
L'adozione e lo sviluppo dell'IA hanno subito una forte accelerazione quando l'IA generativa e l’Agentic AI hanno raggiunto un pubblico vasto. Con l'emergere di nuovi mercati, le aziende hanno difficoltà a sfruttare l'IA per ottenere un reale ritorno sull'investimento. Sebbene le GPU abbiano dominato l'infrastruttura, l'aumento dei costi e la diminuzione della disponibilità dovuti alla domanda hanno spinto i leader a cercare alternative che fossero all’altezza delle prestazioni richieste e degli standard di soddisfazione dei clienti.
Nel frattempo, gli sviluppatori e gli ingegneri che lavorano sull'IA devono affrontare le sfide legate a una configurazione complessa dell’infrastruttura che richiede molto tempo, oltre alle difficoltà nella creazione di software e architetture per un'inferenza ottimale dei modelli linguistici di grandi dimensioni (LLM) con retrieval augmented generation (RAG). La facilità d'uso, la sicurezza dei dati proprietari e anche le modalità per iniziare a creare l'IA sono sfide tecniche che possono impedire agli sviluppatori di accedere all'IA.
La collaborazione tra Intel e Red Hat combina le prestazioni delle CPU Xeon con la scalabilità di Red Hat OpenShift AI, offrendo una base protetta e flessibile per il deployment dell’Agentic AI in azienda. Su questa piattaforma, i clienti possono creare modelli e applicazioni di IA e machine learning in modo più sicuro e scalabile negli ambienti hybrid cloud.
Per semplificare il processo di adozione, Intel ha creato diverse guide introduttive sull'IA. Le guide rapide sull'IA offrono scenari di utilizzo aziendali che possono essere distribuiti rapidamente su Xeon con OpenShift, accelerando lo sviluppo e i tempi di rilascio. Queste guide rapide sono disponibili nel catalogo delle guide rapide IA.
Perché adottare l'IA su Xeon?
Sebbene le GPU abbiano dominato il deep learning, l'IA generativa e l'Agentic AI, l'inferenza può utilizzare piattaforme di elaborazione più piccole e convenienti per soddisfare i requisiti funzionali e prestazionali. Le CPU sono sempre state la piattaforma preferita per l'elaborazione dei dati, l'analisi dei dati e il machine learning classico. Questo include regressione, classificazione, clustering e alberi decisionali che utilizzano metodi quali macchine a vettori di supporto, XGBoost e K-means. Gli scenari di utilizzo includono previsioni finanziarie e di vendita al dettaglio, rilevamento di frodi e ottimizzazione della supply chain. Questo aiuta a gestire i costi dell'infrastruttura IA nel lungo periodo. Intel Xeon è ben posizionata come nodo principale per questo tipo di piattaforme più piccole.
Funzionalità hardware di Intel Xeon
Le caratteristiche hardware sono ciò che contraddistingue Xeon come una valida piattaforma CPU per l'IA. Il set di istruzioni Advanced Matrix Extensions (AMX) e l'elevata larghezza di banda della memoria con i Multiplexed Rank Dual In-line Memory Modules (MRDIMM) sono i componenti più importanti che caratterizzano Xeon.
AMX è stato introdotto nei processori scalabili Intel® Xeon® di quarta generazione come acceleratore IA integrato, ovvero un blocco hardware dedicato sui core, per eseguire calcoli matriciali invece di fare affidamento su un acceleratore discreto. Supporta tipi di dati a precisione inferiore, inclusi Bfloat16 (BF16) e INT8. Uno dei principali vantaggi di BF16 è il miglioramento delle prestazioni senza sacrificare la precisione rispetto a FP32. Le accelerazioni con AMX riducono l'utilizzo di energia e risorse, diminuendo i tempi di sviluppo grazie alle ottimizzazioni upstream nei framework IA, tra cui PyTorch e TensorFlow.
I sistemi di raccomandazione, l'elaborazione del linguaggio naturale, la gen AI, la Agentic AI e gli esempi di utilizzo della computer vision traggono vantaggio da AMX, con un conseguente incremento del valore per l'utente finale e per l'azienda.

