In un articolo precedente, ci siamo concentrati sulla capacità di trasformare i modelli linguistici di grandi dimensioni (LLM) da strumenti generici in strumenti di ricerca attraverso la personalizzazione specifica del dominio. I modelli ottimizzati sono lo strumento con cui i team di ricerca codificano l'esperienza del settore, la ricerca istituzionale e i modelli di ragionamento in sistemi in grado di accelerare la scoperta, anziché limitarsi a supportarla.
Tuttavia, i modelli personalizzati rappresentano solo una metà dell'equazione. Affinché tali modelli diventino utili su scala istituzionale, occorre una piattaforma per addestrarli, distribuirli, gestirne l'accesso e integrarli nel più ampio ambiente di elaborazione della ricerca. Questa piattaforma deve collegare i mondi in cui i ricercatori operano già: i tradizionali cluster high performance computing (HPC) che eseguono il gestore dei carichi di lavoro Slurm e l'ecosistema di IA cloud native in rapida espansione basato su Kubernetes.
In questo articolo esploriamo come si compone tale piattaforma: l'architettura che consente agli istituti di ricerca di far convergere i carichi di lavoro HPC e cloud native, rendere operativi i modelli personalizzati come servizi condivisi e fornire funzionalità di intelligenza artificiale generativa (gen AI) a intere organizzazioni senza sacrificare la governance, la riproducibilità o il controllo dei costi.
L'architettura della piattaforma: in che modo i componenti si integrano
Una volta definito lo scenario di personalizzazione, esaminiamo come si compone l'intera piattaforma. L'architettura è generica e si applica a università di ricerca, centri di ricerca e sviluppo finanziati dal governo federale, ospedali universitari, aziende energetiche o gruppi di ricerca sui servizi finanziari. I componenti sono gli stessi, ma la configurazione per ogni dominio differisce.
La base è Red Hat OpenShift, una distribuzione Kubernetes che fornisce l'orchestrazione dei container, la governance dello spazio dei nomi, il controllo degli accessi basato sui ruoli (RBAC), l'integrazione dello storage permanente e gli strumenti operativi necessari agli ingegneri della piattaforma per eseguire un'infrastruttura di IA condivisa su scala istituzionale.
Oltre a OpenShift, Red Hat OpenShift AI offre funzionalità specifiche per l'IA, tra cui il model serving, la personalizzazione dei modelli, l'orchestrazione delle pipeline, gli ambienti notebook per i data scientist e l'osservabilità per i carichi di lavoro IA. OpenShift AI trasforma la piattaforma Kubernetes di base in un ambiente in cui i ricercatori possono addestrare, ottimizzare, valutare, distribuire e monitorare i modelli attraverso un'interfaccia self service gestita, senza che ogni team debba gestire la propria infrastruttura di machine learning (ML).
Il motore di inferenza è vLLM, fornito tramite il livello di model serving di OpenShift AI. Il batching continuo di vLLM e i meccanismi di attenzione efficienti in termini di memoria lo rendono la scelta giusta per gli ambienti di inferenza condivisi in cui più team di ricerca utilizzano contemporaneamente gli endpoint del modello. In un ambiente con risorse limitate, come la maggior parte degli istituti di ricerca, la differenza tra un'inferenza efficiente e una inefficiente rappresenta una quota significativa del budget della GPU.
Il livello hardware Red Hat AI Factory with NVIDIA è il punto in cui la collaborazione tra Red Hat e NVIDIA diventa direttamente rilevante. Red Hat AI Factory with NVIDIA unisce l'hardware GPU di NVIDIA e il framework NVIDIA Inference Microservices (NIM) alle funzionalità di orchestrazione e governance di OpenShift AI. I container NIM includono configurazioni di modelli ottimizzate e convalidate, pronte per l'uso sull'hardware NVIDIA; poiché vengono eseguiti su OpenShift, ereditano la governance dello spazio dei nomi, l'RBAC e lo stack di osservabilità della piattaforma.
