

I team aziendali riscontrano spesso il problema della lentezza nell’elaborazione dei dati durante lo sviluppo di applicazioni di IA generativa (gen AI), come nel caso della retrieval-augmented generation (RAG), poiché i tradizionali strumenti di elaborazione dei documenti non riescono a gestire in modo efficiente migliaia di documenti complessi. Questo articolo spiega come un'infrastruttura unificata, che combina Ray Data per lo streaming ad alta velocità e Docling per un'analisi precisa dei documenti, elimini questi ostacoli. Grazie alla scalabilità di questi strumenti su piattaforme come Red Hat OpenShift AI o Anyscale, le organizzazioni possono trasformare dati disordinati e non strutturati in informazioni fruibili in poche ore anziché in giorni, trovando la fiducia e l’affidabilità che serviranno per la prossima ondata di innovazione dell'IA.
Anyscale è l'azienda alla base di Ray, un framework per il calcolo distribuito che ora fa parte della PyTorch Foundation. Anyscale offre anche una piattaforma di IA.
Red Hat OpenShift AI offre alle organizzazioni una piattaforma scalabile per sviluppare e distribuire l'IA. Utilizza KubeRay per eseguire i cluster Ray su Kubernetes, offrendo una maggiore affidabilità e scalabilità automatica. Con l'aggiunta di Docling per l'analisi dei documenti, OpenShift AI consente ai team di gestire le attività di CPU e GPU su un unico sistema. Ciò riduce il sovraccarico e accelera la distribuzione delle applicazioni di IA.
La realtà dietro la lentezza nell’elaborazione dei dati della RAG
Nelle demo, la creazione di soluzioni di IA generativa sembra sempre semplice, ma la realtà della preparazione e dell'elaborazione dei dati è molto più complessa. Immagina che il tuo team abbia appena ereditato decine di migliaia di PDF e che il CEO desideri renderli ricercabili il prima possibile. L'elaborazione di così tanti documenti complessi, molti dei quali contenenti tabelle e immagini, può creare rallentamenti e smaltirli può richiedere settimane. La dura realtà è che, per la maggior parte dei progetti di IA, occorre più tempo per la preparazione dei dati che per l’addestramento e l'ottimizzazione dei modelli.
In molti casi, l'ostacolo principale nello sviluppo di RAG è l'inefficienza delle pipeline di dati legacy. La RAG migliora le risposte dei modelli linguistici di grandi dimensioni (LLM) recuperando il contesto pertinente da una knowledge base. I documenti vengono elaborati (analizzati, suddivisi in blocchi, incorporati) e archiviati in un database vettoriale. Al momento della query, i blocchi pertinenti vengono recuperati e forniti come contesto all'LLM, migliorando l'accuratezza della risposta poiché ora si basano sui dati della tua organizzazione, come mostrato di seguito.