Figura 1: Intel® AMX include riquadri di registro 2D con istruzioni multiple per matrici di riquadri TMUL per calcolare matrici di grandi dimensioni in una singola operazione.
Nell'inferenza IA e LLM, un ostacolo alla memoria è rappresentato dalla memorizzazione nella cache chiave-valore (KV), a cause dell'elevata richiesta. MRDIMM risolve questo problema spostando la complessità computazionale da quadratica a lineare, offrendo oltre il 37% di larghezza di banda di memoria in più rispetto agli RDIMM. Ciò migliora la velocità di trasmissione della memoria e riduce la latenza durante la gestione di attività che fanno un uso intensivo dei dati durante l'inferenza dell’IA. Nei sistemi in cui la memoria della GPU è limitata, le CPU Xeon possono scaricare i dati KV, liberando costose risorse GPU e mantenendo prestazioni elevate.
Xeon ha diversi esempi di utilizzo pratico nell'IA: inferenza, RAG, elaborazione sicura dei dati e IA degli agenti. Funzionale e performante, Xeon è una piattaforma con software di supporto per soddisfare le esigenze dell'IA senza la necessità di GPU.
Scenario di utilizzo Xeon 1: Inferenza IA
L'inferenza LLM è alla base di applicazioni quali chatbot aziendali, riepilogo di documenti, assistenti di codice e pipeline RAG. Le aziende di medie dimensioni e le organizzazioni che cercano una gen AI a costi contenuti senza ingenti investimenti in GPU potrebbero trovare Xeon un'opzione più pratica. Xeon funziona al meglio con LLM di piccole e medie dimensioni e mixture-of-experts (MOE) fino a 13 miliardi di parametri, pur soddisfacendo standard quali il time-to-first-token (TTFT) di 3 secondi e il time-per-output-token di 100 ms.
Intel ha collaborato a stretto contatto con la community open source per ottimizzare l'inferenza IA, inclusi vLLM e SGLang. vLLM è un motore per il serving di inferenza con throughput ed efficienza della memoria elevati. La dashboard vLLM per Xeon su Pytorch.org contiene i numeri pubblicati sulle prestazioni degli LLM più diffusi, tra cui Llama-3.1-8B-Instruct su Xeon. Intel continua a migliorare le prestazioni e ad aggiungere supporto a un elenco di modelli convalidati. SGLang è un altro framework di serving rapido che Intel sta integrando con Xeon.
Scenario di utilizzo Xeon 2: RAG ed elaborazione sicura dei dati
RAG è efficace per ottenere risultati accurati dagli LLM senza dover riaddestrare i modelli. La knowledge base viene creata preparando i dati tramite l'analisi dei documenti, la suddivisione in blocchi e l'estrazione dei metadati per creare incorporamenti, che vengono quindi archiviati in un database vettoriale. Tutte le operazioni possono essere eseguite in modo sicuro con Intel® Trust Domain Extensions (TDX), una tecnologia di confidential computing basata su hardware. TDX utilizza macchine virtuali (VM) isolate a livello hardware per proteggere dati e applicazioni da accessi non autorizzati. Questo consente alle aziende di sfruttare rapidamente i dati proprietari disponibili per l'automazione del supporto clienti, il recupero di documenti e la ricerca legale. La latenza di recupero è bassa e le query simultanee possono essere gestite con Xeon.