Per gli istituti di ricerca che acquistano un'infrastruttura GPU NVIDIA (ovvero la maggior parte), l'architettura di riferimento Red Hat AI Factory with NVIDIA offre un percorso convalidato e supportato dall'hardware all'esecuzione dei servizi di inferenza, aiutando a evitare mesi di lavoro di integrazione. Il catalogo NIM di NVIDIA include modelli di base delle principali famiglie di modelli, mentre la pipeline di personalizzazione di OpenShift AI estende tali basi con l'ottimizzazione specifica del dominio. Questa combinazione rappresenta un percorso pratico per passare dal possesso di GPU alla disponibilità di un modello clinico ottimizzato al servizio dei ricercatori.
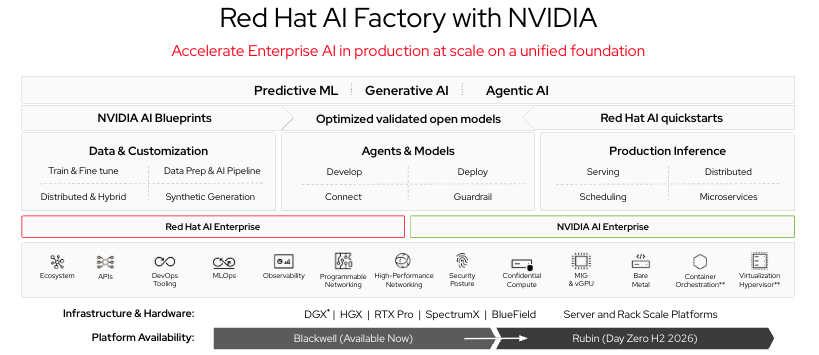
Figura 1: Red Hat AI Factory with NVIDIA
Coniugare HPC e cloud native: l'operatore Slinky
Slurm gestisce molti dei principali supercomputer del mondo ed è l'interfaccia standard per l'invio dei processi HPC negli istituti di ricerca. I punti di forza di Slurm sono concreti e includono prenotazioni esclusive delle GPU, prestazioni prevedibili, gestione matura delle code con priorità e una profonda integrazione con i file system paralleli e i carichi di lavoro in stile message passing interface (MPI). La maggior parte degli utenti HPC degli istituti di ricerca conosce Slurm e le loro pipeline sono generalmente scritte per Slurm.
La sfida è sempre stata il divario tra il mondo Slurm e quello Kubernetes: due scheduler, due sistemi di contabilità delle risorse, due modi per richiedere una GPU, due team operativi. Gli artefatti dei dati vengono spostati manualmente tra gli ambienti e la capacità della GPU rimane spesso inattiva nel cluster HPC durante i periodi di basso utilizzo, mentre l'ambiente Kubernetes mette in coda i processi.
L'operatore Slinky colma questa lacuna. Come illustrato in questo articolo sull'esecuzione dei carichi di lavoro Slurm su OpenShift, Slinky è un operatore Kubernetes che distribuisce e gestisce i componenti Slurm, inclusi slurmctld e slurmd, come carichi di lavoro containerizzati all'interno di OpenShift, automatizzando distribuzione, scalabilità e gestione del ciclo di vita del cluster Slurm, in modo che possa coesistere con i carichi di lavoro Kubernetes native sullo stesso hardware.
Cosa significa in pratica per chi si occupa di ingegneria delle piattaforme di ricerca?
- Pianificazione unificata delle risorse: i processi batch Slurm e i carichi di lavoro di IA Kubernetes native condividono lo stesso pool di GPU. La capacità inattiva tra processi di simulazione di grandi dimensioni può essere allocata ai carichi di lavoro di inferenza o di ottimizzazione (fine tuning) senza intervento manuale o riassegnazione dell'hardware.
- Flussi di lavoro dei ricercatori preservati: i ricercatori HPC che inviano i processi tramite sbatch non devono modificare il proprio flusso di lavoro. L'interfaccia Slurm che conoscono è ancora presente, ma ora è in esecuzione anche all'interno di OpenShift, con tutta l'osservabilità, la gestione del ciclo di vita e la governance offerte da Kubernetes.
- Ambienti riproducibili: i processi Slurm vengono eseguiti come container; questo significa che l'immagine del container definisce l'ambiente, non ciò che risulta installato nel nodo di calcolo. Ciò migliora notevolmente la riproducibilità e semplifica la collaborazione tra le istituzioni che desiderano condividere le pipeline.
