
If you been doing sysadmin work long enough, you’ve seen the dreaded "Server is slow" incidents. For a long time, these types of incidents would give me a pit in my stomach. How the heck do you troubleshoot something so subjective? An everyday user’s "slow" might just be caused by other processes (scheduled or not) running and consuming more resources than usual, or something could actually be wrong with the server.
When I first started working as a sysadmin, I would immediately reply with: "I need more information on this." Well, usually the user isn’t able to give any more info, because they don’t know what’s running behind the scenes or how to explain what they’re seeing other than "it’s just slow." Nowadays, before I even reply to the user, I check a few things out.
Initial login
There’s a lot you can tell by logging into the host. Can you log in at all? Is the login slow or hanging? The ssh command has three debug levels, each of which gives you a plethora of information before you’re even on the system. To enable debug, just add an additional v to the -v option. For example, a level three debug, which is what I use exclusively, would be:
[~]$ ssh -vvv hostname.domain.com
The "Big 3" (aka CPU, RAM, and Disk I/O)
Now, let’s look at the three biggest causes of server slowdown: CPU, RAM, and disk I/O. CPU usage can cause overall slowness on the host, and difficulty completing tasks in a timely fashion. Some tools I use when looking at CPU are top andsar.
Checking CPU usage with top
The top utility gives you a real-time look at what’s going on with the server. By default, when top starts, it shows activity for all CPUs:

This view can be changed by pressing the numeric 1 key, which adds more detail regarding the usage values for each CPU:
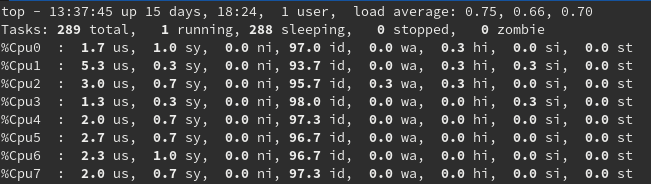
Some things to look for in this view would be the load average (displayed on the right side of the top row), and the value of the following for each CPU:
us: This percentage represents the amount of CPU consumed by user processes.sy: This percentage represents the amount of CPU consumed by system processes.id: This percentage represents how idle each CPU is.
Each of these three values can give you a fairly good, real-time idea of whether CPUs are bound by user processes or system processes.
To truly explain load average would need an article on its own. For the purpose of this article, I’ll talk in generalities. The three load average values from left to right represent one-minute, five-minute, and 15-minute averages. Again, speaking very generally, if you see the one-minute average go above the number of physical CPUs you have, then the system is most likely CPU bound.
Note: For more information about load average and why some people think it’s a silly number, check out Brendan Gregg’s in-depth research.
Checking all of the "Big 3" with sar
For historical CPU performance data I rely on the sar command, which is provided by the sysstat package. On most server versions of Linux, sysstat is installed by default, but if it’s not, you can add it with your distro’s package manager. The sar utility collects system data every 10 minutes via a cron job located in /etc/cron.d/sysstat (CentOS 7.6). Here’s how to check all of the "Big 3" using sar.
Note: If you’ve just installed sar to follow along with this article, give the command some time to record data first.
The command sar -u gives you info about all CPUs on the system, starting at midnight:

As with top, the main things to check here are %user, %system, %iowait, and %idle. This information can tell you how far back the server has been having issues.
Overall, the sar command can provide a lot of information. Since this article explains just a quick check of what’s happening on the server, check out man sar to break down this info even further.
To check RAM performance, I use sar -r, which give you that day’s memory usage:
The main thing to look for in RAM usage is %memused and %commit. A quick word about the %commit field: This field can show above 100% since the Linux kernel routinely overcommits RAM. If %commit is consistently over 100%, this result could be an indicator that the system needs more RAM.
For disk I/O performance, I use sar -d, which gives you the disk I/O output using just the device name. To get the name of the devices, use sar -dP:

For this output, looking at %util and %await will give you a good overall picture of disk I/O on the system. The %util field is pretty self-explanatory: It’s the utilization of that device. The await field contains the amount of time the I/O spends in the scheduler. Await is measured in milliseconds, and in my environment, I’ve seen that anything greater than 50ms starts to cause issues. That threshold may vary in your environment.
If any of these commands show a problem, you can go back to see when the server issues started by using sar {-u, -r, -d, -dP} -f /var/log/sa/sa<XX> (where XX is the day of the month you wish to look for).
At this point, I usually have a good idea of what’s currently happening on the server, and what’s been going on for the last 48 hours or so. I’ll reply to the user with more informed responses. For example: "I don’t see any indication of host slowness in the last 24 hours. Please try using a new putty profile to ssh in, and let me know if you continue to have issues."
Another example: "I don’t see anything currently causing issues on this host, but I did notice some higher CPU load $time. Is that when you saw issues? If so please try now and let me know if you continue to see issues."
You get the idea. Having the information provided by looking at the initial login and then running a few sar commands, which generally take me less than 10 minutes to run, does a lot to head off more questions and reach a resolution faster.
Sull'autore
Jake has been an Enterprise Linux Systems Administrator for the 13 years. His goal has been to automate himself out of a job and try as he will he's been unable to do so, yet. In his free time, he enjoys fishing, kayaking, and knife making.
Altri risultati simili a questo
Red Hat Device Edge è ora disponibile per l'esecuzione su NVIDIA Jetson Orin
Stabilità a lungo termine: introduzione a Red Hat Enterprise Linux Extended Life Cycle, Premium
Operating System Management | Compiler
What’s The Recipe For Burnout? | Compiler
Ricerca per canale

Automazione
Novità sull'automazione IT di tecnologie, team e ambienti

Intelligenza artificiale
Aggiornamenti sulle piattaforme che consentono alle aziende di eseguire carichi di lavoro IA ovunque

Hybrid cloud open source
Scopri come affrontare il futuro in modo più agile grazie al cloud ibrido

Sicurezza
Le ultime novità sulle nostre soluzioni per ridurre i rischi nelle tecnologie e negli ambienti

Edge computing
Aggiornamenti sulle piattaforme che semplificano l'operatività edge

Infrastruttura
Le ultime novità sulla piattaforma Linux aziendale leader a livello mondiale

Applicazioni
Approfondimenti sulle nostre soluzioni alle sfide applicative più difficili
Virtualizzazione
Il futuro della virtualizzazione negli ambienti aziendali per i carichi di lavoro on premise o nel cloud