Figura 2: Intel® TDX utilizza estensioni hardware per la gestione e la crittografia della memoria, al fine di proteggere la riservatezza e l'integrità dei dati.
Scenario di utilizzo Xeon 3: Agentic AI
Gli agenti dell’IA seguono una logica sequenziale di pianificazione, azione, osservazione e riflessione. Utilizza un carico di lavoro misto che include l'inferenza LLM e l'esecuzione di strumenti, dalle query di database alle chiamate API, fino all'accesso ai file. Xeon supporta server Model Context Protocol (MCP), API LlamaStack di tipo agentic, LangChain e framework CrewAI. L'automazione delle operazioni IT, il supporto alle decisioni finanziarie e gli agenti della supply chain sono esempi di scenari di utilizzo aziendali.
Xeon su OpenShift: Novità
Red Hat OpenShift AI è una piattaforma IA di livello enterprise per la gestione dell'intero ciclo di vita di creazione, training e deployment di modelli e applicazioni IA su larga scala in ambienti hybrid cloud, on-premise ed edge. Tra le tecnologie incluse in OpenShift AI, vLLM offre un servizio di modelli ad alta velocità di trasmissione e a bassa latenza, riducendo al contempo i costi dell’hardware. È disponibile una raccolta di modelli di terze parti ottimizzati, convalidati e pronti per la produzione, che offre ai team di sviluppo un maggiore controllo sull'accessibilità e sulla visibilità dei modelli per soddisfare i requisiti di sicurezza e policy. Tutto questo può essere distribuito automaticamente con strumenti avanzati per avviare i progetti IA e ridurre la complessità operativa. Nel complesso, le applicazioni IA possono essere portate in produzione in modo scalabile e più velocemente.
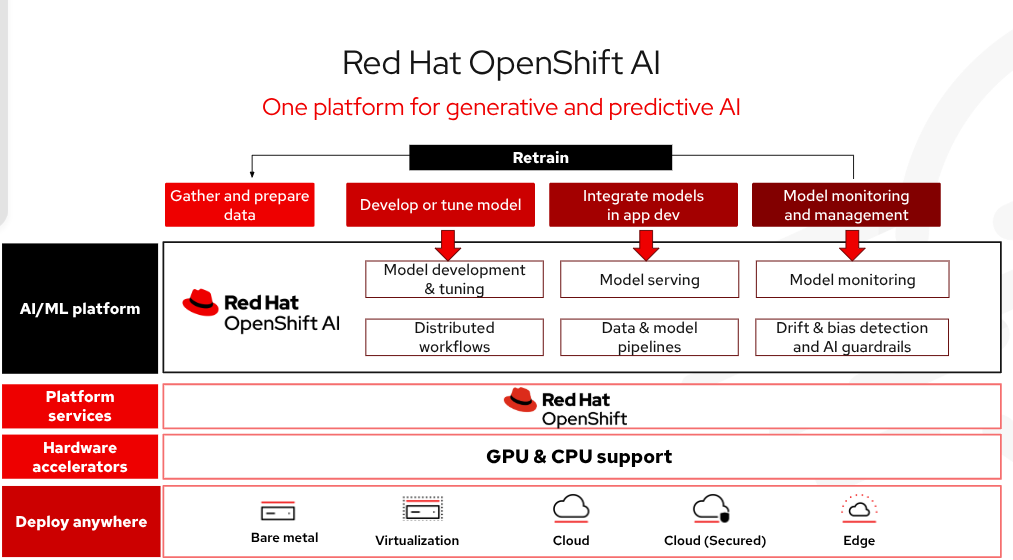
Figura 3: Red Hat OpenShift AI è una piattaforma flessibile e scalabile di intelligenza artificiale (IA) e machine learning (ML), che consente alle aziende di creare e distribuire applicazioni basate sull'IA in modo scalabile in ambienti cloud ibridi.
Funzionalità
La gestione dell'infrastruttura IA richiederà meno tempo: i modelli ad alte prestazioni potranno essere distribuiti facilmente con Models-as-a-Service (MaaS) e sarà possibile accedervi con gli endpoint API. Il cloud ibrido offre flessibilità come software autogestito protetto e flessibile su ambienti bare metal, ambienti virtuali o su tutte le principali piattaforme di cloud pubblico. Red Hat ha testato e integrato comuni strumenti open source di AI/ML e model serving, in modo che gli sviluppatori possano utilizzarli facilmente. OpenShift AI include anche llm-d, un framework open source per l'inferenza dell’IA distribuita in modo scalabile.
Immagine CPU vLLM
Intel ha reso disponibile un'immagine vLLM per CPU su Dockerhub basata sull'immagine di base universale Red Hat. L'immagine è creata con AMX abilitato. Pertanto, per eseguire questa immagine sono necessari processori scalabili Xeon® di quarta generazione o successivi. Ora, molti modelli open source possono essere distribuiti rapidamente ed eseguire rapidamente l'inferenza con velocità di trasmissione elevata e bassa latenza.