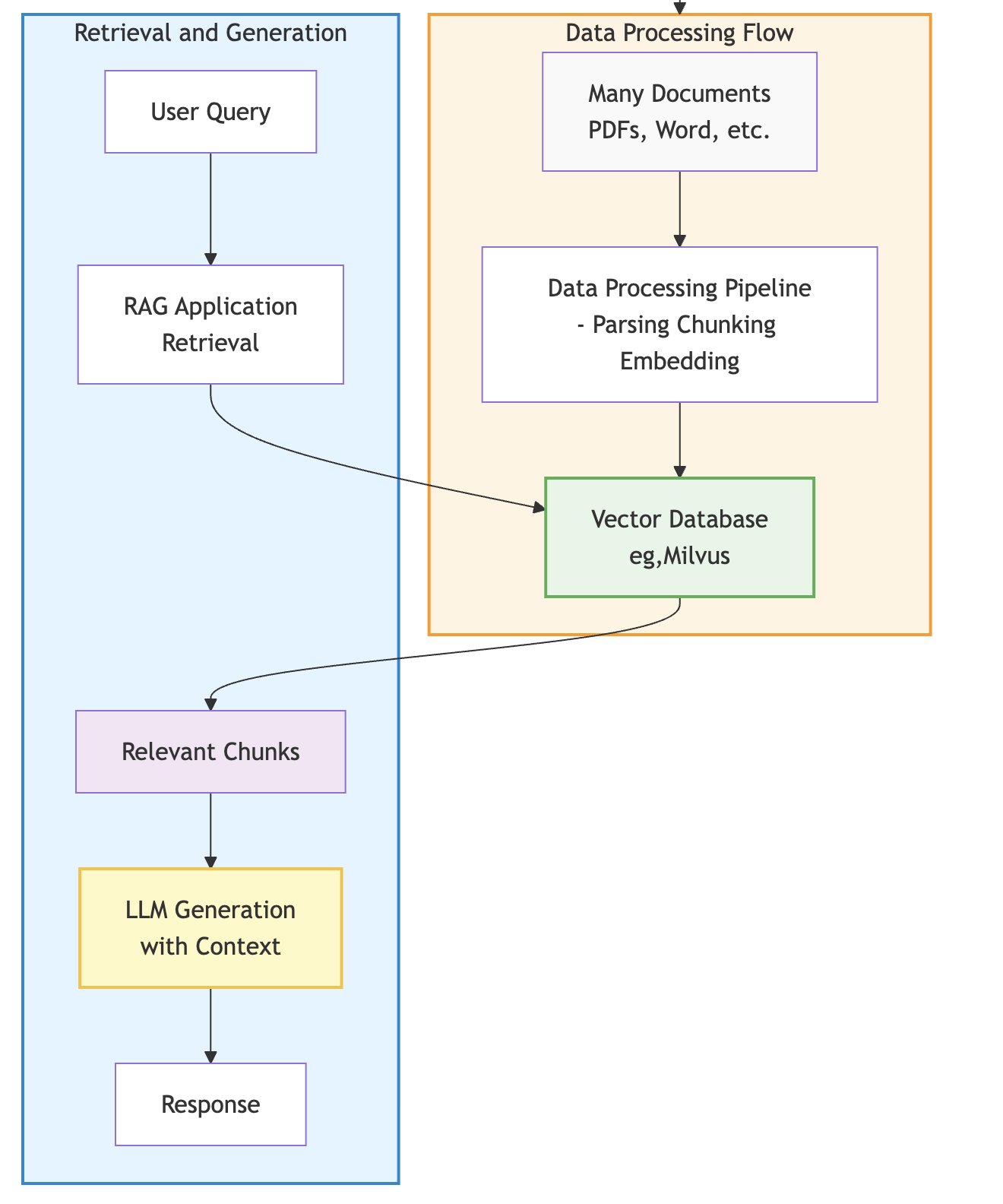
I framework di elaborazione dati tradizionali spesso non soddisfano le esigenze dell'IA, poiché non riescono a coordinare in modo efficace i diversi requisiti di calcolo del flusso di lavoro con l'analisi e l'incorporamento dei documenti. Per scalare l'IA, i team aziendali devono passare a un'infrastruttura unificata che gestisca sia l'analisi ad alta intensità di CPU che l'incorporamento ad alta intensità di GPU in un unico processo snello.
Scalabilità con Ray Data e Docling
Ray Data è una libreria di elaborazione distribuita creata appositamente per i carichi di lavoro di IA e apprendimento automatico (ML). Il suo motore di esecuzione in streaming convoglia i dati tra le attività di CPU e GPU, ottimizzando l'uso della GPU e mantenendo costante il consumo di memoria. Essendo nativo in Python, elimina il sovraccarico di serializzazione dovuto alla traduzione dei dati tra diversi ambienti linguistici, consentendo cicli di iterazione più rapidi per le pipeline RAG.
Docling gestisce la complessa analisi che spesso mette in difficoltà gli strumenti tradizionali, contribuendo a garantire che la tua IA disponga del contesto corretto per fornire risposte utili. Analizzando in modo accurato tabelle e layout nei PDF, Docling aiuta a preservare la struttura semantica che rende più efficace il reperimento con la RAG. Quando è integrato con Ray Data, ogni nodo esegue un'istanza Docling con modelli IA esperti incorporati in memoria (ad esempio per l'elaborazione di layout e tabelle), consentendo un'elaborazione distribuita dei documenti ad alte prestazioni.
Ray Data snellisce l'elaborazione su larga scala suddividendo i set di dati in blocchi, che vengono trasmessi in streaming attraverso un cluster per consentire un elevato parallelismo. In questa architettura, un driver Ray Data gestisce il piano di esecuzione e serializza il codice dell'attività (come l'elaborazione Docling) per la distribuzione, mentre i worker Ray gestiscono il calcolo effettivo. Questi worker leggono i blocchi di dati direttamente dallo storage ed eseguono scritture parallele dei file JSON risultanti nella destinazione, in modo che il driver non sia mai un ostacolo, come illustrato nell’architettura di seguito.
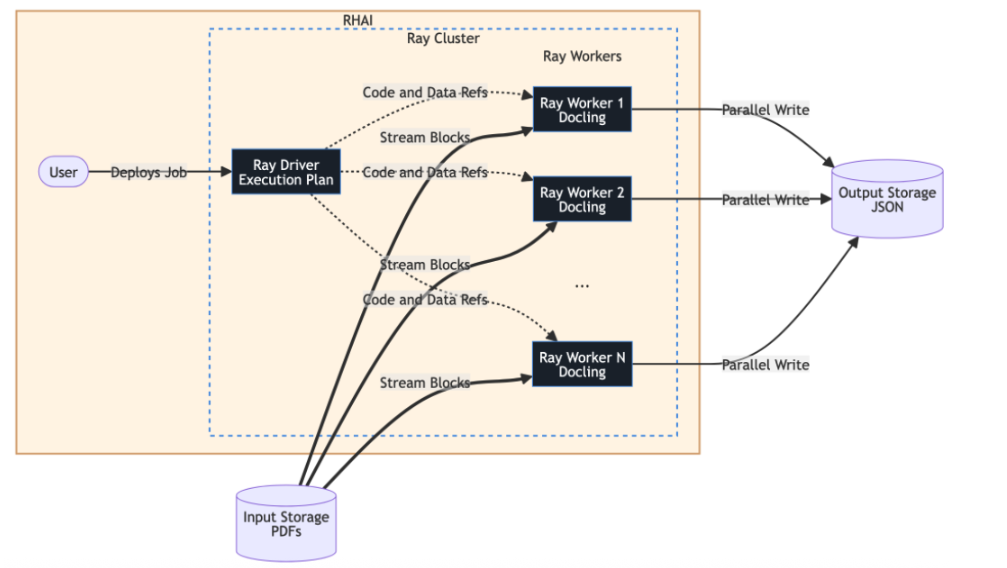
Architettura di dell'elaborazione dei dati IA
- Driver Ray: gestisce gli ObjectRefs e il piano di esecuzione, serializzando il codice Docling per i worker.
- Blocchi di streaming: i worker Ray estraggono i dati direttamente dallo storage di input in parallelo.
- Scrittura in parallelo: ogni worker scrive l'output JSON elaborato direttamente nello storage, così che il throughput dei dati non sovraccarichi il driver Ray.