- Superficie operativa unica: chi si occupa di ingegneria delle piattaforme gestisce un cluster, uno stack di osservabilità e un modello RBAC. Slinky non richiede né crea una seconda infrastruttura: integra la pianificazione HPC nella piattaforma già in uso.
L'acquisizione di SchedMD da parte di NVIDIA, il principale sviluppatore di Slurm, indica la direzione di questa convergenza a livello di settore. I confini tra pianificazione HPC, orchestrazione Kubernetes e infrastruttura di IA vengono eliminati intenzionalmente. Slinky è il contributo di Red Hat a tale convergenza, ora disponibile per l'esecuzione in produzione.
Per un'università di ricerca che gestisce sia un cluster HPC per le scienze computazionali sia un ambiente OpenShift per la ricerca sull'IA, Slinky aiuta a far funzionare questi due investimenti come uno solo.
Models-as-a-Service (MaaS): il modello di piattaforma di IA condivisa per gli istituti di ricerca
La convergenza delle piattaforme risolve il problema dell'infrastruttura, ma esiste un altro problema altrettanto importante e meno discusso: la maggior parte dei team di ricerca non include figure esperte in ingegneria dell'infrastruttura. Un team di informatica clinica che crea un chatbot per l'equità sanitaria non vuole gestire gli spazi dei nomi Kubernetes. Un laboratorio di genomica che necessita di un modello ottimizzato per l'annotazione delle varianti non vuole configurare distribuzioni vLLM. Un dipartimento di scienze sociali computazionali che desidera eseguire l'analisi dei documenti basata su LLM non vuole scrivere grafici Helm.
Il modello operativo che risolve questo problema è Models-as-a-Service (MaaS).
Cos'è il MaaS?
MaaS è un approccio in cui chi si occupa di ingegneria delle piattaforme distribuisce, gestisce e utilizza i modelli di IA come servizi condivisi, esponendoli agli utenti tramite API. Nel contesto di un istituto di ricerca, ciò significa che il team della piattaforma di elaborazione della ricerca gestisce il cluster GPU, il ciclo di vita del modello, il controllo delle versioni e gli aggiornamenti, occupandosi inoltre della manutenzione dell'infrastruttura di serving. Al contempo, i team di ricerca utilizzano gli endpoint del modello come servizio, proprio come farebbero con un'allocazione di elaborazione o un montaggio dello storage.
Le implicazioni per la produttività della ricerca sono significative. Confronta l'aspetto del flusso di lavoro attuale con quello di un modello MaaS.
Oggi, senza MaaS
Un team di ricerca ha bisogno di un modello ottimizzato per il proprio progetto. Il team trascorre settimane a configurare un ambiente GPU, installare dipendenze, configurare un framework di serving e risolvere i problemi dell'infrastruttura. La ricerca vera e propria inizia quando l'infrastruttura finalmente funziona, il che può accadere mesi dopo l'inizio del progetto. Al termine, il modello risiede sulla workstation di una persona o su un'allocazione temporanea del cluster che viene recuperata.
Con MaaS su OpenShift AI
Il team di ricerca fornisce il proprio set di dati e i requisiti del dominio al team della piattaforma. I team collaborano con gli ingegneri della piattaforma per configurare ed eseguire un processo di fine tuning tramite Training Hub su OpenShift AI. Il modello risultante viene fornito come endpoint API controllato e con versione sul cluster condiviso. Altri team di ricerca con esigenze correlate possono accedere allo stesso endpoint. Quando il modello deve essere aggiornato con nuovi dati, la pipeline di addestramento viene rieseguita e la nuova versione viene promossa tramite lo stesso processo controllato.
Il team della piattaforma si occupa dell'infrastruttura, mentre il team di ricerca si dedica alle attività scientifiche. Questa divisione del lavoro consente di estendere le funzionalità di IA all'interno dell'istituto.

