
In today’s Storage Tutorial, Brian chats with Red Hat’s Paul Cuzner of the storage business unit. Paul has been focused on finding new ideas and strategies where Red Hat Storage can make a difference for customers and, most recently, has spent time working with Splunk. Watch the video below to find out just how Paul and Red Hat work with customers to make the most of Splunk and their storage, but we’ve broken down one salient bit for you right here…keep reading!
Understanding Splunk data flows
Data arriving within a Splunk indexer, as it’s being parsed, is placed into a structure named a bucket – a directory in a file structure. This bucket is considered “hot” because its index is being actively built, or files are constantly being added or removed from it. When it reaches a certain size, or age, it moves to “warm” storage, meaning the index is built and closed, so no further information is added and it becomes a point of record.
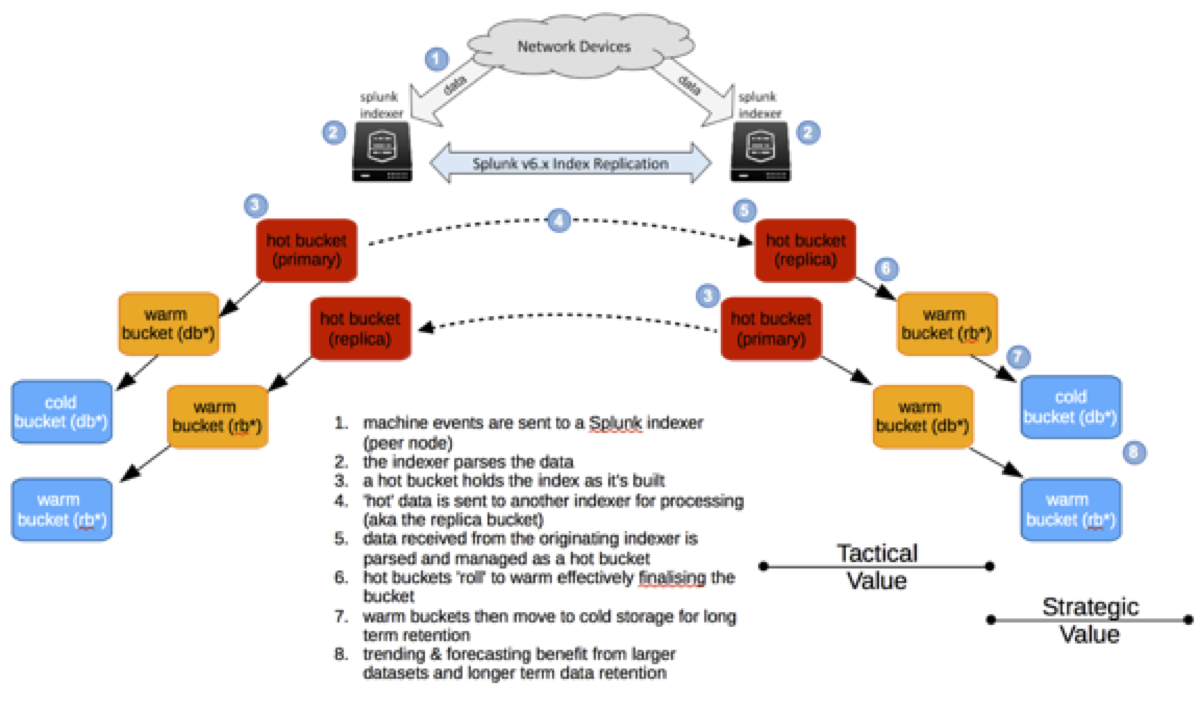 The Splunk data migration flow, illustrated!
The Splunk data migration flow, illustrated!
Hot and warm buckets, because they are considered to be in use or readily available, are typically placed on very fast storage – 10,000 or 15,000 RPM hard disks or flash storage, for example.
Eventually warm buckets are rolled into “cold” buckets. These are also not written to and are available for search. This storage, because it isn’t accessed quite as often, is typically placed on slower storage with very high capacity…and this is where customers struggle to choose a platform.
Be sure to check out the video, next:
Sull'autore
Altri risultati simili a questo
Le minacce dell'IA si muovono rapidamente. Anche le tue difese dovrebbero farlo.
Il punto di svolta per l’IA: perché la sovranità non è più facoltativa
Container Roundup | Compiler
Untangling Networks | Compiler
Ricerca per canale

Automazione
Novità sull'automazione IT di tecnologie, team e ambienti

Intelligenza artificiale
Aggiornamenti sulle piattaforme che consentono alle aziende di eseguire carichi di lavoro IA ovunque

Hybrid cloud open source
Scopri come affrontare il futuro in modo più agile grazie al cloud ibrido

Sicurezza
Le ultime novità sulle nostre soluzioni per ridurre i rischi nelle tecnologie e negli ambienti

Edge computing
Aggiornamenti sulle piattaforme che semplificano l'operatività edge

Infrastruttura
Le ultime novità sulla piattaforma Linux aziendale leader a livello mondiale

Applicazioni
Approfondimenti sulle nostre soluzioni alle sfide applicative più difficili
Virtualizzazione
Il futuro della virtualizzazione negli ambienti aziendali per i carichi di lavoro on premise o nel cloud