L'integrazione gestisce automaticamente tutte le complessità distribuite, tra cui la pianificazione, il ripristino in caso di errore e la gestione della memoria. L'utilizzo di un'elaborazione eterogenea consente alle CPU di eseguire l'analisi mentre le GPU incorporano i dati contemporaneamente, ottimizzando l'uso delle costose risorse GPU durante l'intero processo.
Affidabilità enterprise con Red Hat OpenShift AI
OpenShift AI fornisce una base enterprise tramite KubeRay, orchestrando i cluster Ray su Kubernetes con funzionalità integrate di affidabilità e sicurezza. KubeRay gestisce le complessità operative come l'autoscaling dinamico dei cluster, la tolleranza ai guasti e il ripristino automatico in caso di errore dei nodi worker. Ciò consente di passare da 10 a 100 nodi in modo trasparente per soddisfare le esigenze di grandi processi di acquisizione.
Il flusso end-to-end è semplice, come illustrato qui.
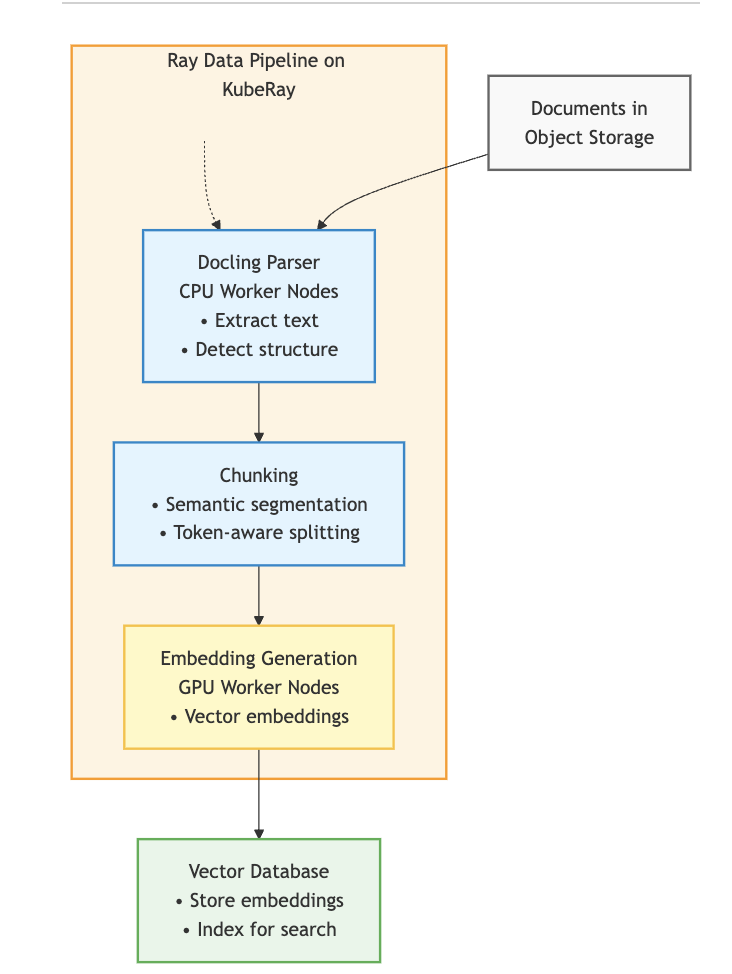
Il processo funziona così:
- I documenti (ad esempio i PDF) arrivano nello storage di oggetti (come S3 o PVC).
- La pipeline Ray Data su OpenShift AI legge questi documenti e li distribuisce tra i nodi worker.
- Docling analizza i documenti sui nodi worker, per poi suddividerli in blocchi per il modello di embedding.
- Gli embedding vengono generati sui nodi GPU e scritti in un database vettoriale come Milvus.
- Un'applicazione RAG interroga il database, fornendo il contesto a un LLM per generare risposte accurate.
L'esecuzione su OpenShift AI mantiene l'elaborazione dei dati all'interno del cluster Kubernetes, contribuendo a soddisfare i requisiti di residenza dei dati e consentendo la distribuzione in cloud privati virtuali o in ambienti on premise. Questa infrastruttura unificata riduce i costi operativi consentendoti di eseguire la preparazione dei dati e la distribuzione dei modelli sulla stessa piattaforma.
Prospettive future: verso soluzioni basate sugli agenti
Il futuro dell'IA aziendale dipende dal superamento della semplice ricerca a favore di sofisticate soluzioni basate su agenti. Le organizzazioni dovranno rafforzare e migliorare ulteriormente le proprie pipeline di dati per supportare flussi di lavoro basati su agenti a più fasi, in cui gli agenti autonomi utilizzano la RAG e il fine-tuning potenziato dal recupero (RAFT) per risolvere problemi complessi. Combinando il contesto in tempo reale della RAG con la capacità di RAFT di "addestrare" un modello su come ignorare meglio le informazioni irrilevanti, i team possono creare agenti decisamente più precisi e affidabili.