Figura 2: unire HPC, cloud native e Models-as-a-Service per la ricerca scientifica
Agli ingegneri della piattaforma, MaaS su OpenShift AI (o "Research-as-a-Service", se vogliamo) fornisce gli strumenti operativi necessari: quote di risorse a livello di namespace che impediscono a un singolo progetto di ricerca di monopolizzare la capacità della GPU, il controllo delle versioni dei modelli tramite un registro, RBAC per controllare chi può eseguire la distribuzione e chi può solo utilizzare il servizio, e l'osservabilità di tutti i carichi di lavoro di serving tramite una dashboard unificata.
Per gli istituti di ricerca con più gruppi di ricerca (ad esempio una facoltà di medicina, un dipartimento di biologia computazionale, una scuola di informatica e un istituto di data science, tutti operanti sulla stessa piattaforma), il modello MaaS permette al team della piattaforma di soddisfare la domanda senza aumentare l'organico in modo lineare rispetto al numero di progetti di ricerca.
Gravità dei dati: porta l'IA dove si svolge la ricerca
La ricerca si trova ad affrontare il problema della gravità dei dati. I set di dati di maggior valore (cartelle cliniche, sequenze genomiche, risultati di simulazioni) sono già estesi, distribuiti e spesso inamovibili a causa di vincoli legati a costi, latenza o governance. Spostare petabyte di dati su un endpoint cloud è inefficiente e spesso impossibile.
La piattaforma descritta in questa sede fa l’opposto: porta l'IA verso i dati. Eseguendo l'addestramento dei modelli, il fine tuning e l'inferenza dove risiedono già i dati (on premise, in laboratorio, in ambienti di ricerca protetti, ecc.), puoi evitare spostamenti non necessari dei dati preservando prestazioni e conformità.
In fin dei conti, non si tratta solo di un'ottimizzazione: è un vero e proprio requisito dell'architettura. Più il modello è vicino ai dati, più veloce è il ciclo di iterazione, più basso è il costo e più pratico diventa rendere operativa l'IA nei flussi di lavoro di ricerca su larga scala.
Ambiti di applicazione di questa architettura: ricerca in tutti i settori
Naturalmente, questa piattaforma non è specifica per la ricerca accademica. L'architettura è adatta a qualsiasi istituto in cui le competenze settoriali sono importanti, la governance dei dati limita la distribuzione cloud native e i carichi di lavoro di ricerca spaziano dall'HPC al cloud native.
- Università di ricerca e centri di ricerca e sviluppo finanziati dal governo federale (FFRDC): le università e i centri di ricerca e sviluppo finanziati dal governo federale, come i laboratori nazionali, dispongono in genere dell'infrastruttura gestita da questa architettura: cluster HPC per la ricerca incentrata sulla simulazione, crescente domanda di IA cloud native da parte dei gruppi di data science e team di ingegneria della piattaforma che cercano di servire decine di gruppi di ricerca con requisiti di elaborazione diversi.
- Istituti medici e ospedali universitari: l'IA clinica è una delle aree di investimento nella ricerca in più rapida crescita ed è una delle più esigenti in termini di accuratezza dei modelli, governance dei dati e requisiti di sicurezza. I modelli cloud generici spesso non sono utilizzabili a causa degli obblighi di privacy dei dati dei pazienti. Queste organizzazioni hanno bisogno di modelli ottimizzati da eseguire on premise, con registrazione degli audit e controlli degli accessi, serviti tramite una piattaforma istituzionale governata.
- Ricerca nel settore della difesa e dell'intelligence: gli FFRDC e gli appaltatori della difesa che operano in ambienti classificati o controllati condividono le stesse esigenze di governance dei dati della ricerca clinica, a cui si aggiungono i requisiti di classificazione che vietano l'uso delle API cloud. Questi richiedono la distribuzione dei modelli on premise, operazioni disconnesse e modelli ottimizzati che integrano internamente conoscenze di dominio classificate.
- Servizi finanziari e ricerca quantitativa: i gruppi di ricerca nei servizi finanziari (ad esempio ricerca quantitativa, modellazione del rischio, analisi normativa) lavorano con dati proprietari e operano nel rispetto di vincoli normativi che limitano ciò che puoi inviare alle API esterne. Questi necessitano di modelli ottimizzati addestrati sulla ricerca interna, forniti on premise tramite MaaS e accessibili tramite API governate che si integrano con i flussi di lavoro di ricerca esistenti.
