurazione regola le dimensioni della pagina di memoria, consigliata per migliorare le prestazioni, soprattutto quando si lavora con SGA più grandi rispetto alle impostazioni predefinite.
Gli script di test di HammerDB sono disponibili in questo repository GitHub.
Il progetto GitHub oracle-db-appdev-monitoring mira a fornire l'osservabilità per Oracle Database in modo che gli utenti possano comprendere le prestazioni e diagnosticare facilmente i problemi tra applicazioni e database. Leggi le istruzioni per configurare il progetto sulla piattaforma OpenShift.
Prova prodotto
Red Hat Learning Subscription | Versione di prova
Sugli autori

Altri risultati simili a questo
Accelerating VM migration to Red Hat OpenShift Virtualization: Hitachi storage offload delivers faster data movement
Achieve more with Red Hat OpenShift 4.21
Ricerca per canale

Automazione
Novità sull'automazione IT di tecnologie, team e ambienti

Intelligenza artificiale
Aggiornamenti sulle piattaforme che consentono alle aziende di eseguire carichi di lavoro IA ovunque

Hybrid cloud open source
Scopri come affrontare il futuro in modo più agile grazie al cloud ibrido

Sicurezza
Le ultime novità sulle nostre soluzioni per ridurre i rischi nelle tecnologie e negli ambienti

Edge computing
Aggiornamenti sulle piattaforme che semplificano l'operatività edge

Infrastruttura
Le ultime novità sulla piattaforma Linux aziendale leader a livello mondiale

Applicazioni
Approfondimenti sulle nostre soluzioni alle sfide applicative più difficili
Virtualizzazione
Il futuro della virtualizzazione negli ambienti aziendali per i carichi di lavoro on premise o nel cloud