Chi investe oggi in architetture scalabili si troverà in una posizione migliore per implementare queste catene di inferenza avanzate, in cui più chiamate LLM avvengono in sequenza con un'allocazione ottimale delle risorse. Il passaggio all'IA basata su agenti significa che la qualità dei tuoi dati elaborati è più importante che mai, poiché gli agenti si affidano a una documentazione precisa per eseguire attività per conto degli utenti. Una base solida consente a queste implementazioni creative dell’IA di soddisfare gli standard aziendali di coerenza e sicurezza.
In definitiva, l'obiettivo consiste nel rendere le informazioni facili da comprendere e da tradurre in azioni per questi agenti di IA. Crediamo che il successo nell'IA generativa inizi rendendo accessibili le informazioni complesse attraverso una base open source dotata di governance aziendale. Creando subito una piattaforma solida e unificata, le aziende possono aiutare le proprie iniziative basate su agenti a generare valore a lungo termine e a promuovere la fiducia degli utenti.
Conclusione
Red Hat OpenShift AI e Anyscale forniscono gli strumenti necessari per trasformare documenti complessi in informazioni fruibili. Risolvendo il problema della lentezza nell'elaborazione dei dati con Ray Data e Docling, aiutiamo le organizzazioni a concentrarsi su ciò che conta di più: risolvere problemi reali.
Registrati al Red Hat Summit 2026 per entrare in contatto con il nostro team ed esplorare il futuro dell'IA in produzione. Potrai provare OpenShift AI nella Red Hat Developer Sandbox con un accesso gratuito di 30 giorni a un ambiente completamente gestito in cui testare questi strumenti.
Prodotto
Red Hat AI
Sugli autori
Ana Biazetti is a senior architect at Red Hat Openshift AI product organization, focusing on Model Customization, Fine Tuning and Distributed Training.
Altri risultati simili a questo
Le minacce dell'IA si muovono rapidamente. Anche le tue difese dovrebbero farlo.
Il punto di svolta per l’IA: perché la sovranità non è più facoltativa
Technically Speaking | Defining sovereign AI with open source
Technically Speaking | Inside open source AI strategy
Ricerca per canale

Automazione
Novità sull'automazione IT di tecnologie, team e ambienti

Intelligenza artificiale
Aggiornamenti sulle piattaforme che consentono alle aziende di eseguire carichi di lavoro IA ovunque

Hybrid cloud open source
Scopri come affrontare il futuro in modo più agile grazie al cloud ibrido

Sicurezza
Le ultime novità sulle nostre soluzioni per ridurre i rischi nelle tecnologie e negli ambienti

Edge computing
Aggiornamenti sulle piattaforme che semplificano l'operatività edge

Infrastruttura
Le ultime novità sulla piattaforma Linux aziendale leader a livello mondiale

Applicazioni
Approfondimenti sulle nostre soluzioni alle sfide applicative più difficili
Virtualizzazione
Il futuro della virtualizzazione negli ambienti aziendali per i carichi di lavoro on premise o nel cloud