- Energia e ricerca industriale: le organizzazioni che si occupano di petrolio e gas, di servizi pubblici e di ricerca industriale eseguono carichi di lavoro di simulazione ad alta intensità di elaborazione insieme a pipeline di machine learning in crescita per la ricerca sui materiali, la manutenzione predittiva e l'analisi geofisica. Slinky è particolarmente importante in questo settore, perché i flussi di lavoro di simulazione basati su Slurm sono standard e l'analisi basata sul machine learning è sempre più richiesta a valle di tali simulazioni.
In tutti questi contesti, il modello architetturale è coerente: convergenza di HPC e scheduling cloud native, personalizzazione dei modelli in base alle specificità del dominio, erogazione efficiente tramite una piattaforma MaaS condivisa e gestione degli accessi a livello istituzionale.
Riassumendo: cosa offre la piattaforma
A titolo di esempio, ecco cosa offre l'intera architettura per un istituto di ricerca che l'ha distribuita:
Un ricercatore di genomica computazionale invia un processo di identificazione delle varianti su larga scala tramite Slurm, nello stesso modo in cui invia processi HPC da anni. L'operatore Slinky pianifica il processo come carico di lavoro containerizzato su OpenShift, sugli stessi nodi GPU che servono anche gli endpoint di inferenza ottimizzati. Al termine del processo, gli output vengono archiviati in un archivio di oggetti condiviso, accessibile sia dagli ambienti HPC che Kubernetes.
Un ricercatore clinico di NLP che lavora in una facoltà di medicina ha bisogno di un modello ottimizzato su note cliniche anonimizzate per un'attività di riconoscimento di entità nominate. Collabora con il team della piattaforma per eseguire un processo di fine tuning Low-Rank Adaptation (LoRA) tramite Training Hub su OpenShift AI, utilizzando un modello di base dal catalogo NVIDIA NIM. Il modello risultante è sottoposto a versionamento e servito come endpoint MaaS. Altri due team di ricerca con attività di elaborazione del linguaggio naturale (NLP) adiacenti iniziano immediatamente a utilizzare lo stesso endpoint, distribuendo i costi di fine tuning in tutto l'istituto.
Un gruppo di ricerca sulla sicurezza informatica presso un FFRDC deve analizzare i report di intelligence sulle minacce su larga scala utilizzando un LLM. Poiché i dati presentano vincoli di sensibilità che vietano l'utilizzo delle API cloud, il modello viene eseguito interamente on premise nel cluster OpenShift. Il modello è stato ottimizzato sul loro set di dati classificato utilizzando la generazione di dati sintetici InstructLab per aumentare il loro piccolo set di dati etichettato. L'endpoint è accessibile solo agli spazi dei nomi con le associazioni RBAC appropriate.
Un ingegnere della piattaforma che gestisce tutti questi carichi di lavoro sullo stesso cluster visualizza un'unica dashboard di osservabilità con l'utilizzo della GPU nei carichi di lavoro Slurm e Kubernetes, la latenza del model serving per endpoint, la profondità della coda dei processi di addestramento e l'utilizzo della quota delle risorse per spazio dei nomi. L'utilità di pianificazione unificata risolve i conflitti di risorse tra i carichi di lavoro, senza richiedere l'intervento manuale.
Ognuna di queste funzionalità è oggi disponibile in Red Hat AI e OpenShift AI, integrata con l'hardware NVIDIA tramite l'architettura di riferimento Red Hat AI Factory with NVIDIA ed estesa ai flussi di lavoro HPC tramite l'operatore Slinky.
Considerazioni conclusive
I ricercatori che guideranno la prossima generazione di scoperte utilizzeranno gli LLM come strumento principale e come parte centrale del flusso di lavoro di ricerca, non come integrazione ai metodi esistenti.
Hanno bisogno di una piattaforma che possano utilizzare senza dover diventare ingegneri dell'infrastruttura. Necessitano di modelli ottimizzati che conoscano effettivamente il loro dominio, di inferenze veloci e affidabili, di flussi di lavoro HPC che non richiedano il passaggio a un cluster diverso e di un accesso condiviso tramite un servizio governato.
Insieme, Red Hat OpenShift, Red Hat AI, NVIDIA e l'operatore Slinky possono fornire questa piattaforma.
Risorsa
Definizione della strategia aziendale per l'IA: una guida introduttiva
Sugli autori