Guida rapida all'IA
Nel catalogo rapido AI su redhat.com sono disponibili scenari di utilizzo aziendali pronti all'uso, che eseguono modelli in modo ottimale con vLLM su Xeon, utilizzando tecnologia OpenShift AI. Gli sviluppatori possono adottare questi esempi come punto di partenza e personalizzarli in base alle proprie esigenze oppure utilizzarli così come sono. Le prime bozze delle diverse guide introduttive sull'IA sono disponibili su GitHub e vengono eseguite direttamente su Xeon. Tutte le guide introduttive definitive vengono rilasciate tramite il catalogo delle guide rapide IA.
- LlamaStack MCP Server: esegue il deployment di LLM con vLLM con server MCP, come nel caso degli strumenti per la reportistica meteorologica e gli strumenti per le risorse umane.
- LLM CPU Serving: un assistente di chat strategico e di leadership basato sull'IA, che fornisce un modello linguistico di piccole dimensioni.
- RAG: utilizza la retrieval augmented generation per migliorare gli LLM con sorgenti di dati specializzate, al fine di ottenere risposte più accurate e consapevoli del contesto.
- vLLM Tool Calling: esegue il deployment di LLM utilizzando vLLM con la chiamata di funzioni.
Passaggi successivi
L'IA su Xeon è semplificata grazie a Red Hat OpenShift AI. L'ambiente gestito e protetto configura l'infrastruttura IA necessaria per lo sviluppo, il deployment e l'osservabilità.
- Consulta la dashboard vLLM per Xeon per i dati relativi alle prestazioni e la documentazione vLLM per creare/scaricare le immagini vLLM per CPU con supporto AMX.
- Utilizza vLLM per CPU in base alla Red Hat Universal Base Image da DockerHub.
- Consulta l'elenco dei modelli supportati per Xeon.
- Esplora il catalogo delle guide rapide per l'IA, dove troverai esempi di utilizzo, e visita AI quickstart Github per le guide rapide per l'IA ancora in fase di sviluppo.
- Visita il sito di Red Hat OpenShift AI.
Prodotto
Red Hat AI
Sull'autore
Altri risultati simili a questo
Le minacce dell'IA si muovono rapidamente. Anche le tue difese dovrebbero farlo.
Il punto di svolta per l’IA: perché la sovranità non è più facoltativa
Technically Speaking | Defining sovereign AI with open source
Technically Speaking | Inside open source AI strategy
Ricerca per canale

Automazione
Novità sull'automazione IT di tecnologie, team e ambienti

Intelligenza artificiale
Aggiornamenti sulle piattaforme che consentono alle aziende di eseguire carichi di lavoro IA ovunque

Hybrid cloud open source
Scopri come affrontare il futuro in modo più agile grazie al cloud ibrido

Sicurezza
Le ultime novità sulle nostre soluzioni per ridurre i rischi nelle tecnologie e negli ambienti

Edge computing
Aggiornamenti sulle piattaforme che semplificano l'operatività edge

Infrastruttura
Le ultime novità sulla piattaforma Linux aziendale leader a livello mondiale

Applicazioni
Approfondimenti sulle nostre soluzioni alle sfide applicative più difficili
Virtualizzazione
Il futuro della virtualizzazione negli ambienti aziendali per i carichi di lavoro on premise o nel cloud