I build real-world GenAI solutions for organizations that can’t afford to get it wrong.
My career spans national security, enterprise software, and next-generation AI platforms, with more than a decade focused on solving complex problems at the intersection of data, intelligence, and technology. I began in the intelligence community, serving eight years with the NSA and across the IC in intrusion defense, intelligence analysis, and mission-critical cyber operations. That experience in high-stakes security, pattern recognition, and adversarial thinking continues to shape how I approach GenAI strategy and deployment today.
Since then, I’ve led product and platform initiatives in digital ecosystems, advised startups, and worked across the data science landscape helping organizations move from experimentation to production. Much of my work focuses on making generative AI models more knowledgeable and reliable by grounding them in domain-specific data, mission context, and real operational constraints across national security, research, and healthcare.
Today, as an AI Solutions Advisor at Red Hat and IBM, I partner with government agencies, research institutions, and enterprises across North America to design scalable GenAI systems that work in the real world. The goal is never novelty — it’s better decisions, faster execution, and durable advantage.

O'Neill Joseph is a Sr AI Solutions Architect in Red Hat focused on specialized AI deployments, has over 20 experience in IT Infrastructure, from telecommunications to cloud native infrastructure with a Degree in Cybersecurity and IT Networking from University of Maryland.

Working with customers to build IT solutions for over 25 years, Wes has experience integrating various technologies and approaches to produce outcomes and achieve mission objectives. Serving highly regulated industries such as healthcare and defense, Wes understands how to approach IT challenges with a secure, compliant end state in mind.
At Red Hat, Wes focuses on helping customers build cloud-native platforms where they can run AI/ML workloads, integrate heterogeneous data and facilitate outcomes anywhere in the world.
Prior to joining Red Hat, Wes was the CTO at a small technology company in DC helping build solutions for a variety of government customers.
Wes has managed global engineering teams, built services to help customers scale their missions, and designed software solutions to meet the needs of growing organizations.
Altri risultati simili a questo
Smetti di gestire il passato e inizia a costruire il futuro dell'IT
Il prossimo punto di svolta dell'IA: trasformare gli agenti in superutenti aziendali
Technically Speaking | Build a production-ready AI toolbox
Technically Speaking | Platform engineering for AI agents
Ricerca per canale

Automazione
Novità sull'automazione IT di tecnologie, team e ambienti

Intelligenza artificiale
Aggiornamenti sulle piattaforme che consentono alle aziende di eseguire carichi di lavoro IA ovunque

Hybrid cloud open source
Scopri come affrontare il futuro in modo più agile grazie al cloud ibrido

Sicurezza
Le ultime novità sulle nostre soluzioni per ridurre i rischi nelle tecnologie e negli ambienti

Edge computing
Aggiornamenti sulle piattaforme che semplificano l'operatività edge

Infrastruttura
Le ultime novità sulla piattaforma Linux aziendale leader a livello mondiale

Applicazioni
Approfondimenti sulle nostre soluzioni alle sfide applicative più difficili
Virtualizzazione
Il futuro della virtualizzazione negli ambienti aziendali per i carichi di lavoro on premise o nel cloud